python应用:爬虫框架Scrapy系统学习第三篇——初识scrapy
scrapy的最通用的爬虫流程:UR2IM
U:URL
R2:Request 以及 Response
I:Item
M:More URL
在scrapy shell中打开服务器一个网页
cmd中执行:scrapy shell http://www.baidu.com (可以使用exit()退出)

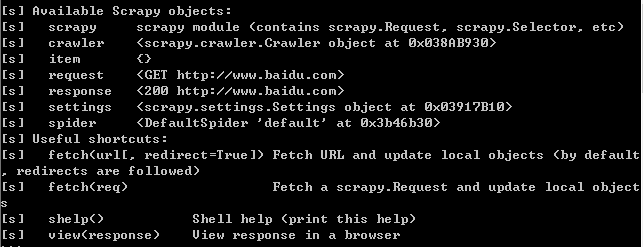
此时,scrapy执行一个默认的GET请求,并得到一个状态码为200的响应
可以使用response.body打印页面源码(或部分字符)
例:response.body[:50]

同时,也可使用response.xpath(' ')来测试XPath表达式的效果
例:response.xpath('//*[@id="su"]') 获取百度一下按钮处的源码
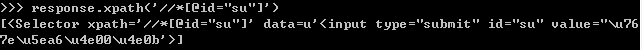
response.xpath('//*[@id="su"]').xpath('.//@value') 获取上述局部源码中的value属性值
注:.//@value是相对XPath表达式;用于获取selector的得到的局部源码中的信息

response.xpath('//*[@id="su"]').xpath('.//@value').extract() 获取上述结果中的源码(源码不等于selector,等于data值)

下一步操作是:从响应中将数据抽取到Item的字段中(通常使用/text()获取文本字段)
通常,我们使用//*[@id="su"][1]这种形式。
目的:为防止结尾某些细微之处的嵌套信息没有注意到
python应用:爬虫框架Scrapy系统学习第三篇——初识scrapy的更多相关文章
- python应用:爬虫框架Scrapy系统学习第四篇——scrapy爬取笔趣阁小说
使用cmd创建一个scrapy项目: scrapy startproject project_name (project_name 必须以字母开头,只能包含字母.数字以及下划线<undersco ...
- python 网络爬虫框架scrapy使用说明
1 创建项目scrapy startproject tutorial 2 定义Itemimport scrapyclass DmozItem(scrapy.Item): title = scra ...
- scrapy系统学习(1)--概要
本文操作环境:ubuntu14.04 一.安装Scrapy/Mysql/MySQLdb 参照官网教程安装Scrapy #sudo apt-key adv --keyserver hkp://keyse ...
- python自动化开发-[第二十四天]-高性能相关与初识scrapy
今日内容概要 1.高性能相关 2.scrapy初识 上节回顾: 1. Http协议 Http协议:GET / http1.1/r/n...../r/r/r/na=1 TCP协议:sendall(&qu ...
- 基于Python接口自动化测试框架+数据与代码分离(进阶篇)附源码
引言 在上一篇<基于Python接口自动化测试框架(初级篇)附源码>讲过了接口自动化测试框架的搭建,最核心的模块功能就是测试数据库初始化,再来看看之前的框架结构: 可以看出testcase ...
- 开源框架.netCore DncZeus学习(三)增加一个菜单
框架运行起来了,先尝试增加一个菜单. 本节增加一个菜单名字:公司管理,需要注意一点,所有的name都要保持一致,注意圈中部分.为了防止手敲代码出错,建议复制已有的代代码进行修改(比如这里用的Role页 ...
- python应用:爬虫框架Scrapy系统学习第二篇——windows下安装scrapy
windows下安装scrapy 依次执行下列操作: pip install wheel pip install lxml pip install PyOpenssl 安装Microsoft visu ...
- python应用:爬虫框架Scrapy系统学习第一篇——xpath详解
HTML的三大概念:标签.元素以及属性 标签:尖括号中的文本 例:<head>……</head> 标签通常成对出现 元素:标签中的所有内容 元素中可包 ...
- Scrapy:Python的爬虫框架
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
随机推荐
- 如何判断单链表是否存在环 & 判断两链表是否相交
给定一个单链表,只给出头指针h: 1.如何判断是否存在环? 2.如何知道环的长度? 3.如何找出环的连接点在哪里? 4.带环链表的长度是多少? 解法: 1.对于问题1,使用追赶的方法,设定两个指针sl ...
- 代码分析工具推荐Understand
之前看ogitor ,第一次看到那么多代码~~不知道从哪里下手,而且好多东西都不会Ogre什么的都不是很清楚,对ogitor的代码结构的了解就更不用提了.晕头转向的 不知道从哪里下手,一点点的看起来好 ...
- 【Leetcode】【Easy】Same Tree
Given two binary trees, write a function to check if they are equal or not. Two binary trees are con ...
- C++的extern关键字
extern是一个声明,不是一个定义,A模块想应用B模块的一个函数或者变量,A模块包含B模块的头文件,并且在变量或者头文件前,加 extern,虽然编译的时候,找不到模块的定义,但是在连接的时候,会在 ...
- SAP Customer Data Cloud(Gigya)的用户搜索实现
我在Gigya前台根据email搜索,输入一个邮箱地址,回车,在Chrome开发者工具里观察到到后台的网络请求: 这是一个post请求: __RequestVerificationToken 请求体: ...
- 【[NOI2016]区间】
发现自己的离散化姿势一直有问题 今天终于掌握了正确的姿势 虽然这并不能阻挡我noip退役爆零的历史进程 还是先来看看离散化怎么写吧,我以前都是这么写的 for(std::set<int>: ...
- C/C++心得-面向对象
首先本文以C++描述面向对象.面向对象应该可以说是C++对C最为重要的扩充.面向对象使得C++可以用更符合人的思维模式的方式编程,使得有一定基础的程序员可以更容易的写程序.相对于C,C++还有其他许多 ...
- rc.local 开机自启脚本无法启动
1.看是否rc.local 第一行如果是 #!/bin/sh -e 改成 #!/bin/bash sudo systemctl enable rc-local.service 2.看rc.local的 ...
- js 关联着数组中追加元素
var arr_data = new Array(); for ( var i in data.data ){ arr_data.push(arr_data[i] = data.data[ i ] ) ...
- 关于mysql 出现 1264 Out of range value for column 错误的解决办法
今天给客服恢复mysql数据的时候.本来测试好的数据.但是到了客户那里却死活不干活了.老报错! INSERT INTO ka_tan4 set num='716641385999', username ...