kafka学习(一)初识kafka
文章更新时间:2020/06/08
一、简介
定义:kafka是一个分布式,基于zookeeper协调的发布/订阅模式的消息系统,本质是一个MQ(消息队列Message Queue),主要用于大数据实时处理领域。
目的:解耦、削峰、异步、缓冲(生产大于消费的情况)详见这里~
日志保留(retention):我们可以配置主题的消息保留策略,譬如只保留一段时间的日志或者只保留特定大小的日志。当超过这些限制时,老的消息会被删除。我们也可以针对某个主题单独设置消息过期策略,这样对于不同应用可以实现个性化。
PS:消息队列中的消息不是永久存的,会定时删除,自动删除的时间可以配置。
结构:

二、消息队列通信的模式
最大的特性就是可以实时的处理大量数据以满足各种需求场景。
点对点模式
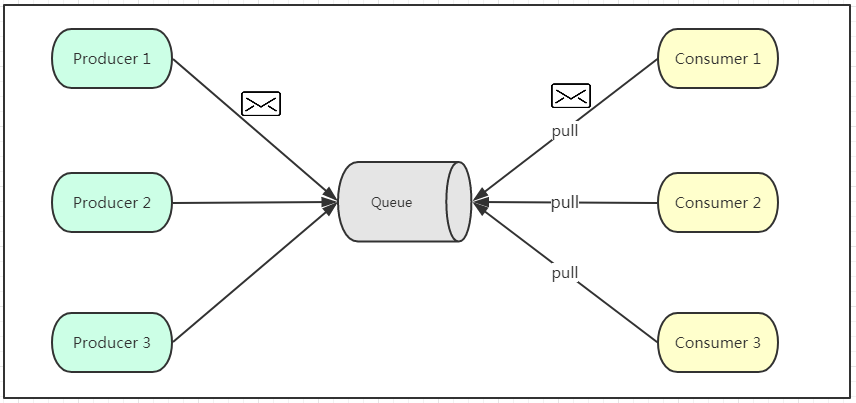
如上图所示,点对点模式通常是基于拉取或者轮询的消息传送模型,这个模型的特点是发送到队列的消息被一个且只有一个消费者进行处理。生产者将消息放入消息队列后,由消费者主动的去拉取消息进行消费。当一个消费者消费了队列中的某条数据之后,该条数据则从消息队列中删除。
优点:拉取消息的频率可以由自己控制。
存在缺陷:消费者端无法感知消息队列是否有消息需要消费,所以在消费者端需要额外的线程去监控。
发布订阅模式(发布订阅模式其实有两种,kafka用的是发布订阅模式中,消费者主动拉取【pull】的模式,其他mq中间件就是以下图【push】的形式进行接收消息)
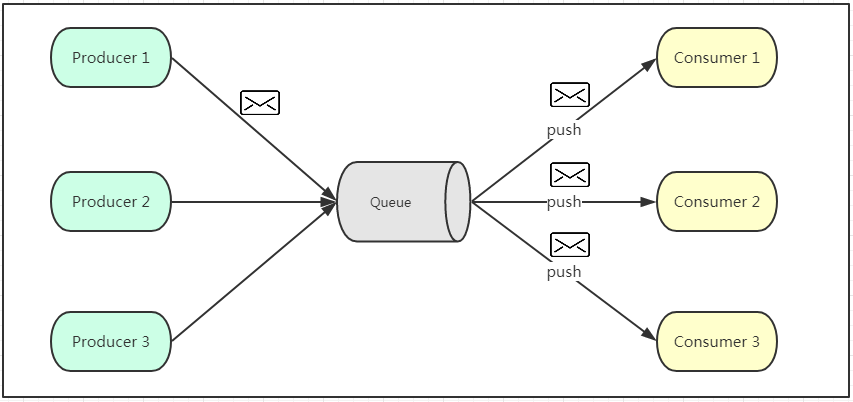
如上图所示,发布订阅模式是一个基于消息送的消息传送模型,该模型可以有多种不同的订阅者。生产者将消息放入消息队列后,队列会将消息推送给订阅过该类消息的消费者(类似微信公众号)。由于是消费者被动接收推送,所以无需感知消息队列是否有待消费的消息!但是consumer1、consumer2、consumer3由于机器性能不一样,所以处理消息的能力也会不一样,而消息队列却无法感知消费者消费的速度!所以推送的速度成了发布订阅模模式的一个问题!假设三个消费者处理速度分别是8M/s、5M/s、2M/s,如果队列推送的速度为5M/s,则consumer3无法承受!如果队列推送的速度为2M/s,则consumer1、consumer2会出现资源的极大浪费!
