最短路径——Dijkstra算法和Floyd算法
Dijkstra算法概述
Dijkstra算法是由荷兰计算机科学家狄克斯特拉(Dijkstra)于1959 年提出的,因此又叫狄克斯特拉算法。是从一个顶点到其余各顶点的最短路径算法,解决的是有向图(无向图是一种特殊的有向图,当然也可以)中最短路径问题(单源最短路径)。
其基本原理是:每次新扩展一个距离最短的点,更新与其相邻的点的距离。当所有边权都为正时,由于不会存在一个距离更短的没扩展过的点,所以这个点的距离永远不会再被改变,因而保证了算法的正确性。不过根据这个原理,用Dijkstra求最短路的图不能有负权边,因为扩展到负权边的时候会产生更短的距离,有可能就破坏了已经更新的点距离不会改变的性质。
举例来说,如果图中的顶点表示城市,而边上的权重表示著城市间开车行经的距离。 Dijkstra算法可以用来找到两个城市之间的最短路径。
Dijkstra算法的输入包含了一个有权重的有向图G,以及G中的一个来源顶点S。 我们以V表示G中所有顶点的集合。 每一个图中的边,都是两个顶点所形成的有序元素对。(u,v)表示从顶点u到v有路径相连。 我们以E为所有边的集合,而边的权重则由权重函数w: E → [0, ∞]定义。 因此,w(u,v)就是从顶点u到顶点v的非负花费值(cost)。 边的花费可以想像成两个顶点之间的距离。任两点间路径的花费值,就是该路径上所有边的花费值总和。 已知V中有顶点s及t,Dijkstra算法可以找到s到t的最低花费路径(i.e. 最短路径)。 这个算法也可以在一个图中,找到从一个顶点s到任何其他顶点的最短路径。
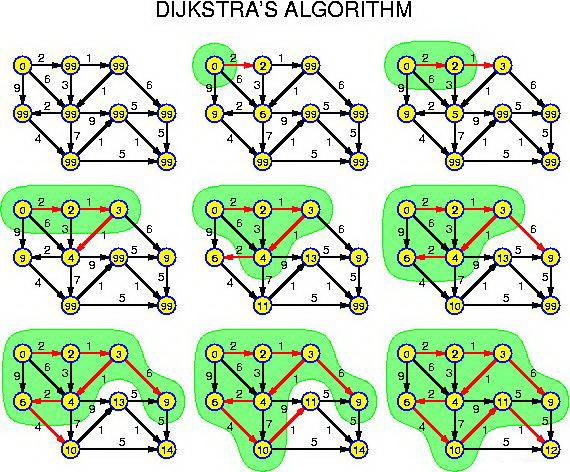
算法描述
这个算法是通过为每个顶点v保留目前为止所找到的从s到v的最短路径来工作的。初始时,源点s的路径长度值被赋为0(d[s]=0), 同时把所有其他顶点的路径长度设为无穷大,即表示我们不知道任何通向这些顶点的路径(对于V中所有顶点v除s外d[v]= ∞)。当算法结束时,d[v]中储存的便是从s到v的最短路径,或者如果路径不存在的话是无穷大。 Dijstra算法的基础操作是边的拓展:如果存在一条从u到v的边,那么从s到u的最短路径可以通过将边(u,v)添加到尾部来拓展一条从s到v的路径。这条路径的长度是d[u]+w(u,v)。如果这个值比目前已知的d[v]的值要小,我们可以用新值来替代当前d[v]中的值。拓展边的操作一直执行到所有的d[v]都代表从s到v最短路径的花费。这个算法经过组织因而当d[u]达到它最终的值的时候没条边(u,v)都只被拓展一次。
算法维护两个顶点集S和Q。集合S保留了我们已知的所有d[v]的值已经是最短路径的值顶点,而集合Q则保留其他所有顶点。集合S初始状态为空,而后每一步都有一个顶点从Q移动到S。这个被选择的顶点是Q中拥有最小的d[u]值的顶点。当一个顶点u从Q中转移到了S中,算法对每条外接边(u,v)进行拓展。
伪码
在下面的算法中,u:=Extract_Min(Q)表示在顶点集Q中搜索有最小的d[u]值的顶点u。这个顶点被从集合Q中删除并返回给用户:
function Dijkstra(G, w, s)
for each vertex v in V[G] // 初始化
d[v] := infinity
previous[v] := undefined
d[s] :=
S := empty set
Q := set of all vertices
while Q is not an empty set // Dijstra算法主体
u := Extract_Min(Q)
S := S union {u}
for each edge (u,v) outgoing from u
if d[v] > d[u] + w(u,v) // 拓展边(u,v)
d[v] := d[u] + w(u,v)
previous[v] := u
如果我们只对在s和t之间寻找一条最短路径的话,我们可以在第9行添加条件如果满足u=t的话终止程序。
现在我们可以通过迭代来回溯出s到t的最短路径:
S := empty sequence
u := t
while defined u
insert u to the beginning of S
u := previous[u]
现在序列S就是从s到t的最短路径的顶点集.
