TUNING FOR ALL FLASH DEPLOYMENTS
Ceph Tuning and Best Practices for All Flash Intel® Xeon® Servers
Last updated: January 2017
TABLE OF CONTENTS
- Introduction
- Ceph Storage Hardware Guidelines
- Intel Tuning and Optimization Recommendations for Ceph
- Appendix
- Sample Ceph.conf
- Sample sysctl.conf
- All-NVMe Ceph Cluster Tuning for MySQL workload
- Sample Ceph Vendor Solutions
INTRODUCTION
Ceph is a scalable, open source, software-defined storage offering that runs on commodity hardware. Ceph has been developed from the ground up to deliver object, block, and file system storage in a single software platform that is self-managing, self-healing and has no single point of failure. Because of its highly scalable, software defined storage architecture, can be a powerful storage solution to consider.
This document covers Ceph tuning guidelines specifically for all flash deployments based on extensive testing by Intel with a variety of system, operating system and Ceph optimizations to achieve highest possible performance for servers with Intel® Xeon® processors and Intel® Solid State Drive Data Center (Intel® SSD DC) Series. Details of OEM system SKUs and Ceph reference architectures for targeted use-cases can be found on ceph.com web-site.
CEPH STORAGE HARDWARE GUIDELINES
- Standard configuration is ideally suited for throughput oriented workloads (e.g., analytics, DVR). Intel® SSD Data Center P3700 series is recommended to achieve best possible performance while balancing the cost.
CPU Intel® Xeon® CPU E5-2650v4 or higher Memory Minimum of 64 GB NIC 10GbE Disks 1x 1.6TB P3700 + 12 x 4TB HDDs (1:12 ratio) / P3700 as Journal and caching Caching software Intel Cache Acceleration Software for read caching, option: Intel® Rapid Storage Technology enterprise/MD4.3
- TCO optimized configuration provides best possible performance for performance centric workloads (e.g., database) while achieving the TCO with a mix of SATA SSDs and NVMe SSDs.
CPU Intel® Xeon® CPU E5-2690v4 or higher Memory 128 GB or higher NIC Dual 10GbE Disks 1x 800GB P3700 + 4x S3510 1.6TB
- IOPS optimized configuration provides best performance for workloads that demand low latency using all NVMe SSD configuration.
CPU Intel® Xeon® CPU E5-2699v4 Memory 128 GB or higher NIC 1x 40GbE, 4x 10GbE Disks 4 x P3700 2TB
INTEL TUNING AND OPTIMIZATION RECOMMENDATIONS FOR CEPH
SERVER TUNING
CEPH CLIENT CONFIGURATION
In a balanced system configuration both client and storage node configuration need to be optimized to get the best possible cluster performance. Care needs to be taken to ensure Ceph client node server has enough CPU bandwidth to achieve optimum performance. Below graph shows the end to end performance for different client CPU configurations for block workload.

Figure 1: Client CPU cores and Ceph cluster impact
CEPH STORAGE NODE NUMA TUNING
In order to avoid latency, it is important to minimize inter-socket communication between NUMA nodes to service client IO as fast as possible and avoid latency penalty. Based on extensive set of experiments conducted in Intel, it is recommended to pin Ceph OSD processes on the same CPU socket that has NVMe SSDs, HBAs and NIC devices attached.
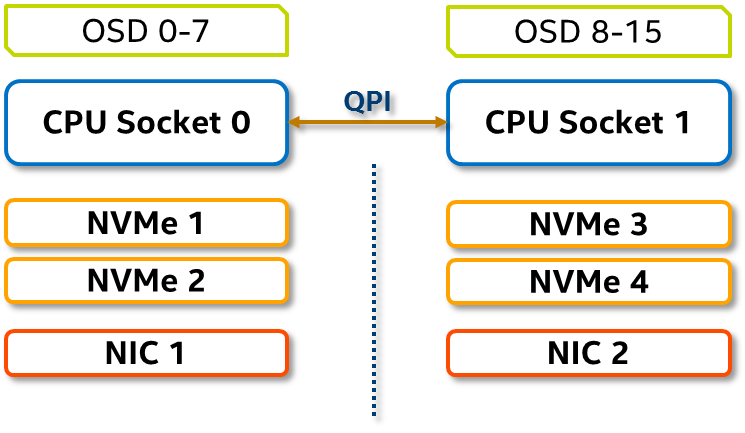
Figure 2: NUMA node configuration and OSD assignment
*Ceph startup scripts need change with setaffinity=" numactl --membind=0 --cpunodebind=0 "
Below performance data shows best possible cluster throughput and lower latency when Ceph OSDs are partitioned by CPU socket to manage media connected to local CPU socket and network IO not going through QPI link.
