Ehcache概念篇
前言
缓存用于提供性能和减轻数据库负荷,本文在缓存概念的基础上对Ehcache进行叙述,经实践发现3.x版本高可用性不好实现,所以我采用2.x版本。
Ehcache是开源、基于缓存标准、基于java的缓存。
一、基本术语
- 缓存:维基词典将缓存定义为"存储将要被使用的东西,并且可以被快速检索"。缓存是一组临时数据,要么是其它地方的数据副本,或者是计算的结果。已经在缓存中的数据可以在时间和资源方面以最小的成本重复访问。
- 缓存条目:缓存条目由一个键和它在缓存中的映射数据值组成。
- 缓存命中:当从缓存请求数据元素时,对于给定的键存在元素,这被称为缓存命中。
- 缓存未命中:当从缓存请求数据元素时,对于给定的键不存在元素,这被称为缓存未命中。
- 记录系统:数据的权威性来源,存储层中的最底层。它通常是一种传统的数据库,可能是一个专门的文件系统或者其他可靠的长期存储。
- 驱逐:从缓存中删除条目,以便为较新的条目腾出空间(通常当缓存耗尽了数据存储容量时)。
- 过期:经过一段时间后,从缓存中删除条目,通常是为了避免缓存中的过时数据。
- 热数据:最近被应用程序使用的数据很可能很快就会被再次访问。这样的数据被认为是热门的。缓存可能会尝试将最热门的数据保存在速度最快的区域,同时尝试选择最不热门的数据来进行驱逐。
二、相关概念
1、数据新鲜度与过期
(1)数据新鲜度
数据新鲜度是指数据的副本(例如,在缓存中)与数据的源版本(例如,在记录系统中)相比的最新情况。一份过期的副本被认为是不同步的(或者很可能是不同步的)。
(2)缓存条目过期
Ehcache可以帮助您减少使用过期数据的可能性。在您的应用中配置缓存过期的方式和时间,一旦过期,该条目将自动从缓存中删除。目前支持的3种过期方式:
- no expiry:永不过期
- time-to-live:在条目创建后,超过了设定的时间将作过期处理
- time-to-idle:如果条目的最后一次访问时间离当前的时间超过了设定的时间长度,它将会作过期处理
2、存储层
(1)存储层介绍
You can configure Ehcache to use various data storage areas. When a cache is configured to use more than one storage area, those areas are arranged and managed as
tiers. They are organized in a hierarchy, with the lowest tier (farther) being called theauthoritytier and the others being part of thecachingtier (nearer, also callednear cache) . The caching tier can itself be composed of more than one storage area. The hottest data is kept in the caching tier, which is typically less abundant but faster than the authority tier. All the data is kept in the authority tier, which is slower but more abundant.Data stores supported by Ehcache include:
On-Heap Store - Utilizes Java’s on-heap RAM memory to store cache entries. This tier utilizes the same heap memory as your Java application, all of which must be scanned by the JVM garbage collector. The more heap space your JVM utilizes, the more your application performance will be impacted by garbage collection pauses. This store is extremely fast, but is typically your most limited storage resource.
Off-Heap Store - Limited in size only by available RAM. Not subject to Java garbage collection (GC). Is quite fast, yet slower than the On-Heap Store because data must be moved to and from the JVM heap as it is stored and re-accessed.
Disk Store - Utilizes a disk (file system) to store cache entries. This type of storage resource is typically very abundant but much slower than the RAM-based stores. As for all application using disk storage, it is recommended to use a fast and dedicated disk to optimize the throughput.
Clustered Store - This data store is a cache on a remote server. The remote server may optionally have a failover server providing improved high availability. Since clustered storage comes with performance penalties due to such factors as network latency as well as for establishing client/server consistency, this tier, by nature, is slower than local off-heap storage.