时间复杂度
我们可以用大O符号将Dijkstra算法的运行时间表示为边数m和顶点数n的函数。
Dijkstra算法最简单的实现方法是用一个链表或者数组来存储所有顶点的集合Q,所以搜索Q中最小元素的运算(Extract-Min(Q))只需要线性搜索Q中的所有元素。这样的话算法的运行时间是O(n^2)。
对于边数少于n^2稀疏图来说,我们可以用邻接表来更有效的实现Dijkstra算法。同时需要将一个二叉堆或者斐波纳契堆用作优先队列来寻找最小的顶点(Extract-Min)。当用到二叉堆的时候,算法所需的时间为O((m+n)log n),斐波纳契堆能稍微提高一些性能,让算法运行时间达到O(m + n log n)。 相关问题和算法在Dijkstra算法的基础上作一些改动,可以扩展其功能。例如,有时希望在求得最短路径的基础上再列出一些次短的路径。为此,可先在原图上计算出最短路径,然后从图中删去该路径中的某一条边,在余下的子图中重新计算最短路径。对于原最短路径中的每一条边,均可求得一条删去该边后子图的最短路径,这些路径经排序后即为原图的一系列次短路径。
OSPF(open shortest path first, 开放最短路径优先)算法是Dijkstra算法在网络路由中的一个具体实现。
与Dijkstra算法不同,Bellman-Ford算法可用于具有负花费边的图,只要图中不存在总花费为负值且从源点 s 可达的环路(如果有这样的环路,则最短路径不存在,因为沿环路循环多次即可无限制的降低总花费)。
与最短路径问题有关的一个问题是旅行商问题(traveling salesman problem),它要求找出通过所有顶点恰好一次且最终回到源点的最短路径。该问题是NP难的;换言之,与最短路径问题不同,旅行商问题不太可能具有多项式时间算法。
如果有已知信息可用来估计某一点到目标点的距离,则可改用A*算法,以减小最短路径的搜索范围。
Floyd算法
1.定义概览
Floyd-Warshall算法(Floyd-Warshall algorithm)是解决任意两点间的最短路径的一种算法,可以正确处理有向图或负权的最短路径问题,同时也被用于计算有向图的传递闭包。Floyd-Warshall算法的时间复杂度为O(N3),空间复杂度为O(N2)。
2.算法描述
1)算法思想原理:
从任意节点i到任意节点j的最短路径不外乎2种可能:
(1)直接从i到j;
(2)从i经过若干个节点k到j。
所以,我们假设Dis(i,j)为节点i到节点j的最短路径的距离,对于每一个节点k,我们检查Dis(i,k) + Dis(k,j) < Dis(i,j)是否成立,如果成立,证明从i到k再到j的路径比i直接到j的路径短,我们便设置Dis(i,j) = Dis(i,k) + Dis(k,j),这样一来,当我们遍历完所有节点k,Dis(i,j)中记录的便是i到j的最短路径的距离。
依次扫描每一点(k),并以该点作为中介点,计算出通过k点的其他任意两点(i,j)的最短距离,这就是floyd算法的精髓!同时也解释了为什么k点这个中介点要放在最外层循环的原因.
