支持向量机(SVM)中的 SMO算法
1. 前言
最近又重新复习了一遍支持向量机(SVM)。其实个人感觉SVM整体可以分成三个部分:
1. SVM理论本身:包括最大间隔超平面(Maximum Margin Classifier),拉格朗日对偶(Lagrange Duality),支持向量(Support Vector),核函数(Kernel)的引入,松弛变量的软间隔优化(Outliers),最小序列优化(Sequential Minimal Optimization)等。
2. 核方法(Kernel):其实核方法的发展是可以独立于SVM来看待的,核方法在很多其它算法中也会应用到。
3. 优化理论:这里主要介绍的是最小序列优化(Sequential Minimal Optimization),优化理论的发展也是独立于SVM的。
2. SVM理论基础
SVM的理论基础在上一篇博客的总结中可以参考:http://www.cnblogs.com/bentuwuying/p/6444249.html。
对于支持向量机(SVM)的简单总结:
1. Maximum Margin Classifier
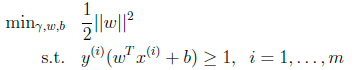
2. Lagrange Duality

3. Support Vector
4. Kernel
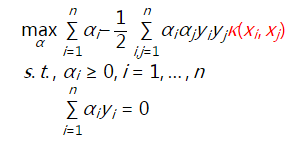
5. Outliers
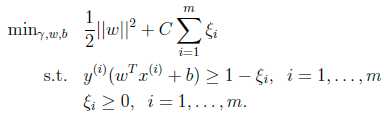
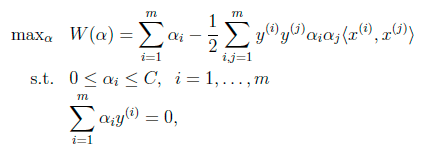
6. Sequential Minimal Optimization
个人觉得SMO又可以分为两部分:
(1)如何选择每次迭代时候的目标工作集,即选择哪两个拉格朗日乘子来迭代。
(2)如何对选择好的工作集(拉格朗日乘子)进行更新迭代。
3. SMO最初的版本(Platt,1998)
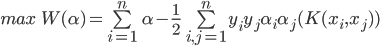
SMO就是要解这个凸二次规划问题,这里的C是个很重要的参数,它从本质上说是用来折中经验风险和置信风险的,C越大,置信风险越大,经验风险越小;并且所有的拉格朗日乘子都被限制在了以C为边长的大盒子里。SMO的出现使得我们不必去求助于昂贵的第三方工具去解决这个凸二次规划问题,目前对它的改进版本很多,这一节先介绍它的最初形式和思想。
SMO是Microsoft Research的John C. Platt在《Sequential Minimal Optimization:A Fast Algorithm for Training Support Vector Machines》一文中提出的,其基本思想是将Vapnik在1982年提出的Chunking方法推到极致,即:通过将原问题分解为一系列小规模凸二次规划问题而获得原问题解的方法,每次迭代只优化由2个点组成的工作集,SMO算法每次启发式地选择两个拉格朗日乘子同时固定其它拉格朗日乘子来找到这两个拉格朗日乘子的最优值,直到达到停止条件。
(1)、 KKT条件
SMO是以C-SVC的KKT条件为基础进行后续操作的,这个KKT条件是:
其中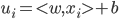
上述条件其实就是KT互补条件,SVM学习——软间隔优化一文,有如下结论:

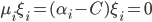
从上面式子可以得到的信息是:当 时,松弛变量
时,松弛变量,此时有:
,对应样本点就是误分点;当
时,松弛变量
为零,此时有
,对应样本点就是内部点,即分类正确而又远离最大间隔分类超平面的那些样本点;而
时,松弛变量
为零,有
,对应样本点就是支持向量。
(2)、凸优化问题停止条件
对于凸优化问题,在实现时总需要适当的停止条件来结束优化过程,停止条件可以是:
1、监视目标函数的增长率,在它低于某个容忍值时停止训练,这个条件是最直白和简单的,但是效果不好;
2、监视原问题的KKT条件,对于凸优化来说它们是收敛的充要条件,但是由于KKT条件本身是比较苛刻的,所以也需要设定一个容忍值,即所有样本在容忍值范围内满足KKT条件则认为训练可以结束;
3、监视可行间隙,它是原始目标函数值和对偶目标函数值的间隙,对于凸二次优化来说这个间隙是零,以一阶范数软间隔为例:
原始目标函数与对偶目标函数
的差为:
定义比率:,可以利用这个比率达到某个容忍值作为停止条件。
(3)、SMO思想
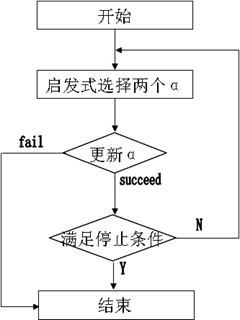
沿袭分解思想,固定“Chunking工作集”的大小为2,每次迭代只优化两个点的最小子集且可直接获得解析解,算法流程:
(4)、仅含两个Langrange乘子解析解
为了描述方便定义如下符号:
于是目标函数就变成了:
注意第一个约束条件:,可以将
看作常数,有
(
为常数,我们不关心它的值),等式两边同时乘以
,得到
(
为常数,其值为
,我们不关心它,
)。将
用上式替换则得到一个只含有变量
的求极值问题:
这下问题就简单了,对求偏导数得到:
将、
带入上式有:
带入、
,用
,表示误差项(可以想象,即使分类正确,
的值也可能很大)、
(
是原始空间向特征空间的映射),这里
可以看成是一个度量两个样本相似性的距离,换句话说,一旦选择核函数则意味着你已经定义了输入空间中元素的相似性。
最后得到迭代式:
注意第二个约束条件——那个强大的盒子:,这意味着
也必须落入这个盒子中,综合考虑两个约束条件,下图更直观:
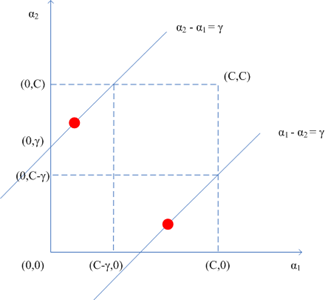
和
异号的情形
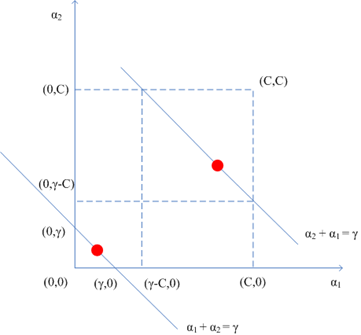
和
同号的情形
可以看到两个乘子既要位于边长为C的盒子里又要在相应直线上,于是对于
的界来说,有如下情况:
整理得下式:
又因为,
,消去
后得到:
(5)、启发式的选择方法
根据选择的停止条件可以确定怎么样选择点能对算法收敛贡献最大,例如使用监视可行间隙的方法,一个最直白的选择就是首先优化那些最违反KKT条件的点,所谓违反KKT条件是指:
由前面的停止条件3可知,对可行间隙贡献最大的点是那些
其中,
取值大的点,这些点导致可行间隙变大,因此应该首先优化它们,原因如下:
1、当满足KKT条件:即时,
当违背KKT条件:即时,
,于是
可见,由于违背KKT条件导致可行间隙变大;
2、当满足KKT条件:即时,
当违背KKT条件:即时
若则
且
,其中
若则
且
,其中
可见,由于违背KKT条件依然导致可行间隙变大;
3、当满足KKT条件:即时,
当违背KKT条件:即时,
且
,其中
可见,由于违背KKT条件还是会导致可行间隙变大。
SMO的启发式选择有两个策略:
启发式选择1:
最外层循环,首先,在所有样本中选择违反KKT条件的一个乘子作为最外层循环,用“启发式选择2”选择另外一个乘子并进行这两个乘子的优化,接着,从所有非边界样本中选择违反KKT条件的一个乘子作为最外层循环,用“启发式选择2”选择另外一个乘子并进行这两个乘子的优化(之所以选择非边界样本是为了提高找到违反KKT条件的点的机会),最后,如果上述非边界样本中没有违反KKT条件的样本,则再从整个样本中去找,直到所有样本中没有需要改变的乘子或者满足其它停止条件为止。
启发式选择2:
内层循环的选择标准可以从下式看出:
要加快第二个乘子的迭代速度,就要使最大,而在
上没什么文章可做,于是只能使
最大。
确定第二个乘子方法:
1、首先在非界乘子中寻找使得最大的样本;
2、如果1中没找到则从随机位置查找非界乘子样本;
3、如果2中也没找到,则从随机位置查找整个样本(包含界上和非界乘子)。
(6)、关于两乘子优化的说明
由式子
可知:
于是对于这个单变量二次函数而言,如果其二阶导数,则二次函数开口向下,可以用上述迭代的方法更新乘子,如果
,则目标函数只能在边界上取得极值(此时二次函数开口向上),换句话说,SMO要能处理
取任何值的情况,于是在
时有以下式子:
1、时:
2、时:
3、
分别将乘子带入得到两种情况下的目标函数值: 和
。显然,哪种情况下目标函数值最大,则乘子就往哪儿移动,如果目标函数的差在某个指定精度范围内,说明优化没有进展。
另外发现,每一步迭代都需要计算输出进而得到
,于是还要更新阈值
,使得新的乘子
、
满足KKT条件,考虑
、
至少有一个在界内,则需要满足
,于是
的迭代可以这样得到:
1、设在界内,则:
又因为:
于是有:
等式两边同乘后移项得:
;
2、设在界内,则:
;
3、设、
都在界内,则:情况1和情况2的
值相等,任取一个;
4、设、
都不在界内,则:
取值为情况1和情况2之间的任意值。
(7)、提高SMO的速度
从实现上来说,对于标准的SMO能提高速度的地方有:
1、能用缓存的地方尽量用,例如,缓存核矩阵,减少重复计算,但是增加了空间复杂度;
2、如果SVM的核为线性核时候,可直接更新,毕竟每次计算
的代价较高,于是可以利用旧的乘子信息来更新
,具体如下:
,应用到这个性质的例子可以参见SVM学习——Coordinate Desent Method。
3、关注可以并行的点,用并行方法来改进,例如可以使用MPI,将样本分为若干份,在查找最大的乘子时可以现在各个节点先找到局部最大点,然后再从中找到全局最大点;又如停止条件是监视对偶间隙,那么可以考虑在每个节点上计算出局部可行间隙,最后在master节点上将局部可行间隙累加得到全局可行间隙。
对标准SMO的改进有很多文献,例如使用“Maximal Violating Pair ”去启发式的选择乘子是一种很有效的方法,还有使用“ Second Order Information”的方法,我觉得理想的算法应该是:算法本身的收敛速度能有较大提高,同时算法可并行程度也较高。
4. SMO更新的版本(Fan,2005)
前面提到过,SMO可以分为两部分:
(1)如何选择每次迭代时候的目标工作集,即选择哪两个拉格朗日乘子来迭代。
(2)如何对选择好的工作集(拉格朗日乘子)进行更新迭代。
而如何选择工作集,是SMO算法很重要的一个部分,因为不同的选择方式可以导致不同的训练速度。
Rong-En Fan等人在2005的paper《Working Set Selection Using Second Order Information for Training Support Vector Machines》介绍了每次迭代时几种不同的工作集选择方法。
首先还是放出SMO需要优化的目标函数:
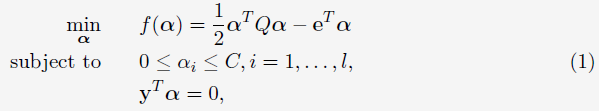
(1)Algorithm 1 (SMO-type decomposition method)

