Elasticsearch安装、原理学习总结
ElasticSearch
ElasticSearch概念
Elasticsearch是Elastic Stack核心的分布式搜索和分析引擎。
什么是Elastic Stack
Elastic Stack,就是ElasticSearch + LogStash + Kibana
Logstash用于收集,聚合和丰富数据并将其存储在Elasticsearch中。
Kibana提供了一套可视化界面,可以交互式的浏览数据,以及管理和监视堆栈。
ElasticSearch是一个分布式,高性能、高可用、可伸缩的搜索和分析系统。
Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch主要用于云计算中,能够达到实时搜索,稳定,可靠,快速,并且安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。
Elasticsearch的使用场景
网上商场,搜索商品.
配合logStash和kibana进行日志分析
为什么要使用Elasticsearch
假设用关系型数据库做搜索,当用户在搜索框输入“一名程序员”时,数据库通常只能把这四个字去进行全部匹配。可是在文本中,可能会出现“他是一名合格的程序员”,这时候就没有结果了,但是ES就可以实现检索,而且速度极快。
Elasticsearch基本概念
Elasticsearch和关系型数据库概念对应关系(方便理解ES的架构)
|
关系型数据库 |
Elasticsearch |
|
数据库 |
索引 |
|
数据表 |
类型 |
|
行 |
文档 |
|
列 |
字段 |
近实时(NRT)
ES是一个近实时的搜索引擎(平台),代表着从添加数据到能被搜索到只有很少的延迟。(大约是1s)
文档
Elasticsearch是面向文档的。可以把文档理解为关系型数据库中的一条记录,文档会被序列化成json格式,保存在Elasticsearch中。同样json对象由字段组成,每一个字段都有自己的类型(字符串,数值,布尔,二进制,日期范围类型)。当我们创建文档时,如果不指定类型,Elasticsearch会帮我们自动匹配类型。每个文档都一个ID(_id),你可以自己指定,也可以让Elasticsearch自动生成。json格式,支持数组/嵌套,在一个索引里面,你可以存储任意多的文档。
具体字段类型和属性的对应关系请参考官网:
https://www.elastic.co/guide/en/elasticsearch/reference/6.0/mapping-types.html
索引
索引是具有某种相似特性的文档集合。例如,您可以拥有客户数据的索引、产品目录的索引以及订单数据的索引。索引的名称必须全部是小写字母。在单个集群中,您可以定义任意多个索引。
类型
一个索引可以有多个类型。例如一个索引下可以有文章类型,也可以有用户类型,也可以有评论类型。

从6.0开始,type已经被逐渐废弃。在7.0之前,一个index可以设置多个types。7.0开始一个索引只能创建一个type(默认是_doc,索引创建以后会自动创建)
节点
节点是一个Elasticsearch实例,本质上就是一个java进程。
节点的类型主要分为如下几种:
master eligible节点
每个节点启动后,默认就是master eligible节点,可以通过node.master: false 禁止,
master eligible可以参加选举成为master节点,当第一个节点启动后,它会将自己选为master节点。
data节点
可以保存数据的节点。负责保存分片数据。
Coordinating(协调)节点
负责接收客户端请求,当请求发送到某个节点的时候,这个节点就成为了协调节点,将请求发送到合适的节点,最终把结果汇集到一起,返回给客户端。每个节点默认都起到了协调节点的职责。
分片和分片副本
一个索引可能会存储大量数据,这些数据可能超过单个节点的硬件限制。例如,十亿个文档的单个索引占用了1TB的磁盘空间,可能不适合单个节点的磁盘,或者可能太慢而无法单独满足来自单个节点的搜索请求。
为了解决此问题,Elasticsearch提供了将索引细分为多个碎片的功能。创建索引时,只需定义所需的分片数量即可。每个分片本身就是一个功能齐全且独立的“索引”,可以托管在群集中的任何节点上。
分片很重要,它可能分布在多个节点上。
在随时可能发生故障的网络环境中,分片副本非常有用,为了防止某节点因某种原因脱机。导致数据查询不到,Elasticsearch允许将索引分片的一个或多个副本制作为所谓的副本分片(简称副本)。如果分片/节点发生故障,分片副本可提供高可用性(相当于一个主从)。
重要的是要注意:副本碎片永远不会与从其复制原始碎片的节点分配在同一节点上。
例如:node1和node2的集群,如果分片1在node1节点,那么分片1的副本就不可能分布在node1节点,因为如果这样设计的话就没意义了,如果node1挂了,那么分片1 和它的副本都不可用了。