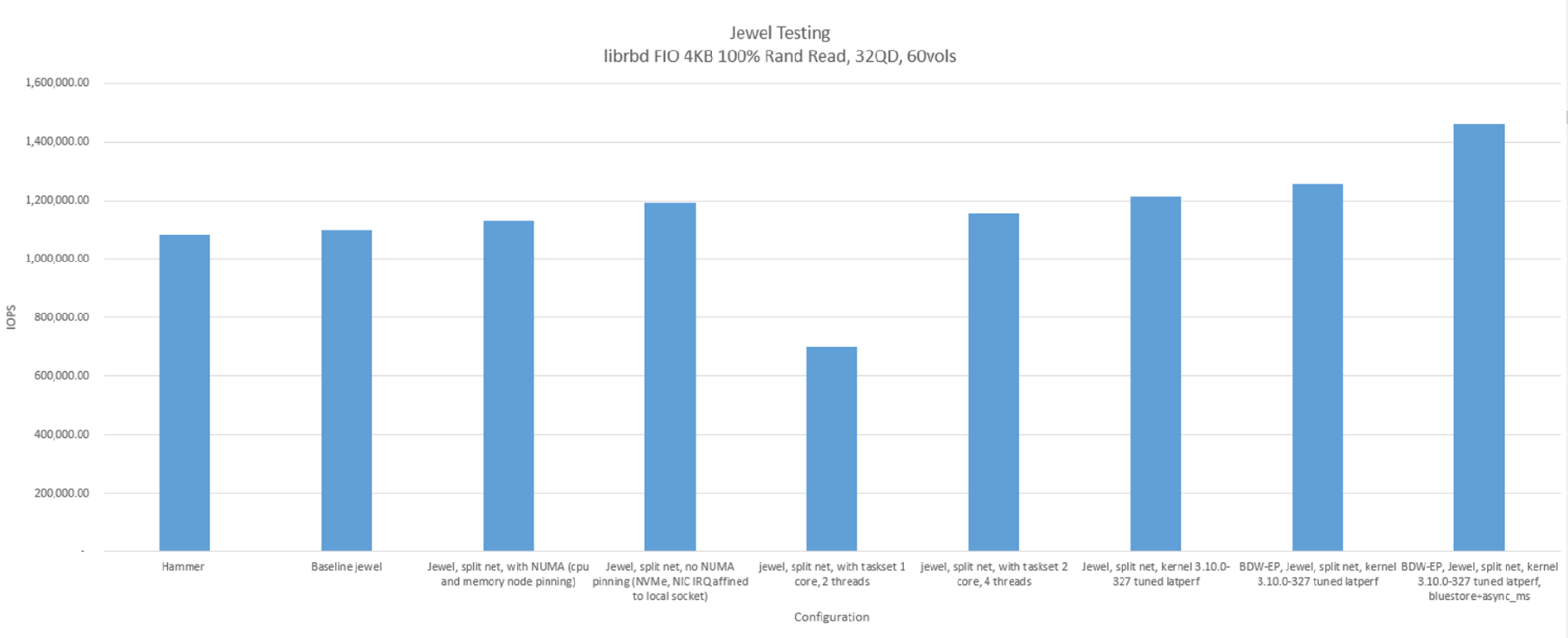
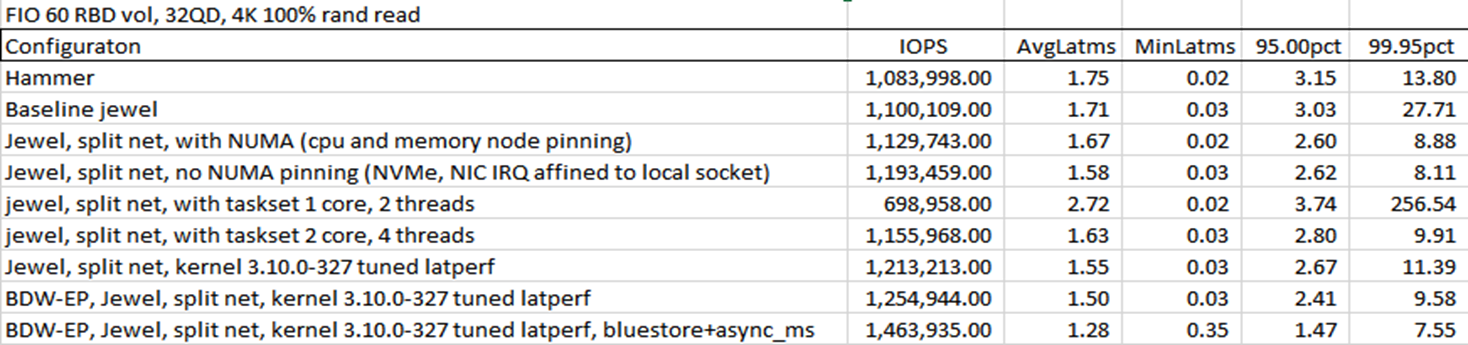
Figure 3: NUMA node performance compared to default system configuration
MEMORY TUNING
Ceph default packages use tcmalloc. For flash optimized configurations, we found jemalloc providing best possible performance without performance degradation over time. Ceph supports jemalloc for the hammer release and later releases but you need to build with jemalloc option enabled.
Below graph in figure 4 shows how thread cache size impacts throughput. By tuning thread cache size, performance is comparable between TCMalloc and JEMalloc. However as shown in Figure 5 and Figure 6, TCMalloc performance degrades over time unlike JEMalloc.
