Python+爬虫+xlwings发现CSDN个人博客热门文章
☞ ░ 前往老猿Python博文目录 ░
一、引言
最近几天老猿博客的访问量出现了比较大的增长,从常规的1000-3000之间波动的范围一下子翻了将近一倍,粉丝增长从日均10-40人也增长了差不多一倍,下面是csdn提供的博文访问量数据图和粉丝增长数据图:
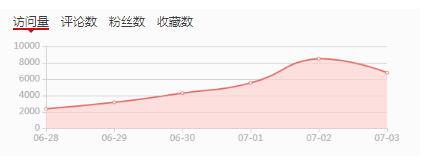
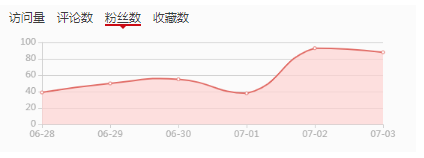
突然增长的情况让人始料不及,老猿非常想弄清楚这些访问量和粉丝是什么文章带来的。但看了下不是最新发布博文,而以前的博文又不记得阅读量是否增长,如果要自己去翻非常麻烦,因为老猿博客文章有点多,自己写的加转发的有900多篇,因此想既然好歹学了爬虫,还是自己写个程序去CSDN获取和记录数据吧。
二、背景知识
- 为了从CSDN爬取数据,本文用到了爬虫程序常用的urllib.request和BeautifulSoup,相关内容介绍请参考老猿《爬虫专栏》的介绍。但要说明一下,该专栏中介绍的爬取CSDN文章的处理方式,由于CSDN网站后来进行了一次全面的升级,大部分使用urllib.request爬取CSDN的案例已经不适用,老猿暂时也没想重新去研究和更新,但其原理完全可以用于其他网站;
- 爬取下来的信息记录到excel文件中,使用了xlwings的excel操作方法,相关内容介绍请参考《Python中高级知识(非专题部分)学习随笔》的介绍。
三、爬取文章阅读量使用的CSDN博文内容结构介绍
爬取CSDN博文阅读量,与CSDN博文相关的网页内容包括两部分,一是博文列表的翻页机制,一是每页显示博文列表的内容。
3.1、CSDN博文翻页机制
CSDN博文的翻页机制是基于每页都在相同目录下,目录名为:
“https://blog.csdn.net/LaoYuanPython/article/list/”,
如第一页的url地址为:https://blog.csdn.net/LaoYuanPython/article/list/1。
后续每下翻一页序号加1,但要说明的是,该翻页数字可以不停增长,如果对应页面序号超出了所有博文数,对应页面会显示如下信息:

3.2、每页文章列表的识别
通过按页向CSDN发起请求后,CSDN会返回对应页的页面内容,在页面内容中与博文列表的数据都在<div class="article-list">这个起始标签及其结束标签对应的块内,这部分中每篇文章的标题、URL和阅读量信息都包含在起始标签<div class="article-item-box csdn-tracking-statistics" data-articleid="xxxxx">和其结束标签之间的块内。
下面就是一个典型的页面包含的文章内容的块:
<div class="article-item-box csdn-tracking-statistics" data-articleid="106533164">
<h4 class="">
<a href="https://blog.csdn.net/LaoYuanPython/article/details/106533164" target="_blank">
<span class="article-type type-1 float-none">原创</span> moviepy音视频剪辑:视频剪辑基类VideoClip详解 <span class="plan-icon">
<img class="article-plan-img article-heard-img" src="https://csdnimg.cn/release/phoenix/template/new_img/planImg.png" alt="">
<div class="plan-tip">原力计划</div>
</span>
</a>
</h4>
<p class="content">
<a href="https://blog.csdn.net/LaoYuanPython/article/details/106533164" target="_blank">
本文是笔者基于moviepy.video.VideoClip.py的文档字符串以及源代码,结合查阅资料和验证测试,断断续续持续了一个多星期探索的结果。详细介绍了视频剪辑基类VideoClip的构造方法、属性和相关处理方法,其中很多方法如save_frame、write_videofile、writ... </a>
</p>
<div class="info-box d-flex align-content-center">
<p>
<span class="date">
2020-06-11 00:05:41</span>
<span class="read-num"><img src="https://csdnimg.cn/release/phoenix/template/new_img/readCountWhite.png" alt="">145</span>
<span class="read-num"><img src="https://csdnimg.cn/release/phoenix/template/new_img/commentCountWhite.png" alt="">0</span>
</p>
</div>
<div class="opt-box">
<button class="btn-opt" data-type="top">置顶</button>
<a class="btn-opt" href="https://editor.csdn.net/md?articleId=106533164">编辑</a>
<button class="btn-opt" data-type="delete">删除</button>
</div>
</div>
其中文章的标题和URL地址在如下标签路径内:div div h4 a,阅读量在起始标签:<span class="read-num">对应的标签内,不过有2个‘read-num’,只有第一个是阅读量,第二个是评价量,我们不关注。
一个页面有多个文章列表,通常为40个。
四、excel的操作
