大数据框架-Mapreduce过程
1、Shuffle
[从mapTask到reduceTask: Mapper -> Partitioner ->Combiner -> Sort ->Reducer]
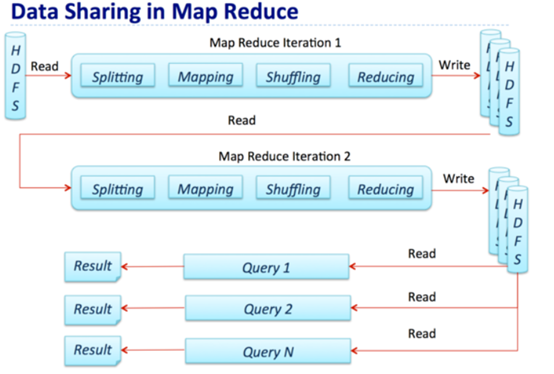
mapper对job任务进行键值对构建并写入环形内存缓冲区[缓冲区满了,map停止直到全写入磁盘],大小100MB(io.sort.mb),一旦达到0.8(io.sort.spill.percent)读入量,即将内存内容经过partitioner分区和sort排序,和combiner合并写入到磁盘一个溢写出文件目录下(mapred.local.dir)。当数据读取完成,将磁盘所有溢出文件合并成一个大文件(同样是经过分区和排序后的文件)。将映射关系提交给AppMaster。
reducer通过心跳机制到AppMaster获取映射关系,再通过Http方式得到文件分区,不同区号文件进入不同reducer,再合并排序进行reduce处理。
Mapper:输出键值对集合(函数setup、map、cleanup、run);
Partitioner:分区,并确保分区号大于或等于reducer的个数。对Mapper结果进行计算确定交给哪个reducer来计算;
Combiner:在map端执行减少传输到reducer的数据量,看作本地的reducer,实现本地key的归并;但combiner不能改变key/value的类型,适用于不影响最终结果场景(累加、最大值);
Sort:按照key值排序。
2、hadoop序列化类型(全都继承Writable)
Text:类似于java中的String
基础Writable对象(IntWritable\LongWritable\ BooleanWritable\ ByteWritable\...)
自定义序列化对象
(实现writable接口;
同时实现序列化函数write和反序列化函数readFiles,但写和读顺序和类型要一致;
重写tostring方法,否则输出结果为类全名+hascode值
需要无参构造方法)
3、MapReduce任务实现流程
Client将JAR包信息发送到RM(PRC通信)
RM返回一个jar包存储路径(固定)和一个jobID
Client对路径进行拼接,通过FileSystem将jar包写入到hdfs中(默认情况下jar包写10份)
Client再将jobID,jar包地址,其他配置发送给RM
RM将任务放入调度器(默认先进先出),NM通过心跳机制获取Mapreduce任务,在HDFS上下载JAR包,启动子进程运行任务
(1)、具体执行过程如下:

函数中主体为submit(),先进行connect(),再使用submitter进行任务调度。
A.
初始化Job持有的cluster对象引用(cluster引用中持有ClientProtocol对象引用)。
Ps: ClientProtocol:RPCserver的代理对象,也可以理解为RM进程对象)。定义了客户端与nameNode间的接口,客户端对文件系统的所有操作都需要通过这个接口,同时客户端读、写文件等操作也需要先通过这个接口与NamenodeRPC通信后后,再进行数据块的读出和写入操作。
B.
通过提交器提交job任务,返回一个PATH
也返回一个Job的ID
拼接上述PATH和JobID
将jar包信息拷贝到HDFS中 job信息,存放job地址和副本数量
提交到服务端RM jobid、jar包地址,其他配置信息,通过RPC通信
大数据框架-Mapreduce过程的更多相关文章
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink
转自:https://www.cnblogs.com/reed/p/7730329.html 今天看到一篇讲得比较清晰的框架对比,这几个框架的选择对于初学分布式运算的人来说确实有点迷茫,相信看完这篇文 ...