优点:消费者无需感知消息队列是否有待消费的消息。
存在缺陷:服务者无法感知消费者机器的性能,容易造成接收溢出或主机资源浪费。
三、kafka设计理念
Kafka 是一种分布式的,基于发布 / 订阅的消息系统。主要设计目标如下:
- 以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间复杂度的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒 100K 条以上消息的传输。
- 支持 Kafka Server 间的消息分区,及分布式消费,同时保证每个 Partition 内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展。
四、kafka相关名词
- Kafka中发布订阅的对象是topic。我们可以为每类数据创建一个topic,把向topic发布消息的客户端称作producer,从topic订阅消息的客户端称作consumer。
- Producers和consumers可以同时从多个topic读写数据。一个kafka集群由一个或多个broker服务器组成,它负责持久化和备份具体的kafka消息。
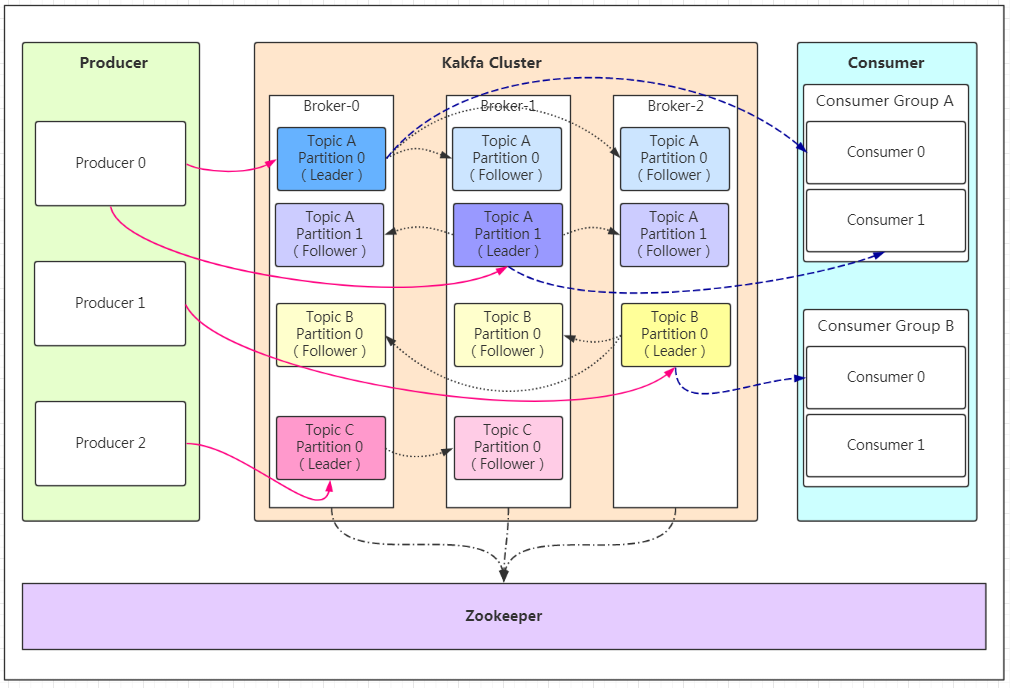
Producer:Producer即生产者,消息的产生者,是消息的入口。
kafka cluster:kafka集群
Broker(kafka实例,可看做kafka主机):每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等……
Topic(消息主题,即分类):可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
Partition(分区):每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量(并发)。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!每个消息在被添加到分区时,都会被分配一个 offset(称之为偏移量),它是消息在此分区中的唯一编号。kafka 通过 offset 保证消息在分区内的顺序,offset 的顺序不跨分区,即 kafka 只保证在同一个分区内的消息是有序的。
Replication(副本):每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
Message(消息内容):每一条发送的消息主体。
Consumer:消费者,即消息的消费方,是消息的出口。
Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费(不同组的消费者可以消费同一个分区的数据)。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
五、zookeeper在kafka中的作用
- kafka集群的正常使用需要依赖zookeeper,可以帮kafka集群存储一些信息。
- 0.9版本前,消息的偏移量(offset)储存在ZK中,0.9版本后储存在一个系统topic【专门储存消息偏移量】
- zookeeper也可以保存消费者的消费信息,目的是消费者挂了重启后,可以接着上次的消费位置继续消费(消费者内存中也会有一份备份,没挂的时候直接取内存)。
参考资料:
- 再过半小时,你就能明白kafka的工作原理了(特此感谢!)
kafka学习(一)初识kafka的更多相关文章
- kafka学习2:kafka集群安装与配置
在前一篇:kafka学习1:kafka安装 中,我们安装了单机版的Kafka,而在实际应用中,不可能是单机版的应用,必定是以集群的方式出现.本篇介绍Kafka集群的安装过程: 一.准备工作 1.开通Z ...
- 【kafka学习之五】kafka运维:kafka操作日志设置和主题删除
一.操作日志 首先附上kafka 操作日志配置文件:log4j.properties 根据相应的需要设置日志. #日志级别覆盖规则 优先级:ALL < DEBUG < INFO <W ...
