Paddle源码之内存管理技术
前言
在深度学习模型训练中,每次迭代过程中都涉及到Tensor的创建和销毁,伴随着的是内存的频繁 malloc和free操作,可能对模型训练带来不必要的 overhead。
在主流的深度学习框架中,会借助 chunk 机制的内存池管理技术来避免这一点。通过实事先统一申请不同 chunk size 的内存,并记录到内存池中。创建一个Tensor时,若内存池中存在满足需求的可用内存,则直接分配。销毁一个Tensor时,并不马上free掉还给系统,而是标记为可用状态,放在内存池供下个Tensor使用。
通过内存池管理技术,可以有效减少频繁的malloc和free操作,避免不必要的overhead。
技术实现
chunk
每个chunk代表一段连续的存储空间。不同的chunk按照地址升序组成双向链表。每个chunk只有两种状态:空闲、已占用。不存在部分使用的中间态。
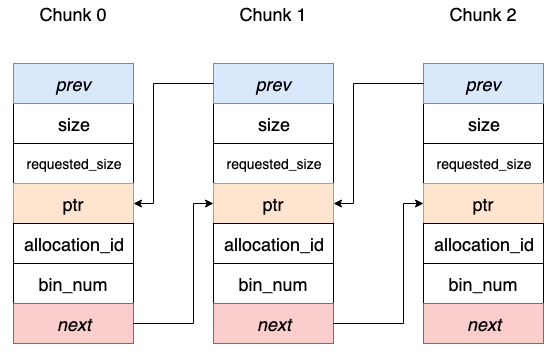
在Paddle中,内存池统一通过 BuddyAllocator类来管理,下面逐一剖析相关实现。成员变量包括:
private:
/*
* 默认的内存分配器,支持CPUAllocator、GPUAllocator、CUDAPinnedAllocator。
*/
std::unique_ptr<SystemAllocator> system_allocator_;
// 用于表示一个内存段的信息
using IndexSizeAddress = std::tuple<size_t, size_t, void*>;
// 借助有序的 set 存放可用的内存段
using PoolSet = std::set<IndexSizeAddress>;
PoolSet pool_; // 内存池,存放可用的不同 chunk size的内存信息
PoolSet chunks_; // 内存池。存放从系统重新申请的内存块
从BuddyAllocator的成员变量可以看出,不同BuddyAllocator对象可以管理不同类型的内存池,比如 CPU内存池、GPU内存池、CUDAPinned内存池。
构造函数显式需要一个SystemAllocator来初始化:
public:
BuddyAllocator(std::unqiue_ptr<SystemAllocator> system_allocator, size_t min_chunk_size, size_t max_chunk_size);
内存申请
BuddyAllocator如何避免内存频繁的malloc和free操作呢?
申请内存时:
void* BuddyAllocator::Alloc(size_t unaligned_size){
// step 1: 做内存对齐,保证申请的内存大小都是 min_chunk_size的整数倍
size_t size = align(unaligned_size+sizeof(MemoryBlock::Desc), min_chunk_size_);
// 加锁
std::lock_guard<std::mutex> lock(mutex_);
// step 2: 如果申请内存超过 max_chunk_size_, 则交由system_allocator完成
if(size > max_chunk_size_){
return SystemAlloc(size);
}
// step 3: 否则,去内存池查找是否有满足大小的可用内存块
auto it = FindExistChunk(size);
// step 4: 若找不到,则向系统申请新内存块,并记录到内存池中
if(it == pool_.end()){
it = RefillPool(size);
if(it == pool_.end()){
return nullptr;
}
}else{
VLOG(10)<<;
}
// step 5: 更新内存池 size 相关信息
total_used_ += size;
total_free_ -= size;
// step 6: 若申请的size小于内存块实际大小,则把多余的部分切分掉,新建一个内存块放到内存池中
return reinterpret_cast<MemoryBlock*>(SplitToAlloc(it, size))->Data();
}
内存释放
此处并非真正的将内存归还给系统,而是将内存块从占用状态标记为可用状态,并放到内存池中开放出去。
void BuddyAllocator::Free(void* p){
// step 1: 将指针转换为内存块指针
auto block = static_cast<MemoryBlock*>(p)->MetaData();
std::lock_guard<std::mutex> lock(mutex_);
// step 2: 获取内存块的详细元信息,释放内存需要
auto* desc = cache_.LoadDesc(block);
if(desc->get_type() == MemoryBlock::HUGE_CHUNK){
// 在前面申请大内存时,也是交由system_allocator完成的,解铃还须系铃人
system_allocator_->Free(block, desc->get_totoal_size(), desc->get_index());
// 删除内存块对应的元信息
cache_.Invalidate(block);
return;
}
// step 3: 若待释放内存块大小在[min_chunk_size_, max_chunk_size_]之间
