drf ( 学习第四部 )
目录
分页Pagination
安装依赖
设置接口文档访问路径
访问接口文档网页
列表页配置
详情页配置
安装
站点的全局配置
DRF框架中常用的组件
分页Pagination
REST framework 提供了分页的支持. 我们可以在配置文件中设置全局的分页方式,如:
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 100 # 每页数目
}
如果在配置settings.py文件中, 设置了全局分页,那么在drf中凡是调用了ListModelMixin的list(),都会自动分页。如果项目中出现大量需要分页的数据,只有少数部分接口不需要分页,则可以在少部分的视图类中关闭分页功能。
class 视图类(ListAPIView):
pagination_class = None
也可以通过自定义P阿覅nation类 ,来为视图添加不同分页行为. 在视图中通过 pagination_class属性来指明.
class LargeResultsSetPagination(PageNumberPagination):
page_size = 1000
page_size_query_param = 'page_size'
max_page_size = 10000
class BookDetailView(RetrieveAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
pagination_class = LargeResultsSetPagination
可选分页器
! ) PagiNumberPagination
前端访问网址形式:
GET http://127.0.0.1:8000/students/?page=4
可以在子类中定义的属性:
- page_size 每页数目
- page_query_param 前端发送的页数关键字名, 默认为 ' page'
- page_size_query_param 前端发送的每页数目关键字名, 默认为None
- max_page_size 前端最多能设置的每页数量
# 声明分页的配置类
from rest_framework.pagination import PageNumberPagination
class StandardPageNumberPagination(PageNumberPagination):
# 默认每一页显示的数据量
page_size = 2
# 允许客户端通过get参数来控制每一页的数据量
page_size_query_param = "size"
max_page_size = 10
# 自定义页码的参数名
page_query_param = "p" class StudentAPIView(ListAPIView):
queryset = Student.objects.all()
serializer_class = StudentModelSerializer
pagination_class = StandardPageNumberPagination # 127.0.0.1/four/students/?p=1&size=5
2 ) LinitOffsetPagination
前端访问网址形式:
GET http://127.0.0.1/four/students/?limit=100&offset=100
可以在子类中定义的属性:
default默认限制, 默认值与 PAGE_SIZE 设置一致
- limit_query_param limit参数名,默认'limit'
- offset_query_param offset参数名, 默认 ' offset'
- max_limit 最大limit限制, 默认None
from rest_framework.pagination import LimitOffsetPagination
class StandardLimitOffsetPagination(LimitOffsetPagination):
# 默认每一页查询的数据量,类似上面的page_size
default_limit = 2
limit_query_param = "size"
offset_query_param = "start" class StudentAPIView(ListAPIView):
queryset = Student.objects.all()
serializer_class = StudentModelSerializer
# 调用页码分页类
# pagination_class = StandardPageNumberPagination
# 调用查询偏移分页类
pagination_class = StandardLimitOffsetPagination
异常处理Exceptions
REST framework 提供了自定义异常处理, 我们可以自定义的方式来编写异常处理函数. 例如我们想要在要创建一个自定义异常函数.
这个函数, 我们保存到当前主应用中( 注意在实际工作中, 我们可以设置一个单独的独立的公共目录来保存这种公共的函数/工具/类库 ) .
drfemo/exceptions.py, 代码:
"""自定义异常"""
# drf内置的异常处理,仅仅针对于API接口进行异常处理,不是api出错,则不识别,不处理
from rest_framework.views import exception_handler as drf_exception_handler
from django.db import DatabaseError
from rest_framework.response import Response
from rest_framework import status
from django.core.exceptions import ImproperlyConfigured
def custom_exception_handler(exc,context):
"""
自定义异常处理函数
:param exc: 异常对象,本次发生的异常对象
:param context: 字典,异常出现时的执行上下文环境
:return:
"""
# 返回值要么是报错的响应信息,要么就是None
response = drf_exception_handler(exc,context) if response is None:
if isinstance(exc, DatabaseError):
# 数据库异常
# 一般先进行日志的记录
# 然后才返回给客户端
response = Response({"detail":"数据库异常"}, status=status.HTTP_507_INSUFFICIENT_STORAGE) # 其他的异常处理
if isinstance(exc, Exception):
response = Response({"detail":"数据访问出错"}, status=status.HTTP_500_INTERNAL_SERVER_ERROR) return response
在主应用的配置文件settings.py 中声明自定义的异常处理
REST_FRAMEWORK = {
# 异常处理
'EXCEPTION_HANDLER': 'drfdemo.exceptions.custom_exception_handler',
}
如果未声明, 会采用默认的方式, 如下:
rest_framework/settings.py
REST_FRAMEWORK = {
'EXCEPTION_HANDLER': 'rest_framework.views.exception_handler'
}
REST framework 定义的异常
- APIException drf中所有异常的父类
- ParseError 解析错误
- AuthenticationFailed 认证失败
- NotAuthenticated 尚未认证
- PermissionDenied 权限受限
- NotFound 未找到
- MethodNotAllowed 请求方式不支持
- NotAcceptable 要获取的数据格式不支持
- Throttled 超过限流次数
- ValidationError 校验失败
也就是说, 很多的没有在上面列出来的异常,就需要我们在自定义异常中子处理了.