本案例内,是通过保存不同时间点的阅读量,有了不同时刻的阅读量数据,通过对比就可以知道某段时间内热门博文是哪些。本文仅实现了博文数据的excel记录,对比可以通过人手工对比。
为了实现这些功能,对excel的功能包括判断文件是否存在、读入上次记录、查找博文是否在excel中存在、将最新记录更新到对应博文或插入一个新的博文数据,每次访问的时间点记录在excel的第一行作为标题栏。
由于excel的操作性能并不高,比python列表慢,因此博文内容的查找和更新都是通过列表进行的,excel的操作只进行了初始运行时读入文件到列表、最后将内存列表中的内容输出到excel对象、将excel对象的数据保存到excel文件中这几步。
五、实现代码
5.1、二维列表的行列位置交换函数
下面的函数是将二维列表的行和列进行交换,可以将一个如a[100][3]的数组变成b[3][100],其目的是为了提高excel对象更新的效率,具体可参考《一个使用xlwings操作excel数据优化60倍处理效率的案例》的介绍。
def exchangeLineColumn(array):
columncount = len(array[0])
rowcount = len(array)
columnData = []
for i in range(columncount):
columnData.append([])
for line in array:
columnPos = 0
for column in line:
columnData[columnPos].append(column)
columnPos += 1
return columnData
5.2、构建http请求头函数
def mkhead():
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'}
return header
5.3、从保存excel文件中读入已保存的博文信息
函数initArticleList从excel文件中读入标题栏、博文URL列表、标题列表和阅读量列表,如果excel文件不存在,则初始化标题列表和列数。
def initArticleList():
global urlList,urlReadInfoList,columncount,ReadInfoExcelHead,titleList
#每次除了记录博文信息,还单独输出一个url和博文标题对应的文本文档,老猿用于构建一个所有博文的汇总目录,每次运行前备份上次的数据
if os.path.exists(r"c:\temp\csdn\articles.bak"):
os.remove(r"c:\temp\csdn\articles.bak")
if os.path.exists(r"c:\temp\csdn\articles.txt"):
os.rename(r"c:\temp\csdn\articles.txt",r"c:\temp\csdn\articles.bak")
#判断excel文件是否存在
fileexists = os.path.exists(r"c:\temp\csdn\readcount.xlsx")
if fileexists:#如果存在则读入excel中的信息到全局变量中
excelApp = excel.App(False, False)
excelFile = excelApp.books.open(r"c:\temp\csdn\readcount.xlsx")
sheet = excelFile.sheets[0]
ReadInfoExcelHead = sheet.range(1,1).expand('right').value #读取excel标题行保存到全局变量ReadInfoExcelHead
columncount = sheet.used_range.last_cell.column #获取文件总列数
urlList = sheet.range(2,1).expand('down').value #读取保存的所有url记录到全局变量urlList
titleList = sheet.range(2,2).expand('down').value #读取保存的所有文章标题记录到全局变量titleList
urlReadInfoList=sheet.range(2,3).expand().value #读取保存的所有文章阅读记录到全局变量urlReadInfoList
if not isinstance(urlReadInfoList[0],list):
#阅读记录仅1列时urlReadInfoList为一维列表,元素为1个阅读量数值,如果是多列时返回二维列表,每个列表中元素为一行阅读量记录,为了统一二维列表和一维列表后续处理,在此将一维列表强制转为二维列表
urlReadInfoList=[[i]for i in urlReadInfoList]
excelFile.close()
excelApp.quit()
else: #excel文件不存在则准备初始化列数为2表示只有url和标题,没有阅读量记录
columncount = 2
ReadInfoExcelHead = ['url','标题']
columncount += 1 #列数加1用于记录本次读取的阅读量
curtime = time.strftime("%Y%m%d %H%M%S", time.localtime())
ReadInfoExcelHead.append(curtime) #excel标题栏增加本次读取的时间
5.4、更新博文信息的updateReadcount函数
updateReadcount函数将对应博文信息更新到urlReadInfoList中
def updateReadcount(url,title,readcount):
global urlList,urlReadInfoList,ReadInfoExcelHead,titleList,columncount
try:
line = urlList.index(url)
except ValueError:
print(f"{url} not found")
urlList.append(url)
titleList.append(title)
urlReadInfoList.append([0]*(columncount-2))
line = len(urlReadInfoList)-1
else:
urlReadInfoList[line].append(0)
urlReadInfoList[line][columncount-2-1] = readcount
5.5、读取页面中博文信息的getPageArticles函数
根据页面结构信息识别博文的url、标题和阅读量:
def getPageArticles(pageText):
soup = BeautifulSoup(pageText, 'lxml')
#articlesList = soup.select('.article-list div h4 a')
articlesList = soup.select('.article-list>div ')
for article in articlesList:
try:
#logPag(f"\n网页内容如下:\n {article}")
articlehead = article.select('h4 a')
if not articlehead:
continue
url = articlehead[0].attrs['href']
title = list(article.a.stripped_strings)[1]
readcount = int(article.find_all("span", class_="read-num")[0].contents[1])
#logPag(f"{url}, {title}, {readcount}\n")
except Exception as e:
logPag(f"读取 {url}网页内容解码失败,原因:\n{e}")
logPag(f"\n网页内容如下:\n {article}")
break
updateReadcount(url, title, readcount) #更新博文信息到全局变量中
5.6、访问博文所有页面的getArticles函数
getArticles函数逐页请求访问对应页面,调用getPageArticles解析对应页的博文信息:
def getArticles():
preURLAtriclelist = "https://blog.csdn.net/LaoYuanPython/article/list/"
header = mkhead()
for page in range(1,300):
print("get article list page:",page)
url = preURLAtriclelist +str(page)
try:
req = urllib.request.Request(url=url, headers=header)
text = urllib.request.urlopen(req).read().decode()
isEnd = text.find("空空如也")
if isEnd>=0:
print(f"所有页读取完成!\n")
break
else:getPageArticles(text)
except Exception as e:
logPag(f"读取 {url}网页内容解码失败,原因:\n{e}")
break
else:
print(f"读取第{page}页成功!")
5.7、保存博文列表信息到excel文件的saveArticlesInfo函数
saveArticlesInfo函数将包含获取数据时间列表的标题栏、博文URL地址、标题栏以及所有时刻对应阅读量信息保存到excel中,保存前先判断是否存在对应excel文件,有则将其备份再写入。同时将博文和url地址保存到文本文件。
def saveArticlesInfo():
global urlList, urlReadInfoList, ReadInfoExcelHead, titleList, columncount
logPag("准备将博客博文url地址和标题保存到文件:"+r"c:\temp\csdn\articles.txt")
line = 0
if os.path.exists(r"c:\temp\csdn\article.bak"):
os.remove(r"c:\temp\csdn\article.bak")
fp = open(r"c:\temp\csdn\articles.txt", "w", encoding='utf-8')
for url in urlList:
fp.write(f"{titleList[line]} {url}\n")
line+= 1
fp.close()
if os.path.exists(r"c:\temp\csdn\readcount.bak"):
os.remove(r"c:\temp\csdn\readcount.bak")
if os.path.exists(r"c:\temp\csdn\readcount.xlsx"):
os.rename(r"c:\temp\csdn\readcount.xlsx", r"c:\temp\csdn\readcount.bak")
logPag("创建excel对象...")
excelApp = excel.App(False, False)
excelFile = excelApp.books.add()
sheet = excelFile.sheets.add('csdn文章阅读次数')
logPag("将文章url地址和标题填入excel对象中...")
sheet.range(1, 1).expand('right').value = ReadInfoExcelHead
sheet.range(1, 1).expand('right').api.VerticalAlignment = -4130
#api.HorizontalAlignment = -4108 # -4108 水平居中。 -4131 靠左,-4152 靠右。
#api.VerticalAlignment = -4130 # -4108 垂直居中(默认)。 -4160 靠上,-4107 靠下, -4130 自动换行对齐。
sheet.range('A2').options(transpose=True).value = urlList
sheet.range('B2').options(transpose=True).value = titleList
logPag("将文章阅读数量填入excel对象中...")