创建索引后,可以随时动态更改副本数,但不能更改分片数,因为如果修改了分片数的话会导致分片上的数据错乱。
Elasticsearch写数据原理

写请求发送到集群节点,比如发送到了node1,这个节点内部会去根据ID计算hash,计算这个ID到底属于哪个主分片(ID通过hash以后对主分片的数量取余),比如这个时候计算出来属于主分片2,这个时候node1节点会把请求转发到node2节点的主分片2,进行写入数据,当主分片2写入数据成功以后,会把请求并行转发到对应的两个副本R2-1和R2-2,写入成功以后返回到主分片,然后返回到node1,最后由node1返回到客户端,报告写入成功,如果写入副本的时候失败了,会把写入失败的分片移除(防止读取数据的时候从这个分片中读不到数据或者读到脏数据)。
以上写入都是写入到内存中,写入之前会先转换为段(这就是近实时中说到的,有1S的延迟时间),同时伴随有一个日志文件的写入,当写入到内存以后过五分钟以后,通过定时任务,才把数据写到磁盘上,日志文件的存在是为了解决定时任务5分钟期间内存出现问题导致读取不到内存数据的问题,如果内存出现问题,直接读取日志文件,写到磁盘。
官网参考:
https://www.elastic.co/guide/en/elasticsearch/reference/6.0/docs-replication.html
Elasticsearch读数据原理
Elasticsearch查询分为两个阶段: Query(查)和 Fetch(取),假设我们进行分页查询从 from到 from + size 的文档信息,下面是查询流程:
from:代表前面忽略多少数据,size:代表查询数据的条数
Query 阶段
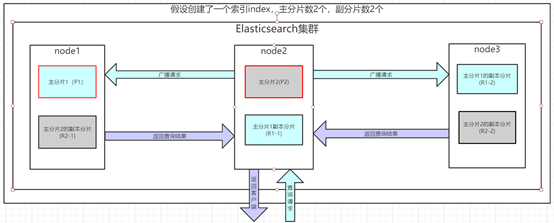
1、客户端发送一个search请求到node2上,node节点此时就是协调节点。
2、接着node2以协调节点的身份广播这个search请求到索引里面每一个主分片或者副分片上(不为主副),每个分片执行查询并进行排序,返回from+size个排序后的文档 ID给协调节点node2。
3、然后node2负责将所有分片查询返回的数据给合并到一个全局的排序的列表。
Fetch 阶段
1、协调节点node2从全局排序列表中,选取 from 到 from + size 个文档的 ID,并发送一个批量的查询请求到相关的分片上(即发送批量文档ID,根据ID查询文档)。
2、协调节点node2将查询到的结果集返回到客户端上。
官网参考:
https://www.elastic.co/guide/en/elasticsearch/reference/6.0/docs-replication.html
倒排索引
倒排索引就是为什么ES查询如此快的原因
官网地址:
https://www.elastic.co/guide/en/elasticsearch/guide/current/inverted-index.html
原理自行参考:通过分词到内存中找ID,再通过ID到磁盘上查找数据
https://blog.csdn.net/jiaojiao521765146514/article/details/83750548
https://www.cnblogs.com/dreamroute/p/8484457.html
Elasticsearch安装(linux)
下载安装包
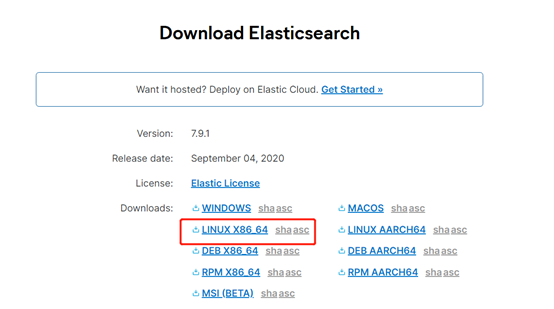
下载elasticsearch安装包,版本7.9.1(目前最新版本)
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
安装elasticsearch
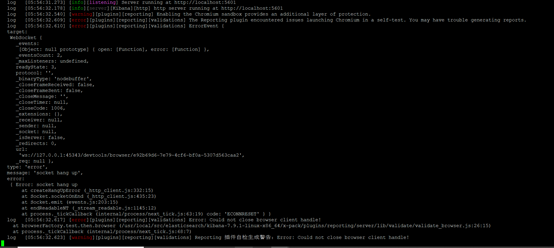
特别注意:
elasticsearch和kibana的安装路径不能有空格,要不然kibana启动会报如下错误
把安装包上传到服务器的安装目录并解压
注意:
elasticsearch是不允许使用root用户启动的
在6.xx之前,可以通过root用户启动。但是后来发现黑客可以通过elasticsearch获取root用户密码,所以为了安全性,在6版本之后就不能通过root启动elasticsearch
新建操作用户
|
groupadd elasticsearch useradd elasticsearch -g elasticsearch cd /usr/local/src/elasticsearch chown -R elasticsearch: elasticsearch elasticsearch-7.9.1 |
修改JVM参数
如果机器内存足够的话也可以默认,默认1G
|
vi config/jvm.options |