- Kafka学习之二 Kafka安装和使用
部署环境Linux(Centos 6.5),JDK 1.8.0,zookeeper-3.4.12,kafka_2.11-2.0.0. 1. 单机环境 官方建议使用JDK 1.8版本,因此本文使 ...
- kafka学习1:kafka安装
一.环境准备 1.jdk 如果不会安装linux下的jdk,参考这篇文章:http://www.cnblogs.com/gudi/p/7812033.html 2.kafka wget –c ht ...
- Kafka学习笔记之Kafka三款监控工具
0x00 概述 在之前的博客中,介绍了Kafka Web Console这 个监控工具,在生产环境中使用,运行一段时间后,发现该工具会和Kafka生产者.消费者.ZooKeeper建立大量连接,从而导 ...
- kafka学习总结之kafka简介
kafka是一个分布式,基于subscribe-publish的消息系统 特性:高吞吐量.低延迟.可扩展性.持久性(消息持久化到本地磁盘).可靠性.容错性(n个副本,允许n-1个节点失败).高并发(支 ...
- 【kafka学习之四】kafka集群性能测试
kafka集群的性能受限于JVM参数.服务器的硬件配置以及kafka的配置,因此需要对所要部署kafka的机器进行性能测试,根据测试结果,找出符合业务需求的最佳配置. 1.kafka broker j ...
- 【kafka学习之三】kafka集群运维
kafka集群维护一.kafka集群启停#启动kafka/home/cluster/kafka211/bin/kafka-server-start.sh -daemon /home/cluster/k ...
- Kafka学习笔记之Kafka性能测试方法及Benchmark报告
0x00 概述 本文主要介绍了如何利用Kafka自带的性能测试脚本及Kafka Manager测试Kafka的性能,以及如何使用Kafka Manager监控Kafka的工作状态,最后给出了Kafka ...
- Kafka学习笔记之Kafka Consumer设计解析
0x00 摘要 本文主要介绍了Kafka High Level Consumer,Consumer Group,Consumer Rebalance,Low Level Consumer实现的语义,以 ...
随机推荐
- Robot Framework(3)——RIDE工具详解
上一篇介绍了用RF来简单运行案例,此篇主要了解一下工具操作 一.菜单栏 1.File 1>New Project:新建工程 2>Open Test Suite:打开测试套件 3>Op ...
- ubuntu18.04 开机定时启动任务
1,crontab 格式:M H D m d cmd == 分 时 天 月 周几 命令 参数 : crontab -e : 执行文字编辑器来设定时程表,内定的文字编辑器是 VI,如果你想用别的文字编辑 ...
- 最强云硬盘来了,让AI模型迭代从1周缩短到1天
摘要:华为云擎天架构+ Flash-Native存储引擎+低时延CurreNET,数据存储和处理还有啥担心的? 虽然我们已经进入大数据时代,但多数企业数据利用率只有10%,数据的价值没有得到充分释放. ...
- Javascript循环和代码规范
1 - 循环 1.1 for循环 语法结构 for(初始化变量; 条件表达式; 操作表达式 ){ //循环体 } 名称 作用 初始化变量 通常被用于初始化一个计数器,该表达式可以使用 var 关键字声 ...
- 跟我一起学.NetCore之中间件(Middleware)简介和解析请求管道构建
前言 中间件(Middleware)对于Asp.NetCore项目来说,不能说重要,而是不能缺少,因为Asp.NetCore的请求管道就是通过一系列的中间件组成的:在服务器接收到请求之后,请求会经过请 ...
- nginx如何限制并发连接请求数?
简介 限制并发连接数的模块为:http_limit_conn_module,地址:http://nginx.org/en/docs/http/ngx_http_limit_conn_module.ht ...
- TDengine能比Hadoop快10倍?
之前对国产的时序大数据存储引擎 TDengine 感兴趣,因为号称比Hadoop快十倍,一直很好奇怎么实现的,所以最近抽空看了下白皮书和设计文档. 如果用一句话总结,就是 TDengine 是为特定的 ...
- UI设计中的软件知识
最近挺想学学UI的,因为我们公司没有UI,所以做页面都是全靠摸索,老是被领导说没有审美[捂脸] 学习UI所需要的软件 PS AI Sketch XD Sketch是MAC才能安装的软件 作者:彼岸舞 ...
- Cocos Creator 性能优化:DrawCall
前言 在游戏开发中,DrawCall 作为一个非常重要的性能指标,直接影响游戏的整体性能表现. 无论是 Cocos Creator.Unity.Unreal 还是其他游戏引擎,只要说到游戏性能优化,D ...
- Myeclipse 连接数据库(jdbc)
1.找到DataBase Explorer,如下图所示: 2.点击下图红框内图标,new 3.进入下图界面 如果是JDBC驱动按下图配置: driver name自己起 url一定要注意:jdbc:m ...