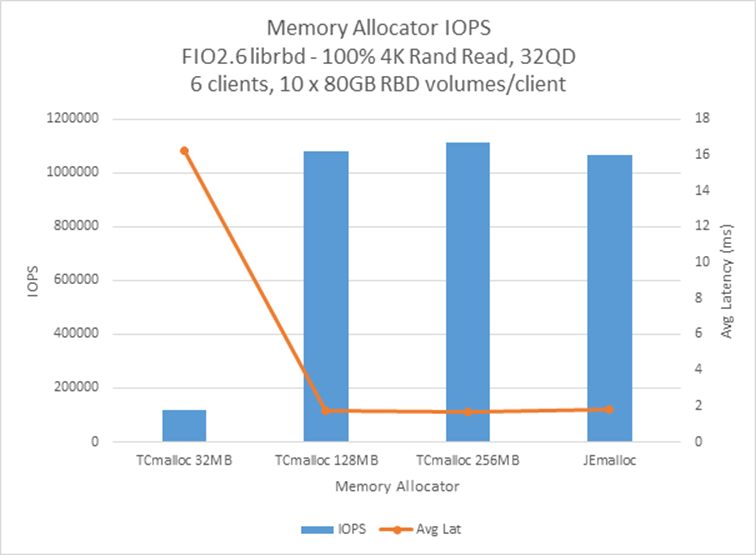
Figure 4: Thread cache size impact over performance
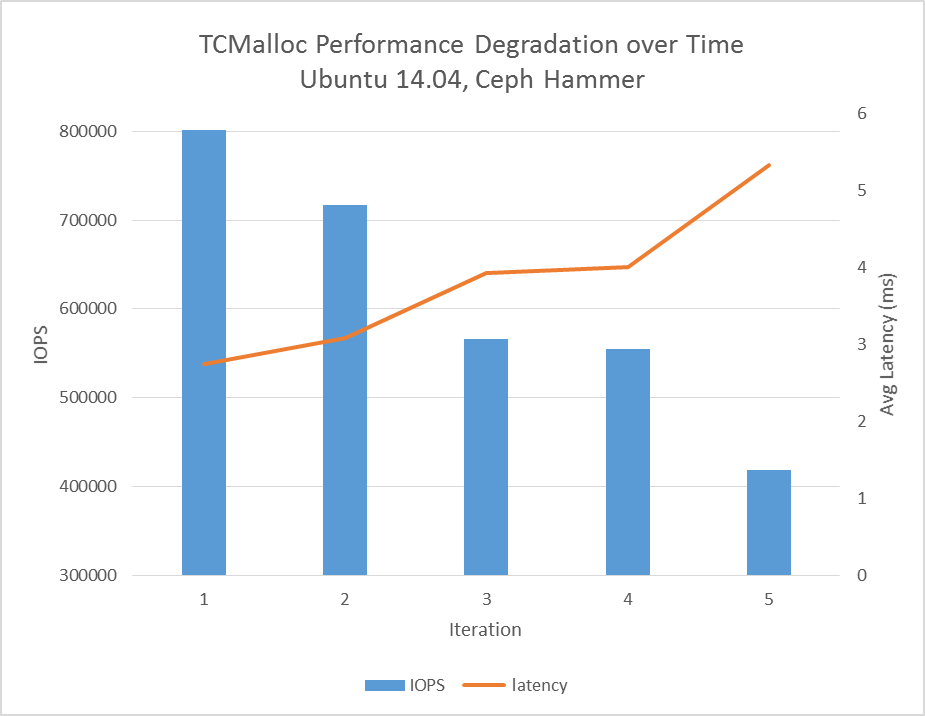
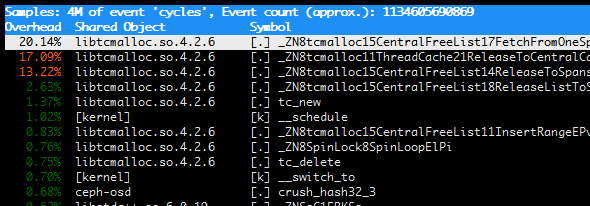
Figure 5: TCMalloc performance in a running cluster over time
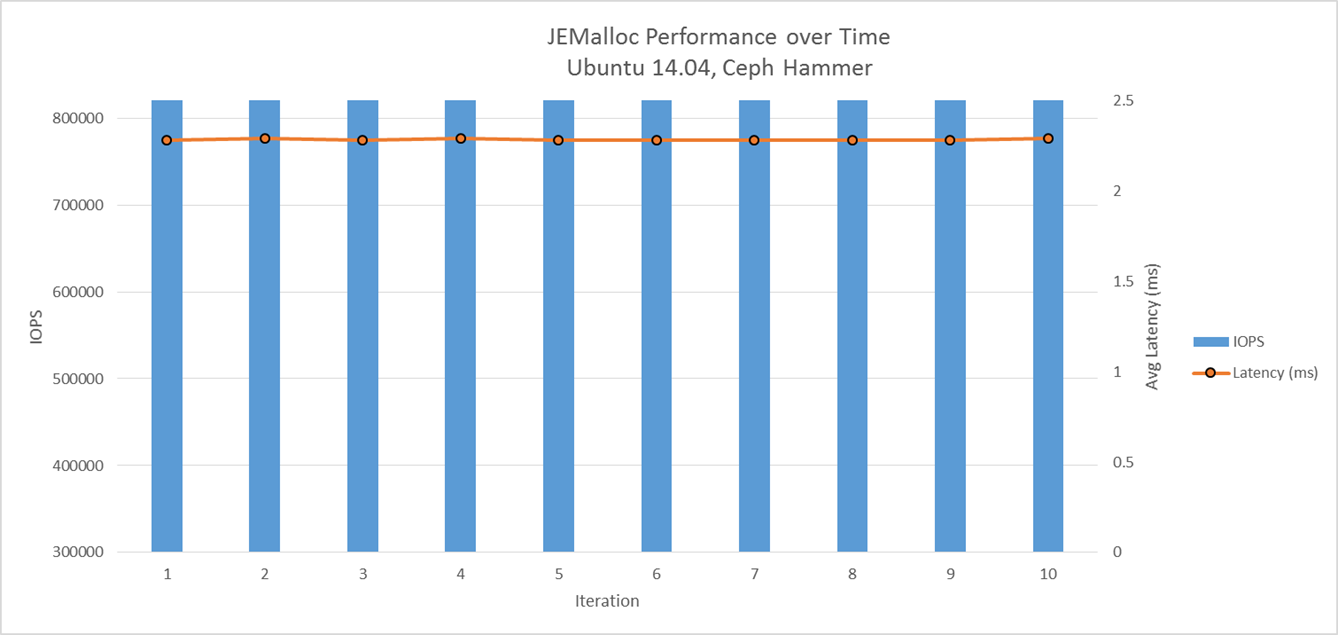
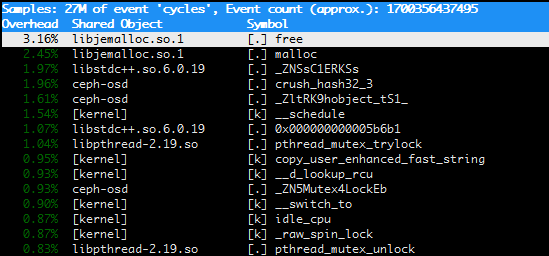
Figure 6: JEMalloc performance in a running cluster over time
NVME SSD PARTITIONING
It is not possible to take advantage of NVMe SSD bandwidth with single OSD. 4 is the optimum number of partitions per SSD drive that gives best possible performance.