修改如下内容:
|
-Xms512m -Xmx512m |
修改ES相关配置
|
vi config/elasticsearch.yml |
修改如下内容:
|
#集群名称, 默认名称为elasticsearch cluster.name=zhongan-elasticsearch #节点名称 node.name=node-1 #允许访问的IP network.host: 0.0.0.0 #管理管端口 http.port: 9200 #允许成为主节点的节点名称 cluster.initial_master_nodes: ["node-1"] #数据保存路径 path.data: /usr/local/src/elasticsearch/elasticsearch-7.9.1/data #日志路径 path.logs: /usr/local/src/elasticsearch/elasticsearch-7.9.1/logs |
修改sysctl.conf
|
vi /etc/sysctl.conf |
写入如下内容:
|
vm.max_map_count=655360 #使配置生效 sysctl -p |
注:如果不修改,启动会报如下错误:
vm最大虚拟内存,max_map_count[65530]太低,至少增加到[262144]
|
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] |
修改limits.conf
|
vi /etc/security/limits.conf |
写入如下内容:
|
* soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096 |
* 所有用户
nofile - 打开文件的最大数目
noproc - 进程的最大数目
soft 指的是当前系统生效的设置值
hard 表明系统中所能设定的最大值
注:如果不修改,启动会报如下错误:
最大文件描述符[4096]对于elasticsearch进程可能太低,至少增加到[65536]
|
descriptors [4096] for elasticsearch process likely too low, increase to at least [65536] |
修改90-nproc.conf
|
vi /etc/security/limits.d/90-nproc.conf |
写入如下内容:
|
* soft nproc 4096 |
注:如果不修改,启动会报如下错误:
用户的最大线程数[2048]过低,增加到至少[4096]
|
max number of threads [2048] for user [tongtech] is too low, increase to at least [4096] |
启动
|
cd /usr/local/src/elasticsearch/elasticsearch-7.9.1/bin #以后台方式运行 ./elasticsearch -d |
出现如下日志表示启动成功

防火墙设置
需要把ES相关端口添加白名单
|
#开启9200端口 firewall-cmd --zone=public --add-port=9200/tcp --permanent #开启9300端口 firewall-cmd --zone=public --add-port=9300/tcp --permanent #重启防火墙 systemctl restart firewalld |
验证
浏览器访问:http://ip:9200/

Elasticsearch重启
|
ps -ef | grep elastic kill -9 PID |
Kibana安装(linux)
下载安装包
下载kibana安装包,版本7.9.1(需要和ES版本一致)
下载地址:https://www.elastic.co/cn/downloads/kibana

安装Kibana
把安装包上传到服务器的安装目录并解压
修改配置文件
|
vi /usr/local/src/elasticsearch/kibana-7.9.1-linux-x86_64/config/kibana.yml |
修改如下配置
|
#管理端端口 server.port: 5601 #允许访问的IP server.host: "0.0.0.0" #管理端语言,默认未英文,修改为中文 i18n.locale: "zh-CN" #ES地址 elasticsearch.hosts: ["http://localhost:9200"] |
启动kibana
|
cd /usr/local/src/elasticsearch/kibana-7.9.1-linux-x86_64/bin nohup ./kibana --allow-root & |
防火墙设置
把kibana端口设置为白名单
|