readInfoList= exchangeLineColumn(urlReadInfoList)
columnno = 3
for readinfo in readInfoList:
sheet.range(2,columnno).options(transpose=True).value = readinfo
columnno += 1
logPag("设置excel数据的宽度...")
sheet.range('A1').column_width = 10
sheet.range('B1').column_width = 120
sheet.range('C1').expand('right').column_width = 8#.columns.autofit()
logPag("设置excel数据的字体颜色和背景色...")
sheet.range(1, 1).expand('right').api.Font.Color = 0xffffff #标题栏字体白色
sheet.range(1, 1).expand('right').color = (0, 0, 255) #标题栏填充色蓝色
sheet.range(1, 1).expand('right').api.HorizontalAlignment = -4108 #标题栏自动换行
logPag(r"保存读取数据到c:\temp\csdn\readcount.xlsx......")
excelFile.save(r"c:\temp\csdn\readcount.xlsx")
logPag(r"保存完毕.")
excelFile.close()
excelApp.quit()
5.8、主程序
主程序就是调用initArticleList函数读入excel文件信息,调用getArticles访问博客的最新博文数据、调用saveArticlesInfo保存最新博文数据。
initArticleList()
getArticles()
saveArticlesInfo()
六、生成excel文件的数据分析
下面是7月4日和7月5日爬取的老猿自己博客的访问量数据,选择最后一次和最开始一次进行比较,手工在excel中计算出增长量,将这段时间阅读量大于30的选择出来,对应文章列表如下:
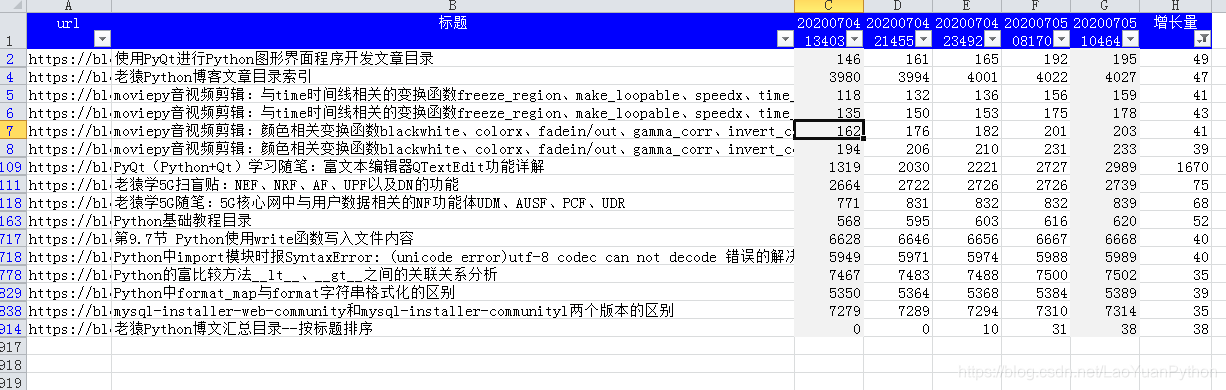
可以看到《PyQt(Python+Qt)学习随笔:富文本编辑器QTextEdit功能详解》这篇文章阅读量增长幅度最大,其他的依次是老猿学5G、Python教程以及moviepy相关文章。
八、小结
本文详细介绍了利用urllib.request和BeautifulSoup爬取CSDN博客文章的阅读量信息,并利用xlwings将信息更新保存到excel中的过程和方法,爬取的信息可以用于分析对应时段内的热门博文。


跟老猿学Python、学5G!
☞ ░ 前往老猿Python博文目录 ░
Python+爬虫+xlwings发现CSDN个人博客热门文章的更多相关文章
- [Python爬虫笔记][随意找个博客入门(一)]
[Python爬虫笔记][随意找个博客入门(一)] 标签(空格分隔): Python 爬虫 2016年暑假 来源博客:挣脱不足与蒙昧 1.简单的爬取特定url的html代码 import urllib ...
- Python爬虫入门教程 17-100 CSD*博客抓取数据
写在前面 写了一段时间的博客了,忽然间忘记了,其实CSD*博客频道的博客也是可以抓取的,所以我干了..... 其实这事情挺简单的,打开CSDN博客首页,他不是有个最新文章么,这个里面都是最新发布的文章 ...