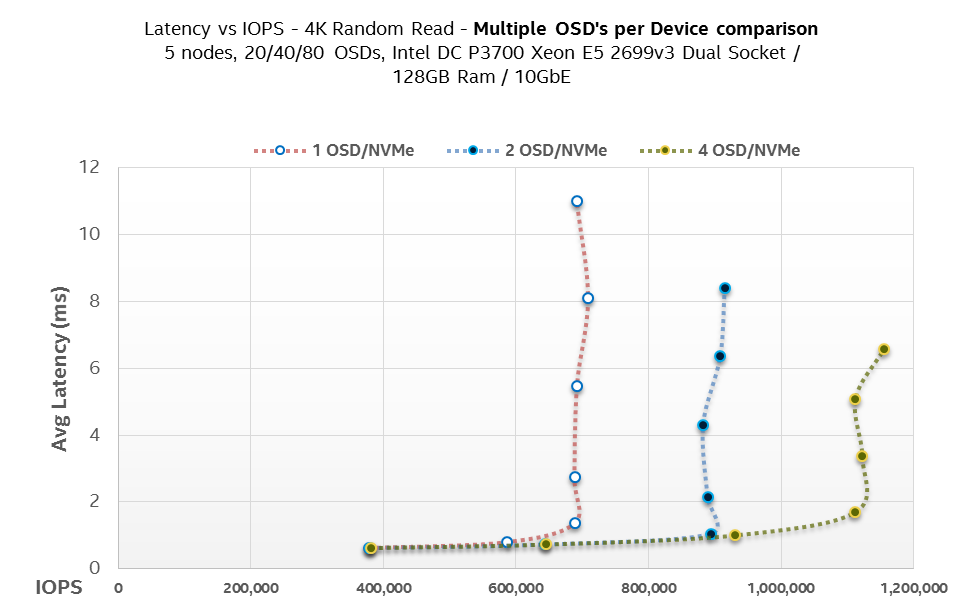
Figure 7: Ceph OSD latency with different SSD partitions
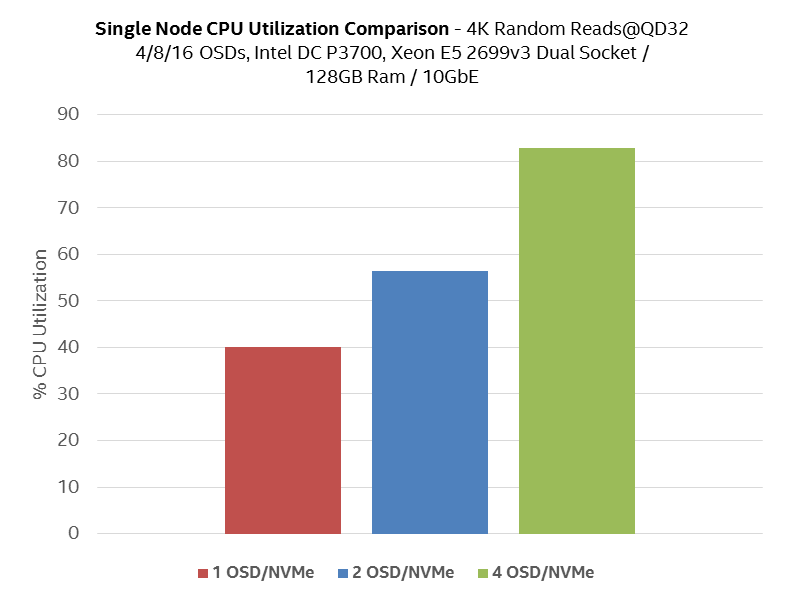
Figure 8: CPU Utilization with different #of SSD partitions
OS TUNING
(must be done on all Ceph nodes)
KERNEL TUNING
1. Modify system control in /etc/sysctl.conf
# Kernel sysctl configuration file for Red Hat Linux
#
# For binary values, 0 is disabled, 1 is enabled. See sysctl(8) and
# sysctl.conf(5) for more details. # Controls IP packet forwarding
net.ipv4.ip_forward = 0 # Controls source route verification
net.ipv4.conf.default.rp_filter = 1 # Do not accept source routing
net.ipv4.conf.default.accept_source_route = 0 # Controls the System Request debugging functionality of the kernel
kernel.sysrq = 0 # Controls whether core dumps will append the PID to the core filename.
# Useful for debugging multi-threaded applications.
kernel.core_uses_pid = 1 # disable TIME_WAIT.. wait ..
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1 # Controls the use of TCP syncookies
net.ipv4.tcp_syncookies = 0 # double amount of allowed conntrack
net.netfilter.nf_conntrack_max = 2621440
net.netfilter.nf_conntrack_tcp_timeout_established = 1800 # Disable netfilter on bridges.
net.bridge.bridge-nf-call-ip6tables = 0
net.bridge.bridge-nf-call-iptables = 0
net.bridge.bridge-nf-call-arptables = 0 # Controls the maximum size of a message, in bytes
kernel.msgmnb = 65536 # Controls the default maxmimum size of a mesage queue
kernel.msgmax = 65536 # Controls the maximum shared segment size, in bytes
kernel.shmmax = 68719476736 # Controls the maximum number of shared memory segments, in pages
kernel.shmall = 4294967296
2. IP jumbo frames
If your switch supports jumbo frames, then the larger MTU size is helpful. Our tests showed 9000 MTU improves Sequential Read/Write performance.
3. Set the Linux disk scheduler to cfq
FILESYSTEM CONSIDERATIONS
Ceph is designed to be mostly filesystem agnostic–the only requirement being that the filesystem supports extended attributes (xattrs). Ceph OSDs depend on the Extended Attributes (XATTRs) of the underlying file system for: a) Internal object state b) Snapshot metadata c) RGW Access control Lists etc. Currently XFS is the recommended file system. We recommend using big inode size (default inode size is 256 bytes) when creating the file system:
mkfs.xfs –i size=2048 /dev/sda1
Setting the inode size is important, as XFS stores xattr data in the inode. If the metadata is too large to fit in the inode, a new extent is created, which can cause quite a performance problem. Upping the inode size to 2048 bytes provides enough room to write the default metadata, plus a little headroom.