译:存储层中的最底层被命名为权威层(
authoritytier ,资源量最丰富的层),一般是磁盘存储层(Disk Tier)或集群存储层(Clustered Tier),其它更近访问更快的层有堆内存储层(Heap tier)和堆外存储层(Off Heap Tier)Ehcache支持的数据存储包括:
- 堆内存储 - 利用Java的堆内存来存储缓存条目。使用与Java应用程序相同的由JVM垃圾收集器管理的堆内存。JVM使用的堆空间越多,应用程序性能受到的垃圾收集暂停影响越大。此存储最快但空间最小。
- 堆外存储 - 只有可用RAM限制大小。不受Java垃圾收集(GC)的影响。它的速度非常快,但比堆内存储要慢,因为数据的存储和重新访问的都要经过堆内存储层。
- 磁盘存储 - 利用磁盘(文件系统)来存储缓存条目。这种类型的存储资源通常非常丰富,但是比基于ram的存储要慢得多。对于使用磁盘存储的所有应用程序,建议使用一个快速且专用的磁盘来优化吞吐量。
- 集群存储 - 这个数据存储是远程服务器上的一个缓存。远程服务器可以有选择地提供一个故障转移服务器使可用性更高。集群存储由于网络延迟和建立客户机/服务器一致性等因素而受到性能的惩罚,因此这一层的性能比本地的堆外存储要慢。
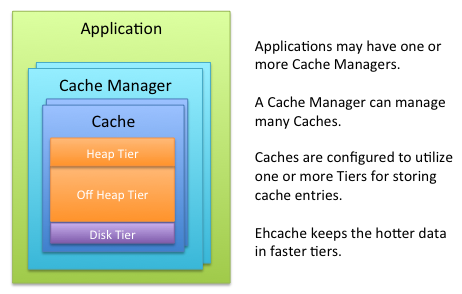
(2)Ehcache在多存储层中的操作流程图
Sequence Flow for Cache Operations with Multiple Tiers
In order to understand what happens for different cache operations when using multiple tiers, here are examples of Put and Get operations. The sequence diagrams are oversimplified but still show the main points.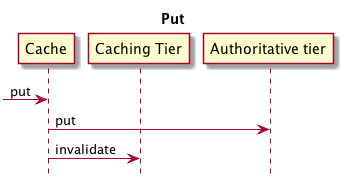
Figure 2. Multiple tiers using Put
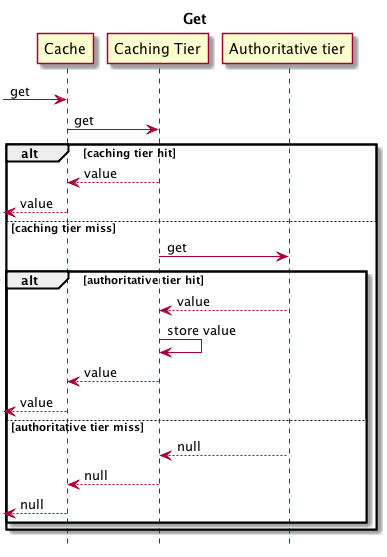
Figure 3. Multiple tiers using Get
You should then notice the following:
When putting a value into the cache, it goes straight to the authoritative tier, which is the lowest tier.
A following
getwill push the value upwards in the caching tiers.Of course, as soon as a value is put in the authoritative tier, all higher-level caching tiers are invalidated.
A full cache miss (the value isn’t on any tier) will always go all the way down to the authoritative tier.