#开启5601端口 firewall-cmd --zone=public --add-port=5601/tcp --permanent #重启防火墙 systemctl restart firewalld |
访问kibana
浏览器访问:http://ip:5601/
出现如下界面表示启动成功

Kibana重启
|
netstat -apn|grep 5601 kill -9 PID |
Elasticsearch用户设置
完成Elasticsearch和kibana的安装以后发现管理端可以直接访问数据,这样是不安全的,下面就是Elasticsearch用户相关介绍
用户新增
Elasticsearch内部已经内置了一些用户,只需要设置这些用户的密码,并修改配置文件即可。
修改配置文件
修改elasticsearch.yml文件加入如下配置,启用节点上的Elasticsearch安全功能
|
xpack.security.enabled: true xpack.license.self_generated.type: basic xpack.security.transport.ssl.enabled: true |
重启ES,访问ES,这个时候需要用户名密码访问,如下截图:
设置用户密码
ES bin目录执行命令,依次设置用户密码
|
./elasticsearch-setup-passwords interactive |
用户登录

Kibana配置
这个时候访问kibana发现也需要登录
需要修改kibana的配置文件:kibana.yml
加入以下配置:
|
#ES的登录用户名 elasticsearch.username: "elastic" # ES的登录用户名密码,需要对应 elasticsearch.password: "123456" |
重启kibana,访问kibana
分词器安装
Elasticsearch内部已经内置了一些分词器,无需进一步配置即可在任何索引中使用
官网地址:
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html
|
Standard |
默认分词器 按词分类 小写处理 |
|
Simple |
非字母文本划分为多个词 小写处理 |
|
Stop |
小写处理 停用词过滤(the,a, is) |
|
Whitespace |
按空格切分 |
|
Keyword |
不分词,当成一整个term输出 |
|
Patter |
通过正则表达式进行分词 默认是 \W+(非字母进行分隔) |
|
Language |
提供了 30 多种常见语言的分词器 |
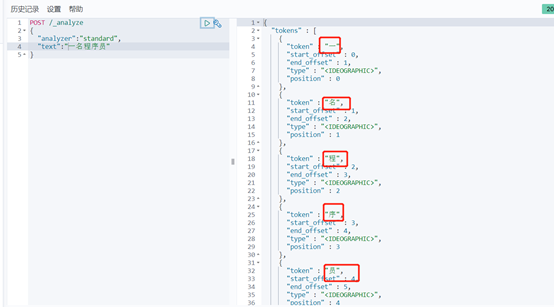
Standard分词器简单操作:
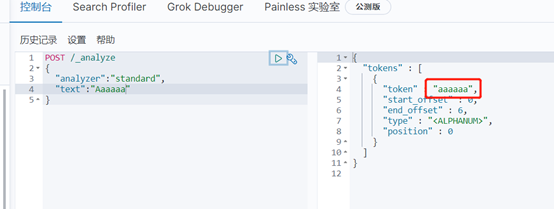
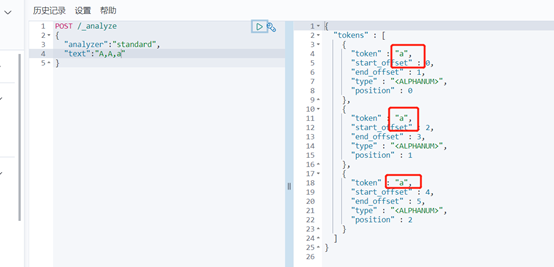
其他分词器自行尝试后看效果。。。
一般使用ES内置分词器即可,但是内置分词器对中文的分词效果较差,一段中文经过内置分词器分词以后会变为一个一个的汉字,所以需要用分词器插件,对中文分词时可以实现在词语之间分词。
常用中文分词器,IK、jieba、THULAC等,推荐使用IK分词器。
IK分词器
下载ik分词器安装包,版本7.9.1(需要和ES的版本对应)
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases

安装
安装包解压,在ES的plugins目录下创建一个ik文件夹,把解压后的内容放到该文件夹即可。
验证
重启ES,执行如下命令:
|
POST /_analyze { "analyzer": "ik_max_word", "text": "一名程序员" } |

ElasticSearch基本API
索引操作
创建索引
官网地址:
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-create-index.html
|
PUT /test { "settings": { "number_of_shards": "2", //分片数 "number_of_replicas": "0", //副本数 "write.wait_for_active_shards": 1 //操作之前必须处于活动状态的分片分片数 } } |
修改索引
|
PUT test/_settings { "number_of_replicas" : "2"//修改索引的副本数位2 } |
删除索引
|
DELETE /test |
文档操作
插入数据
|
//指定id POST /test/_doc/1 { "id":1001, "name":"张三", "age":20, "sex":"男" } |
|