The following example mount options are recommended when using XFS:
mount -t xfs -o noatime,nodiratime,logbufs=8 /dev/sda1 /var/lib/Ceph/osd/Ceph-0
The following are specific recommendations for Intel SSD and Ceph.
mkfs.xfs -f -K -i size=2048 -s size=4096 /dev/md0
/bin/mount -o noatime,nodiratime/dev/md0 /data/mysql
DISK READ AHEAD
Read_ahead is the file prefetching technology used in the Linux operating system. It is a system call that loads a file's contents into the page cache. When a file is subsequently accessed, its contents are read from physical memory rather than from disk, which is much faster.
echo 2048 > /sys/block/${disk}/queue/read_ahead_kb (default 128)
| Per disk performance | 128 | 512 | Percentage |
| Sequential Read(MB/s) | 1232 MB/s | 3251 MB/s | +163% |
- 6 nodes Ceph cluster, each have 20 OSD (750 GB * 7200 RPM. 2.5’’ HDD)
OSD: RADOS
Tuning have significant performance impact of Ceph storage system, there are hundreds of tuning knobs for swift. We will introduce some of the most important tuning settings.
- Large PG/PGP number (since Cuttlefish)
We find using large PG number per OSD (>200) will improve the performance. Also this will ease the data distribution unbalance issue(default to 8)
ceph osd pool create testpool 8192 8192 - omap data on separate disks (since Giant)
Mounting omap directory to some separate SSD will improve the random write performance. In our testing we saw a ~20% performance improvement. - objecter_inflight_ops/objecter_inflight_op_bytes (since Cuttlefish)
objecter_inflight_ops/objecter_inflight_op_bytes throttles tell objecter to throttle outgoing ops according its budget, objecter is responsible for send requests to OSD. By default tweak this parameter to 10x(default to 1024/1024*1024*100)
objecter_inflight_ops = 10240
objecter_inflight_op_bytes = 1048576000 - ms_dispatch_throttle_bytes (since Cuttlefish)
ms_dispatch_throttle_bytes throttle is to throttle dispatch message size for simple messenger, by default tweak this parameter to 10x.ms_dispatch_throttle_bytes = 1048576000
- journal_queue_max_bytes/journal_queue_max_ops (since Cuttlefish)
journal_queue_max_bytes/journal_queue_max_op throttles are to throttle inflight ops for journal,
If journal does not get enough budget for current op, it will block osd op thread, by default tweak this parameter to 10x.journal_queueu_max_ops = 3000
journal_queue_max_bytes = 1048576000 - filestore_queue_max_ops/filestore_queue_max_bytes (since Cuttlefish)
filestore_queue_max_ops/filestore_queue_max_bytes throttle are used to throttle inflight ops for filestore, these throttles are checked before sending ops to journal, so if filestore does not get enough budget for current op, osd op thread will be blocked, by default tweak this parameter to 10x.filestore_queue_max_ops=5000
filestore_queue_max_bytes = 1048576000 - filestore_op_threads controls the number of filesystem operation threads that execute in parallel
If the storage backend is fast enough and has enough queues to support parallel operations, it’s recommended to increase this parameter, given there is enough CPU head room.filestore_op_threads=6
- journal_max_write_entries/journal_max_write_bytes (since Cuttlefish)
journal_max_write_entries/journal_max_write_bytes throttle are used to throttle ops or bytes for every journal write, tweaking these two parameters maybe helpful for small write, by default tweak these two parameters to 10xjournal_max_write_entries = 5000
journal_max_write_bytes = 1048576000 - osd_op_num_threads_per_shard/osd_op_num_shards (since Firefly)
osd_op_num_shards set number of queues to cache requests , osd_op_num_threads_per_shard is threads number for each queue, adjusting these two parameters depends on cluster.
After several performance tests with different settings, we concluded that default parameters provide best performance. - filestore_max_sync_interval (since Cuttlefish)
filestore_max_sync_interval control the interval that sync thread flush data from memory to disk, by default filestore write data to memory and sync thread is responsible for flushing data to disk, then journal entries can be trimmed. Note that large filestore_max_sync_interval can cause performance spike. By default tweak this parameter to 10 secondsfilestore_max_sync_interval = 10
- ms_crc_data/ms_crc_header (since Cuttlefish)
Disable crc computation for simple messenger, this can reduce CPU utilization - filestore_fd_cache_shards/filestore_fd_cache_size (since Firefly)
filestore cache is map from objectname to fd, filestore_fd_cache_shards set number of LRU Cache, filestore_fd_cache_size is cache size, tweak these two parameter maybe reduce lookup time of fd - Set debug level to 0 (since Cuttlefish)
For an all-SSD Ceph cluster, set debug level for sub system to 0 will improve the performance.debug_lockdep = 0/0
debug_context = 0/0
debug_crush = 0/0
debug_buffer = 0/0
debug_timer = 0/0
debug_filer = 0/0
debug_objecter = 0/0
debug_rados = 0/0
debug_rbd = 0/0
debug_journaler = 0/0
debug_objectcatcher = 0/0
debug_client = 0/0
debug_osd = 0/0
debug_optracker = 0/0
debug_objclass = 0/0
debug_filestore = 0/0
debug_journal = 0/0
debug_ms = 0/0
debug_monc = 0/0
debug_tp = 0/0
debug_auth = 0/0
debug_finisher = 0/0
debug_heartbeatmap = 0/0
debug_perfcounter = 0/0
debug_asok = 0/0
debug_throttle = 0/0
debug_mon = 0/0
debug_paxos = 0/0
debug_rgw = 0/0
RBD TUNING
To help achieve low latency on their RBD layer, we suggest the following, in addition to the CERN tuning referenced in ceph.com.
- echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor /dev/null
- start each ceph-osd in dedicated cgroup with dedicated cpu cores (which should be free from any other load, even the kernel one like network interrupts)
- increase “filestore_omap_header_cache_size” • “filestore_fd_cache_size” , for better caching (16MB for each 500GB of storage)
For disk entry in libvirt put address to all three ceph monitors.