block->MarkAsFree(&cache_); // 修改元信息,标记为 可用 状态
// step 4: 更新总内存信息
total_used_ -= desc->get_total_size();
total_free += desc->get_total_size();
// step 5: 看是否可以将此内存块与左右空闲的内存块合并,避免内存碎片
MemoryBlock* right_buddy = block->GetRightBuddy(&cache_);
if(right_buddy){
auto rb_desc = cache_.LoadDesc(right_buddy);
if(rb_desc->get_type() == MemoryBlock::FREE_CHUNK){
pool_.erase(IndexSizedAddress(rb_desc->get_index(), rb_desc->get_total_size(), right_buddy));
block->Merge(&cache_, right_buddy);
}
}
MemoryBlock* left_buddy = block->GetLeftBuddy(&cache_);
// .... (省略对前序内存块的合并操作)
// step 6: 将合并后的内存块放入到可用内存池中
pool_.insert(IndexSizeAddress(desc->get_index(), desc->get_total_size(), block));
}
内存归还
此阶段才是真正的将内存归还给操作系统,此过程分为两个步骤:
- 把后来的、通过
system_allocator_申请的内存free掉(调用Release函数) - 析构
BuddyAllocator对象时,对内存池剩余的内存free掉(调用析构函数)
我们先看第一阶段 Release逻辑:
uint64_t BuddyAllocator::Release(){
// 先加锁
std::lock_guard<std::mutex> lock(mutex_);
int num = 0; // 标记后来新增申请的内存块
uint64_t bytes = 0; // 统计总共可释放的内存
bool del_flag = false;
// step 1: 有序遍历可用内存池中的每个内存块
for(auto iter = pool_.begin(); iter != pool_.end()){
auto remain_size = std::get<1>(*iter);
auto remain_ptr = std::get<2>(*iter);
for(auto& chunk : chunks_){
auto init_size = std::get<1>(chunk);
auto init_ptr = std::get<2>(chunk);
// step 2: 若在之前的chunks_记录中找到地址一样,空间一样的chunk
if(init_size = remain_size && init_ptr == remain_ptr){
++num;
bytes += init_size;
total_free_ -= init_size;
auto block = static_cast<MemoryBlock*>(init_ptr);
// step 3: 则归还内存给系统,标记为此内存块为可回收状态
system_allocator_->Free(init_ptr, init_size, std::get<0>(chunk));
cache_.Invalidate(block);
del_flag = true;
break;
}
}
// step 4: 对于标记为可回收状态的内存块,从内存池中移除
if(del_flag){
iter = pool_.erase(iter);
}else{
iter++;
}
}
return bytes;
}
Release支持被显式调用,以归还未用到的内存给操作系统。
当BuddyAllocator对象在模型训练结束后,会被析构掉。析构时需要保证之前申请的内存必须正确的归还给操作系统,否则会导致内存泄露。
BuddyAllocator::~BuddyAllocator(){
while(!pool.empty()){
// step 1: 遍历内存池中所有的内存块
auto block = static_cast<MemoryBlock*>(std::get<2>(pool_.begin()));
auto desc = cache_.LoadDesc(block);
// step 2: Free掉,归还给系统
system_allocator_->Free(block, desc->get_total_size(), desc->get_index());
// step 3: 删除元信息
cache_.Invalidata(block);
pool_.erase(pool_.begin());
}
}
参考资料
Paddle源码之内存管理技术的更多相关文章
- MongoDB源码概述——内存管理和存储引擎
原文地址:http://creator.cnblogs.com/ 数据存储: 之前在介绍Journal的时候有说到为什么MongoDB会先把数据放入内存,而不是直接持久化到数据库存储文件,这与Mong ...
- Memcached源码分析——内存管理
注:这篇内容极其混乱 推荐学习这篇博客.博客的地址:http://kenby.iteye.com/blog/1423989 基本元素item item是Memcached中记录存储的基本单元,用户向m ...