//不指定id es帮我们自动生成 POST /test/_doc { "id":1002, "name":"三哥", "age":20, "sex":"男" } |
更新数据
在Elasticsearch中,文档数据是不能修改的,但是可以通过覆盖的方式进行更新
|
POST /test/_doc/1 { "id":1001, "name":"张三四五", "age":20, "sex":"男" } |
局部更新
其实Elasticsearch内部对局部更新的实际执行和全量替换方式是几乎一样的,其步骤如下
1、内部先获取到对应的文档;
2、将传递过来的field更新到文档的json中(这一步实质上也是一样的);
3、将老的文档标记为deleted(到一定时候才会物理删除);
4、将修改后的新的文档创建出来
|
POST /test/_update/1 { "doc":{ "age":46 } } |
删除数据
|
DELETE /test/_doc/1 |
根据ID搜索数据
|
GET /test/_doc/h5a3n3QBhTn7IjwCRtEV #去掉元数据查询 GET /test/_source/h5a3n3QBhTn7IjwCRtEV #去掉元数据并且返回指定字段 GET /test/_source/h5a3n3QBhTn7IjwCRtEV?_source=id,name |
根据属性查询
|
GET /test/_search?q=age:20 //查询age为20的 |
返回节点说明
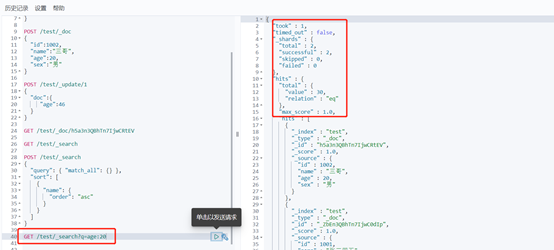
took Elasticsearch运行查询需要多长时间(以毫秒为单位)
timed_out 搜索请求是否超时
_shards 搜索了多少碎片,并对多少碎片成功、失败或跳过进行了细分。
max_score 找到最相关的文档的得分
搜索全部数据
|
GET /test/_search //默认最多返回10条数据 GET /test/_search?size=1000 //指定查询的条数 |
高级检索
查询年龄等于23的
|
POST /test/_search { "query" : { "match" : { "age" : 20 } } } |
查询地址是南京市或者上海市的数据
|
GET /test/_search { "query": { "match": { "address": "南京市 上海市" } } } |
查询地址是(南京市 上海市)的数据
|
GET /test/_search { "query": { "match_phrase": { "address": "南京市 上海市" } } } |
注意:
match 中如果加空格,那么会被认为两个单词,包含任意一个单词将被查询到。
match_parase 将忽略空格,将该字符认为一个整体,会在索引中匹配包含这个整体的文档。
查询年龄大于20 并且性别是男的
|
POST /test/_search { "query": { "bool": { "filter": { "range": { "age": { "gt": 20 } } }, "must": { "match": { "sex": "男" } } } } } |
聚合
|
avg :平均值 max:最大值 min:最小值 sum:求和 |
查询前100条数据的年龄平均值
|
POST /test/_search { "aggs": { "test": { "avg": { "field": "age" } } }, "size": 100 } |
分页查询
from跳过开头的结果数;size查询的结果数,默认为10
|
GET /test/_search?from=1&size=10 |
浅分页
浅分页,它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据。这样其实白白浪费了前10条的查询
|
GET /test/_search { "sort": [ { "age": { "order": "desc" } } ], "query": { "match": { "name": "张三" } }, "size": 10, "from": 0 } |
scroll 深分页
scroll 深分页,使用scroll,每次只能获取一页的内容,然后会返回一个scroll_id。根据返回的这个scroll_id可以不断地获取下一页的内容,因为查一次获取下一页,所以scroll并不适用于有跳页的情景
scroll=5m表示设置scroll_id保留5分钟可用。
使用scroll必须要将from设置为0。
size决定后面每次调用_search搜索返回的数量
|