(2)WSS 1 (Working set selection via the “maximal violating pair”)
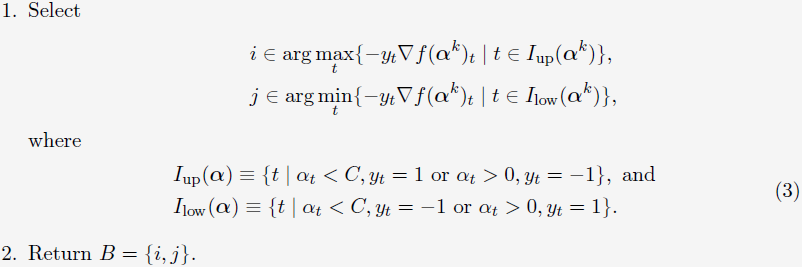
这个working set selection是Keerthi等人在2001年提出的,在2001年发布的libSVM中有所应用。
该working set selection可以由(1)式的KKT条件得出:假设存在向量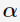 是(1)式的解,则必然存在实数
是(1)式的解,则必然存在实数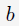 和两个非负向量
和两个非负向量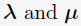 使得下式成立:
使得下式成立:
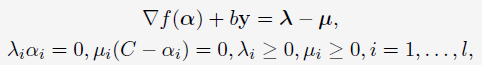
其中,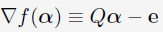 是目标函数的梯度。
是目标函数的梯度。
上面的条件可以被重写为:
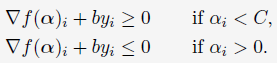
进一步,有
令,
则目标函数存在最优解的条件是:

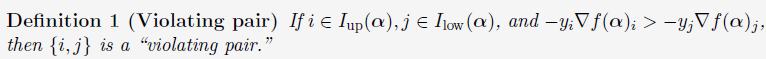
由上面这个关于“Violating pair”的定义可以看出,最大程度上违反(6)式条件的{i, j} pair 即是working set的最佳选择,因为我们需要对这些最违反(6)式的{i, j} pair做更新迭代,让它们符合(6)式的要求,便会逐步让目标函数得到最优值。具体的理论定理如下:

有趣的是,选择最大程度上违反KKT条件的{i, j} pair 与 “求目标函数的一阶近似的最小值”时候取得的{i, j} pair是一致的。即通过WSS 1获得的{i, j} pair满足:

通过定义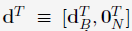 ,(8a)的目标函数即是对
,(8a)的目标函数即是对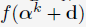 的一阶近似进行求最优解:
的一阶近似进行求最优解:
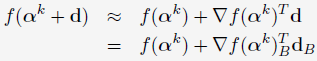
其中,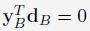 是由于
是由于 ,而(8b)和(8c)是由于
,而(8b)和(8c)是由于 。由于(8a)是线性函数,
。由于(8a)是线性函数,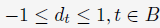 则避免了目标函数取值无穷小。
则避免了目标函数取值无穷小。
第一眼看上去,(7)式似乎需要对所有的拉格朗日乘子遍历一遍才能够找出最优的{i,j} pair,然而,WSS 1可以在线性时间复杂度内找到最优值。证明如下:
Proof

(3)A New Working Set Selection
上面是使用了目标函数的一阶近似作为代替进行优化,于是乎,我们可以再进一步,使用目标函数的二阶近似作为代替进行优化:

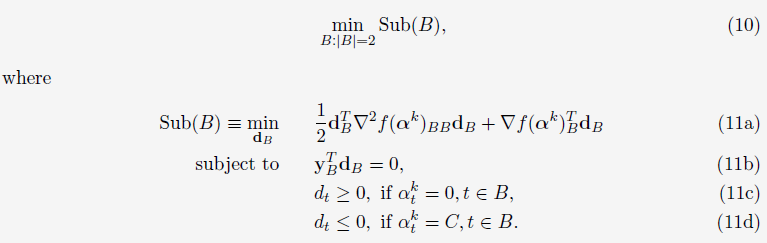
(4)WSS 2 (Working set selection using second order information)

下面的理论证明按照WSS 2可以有效地解决(11)式中的最优值问题:

(5)Non-Positive Definite Kernel Matrices
前面的方法并没有涵盖 的情况,对于这种情况,Chen等人在2006年给出了解决方法:
的情况,对于这种情况,Chen等人在2006年给出了解决方法:

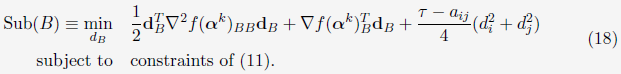
(6)WSS 3 (Working set selection using second order information: any symmetric K)
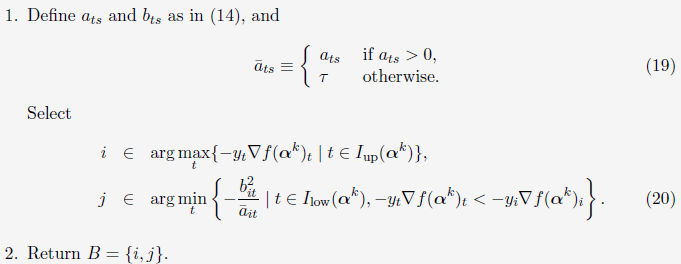
于是,使用WSS 3来对SMO-type 分解方法选择working set的步骤为:
(7)Algorithm 2 (An SMO-type decomposition method using WSS 3)