自动生成接口文档
官方文档:http://core-api.github.io/python-client/
REST framework可以自动帮助我们生成接口文档。
接口文档以网页的方式呈现。
自动接口文档能生成的是继承自APIView及其子类的视图。
安装依赖
REST framework 生成接口文档需要 core挨批 库的支持
pip install coreapi
设置接口文档访问路径
在settings.py中配置接口文档
REST_FRAMEWORK = {
# 。。。 其他选项
# 接口文档
'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.AutoSchema',
}
在总路由中添加接口文档路径.
文档路由对应的视图配置为:
`rest_framework.documentation.include_docs_urls`
参数title 为接口文档网站的标题.
from rest_framework.documentation import include_docs_urls urlpatterns = [
...
path('docs/', include_docs_urls(title='站点页面标题'))
]
文档描述说明的定义位置
1 ) 单一方法的视图, 可直接使用类视图的文档字符串, 如:
class BookListView(generics.ListAPIView):
"""
返回所有图书信息.
"""
2 ) 包含多个方法的视图, 在类视图的文档字符串中, 分开方法定义, 如:
class BookListCreateView(generics.ListCreateAPIView):
"""
get:
返回所有图书信息. post:
新建图书.
"""
3 ) 对于视图集ViewSet , 仍在类视图的文档字符串中分开定义, 但是应使用action名称区分, 如:
class BookInfoViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet):
"""
list:
返回图书列表数据 retrieve:
返回图书详情数据 latest:
返回最新的图书数据 read:
修改图书的阅读量
"""
访问接口文档网页
浏览器访问 127.0.0.1:8000/docs/ , 即可看到自动生成的接口文档.
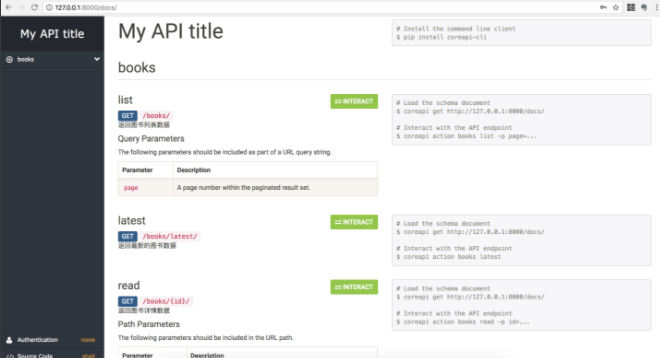
俩点说明:
1 ) 视图集ViewSet的 retrieve 名称, 在接口文档网站中叫做read
2 ) 函数的Description需要在模型类或者序列化器类的字段中以 help_text选项定义,如:
class Student(models.Model):
...
age = models.IntegerField(default=0, verbose_name='年龄', help_text='年龄')
...
或者:
class StudentSerializer(serializers.ModelSerializer):
class Meta:
model = Student
fields = "__all__"
extra_kwargs = {
'age': {
'required': True,
'help_text': '年龄'
}
}
Admin
django内置了一个强大的组件叫Admin, 提供给网站管理员快速开发运营后台的管理站点.