2).算法描述:
a.从任意一条单边路径开始。所有两点之间的距离是边的权,如果两点之间没有边相连,则权为无穷大。
b.对于每一对顶点 i 和 j,看看是否存在一个顶点 k 使得从 i 到 k 再到 j 比己知的路径更短。如果是更新它。
3). Floyd算法是一个经典的动态规划算法。用通俗的语言来描述的话,首先我们的目标是寻找从点i到点j的最短路径。从动态规划的角度看问题,我们需要为这个目标重新做一个诠释(这个诠释正是动态规划最富创造力的精华所在),floyd算法加入了这个概念 Ak(i,j):表示从i到j中途不经过索引比k大的点的最短路径. 这个限制的重要之处在于,它将最短路径的概念做了限制,使得该限制有机会满足迭代关系,这个迭代关系就在于研究:假设Ak(i,j)已知,是否可以借此推导出Ak-1(i,j)。
假设我现在要得到Ak(i,j),而此时Ak(i,j)已知,那么我可以分两种情况来看待问题:1. Ak(i,j)沿途经过点k;2. Ak(i,j)不经过点k。如果经过点k,那么很显然,Ak(i,j) = Ak-1(i,k) + Ak-1(k,j),为什么是Ak-1呢?因为对(i,k)和(k,j),由于k本身就是源点(或者说终点),加上我们求的是Ak(i,j),所以满足不经过比k大的点的条件限制,且已经不会经过点k,故得出了Ak-1这个值。那么遇到第二种情况,Ak(i,j)不经过点k时,由于没有经过点k,所以根据概念,可以得出Ak(i,j)=Ak-1(i,j)。现在,我们确信有且只有这两种情况--不是经过点k,就是不经过点k,没有第三种情况了,条件很完整,那么是选择哪一个呢?很简单,求的是最短路径,当然是哪个最短,求取哪个,故得出式子:
Ak(i,j) = min( Ak-1(i,j), Ak-1(i,k) + Ak-1(k,j) )
现在已经得出了Ak(i,j) = Ak-1(i,k) + Ak-1(k,j)这个递归式,但显然该递归还没有一个出口,也就是说,必须定义一个初始状态,事实上,这个初始状态取决于索引k是从0开始还是从1开始,上面的代码是C写的,是以0为开始索引,但一般描述算法似乎习惯用1做开始索引,如果是以1为开始索引,那么初始状态值应设置为A0了,A0(i,j)的含义不难理解,即从i到j的边的距离。也就是说,A0(i,j) = cost(i,j) 。由于存在i到j不存在边的情况,也就是说,在这种情况下,cost(i,j)无限大,故A0(i,j) = oo(当i到j无边时)
到这里,已经列出了求取Ak(i,j)的整个算法了,但是,最终的目标是求dist(i,j),即i到j的最短路径,如何把Ak(i,j)转换为dist(i,j)?这个其实很简单,当k=n(n表示索引的个数)的时候,即是说,An(i,j)=dist(i,j)。那是因为当k已经最大时,已经不存在索引比k大的点了,那这时候的An(i,j)其实就已经是i到j的最短路径了。
从floyd算法中不难看出,要设计一个好的动态规划算法,首先需要研究是否能把目标进行重新诠释(这一步是最关键最富创造力的一步),转化为一个可以被分解的子目标,如果可以转化,就要想办法寻找数学等式使目标收敛为子目标,如果这一步可以实现了,还需要研究该递归收敛式的出口,即初始状态是否明确(这一步往往已经简单了)。
如果需要保存最短路径,需要借助path数组.
typedef struct
{
char vertex[VertexNum]; //顶点表
int edges[VertexNum][VertexNum]; //邻接矩阵,可看做边表
int n,e; //图中当前的顶点数和边数
}MGraph; void Floyd(MGraph g)
{
int A[MAXV][MAXV];
int path[MAXV][MAXV];
int i,j,k,n=g.n;
// 初始化数据
for(i=;i<n;i++)
for(j=;j<n;j++)
{
A[i][j]=g.edges[i][j];
path[i][j]=-;
}
//
for(k=;k<n;k++)
{
for(i=;i<n;i++)
for(j=;j<n;j++)
if(A[i][j]>(A[i][k]+A[k][j]))
{
A[i][j]=A[i][k]+A[k][j];
path[i][j]=k;
}
}
}
【参考】
2. MBA智库:
http://wiki.mbalib.com/wiki/Dijkstra%E7%AE%97%E6%B3%95
3. floyd算法
最短路径——Dijkstra算法和Floyd算法的更多相关文章
- 最短路径Dijkstra算法和Floyd算法整理、
转载自:http://www.cnblogs.com/biyeymyhjob/archive/2012/07/31/2615833.html 最短路径—Dijkstra算法和Floyd算法 Dijks ...
- 【转】最短路径——Dijkstra算法和Floyd算法
[转]最短路径--Dijkstra算法和Floyd算法 标签(空格分隔): 算法 本文是转载,原文在:最短路径-Dijkstra算法和Floyd算法 注意:以下代码 只是描述思路,没有测试过!! Di ...
- 最短路径—Dijkstra算法和Floyd算法
原文链接:http://www.cnblogs.com/biyeymyhjob/archive/2012/07/31/2615833.html 最后边附有我根据文中Dijkstra算法的描述使用jav ...