- Linux 2.6 源码学习-内存管理-buddy算法
核心数据结构 linux 2.6 的内存管理支持NUMA(Non Uniform Memory Access Achitecture),即非一致内存访问体系,在该体系中存在多个CPU,并且拥有分离的存 ...
- redis源码笔记-内存管理zmalloc.c
redis的内存分配主要就是对malloc和free进行了一层简单的封装.具体的实现在zmalloc.h和zmalloc.c中.本文将对redis的内存管理相关几个比较重要的函数做逐一的介绍 参考: ...
- 鸿蒙内核源码分析(内存规则篇) | 内存管理到底在管什么 | 百篇博客分析OpenHarmony源码 | v16.02
百篇博客系列篇.本篇为: v16.xx 鸿蒙内核源码分析(内存规则篇) | 内存管理到底在管什么 | 51.c.h .o 内存管理相关篇为: v11.xx 鸿蒙内核源码分析(内存分配篇) | 内存有哪 ...
- linux内存源码分析 - 内存回收(整体流程)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 概述 当linux系统内存压力就大时,就会对系统的每个压力大的zone进程内存回收,内存回收主要是针对匿名页和文 ...
- TOMCAT8源码分析——SESSION管理分析(上)
前言 对于广大java开发者而已,对于J2EE规范中的Session应该并不陌生,我们可以使用Session管理用户的会话信息,最常见的就是拿Session用来存放用户登录.身份.权限及状态等信息.对 ...
- Tomcat源码分析——Session管理分析(上)
前言 对于广大java开发者而已,对于J2EE规范中的Session应该并不陌生,我们可以使用Session管理用户的会话信息,最常见的就是拿Session用来存放用户登录.身份.权限及状态等信息.对 ...
- (转)linux内存源码分析 - 内存回收(整体流程)
http://www.cnblogs.com/tolimit/p/5435068.html------------linux内存源码分析 - 内存回收(整体流程) 概述 当linux系统内存压力就大时 ...
随机推荐
- LeetCode-680-验证回文字符串 Ⅱ
给定一个非空字符串 s,最多删除一个字符.判断是否能成为回文字符串. image.png 解题思路: 判断是否回文字符串:isPalindrome = lambda x: x==x[::-1],即将字 ...
- vs code远程开发
VS Code如何配置远程开发 你是如何远程开发的?还在使用FTP/SFTP同步文件?那你out了,有了宇宙第一IDE:VS就不需要这么麻烦了,一起学习一下吧. 第一步,安装Remote SSH插件 ...
- Socket 结构体
proto socket 关联结构: { .type = SOCK_STREAM, .protocol = IPPROTO_TCP, .prot = &tcp_prot, .ops = &am ...
- JAVA注解的继承性
摘要 本文从三个方面介绍java注解的**"继承性"**: 基于元注解@Inherited,类上注解的继承性 基于类的继承,方法/属性上注解的继承性 基于接口的继承/实现,方法/属 ...
- Ceph的参数mon_osd_down_out_subtree_limit细解
前言 之前跟一个朋友沟通一个其他的问题的时候,发现了有一个参数 mon osd down out subtree limit 一直没有接触到,看了一下这个参数还是很有作用的,本篇将讲述这个参数的作用和 ...
- git 最新笔记,工作中的必会技能
1.状态查看: git status 可以查看工作区,暂存区的状态 untracked 在暂存区没有该文件 modified 修改过 staged 使用git add 暂存过 2.添加操作: git ...
- iOS gif图显示问题
问题 有时候需要显示gif动态图,让界面更加的绚丽,但是iOS默认只支持png,gpg图片.那么如何才能显示gif图呢? 解决方式 添加框架 CoreGraphics.framework ImageI ...
- ⭐NES.css推荐⭐
今天发现一个有意思的CSS框架,叫NES.css 官网地址:https://nostalgic-css.github.io/NES.css/ gitHub地址:https://github.com/n ...
- MySql学习笔记--详细整理--上
目录 MySql MySql安装 连接数据库 操作数据库 数据库的列类型 数据库的字段属性 创建数据库 修改删除表 数据管理 外键 DML语言 添加 修改 删除 DQL查询数据(重点) 查询 去重 w ...
- sentinel配置
登陆接口 QPS5,异常0.8,熔断10s 1.异地登陆同省逻辑降级security 2.可疑用户判断certification 3.是否是危险设备判断account 4.是否是自动化imei,ime ...