站点文档: https://docs.djangoproject.com/zh-hans/2.2/ref/contrib/admin/
辅助文档: https://www.runoob.com/django/django-admin-manage-tool.html
注意:要使用Admin,必须先创建超级管理员. python manage.py createsuperuser
访问地址: http://127.0.0.1:8000/admin,访问效果如下:
admin 站点默认并没有提供其他的操作给我们,所以一切功能都需要我们进行配置, 在项目中,我们每次创建子应用的时候都会存在一个admin,朋友文件. 这个文件就是用于配置admin站点功能的文件.
admin, py 里面允许我们编写的代码一共可以分成2部分:
列表页配置
主要用于针对项目中各个子应用里面的model.py里面的模型, 根据这些模型自动生成后台运营站点的管理功能.
from django.contrib import admin
from .models import Student
class StudentModelAdmin(admin.ModelAdmin):
"""学生模型管理类"""
pass # admin.site.register(模型类, 模型管理类)
admin.site.register(Student, StudentModelAdmin)
关于列表的配置吗代码:
from django.contrib import admin
from .models import Student
class StudentModelAdmin(admin.ModelAdmin):
"""学生模型管理类"""
date_hierarchy = 'born' # 按指定时间字段的不同值来进行选项排列
list_display = ['id', "name", "sex", "age", "class_num","born","my_born"] # 设置列表页的展示字段
ordering = ['-id'] # 设置默认排序字段,字段前面加上-号表示倒叙排列
actions_on_bottom = True # 下方控制栏是否显示,默认False表示隐藏
actions_on_top = True # 上方控制栏是否显示,默认False表示隐藏
list_filter = ["class_num"] # 过滤器,按指定字段的不同值来进行展示
search_fields = ["name"] # 搜索内容 def my_born(self,obj):
return str(obj.born).split(" ")[0] my_born.short_description = "出生日期" # 自定义字段的描述信息
my_born.admin_order_field = "born" # 自定义字段点击时使用哪个字段作为排序条件 # admin.site.register(模型类, 模型管理类)
admin.site.register(Student, StudentModelAdmin)
详情页配置
from django.contrib import admin
from .models import Student
class StudentModelAdmin(admin.ModelAdmin):
"""学生模型管理类"""
date_hierarchy = 'born' # 按指定时间字段的不同值来进行选项排列
list_display = ['id', "name", "sex", "age", "class_null","born","my_born"] # 设置列表页的展示字段
ordering = ['-id'] # 设置默认排序字段,字段前面加上-号表示倒叙排列
actions_on_bottom = True # 下方控制栏是否显示,默认False表示隐藏
actions_on_top = True # 上方控制栏是否显示,默认False表示隐藏
list_filter = ["class_null"] # 过滤器,按指定字段的不同值来进行展示
search_fields = ["name"] # 搜索内容 def my_born(self,obj):
return str(obj.born).split(" ")[0] my_born.short_description = "出生日期" # 自定义字段的描述信息
my_born.admin_order_field = "born" # 自定义字段点击时使用哪个字段作为排序条件 def delete_model(self, request, obj):
"""当站点删除当前模型时执行的钩子方法"""
print("有人删除了模型信息[添加/修改]") # raise Exception("无法删除") # 阻止删除
return super().delete_model(request, obj) # 继续删除 def save_model(self, request, obj, form, change):
"""
当站点保存当前模型时
"""
print("有人修改了模型信息[添加/修改]")
# 区分添加和修改? obj是否有id
print(obj.id)
return super().save_model(request, obj, form, change) # fields = ('name', 'age', 'class_null', "description") # exclude 作用与fields相反
# readonly_fields = ["name"] # 设置只读字段 # 字段集,fieldsets和fields只能使用其中之一
fieldsets = (
("必填项", {
'fields': ('name', 'age', 'sex')
}),
('可选项', {
'classes': ('collapse',), # 折叠样式
'fields': ('class_null', 'description'),
}),
) # admin.site.register(模型类, 模型管理类)
admin.site.register(Student, StudentModelAdmin)
Xadmin
下点敏是Django 的第三方扩展, 是一个比Django的admin站点使用更方便的后台站点,.构建于admin站点之上.
文档: http://sshwsfc.github.io/xadmin/
https://xadmin.readthedocs.io/en/latest/index.html
安装
通过如下命令安装xadmin的最新版
pip install https://codeload.github.com/sshwsfc/xadmin/zip/django2
在配置文件settings.py中注册如下应用:
INSTALLED_APPS = [
...
'xadmin',
'crispy_forms',
'reversion',
...