- 大数据框架:Spark vs Hadoop vs Storm
大数据时代,TB级甚至PB级数据已经超过单机尺度的数据处理,分布式处理系统应运而生. 知识预热 「专治不明觉厉」之“大数据”: 大数据生态圈及其技术栈: 关于大数据的四大特征(4V) 海量的数据规模( ...
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink——flink支持SQL,待看
简介 大数据是收集.整理.处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称.虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性.规模,以及价值在最近几年才 ...
- YARN之上的大数据框架REEF:微软出品,是否值得期待?
YARN之上的大数据框架REEF:微软出品,是否值得期待? 摘要:微软即将开源大数据框架REEF,REEF运行于Hadoop新一代资源管理器YARN的上层.对于机器学习等在数据传输.任务监控和结果 ...
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
- 老李分享:大数据框架Hadoop和Spark的异同
poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨询qq:908821478,咨询电话010-845052 ...
- 【机器学习实战】第15章 大数据与MapReduce
第15章 大数据与MapReduce 大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力. 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则 ...
- [转载] 2 分钟读懂大数据框架 Hadoop 和 Spark 的异同
转载自https://www.oschina.net/news/73939/hadoop-spark-%20difference 谈到大数据,相信大家对Hadoop和Apache Spark这两个名字 ...
- 2分钟读懂大数据框架Hadoop和Spark的异同
转自:https://www.cnblogs.com/reed/p/7730313.html 谈到大数据,相信大家对Hadoop和Apache Spark这两个名字并不陌生.但我们往往对它们的理解只是 ...
随机推荐
- cf1037E. Trips(图论 set)
题意 题目链接 Sol 倒着考虑!倒着考虑!倒着考虑! 显然,一个能成为答案的子图一定满足,其中任意节点的度数\(>= k\) 那么倒着维护就只用考虑删除操作,如果一个点不合法的话就把它删掉,然 ...
- 关于github改名问题
不喜欢github显示的目录名字于是百度了下,更改过程,记录下来,方便日后查看! 首页右上角点击出来菜单,找到Settings按钮点击 左侧找到Account账号菜单点击 找到change usern ...
- 01_微信小程序支付
[支付流程] 1.小程序内调用登录接口,获取到用户的openid(我们这一步骤让前端去获取) 2.服务端代码这边生成订单 3.服务端调用支付统一下单的api 4.服务端将再次签名,返回5个参数(前端得 ...
- webgis开发-开始向JS转向
官方的一个blog Final Release and Support Plan for the ArcGIS APIs / Viewers for Flex and Silverlight 网址: ...
- MySQL数据库备份与还原
备份数据库 1.使用mysqldump命令备份 备份一个数据库:mysqldump -u 用户名 -p密码 数据库名 [表名1,表名2...]>备份文件路径及名字.sql 如 ...
- C语言函数指针(指向函数的指针)
转载:http://c.biancheng.net/cpp/html/3248.html 一个函数总是占用一段连续的内存区域,函数名在表达式中有时也会被转换为该函数所在内存区域的首地址,这和数组名非常 ...
- spring-springmvc code-based
idea设置maven在下载依赖的同时把对应的源码下载过来.图0: 1 主要实现零配置来完成springMVC环境搭建,当然现在有了springBoot也是零配置,但是很多同仁都是从spring3.x ...
- [转] RISC-V架构介绍
1. RISC-V和其他开放架构有何不同 如果仅从"免费"或"开放"这两点来评判,RISC-V架构并不是第一个做到免费或开放的处理器架构. 在开始之前,我们先通 ...
- 个体商户POS机遭遇禁刷 职业养卡人称自有对策
“套现猛于虎也”,这对于信用卡业而言无异于一大命门,信用卡套现金额的规模如同滚雪球般愈演愈烈.记者昨日采访银行业内了解到,虽然为防套现将根据规定关闭个体商户POS机刷信用卡的功能,但职业“养卡人”不以 ...
- SQL Server ->> SQL Server 2016新特性之 -- AlwaysOn的增强改进
1)标准版也开始支持AlwaysOn了,只不过限制太多,比如副节点不能只读访问和只能有一个副节点. 2)副节点(只读节点)的负载均衡,这是我认为最有用的改进 3)自动failover的节点从2个增加到 ...