GET /test/_search?scroll=5m { "size": 10, "from": 0, "sort": [ { "_id": { "order": "desc" } } ] } 会返回一个: "_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAhRzWmJzbjNRQmhUbjdJandDbWRjMgAAAAAAABHZFlRKaUV2aGRMVEM2LXM1enN6c0dLb0EUc3Bic24zUUJoVG43SWp3Q21kYzIAAAAAAAAR2hZUSmlFdmhkTFRDNi1zNXpzenNHS29B" 以后调用: GET _search/scroll { "scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAhRzWmJzbjNRQmhUbjdJandDbWRjMgAAAAAAABHZFlRKaUV2aGRMVEM2LXM1enN6c0dLb0EUc3Bic24zUUJoVG43SWp3Q21kYzIAAAAAAAAR2hZUSmlFdmhkTFRDNi1zNXpzenNHS29B", "scroll": "5m" } 删除scroll_id DELETE _search/scroll/ FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAhRzWmJzbjNRQmhUbjdJandDbWRjMgAAAAAAABHZFlRKaUV2aGRMVEM2LXM1enN6c0dLb0EUc3Bic24zUUJoVG43SWp3Q21kYzIAAAAAAAAR2hZUSmlFdmhkTFRDNi1zNXpzenNHS29B 删除所有scroll_id DELETE _search/scroll/_all |
结构化查询
term查询
term 主要用于精确匹配哪些值,比如数字,日期,布尔值等
|
POST /test/_search { "query" : { "term" : { "age" : 20 } } } |
terms查询
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配:
|
POST /test/_search { "query" : { "terms" : { "age" : [30,46] } } } |
range查询
range 过滤允许我们按照指定范围查找一批数据:
|
gt 大于 gte 大于等于 lt 小于 lte 小于等于 |
|
POST /test/_search { "query": { "range": { "age": { "gte": 25, "lte": 50 } } } } |
exists查询
exists 查询可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的 IS_NULL 条件,包含这个字段就返回这条数据
|
POST /test/_search { "query": { "exists": { "field": "address" } } } |
match查询
match 查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。如果你使用 match 查询一个全文本字段,它会在真正查询之前先用分词器去分析一下查询字符;如果用 match 下指定了一个确切值,在遇到数字,日期,布尔值的字符串时,它将为你搜索你给定的值,不再分词:
|
POST /test/_search { "query" : { "match" : { "name" : "三个" } } } |
bool查询
bool 查询可以用来合并多个条件查询结果的布尔逻辑,它包含一下操作符:
|
must 多个查询条件的完全匹配,相当于 and 。 must_not 多个查询条件的相反匹配,相当于 not 。 should 至少有一个查询条件匹配, 相当于 or 。 |
这些参数可以分别继承一个查询条件或者一个查询条件的数组:
|
POST /test/_search { "query": { "bool": { "must": { "term": { "sex": "男" } }, "must_not": { "term": { "age": "29" } }, "should": [ { "term": { "sex": "男" } }, { "term": { "id": 1003 } } ] } } } |
Elasticsearch整合Springboot
版本对应关系
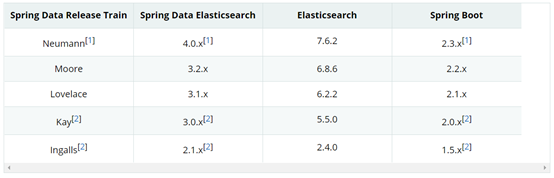
由于Elasticsearch版本为7.9.1,所以Springboot版本必须至少为2.3.x,此处采用目前官网最新版本:2.3.4.RELEASE
导入依赖
|