] # 修改使用中文界面
LANGUAGE_CODE = 'zh-Hans' # 修改时区
TIME_ZONE = 'Asia/Shanghai'
xadmin有建立自己的数据库模型类, 需要进行数据刻苦迁移
python manage.py makemigrations
python manage.py migrate
在总路由中添加xadmin的路由信息
import xadmin
xadmin.autodiscover() # version模块自动注册需要版本控制的 Model
from xadmin.plugins import xversion
xversion.register_models() urlpatterns = [
path('xadmin/', xadmin.site.urls),
]
创建超级用户
python manage.py createsuperuser
使用
- xadmin不用使用Django的admin.py 进行功能配置乐乐, 而是需要编写代码在admin.py文件中.
- xadmin的站点管理类不用继承 admin.ModelAdmin, 而是直接继承 object 即可
例如: 在子应用 students 中创建 admin.py文件.
站点的全局配置
import xadmin
from xadmin import views class BaseSetting(object):
"""xadmin的基本配置"""
enable_themes = True # 开启主题切换功能
use_bootswatch = True xadmin.site.register(views.BaseAdminView, BaseSetting) class GlobalSettings(object):
"""xadmin的全局配置"""
site_title = "路飞学城" # 设置站点标题
site_footer = "路飞学城有限公司" # 设置站点的页脚
menu_style = "accordion" # 设置菜单折叠 xadmin.site.register(views.CommAdminView, GlobalSettings)
站点Model管理
xadmin可以使用的页面样式控制基本与Django原生的admin一致.
- list_display 控制列表展示的字段
list_display = ['id', 'title', 'read', 'comment']
- search_fields控制可以通过搜索框搜索的字段名称, xadmin使用的是模糊查询
search_fields = ['id','title']
- list_filter 可以进行过滤操作的列, 对于分类, 性别,状态
list_filter = ['is_delete']
- ordering默认排序的字段
- readonly_fields在编辑页面的只读字段
- exclude 在编辑页面隐藏的字段
- list_editable 在列表页可以快速直接编写的字段
- show_detail_fields 在列表页提供快速显示详情信息
- refresh_times 指定列表页的定时刷新
refresh_times = [5, 10,30,60] # 设置允许后端管理人员按多长时间(秒)刷新页面
- list_export 控制列表导出数据的可选格式
list_export = ('xls', 'xml', 'json') list_export设置为None来禁用数据导出功能
list_export_fields = ('id', 'title', 'pub_date') # 允许导出的字段
- show_bookmarks 控制是否显示书签功能
show_bookmarks = True
- data_charts 控制显示图表的样式
data_charts = {
"order_amount": {
'title': '图书发布日期表',
"x-field": "bpub_date",
"y-field": ('btitle',),
"order": ('id',)
},
# 支持生成多个不同的图表
# "order_amount": {
# 'title': '图书发布日期表',
# "x-field": "bpub_date",
# "y-field": ('btitle',),
# "order": ('id',)
# },
}- title 控制图标名称
- x-field 控制x 轴字段
- y-field 控制y 轴字段, 可以是多个值
- order 控制默认排序
- model_icon 控制菜单的图标
这里使用的图标是来自 bootstrap3 的图标. https://v3.bootcss.com/components/
class BookInfoAdmin(object):
model_icon = 'fa fa-gift' xadmin.site.register(models.BookInfo, BookInfodmin)
修改admin或者下低敏站点下的子应用成中文内容.
# 在子应用的apps.py下面的配置中,新增一个属性verbose_name
from django.apps import AppConfig class StudentsConfig(AppConfig):
name = 'students'
verbose_name = "学生管理" # 然后在当前子应用的__init__.py里面新增一下代码:
default_app_config = "students.apps.StudentsConfig"
drf ( 学习第四部 )的更多相关文章
- Vue (学习第四部 前端项目搭建流程 )
目录 客户端项目搭建 创建项目目录 初始化项目 安装路由 Vue-router 下载安装路由组件 配置路由 初始化路由对象 注册路由信息 在视图函数中显示路由对应的内容 路由对象提供的操作 页面跳转 ...
- Django( 学习第四部 Django的views视)
目录 视图层 JsonResponse对象 form表单之文件上传 request方法及属性 FBV与CBV JsonResponse对象 前端序列化 JSON.stringify() json.du ...
- 从零开始学习jQuery (四) 使用jQuery操作元素的属性与样式
本系列文章导航 从零开始学习jQuery (四) 使用jQuery操作元素的属性与样式 一.摘要 本篇文章讲解如何使用jQuery获取和操作元素的属性和CSS样式. 其中DOM属性和元素属性的区分值得 ...