- Python爬虫,看看我最近博客都写了啥,带你制作高逼格的数据聚合云图
转载请标明出处: http://blog.csdn.net/forezp/article/details/70198541 本文出自方志朋的博客 今天一时兴起,想用python爬爬自己的博客,通过数据 ...
- 开发记录_自学Python写爬虫程序爬取csdn个人博客信息
每天刷开csdn的博客,看到一整个页面,其实对我而言,我只想看看访问量有没有上涨而已... 于是萌生了一个想法: 想写一个爬虫程序把csdn博客上边的访问量和评论数都爬下来. 打算通过网络各种搜集资料 ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- Python爬虫简单实现CSDN博客文章标题列表
Python爬虫简单实现CSDN博客文章标题列表 操作步骤: 分析接口,怎么获取数据? 模拟接口,尝试提取数据 封装接口函数,实现函数调用. 1.分析接口 打开Chrome浏览器,开启开发者工具(F1 ...
- python实现的文本编辑器 - Skycrab - 博客频道 - CSDN.NET
Download Qt, the cross-platform application framework | Qt Project Qt 5.2.1 for Windows 64-bit (VS 2 ...
- 史诗级干货-python爬虫之增加CSDN访问量
史诗级干货-python爬虫之增加CSDN访问量 搜索微信公众号:'AI-ming3526'或者'计算机视觉这件小事' 获取更多算法.机器学习干货 csdn:https://blog.csdn.net ...
- 在CSDN开通博客专栏后如何发布文章(图文)
今天打开电脑登上CSDN发现自己授予了专栏勋章,有必要了解如何在专栏发布文章. 很感谢已经有前辈给出了图文教程,此文章转载自博客:http://blog.csdn.net/upi2u/article/ ...
随机推荐
- c++11-17 模板核心知识(二)—— 类模板
类模板声明.实现与使用 Class Instantiation 使用类模板的部分成员函数 Concept 友元 方式一 方式二 类模板的全特化 类模板的偏特化 多模板参数的偏特化 默认模板参数 Typ ...
- Ros中创建msg和srv遇到的问题
在创建msg和srv文件之后,使用srv和msg文件时候需要对xml文件进行修改,如下: <build_depend>message_generation</build_depend ...
- 带货直播源码开发采用MySQL有什么优越性
MySQL是世界上最流行的开源关系数据库,带货直播源码使用MySQL,可实现分钟级别的数据库部署和弹性扩展,不仅经济实惠,而且稳定可靠,易于运维.云数据库 MySQL 提供备份恢复.监控.容灾.快速扩 ...
- Linux 基础命令及基本目录
Linux 基础命令及基本目录 一.网卡 1.网卡配置文件路径 /etc/sysconfig/network-scripts/ifcfg-eth0 配置文件: TYPE=Ethernet # 以太 ...
- 腾讯云对象存储COS新品发布——智能分层存储,自动优化您的存储成本
近日,腾讯云正式发布对象存储新品--智能分层存储,能够根据用户数据的访问模式,自动地转换数据的冷热层级,为用户提供与标准存储一致的低延迟和高吞吐的产品体验,同时具有更低的存储成本. 熟悉数据存储的用户 ...
- php 正则金额验证
$money_reg = '/^[1-9]\d*|^[1-9]\d*.\d+[1-9]$/';if(!preg_match($money_reg, $money)){ $this->ajaxEr ...
- Andrew Ng 机器学习公开课 - 线性回归
我的机器学习系列从现在开始将会结合Andrew Ng老师与sklearn的api是实际应用相结合来写了. 吴恩达(1976-,英文名:Andrew Ng),华裔美国人,是斯坦福大学计算机科学系和电子工 ...
- 还不懂Docker?一个故事安排的明明白白!
程序员受苦久矣 多年前的一个夜晚,风雨大作,一个名叫Docker的年轻人来到Linux帝国拜见帝国的长老. "Linux长老,天下程序员苦于应用部署久矣,我要改变这一现状,希望长老你能帮帮我 ...
- css子选择器 :frist-child :nth-child(n) :nth-of-type(n) ::select选择器
记录一下前一段时间使用.学习的几种选择器. 1. :frist-child 选择器n 比如<ul><li></li> <li></li> & ...
- git操作之三:git reset
在上篇文章中介绍了git restore命令,该命令的可以看作是撤销命令,文件在不同的状态下,使用git restore <file> 命令,会撤销对文件的修改,是文件回到修改前的状态也就 ...