RGW: RADOS GATEWAY TUNING
- Disable usage/access log (since Cuttlefish)
rgw enable ops log = false
rgw enable usage log = false
log file = /dev/nullWe find disabling usage/access log improves the performance.
- Using large cache size (since Cuttlefish)
rgw cache enabled = true
rgw cache lru size = 100000Caching the hot objects improves the GET performance.
- Using larger PG split/merge value. (since Firefly)
filestore_merge_threshold = 500
filestore_split_multiple = 100We find PG split/merge will introduce a big overhead. Using a large value would postpone the split/merge behavior. This will help the case where lots of small files are stored in the cluster.
- Using load balancer with multiple RGW instances (since Cuttlefish)
We’ve found that the RGW has some scalability issues at present. With a single RGW instance the performance is poor. Running multiple RGW instances with a load balancer (e.g., Haproxy) will greatly improve the throughput. - Increase the number of Rados handlers (since Hammer)
Since Hammer it’s able to using multiple number of Rados handlers per RGW instances. Increasing this value should improve the performance. - Using Civetweb frontend (since Giant)
Before Giant, Apache + Libfastcgi were the recommended settings. However libfastcgi still use the very old ‘select’ mode, which is not able to handle large amount of concurrent IO in our testing. Using Civetweb frontend would help to improve the stability.rgw frontends =civetweb port=80
- Moving bucket index to SSD (since Giant)
Bucket index updating maybe some bottleneck if there’s millions of objects in one single bucket. We’ve find moving the bucket index to SSD storage will improve the performance. - Bucket Index Sharding (since Hammer)
We’ve find the bucket index sharding is a problem if there’s large amount of objects inside one bucket. However the index listing speed may be impacted.
ERASURE CODING TUNING
- Use larger stripe width
The default erasure code stripe size (4K) is not optimal, We find using a bigger value (64K) will reduce the CPU% a lot (10%+)osd_pool_erasure_code_stripe_width = 65536
- Use mid-sized K
For the Erasure Code algorithms, we find using some mid-sized K value would bring balanced results between throughput and CPU%. We recommend to use 10+4 or 8+2 mode
APPENDIX
SAMPLE CEPH.CONF
[global]
fsid = 35b08d01-b688-4b9a-947b-bc2e25719370
mon_initial_members = gw2
mon_host = 10.10.10.105
filestore_xattr_use_omap = true
auth_cluster_required = none
auth_service_required = none
auth_client_required = none
debug_lockdep = 0/0
debug_context = 0/0
debug_crush = 0/0
debug_buffer = 0/0
debug_timer = 0/0
debug_filer = 0/0
debug_objecter = 0/0
debug_rados = 0/0
debug_rbd = 0/0
debug_journaler = 0/0
debug_objectcatcher = 0/0
debug_client = 0/0
debug_osd = 0/0
debug_optracker = 0/0
debug_objclass = 0/0
debug_filestore = 0/0
debug_journal = 0/0
debug_ms = 0/0
debug_monc = 0/0
debug_tp = 0/0
debug_auth = 0/0
debug_finisher = 0/0
debug_heartbeatmap = 0/0
debug_perfcounter = 0/0
debug_asok = 0/0
debug_throttle = 0/0
debug_mon = 0/0
debug_paxos = 0/0
debug_rgw = 0/0
[mon]
mon_pg_warn_max_per_osd=5000
mon_max_pool_pg_num=106496
[client]
rbd cache = false
[osd]
osd mkfs type = xfs
osd mount options xfs = rw,noatime,,nodiratime,inode64,logbsize=256k,delaylog
osd mkfs options xfs = -f -i size=2048
filestore_queue_max_ops=5000
filestore_queue_max_bytes = 1048576000
filestore_max_sync_interval = 10
filestore_merge_threshold = 500
filestore_split_multiple = 100
osd_op_shard_threads = 8
journal_max_write_entries = 5000
journal_max_write_bytes = 1048576000
journal_queueu_max_ops = 3000
journal_queue_max_bytes = 1048576000
ms_dispatch_throttle_bytes = 1048576000
objecter_inflight_op_bytes = 1048576000
public_network = 10.10.10.100/24
cluster_network = 10.10.10.100/24 [client.radosgw.gw2-1]
host = gw2
keyring = /etc/ceph/ceph.client.radosgw.keyring
rgw cache enabled = true
rgw cache lru size = 100000
rgw socket path = /var/run/ceph/ceph.client.radosgw.gw2-1.fastcgi.sock
rgw thread pool size = 256
rgw enable ops log = false
rgw enable usage log = false
log file = /dev/null
rgw frontends =civetweb port=80
rgw override bucket index max shards = 8
SAMPLE SYSCTL.CONF
fs.file-max = 6553600
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_fin_timeout = 20
net.ipv4.tcp_max_syn_backlog = 819200
net.ipv4.tcp_keepalive_time = 20
kernel.msgmni = 2878
kernel.sem = 256 32000 100 142
kernel.shmmni = 4096
net.core.rmem_default = 1048576
net.core.rmem_max = 1048576
net.core.wmem_default = 1048576
net.core.wmem_max = 1048576
net.core.somaxconn = 40000
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_max_tw_buckets = 10000
ALL-NVME CEPH CLUSTER TUNING FOR MYSQL WORKLOAD
CEPH.CONF
[global]
enable experimental unrecoverable data corrupting features = bluestore rocksdb
osd objectstore = bluestore
ms_type = async
rbd readahead disable after bytes = 0
rbd readahead max bytes = 4194304
bluestore default buffered read = true
auth client required = none
auth cluster required = none
auth service required = none
filestore xattr use omap = true