- 前端学习 第四弹: HTML(一)
前端学习 第四弹: HTML(一) 元素分类:块元素 内联元素 块级元素在浏览器显示时,通常会以新行来开始(和结束). 例子:<h1>, <p>, <ul>, &l ...
- C#可扩展编程之MEF学习笔记(四):见证奇迹的时刻
前面三篇讲了MEF的基础和基本到导入导出方法,下面就是见证MEF真正魅力所在的时刻.如果没有看过前面的文章,请到我的博客首页查看. 前面我们都是在一个项目中写了一个类来测试的,但实际开发中,我们往往要 ...
- Android Animation学习(四) ApiDemos解析:多属性动画
Android Animation学习(四) ApiDemos解析:多属性动画 如果想同时改变多个属性,根据前面所学的,比较显而易见的一种思路是构造多个对象Animator , ( Animator可 ...
- 五、Android学习第四天补充——Android的常用控件(转)
(转自:http://wenku.baidu.com/view/af39b3164431b90d6c85c72f.html) 五.Android学习第四天补充——Android的常用控件 熟悉常用的A ...
- 四、Android学习第四天——JAVA基础回顾(转)
(转自:http://wenku.baidu.com/view/af39b3164431b90d6c85c72f.html) 四.Android学习第四天——JAVA基础回顾 这才学习Android的 ...
- MVC学习(四)几种分页的实现(3)
在这篇MVC学习(四)几种分页的实现(2)博文中,根据URL中传入的两个参数(页码数,首页.上一页.下一页.末页的标记符)来获得对应的分页数据, 只是传入的参数太多,调用起来不太方便(标记符不能够写错 ...
随机推荐
- hystrix文档翻译之开始使用
获取包 使用maven获取包. <dependency> <groupId>com.netflix.hystrix</groupId> <artifactId ...
- javaweb修改表单参数---使用过滤器
需求: 所有的字段要将空字符串转成null: 问题: 我们知道表单如果不写值的时候,传递到后台的不是null,而且是空字符串.那么怎么改成null呢? 解决: 使用过滤器,将请求的参数修改过后继续,再 ...
- 手写:javascript中的关键字new
简单介绍一下new new再熟悉不过了,new后面跟着构造函数,可以创建对象,这个对象的原型指向构造函数的原型对象,说起来可能有点绕,直接看代码吧 function Person(name, age) ...
- xss小游戏通关
xss url:http://test.ctf8.com/level1.php?name=test 小游戏payload: <script>alert("'test'" ...
- C语言专项错题集
2020-08-10 记录 #1 1 struct student{ 2 int num; 3 int age; 4 }; 5 struct student stu[3]={{6001,20},{60 ...
- Kubernetes Pod水平自动伸缩(HPA)
HPA简介 HAP,全称 Horizontal Pod Autoscaler, 可以基于 CPU 利用率自动扩缩 ReplicationController.Deployment 和 ReplicaS ...
- 我竟在arm汇编除法算法里找到了leetcode某道题的解法
今天讲讲arm汇编中除法的底层实现.汇编代码本身比较长了,如需参考请直接拉到文末. 下面我直接把arm的除法算法的汇编代码转译成C语言的代码贴出来,并进行解析. 因为篇幅有限,所以在此只解析无符号整型 ...
- 071 01 Android 零基础入门 01 Java基础语法 09 综合案例-数组移位 03 综合案例-数组移位-显示数组当中所有元素的的方法
071 01 Android 零基础入门 01 Java基础语法 09 综合案例-数组移位 03 综合案例-数组移位-显示数组当中所有元素的的方法 本文知识点:综合案例-数组移位-显示数组当中所有元素 ...
- 题解【QTree3】
题目描述 给出N个点的一棵树(N-1条边),节点有白有黑,初始全为白 有两种操作: 0 i : 改变某点的颜色(原来是黑的变白,原来是白的变黑) 1 v : 询问1到v的路径上的第一个黑点,若无,输出 ...
- vs code C语言环境搭建
最近重温C语言,因为很多练习只是小程序,并不需要Clion和Codeblocks这样工程导向的编译软件,所以下载了vs code,并试图搜索相应的环境,在此过程中发现,网上许多vs code 的c/c ...