- 最短路径—Dijkstra算法和Floyd算法【转】
本文来自博客园的文章:http://www.cnblogs.com/biyeymyhjob/archive/2012/07/31/2615833.html Dijkstra算法 1.定义概览 Dijk ...
- 图的最短路径——dijkstra算法和Floyd算法
dijkstra算法 求某一顶点到其它各个顶点的最短路径:已知某一顶点v0,求它顶点到其它顶点的最短路径,该算法按照最短路径递增的顺序产生一点到其余各顶点的所有最短路径. 对于图G={V,{E}};将 ...
- 【转载】最短路径—Dijkstra算法和Floyd算法
注意:以下代码 只是描述思路,没有测试过!! Dijkstra算法 1.定义概览 Dijkstra(迪杰斯特拉)算法是典型的单源最短路径算法,用于计算一个节点到其他所有节点的最短路径.主要特点是以起始 ...
- 最短路径—Dijkstra 算法和Floyd 算法
某省自从实行了很多年的畅通工程计划后,终于修建了很多路.不过路多了也不好,每次要从一个城镇到另一个城镇时,都有许多种道路方案可以选择,而某些方案要比另一些方案行走的距离要短很多.这让行人很困扰. 现在 ...
- 【转载】Dijkstra算法和Floyd算法的正确性证明
说明: 本文仅提供关于两个算法的正确性的证明,不涉及对算法的过程描述和实现细节 本人算法菜鸟一枚,提供的证明仅是自己的思路,不保证正确,仅供参考,若有错误,欢迎拍砖指正 ----------- ...
- Dijkstra算法和Floyd算法的正确性证明
说明: 本文仅提供关于两个算法的正确性的证明,不涉及对算法的过程描述和实现细节 本人算法菜鸟一枚,提供的证明仅是自己的思路,不保证正确,仅供参考,若有错误,欢迎拍砖指正 ------------- ...
随机推荐
- Axiom3D:Ogre中Mesh网格分解成点线面。
这个需求可能比较古怪,一般Mesh我们组装好顶点,索引数据后,直接放入索引缓冲渲染就好了.但是如果有些特殊需要,如需要标注出Mesh的顶点,线,面这些信息,以及特殊显示这些信息. 最开始我想的是自己分 ...
- 基于SOA的组件化业务基础平台[转]
转自https://www.ibm.com/developerworks/cn/webservices/1111_xiaojg_soa/index.html 业务基础平台是业务逻辑和基础架构平台之间的 ...
- Kilo 版 Keystone 数据库结构
在安装完keystone并利用keystone-manage命令同步数据库后,mysql(我使用的存储后端)中新加了如下表: +------------------------+ | Tables_i ...
- 设置 sqlserver Profiler 只监控 EF的sql执行请求
当我们用EF执行语句的时候,可以使用 sqlserver Profiler来监控到底执行了哪些sql语句,但是默认他是监控全局的,我们只想监控Ef的语句,这里如下设置 这样就只会监控 EF产生的 sq ...
- EasyUI的combobox组件Chrome浏览器不兼容问题解决办法
EasyUI版本:jQuery EasyUI 1.4.1 Chrome浏览器版本:41.0.2272.101 m 问题描述 在Chrome浏览器下,下拉框选择选项之后,选择的值在下拉框中不显示,重新选 ...
- C# ToString()格式设置大全
C 货币 2.5.ToString("C") ¥2.50 D 十进制数 25.ToString("D5") 00025 E 科学型 25000.ToString ...
- Tomcat介绍 安装jdk 安装Tomcat
Tomcat介绍 Tomcat是Apache软件基金会(Apache Software Foundation)的Jakarta项目中的一个核心项目,由Apache.Sun和其他一些公司及个人共同开发而 ...
- Service 保活法之一
我们都知道,在Android中,Service有两种启动方式: startService 以startService()启动服务,系统将通过传入的Intent在底层搜索相关符合Intent里面信息的s ...
- Oracle统计每条数据的大小
怎么查询一条记录到底占了多少空间呢,随便用一个表举例(如上图),就着解决眼前问题的原则(oracle),网上简单查了查,发现生效了,就没深入了解了,包括其它数据库怎么解决,都没做研究.Oracle下, ...
- 2 URL的玩法
preface 这里我主要说说flask的URL玩法 include: 动态URL规则 自定义URL转换器 HTTP方法 唯一的URL 构造URL 跳转和重定向 动态URL规则 URL规则可以添加变量 ...