cluster network = 192.168.142.0/24, 192.168.143.0/24
private network = 192.168.144.0/24, 192.168.145.0/24
log file = /var/log/ceph/$name.log
log to syslog = false
mon compact on trim = false
osd pg bits = 8
osd pgp bits = 8
mon pg warn max object skew = 100000
mon pg warn min per osd = 0
mon pg warn max per osd = 32768
debug_lockdep = 0/0
debug_context = 0/0
debug_crush = 0/0
debug_buffer = 0/0
debug_timer = 0/0
debug_filer = 0/0
debug_objecter = 0/0
debug_rados = 0/0
debug_rbd = 0/0
debug_ms = 0/0
debug_monc = 0/0
debug_tp = 0/0
debug_auth = 0/0
debug_finisher = 0/0
debug_heartbeatmap = 0/0
debug_perfcounter = 0/0
debug_asok = 0/0
debug_throttle = 0/0
debug_mon = 0/0
debug_paxos = 0/0
debug_rgw = 0/0
perf = true
mutex_perf_counter = true
throttler_perf_counter = false
rbd cache = false
[mon]
mon data =/home/bmpa/tmp_cbt/ceph/mon.$id
mon_max_pool_pg_num=166496
mon_osd_max_split_count = 10000
mon_pg_warn_max_per_osd = 10000
[mon.a]
host = ft02
mon addr = 192.168.142.202:6789
[osd]
osd_mount_options_xfs = rw,noatime,inode64,logbsize=256k,delaylog
osd_mkfs_options_xfs = -f -i size=2048
osd_op_threads = 32
filestore_queue_max_ops=5000
filestore_queue_committing_max_ops=5000
journal_max_write_entries=1000
journal_queue_max_ops=3000
objecter_inflight_ops=102400
filestore_wbthrottle_enable=false
filestore_queue_max_bytes=1048576000
filestore_queue_committing_max_bytes=1048576000
journal_max_write_bytes=1048576000
journal_queue_max_bytes=1048576000
ms_dispatch_throttle_bytes=1048576000
objecter_infilght_op_bytes=1048576000
osd_mkfs_type = xfs
filestore_max_sync_interval=10
osd_client_message_size_cap = 0
osd_client_message_cap = 0
osd_enable_op_tracker = false
filestore_fd_cache_size = 64
filestore_fd_cache_shards = 32
filestore_op_threads = 6
CBT YAML
cluster:
user: "bmpa"
head: "ft01"
clients: ["ft01", "ft02", "ft03", "ft04", "ft05", "ft06"]
osds: ["hswNode01", "hswNode02", "hswNode03", "hswNode04", "hswNode05"]
mons:
ft02:
a: "192.168.142.202:6789"
osds_per_node: 16
fs: xfs
mkfs_opts: '-f -i size=2048 -n size=64k'
mount_opts: '-o inode64,noatime,logbsize=256k'
conf_file: '/home/bmpa/cbt/ceph.conf'
use_existing: False
newstore_block: True
rebuild_every_test: False
clusterid: "ceph"
iterations: 1
tmp_dir: "/home/bmpa/tmp_cbt"
pool_profiles:
2rep:
pg_size: 8192
pgp_size: 8192
replication: 2
benchmarks:
librbdfio:
time: 300
ramp: 300
vol_size: 10
mode: ['randrw']
rwmixread: [0,70,100]
op_size: [4096]
procs_per_volume: [1]
volumes_per_client: [10]
use_existing_volumes: False
iodepth: [4,8,16,32,64,128]
osd_ra: [4096]
norandommap: True
cmd_path: '/usr/local/bin/fio'
pool_profile: '2rep'
log_avg_msec: 250
MYSQL CONFIGURATION FILE (MY.CNF)
[client]
port = 3306
socket = /var/run/mysqld/mysqld.sock
[mysqld_safe]
socket = /var/run/mysqld/mysqld.sock
nice = 0
[mysqld]
user = mysql
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
port = 3306
datadir = /data
basedir = /usr
tmpdir = /tmp
lc-messages-dir = /usr/share/mysql
skip-external-locking
bind-address = 0.0.0.0
max_allowed_packet = 16M
thread_stack = 192K
thread_cache_size = 8
query_cache_limit = 1M
query_cache_size = 16M
log_error = /var/log/mysql/error.log
expire_logs_days = 10
max_binlog_size = 100M
performance_schema=off
innodb_buffer_pool_size = 25G
innodb_flush_method = O_DIRECT
innodb_log_file_size=4G
thread_cache_size=16
innodb_file_per_table
innodb_checksums = 0
innodb_flush_log_at_trx_commit = 0
innodb_write_io_threads = 8
innodb_page_cleaners= 16
innodb_read_io_threads = 8
max_connections = 50000
[mysqldump]
quick
quote-names
max_allowed_packet = 16M
[mysql]
!includedir /etc/mysql/conf.d/
SAMPLE CEPH VENDOR SOLUTIONS
The following are pointers to Ceph solutions, but this list is not comprehensive:
- https://www.dell.com/learn/us/en/04/shared-content~data-sheets~en/documents~dell-red-hat-cloud-solutions.pdf
- http://www.fujitsu.com/global/products/computing/storage/eternus-cd/
- http://www8.hp.com/h20195/v2/GetPDF.aspx/4AA5-2799ENW.pdf http://www8.hp.com/h20195/v2/GetPDF.aspx/4AA5-8638ENW.pdf
- http://www.supermicro.com/solutions/storage_ceph.cfm
- https://www.thomas-krenn.com/en/products/storage-systems/suse-enterprise-storage.html
- http://www.qct.io/Solution/Software-Defined-Infrastructure/Storage-Virtualization/QCT-and-Red-Hat-Ceph-Storage-p365c225c226c230
Notices:
Copyright © 2016 Intel Corporation. All rights reserved
Intel, the Intel logo, Intel Atom, Intel Core, and Intel Xeon are trademarks of Intel Corporation in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others.
Results have been estimated based on internal Intel analysis and are provided for informational purposes only. Any difference in system hardware or software design or configuration may affect actual performance.
Intel® Hyper-Threading Technology available on select Intel® Core™ processors. Requires an Intel® HT Technology-enabled system. Consult your PC manufacturer. Performance will vary depending on the specific hardware and software used. For more information including details on which processors support HT Technology, visit http://www.intel.com/info/hyperthreading.