译:为了理解在使用多个层时不同的缓存操作会发生什么情况,图为Put和Get操作的示例。序列图过于简化,但仍然显示了要点。
你应该注意到以下几点:
- 当将一个值放入缓存时,它会直接转到权威层,这是最底层。
- get将在缓存层中向上推送值。
- 一旦将值放入到权威层中,所有更近的缓存层都将失效。
- 缓存丢失(值不在任何层上)总是会一直向下获取直到权威层。
3、拓扑类型
(1)独立拓扑
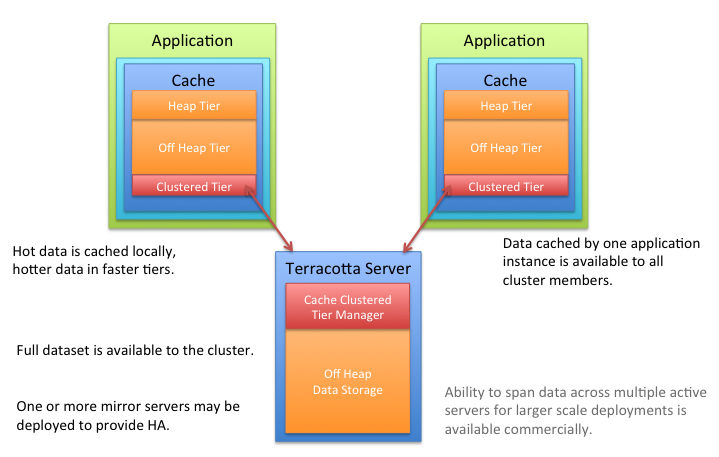
普遍来说,许多生产的应用程序都可以部署在多个实例的集群中,以获得可用性和可伸缩性。然而,如果没有分布式缓存,应用程序集群会出现许多不符合需求的行为,例如:
缓存偏移 - 如果每个应用程序实例维护自己的缓存,那么对一个缓存的更新将不会出现在其他实例中。分布式缓存确保了所有的缓存实例保持同步。
数据库瓶颈 - 在单实例应用程序中,缓存有效地保护了数据库免受冗余查询的开销。但是,在分布式应用程序环境中,每个实例必须加载并保持其缓存的新鲜度。当添加更多的应用程序实例时,加载和刷新多个缓存的开销会导致数据库瓶颈。分布式缓存消除了从数据库中加载和刷新多个缓存的开销。
三、缓存的使用模式
在使用缓存时,有几种常见的访问模式。Ehcache支持以下模式:
Cache-aside(应用程序直接操作缓存与数据库数据,由应用程序保证缓存的有效性)
应用程序代码首先查询缓存,如果缓存包含数据,则直接从缓存中返回数据。否则,应用程序代码必须从数据库中获取数据,将数据存储在缓存中,然后返回它。当写入数据时,先更新数据库,更新成功之后再更新缓存。Cache-as-SoR(应用程序只能看见缓存,缓存层有自己的加载和写入组件,负责与数据库的交互。直接翻译就是把缓存层当做数据库用了 )
实现Cache-as-SoR可以使用以下的读和写模式的组合Read-through
这种模式配有一个数据库加载组件,负责将从数据库中加载数据。获取数据时,如果在缓存中找不到,则会调用加载组件从数据库中检索数据,将获取到的数据存储在缓存中,然后返回它。下一次当缓存被请求为同一个键时,它可以从缓存中返回,而不需要使用加载组件(除非该条目已被清除或过期)。Write-through
这种模式配有一个数据库写入组件,负责将数据写入到数据库中。当要写入数据时,缓存将调用写入组件来存储到数据库中,并更新缓存。Write-behind
将缓存更新的数据存放队列中,然后定时批量从队列中取出数据更新数据库。
ehcache官网:http://www.ehcache.org/
Ehcache概念篇的更多相关文章
- 【转】android 电容屏(二):驱动调试之基本概念篇
关键词:android 电容屏 tp 工作队列 中断 多点触摸协议平台信息:内核:linux2.6/linux3.0系统:android/android4.0 平台:S5PV310(samsung ...
- 我的TDD实践---TDD概念篇
“我的TDD实践”系列之TDD概念篇 写在前面: 我的TDD实践这几篇文章主要是围绕测试驱动开发所展开的,其中涵盖了一小部分测试理论,更多的则是关注工具的使用及环境的搭建,做到简单实践先行,后理论专精 ...
- DNA拷贝数变异CNV检测——基础概念篇
DNA拷贝数变异CNV检测——基础概念篇 一.CNV 简介 拷贝数异常(copy number variations, CNVs)是属于基因组结构变异(structural variation), ...