支持向量机(SVM)中的 SMO算法的更多相关文章
- 机器学习——支持向量机(SVM)之Platt SMO算法
Platt SMO算法是通过一个外循环来选择第一个alpha值的,并且其选择过程会在两种方式之间进行交替: 一种方式是在所有数据集上进行单遍扫描,另一种方式则是在非边界alpha中实现单遍扫描. 所谓 ...
- 机器学习-SVM中的SMO算法详解
- 统计学习方法c++实现之六 支持向量机(SVM)及SMO算法
前言 支持向量机(SVM)是一种很重要的机器学习分类算法,本身是一种线性分类算法,但是由于加入了核技巧,使得SVM也可以进行非线性数据的分类:SVM本来是一种二分类分类器,但是可以扩展到多分类,本篇不 ...
- 支持向量机(五)SMO算法
11 SMO优化算法(Sequential minimal optimization) SMO算法由Microsoft Research的John C. Platt在1998年提出,并成为最快的二次规 ...
- <转>SVM实现之SMO算法
转自http://blog.csdn.net/zouxy09/article/details/17292011 终于到SVM的实现部分了.那么神奇和有效的东西还得回归到实现才可以展示其强大的功力.SV ...
- 理解支持向量机(三)SMO算法
在支持向量机模型的求解中,我们用到了SMO算法来求解向量α. 那么什么是SMO算法?在讲SMO算法之前.我们须要先了解下面坐标上升法. 1.坐标上升法 如果有优化问题: W是α向量的函数.利用坐标上升 ...
- 机器学习——支持向量机(SVM)之拉格朗日乘子法,KKT条件以及简化版SMO算法分析
SVM有很多实现,现在只关注其中最流行的一种实现,即序列最小优化(Sequential Minimal Optimization,SMO)算法,然后介绍如何使用一种核函数(kernel)的方式将SVM ...
- 机器学习之支持向量机(二):SMO算法
注:关于支持向量机系列文章是借鉴大神的神作,加以自己的理解写成的:若对原作者有损请告知,我会及时处理.转载请标明来源. 序: 我在支持向量机系列中主要讲支持向量机的公式推导,第一部分讲到推出拉格朗日对 ...
- SMO算法--SVM(3)
SMO算法--SVM(3) 利用SMO算法解决这个问题: SMO算法的基本思路: SMO算法是一种启发式的算法(别管启发式这个术语, 感兴趣可了解), 如果所有变量的解都满足最优化的KKT条件, 那么 ...
随机推荐
- JiraRemoteUserAuth
配置Jira7.x版本使用REMOTE_USER的HTTP Header方式登录: 前提是已经安装好了JIRA,并且前端使用apache或者nginx拦截对应的地址进行认证,认证之后访问对应的应用的时 ...
- Excel转Json
参考: Excel2JSON Excel转JSON Excel另存为JSON的技巧 (office的插件) excel2json 游戏程序员的自我修养 (其他人写的工具) Excel转JSON格式- ...
- 如何搭建Packetbeat性能监控
安装与配置JDK 1. 将jdk-8u111-linux-x64.tar.gz上传至Linux的/opt目录下,并执行解压命令: tar -zxvf jdk-8u111-linux-x64.tar. ...
- Xcode - xcode-select: error: tool 'xcodebuild' requires Xcode报错解决方案
用mac 自带的终端执行的命令,安装安装Vapor和toolbox 安装指令: macdeMacBook-Pro:~ mac$ curl -sL check.vapor.sh| bash 结果报这个错 ...
- 关于python爬虫的编码错误
现在才发现很多错误只有自己一点点的去尝试才能发现.不管之前别人怎么和你说,总是不可能面面俱到,所以提升自己的方法就是亲手实践,自己一点点的去发现问题,并一个个的解决.慢慢享受其中无言的快感. 今天就发 ...
- 电话、地址、Email等常用正则表达式
正则表达式用于字符串处理.表单验证等场合,实用高效.现将一些常用的表达式收集于此,以备不时之需. 匹配中文字符的正则表达式: [\u4e00-\u9fa5]评注:匹配中文还真是个头疼的事,有了这个表达 ...
- Exception in thread "main" java.lang.StackOverflowError
总结:1.创建对象时,在父类构造方法new子类对象,这样会造成循环调用构造方法
- python面向对象高级:Mixin多重继承
继上一篇学习笔记:python面向对象的继承与多态,本篇就Mixin扩展类的方法写下学习笔记 Mixin Mixin编程是一种开发模式,是一种将多个类中的功能单元的进行组合的利用的方式,这听起来就像是 ...
- kerberos (https://en.wikipedia.org/wiki/Kerberos_(protocol))
Protocol[edit] Description[edit] The client authenticates itself to the Authentication Server (AS) w ...
- IOS UIView圆角,阴影,边框,渐增光泽
圆角 sampleView.layer.cornerRadius = 2.5; // 圓角的弧度sampleView.layer.masksToBounds = YES; 阴影 sampleView. ...