Any software source code reprinted in this document is furnished under a software license and may only be used or copied in accordance with the terms of that license.
INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT.
A "Mission Critical Application" is any application in which failure of the Intel Product could result, directly or indirectly, in personal injury or death. SHOULD YOU PURCHASE OR USE INTEL'S PRODUCTS FOR ANY SUCH MISSION CRITICAL APPLICATION, YOU SHALL INDEMNIFY AND HOLD INTEL AND ITS SUBSIDIARIES, SUBCONTRACTORS AND AFFILIATES, AND THE DIRECTORS, OFFICERS, AND EMPLOYEES OF EACH, HARMLESS AGAINST ALL CLAIMS COSTS, DAMAGES, AND EXPENSES AND REASONABLE ATTORNEYS' FEES ARISING OUT OF, DIRECTLY OR INDIRECTLY, ANY CLAIM OF PRODUCT LIABILITY, PERSONAL INJURY, OR DEATH ARISING IN ANY WAY OUT OF SUCH MISSION CRITICAL APPLICATION, WHETHER OR NOT INTEL OR ITS SUBCONTRACTOR WAS NEGLIGENT IN THE DESIGN, MANUFACTURE, OR WARNING OF THE INTEL PRODUCT OR ANY OF ITS PARTS.
Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined". Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The information here is subject to change without notice. Do not finalize a design with this information.
The products described in this document may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request.
Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order.
http://tracker.ceph.com/projects/ceph/wiki/Tuning_for_All_Flash_Deployments
TUNING FOR ALL FLASH DEPLOYMENTS的更多相关文章
- Kafka Tuning Recommendations
Kafka Brokers per Server Recommend 1 Kafka broker per server- Kafka not only disk-intensive but can ...
- Car Flash ECU Programmer From autonumen
Whether you’re a home car owner or an auto mechanic — you can save thousands of dollars on car maint ...
- 隐私泄露杀手锏 —— Flash 权限反射
[简版:http://weibo.com/p/1001603881940380956046] 前言 一直以为该风险早已被重视,但最近无意中发现,仍有不少网站存在该缺陷,其中不乏一些常用的邮箱.社交网站 ...
- 百度 flash html5自切换 多文件异步上传控件webuploader基本用法
双核浏览器下在chrome内核中使用uploadify总有302问题,也不知道如何修复,之所以喜欢360浏览器是因为帮客户控制渲染内核: 若页面需默认用极速核,增加标签:<meta name=& ...
- 解决“chrome提示adobe flash player 已经过期”的小问题
这个小问题也确实困扰我许久,后来看到chrome吧里面有人给出了解决方案: 安装install_flash_player_ppapi, 该软件下载地址:http://labs.adobe.com/do ...
- Performance Tuning
本文译自Wikipedia的Performance tuning词条,原词条中的不少链接和扩展内容非常值得一读,翻译过程中暴露了个人工程学思想和英语水平的不足,翻译后的内容也失去很多准确性和丰富性,需 ...
- 在 Linux 中使用搜狗拼音输入法以及搞定 Flash 和支付宝
在 Ubuntu 中安装搜狗输入法 在 Ubuntu Kylin 系统中,默认安装搜狗拼音输入法,但是在原生 Ubuntu 系统中则不是.这可以理解,毕竟搜狗输入法的 Linux 版有 Kylin 团 ...
- [异常解决] ubuntukylin16.04 LTS中关于flash安装和使用不了的问题解决
http://www.linuxdiyf.com/linux/25211.html 归纳解决flash插件大法: 启动器中找到 软件更新,启动,点击 其它软件,把Canonical合作伙伴前方框 选上 ...
- 基于Adobe Flash平台的3D页游技术剖析
写在前面 从黑暗之光,佛本是道,大战神的有插件3D页游.再到如今的魔龙之戒. 足以证明,3D无插件正在引领页游技术的潮流. 目前,要做到3D引擎,有以下几个选择. 说到这里,我们发现.这些都不重要. ...
随机推荐
- Jmeter--BeanShell使用
博客首页:http://www.cnblogs.com/fqfanqi/ (一)BeanShell简介 BeanShell是一个小型嵌入式Java源代码解释器,具有对象脚本语言特性,能够动态地执行标准 ...
- 手动爬虫之京东笔记本栏(ptyhon3)
import urllib.request as ur import urllib.error as ue import re # 目标网址 url = 'https://list.jd.com/li ...
- centos7下搭建NFS服务器
NFS是Network File System的缩写,即网络文件系统.客户端通过挂载的方式将NFS服务器端共享的数据目录挂载到本地目录下. nfs为什么需要RPC?因为NFS支持的功能很多,不同功能会 ...
- salt常用命令、模块、执行
一.salt常用命令 salt 该命令执行salt的执行模块,通常在master端运行,也是我们最常用到的命令 salt [options] '<target>' <function ...
- [刷题]ACM ICPC 2016北京赛站网络赛 D - Pick Your Players
Description You are the manager of a small soccer team. After seeing the shameless behavior of your ...
- jquery实现滚动到页面底部时无限加载内容的代码
var p="{$other.p}"; if(p=="") p=1; var stop=true;//触发开关,防止多次调用事件 $(window).scrol ...
- Oracle数据库命令行下数据的导入导出
//设置导入导出字符集,导入导出都要设置一下 export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK //导出 exp system/oracle@orcl file=/u ...
- time/datetime/random/string/os/sys/shutil/zipfile/tarfile - 总结
time 模块: time.time() #时间戳 time.localtime() #当前时间对象元组 time.localtime(123123) #根据时间戳的时间对象 time.mktime( ...
- 【vim使用】
nano,与vim相似的一个文本编辑工具,在git merge时默认使用 https://www.vpser.net/manage/nano.html 这里介绍一下如何退出nano 按Ctrl+X 如 ...
- C#HTML与UBB(纯文本)之间的转换
private string HtmlToUBB(string _Html) { _Html = Regex.Replace(_Html,"<br ...