- 【黑金原创教程】 FPGA那些事儿《概念篇》
简介一本讲述非软硬片上系统的书,另外还是低级建模的使用手册. 目录[黑金原创教程] FPGA那些事儿<概念篇>:File01 - 结构的玩笑[黑金原创教程] FPGA那些事儿<概念篇 ...
- 常见面试题整理--Python概念篇
希望此文可以长期更新并作为一篇Python的面试宝典.每一道题目都附有详细解答,以及更加详细的回答链接.此篇是概念篇,下一篇会更新面试题代码篇. (一).这两个参数是什么意思:*args,**kwar ...
- Linux Capabilities 入门教程:概念篇
原文链接:Linux Capabilities 入门教程:概念篇 Linux 是一种安全的操作系统,它把所有的系统权限都赋予了一个单一的 root 用户,只给普通用户保留有限的权限.root 用户拥有 ...
- 【转帖】H5 手机 App 开发入门:概念篇
H5 手机 App 开发入门:概念篇 http://www.ruanyifeng.com/blog/2019/12/hybrid-app-concepts.html 作者: 阮一峰 日期: 2019年 ...
- 鸿蒙内核源码分析(文件概念篇) | 为什么说一切皆是文件 | 百篇博客分析OpenHarmony源码 | v62.01
百篇博客系列篇.本篇为: v62.xx 鸿蒙内核源码分析(文件概念篇) | 为什么说一切皆是文件 | 51.c.h.o 本篇开始说文件系统,它是内核五大模块之一,甚至有Linux的设计哲学是" ...
- 鸿蒙内核源码分析(中断概念篇) | 海公公的日常工作 | 百篇博客分析OpenHarmony源码 | v43.02
百篇博客系列篇.本篇为: v43.xx 鸿蒙内核源码分析(中断概念篇) | 海公公的日常工作 | 51.c.h .o 硬件架构相关篇为: v22.xx 鸿蒙内核源码分析(汇编基础篇) | CPU在哪里 ...
随机推荐
- C语言顺序表
顺序表结构可设为一个数组和一个指向尾部的变量,数组用来存放元素,指向尾部的变量在插入元素的时候加一,删除元素的时候减一,始终指向尾部. typedef int elemtype; typedef st ...
- 安装cuda9.0+cudnn v7+python3.5.3+tensorflow
本机设备 windows10 gtx1060 安装软件及下载地址 python-3.5.3-amd64 链接:https://pan.baidu.com/s/1I3oIDatMgvDLEtaPtvu ...
- 北京Uber优步司机奖励政策(3月19日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 北京Uber优步司机奖励政策(3月2日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 2 引用 深copy 浅copy
1. is == 总结 is 是比较两个引用是否指向了同一个对象(引用比较). == 是比较两个对象是否相等. In [1]: a = [11,22,33] In [2]: b = [11,22,33 ...
- zabbix经常报警elasticsearch节点TCP连接数过高问题
单服务器最大tcp连接数及调优汇总 单机最大tcp连接数 网络编程 在tcp应用中,server事先在某个固定端口监听,client主动发起连接,经过三路握手后建立tcp连接.那么对单机,其最大并发t ...
- CakePHP模型中使用join的多种写法
Cake写法 App::import("Model","Client"); $this->Client = & new Client(); $th ...
- JS日期转换
用js将从后台得到的时间戳(毫秒数)转换为想要的日期格式 得到后台从数据库中拿到的数据我们希望格式是 2016年10月25日 17时37分30秒 或者 2016/10/25 17:37:30 然而我们 ...
- PostFix支持SMTP认证
安装cyrus-sasl yum -y install cyrus-sasl* 启动服务,开机启动 service saslauthd start chkconfig saslauthd on 配置p ...
- meta-data获取小结
android 开发中: 在AndroidManifest.xml中,<meta-data>元素可以作为子元素, 被包含在<activity>.<applicat ...