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.4.RELEASE</version> <relativePath/> </parent> <!--elasticsearch包--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency> <!--单元测试--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> |
配置类
配置类里面配置了连接ES的连接信息,相当于配置了一个数据源
|
import org.elasticsearch.client.RestHighLevelClient; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.elasticsearch.client.ClientConfiguration; import org.springframework.data.elasticsearch.client.RestClients; import org.springframework.data.elasticsearch.config.AbstractElasticsearchConfiguration; @Configuration public class RestClientConfig extends AbstractElasticsearchConfiguration { @Override @Bean public RestHighLevelClient elasticsearchClient() { final ClientConfiguration clientConfiguration = ClientConfiguration.builder().connectedTo("10.0.2.102:9200") .withBasicAuth("elastic", "123456").build(); return RestClients.create(clientConfiguration).rest(); } } |
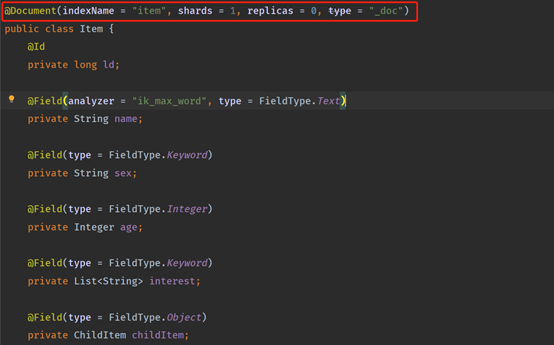
创建实体类
实体类上加上Document注解,指定索引名称和主分片副分片数量,type可以不用指定了,默认一个索引只有一个类型,属性加上对应的注解,具体属性和字段对应关系文档章节已经说明,请自行参考。
analyzer = "ik_max_word"是指定IK分词器,说明name字段分词的时候需要根据IK分词器去分词,不采用ES内置的分词器,也可以用ES内置的分词器。
测试
注入elasticsearchRestTemplate
|
@Autowired private ElasticsearchRestTemplate elasticsearchRestTemplate; |
索引创建
|
/** * 创建索引 */ @Test public void createIndex() throws Exception { IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(Item.class); boolean exists = indexOperations.exists(); System.out.println("索引是否已经存在:"+exists); } |
数据新增
|
/** * 测试新增数据 */ @Test void save() { SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); String str = simpleDateFormat.format(new Date()); Goods goods = new Goods(1093l, "", "测试数据" + str, 37400, 20, 100, "https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/10441/9/5525/162976/5c177debEaf815b43/3aa7d4dc182cc4d9.jpg!q70.jpg.webp", "https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/10441/9/5525/162976/5c177debEaf815b43/3aa7d4dc182cc4d9.jpg!q70.jpg.webp", 10, str, str, "10000243333000", 558, "测试", "", "", 1, 1, 1, 5L); /*方法1*/ Goods save = elasticsearchRestTemplate.save(goods); System.out.println(save.toString()); /*方法2*/ // IndexQuery indexQuery = new IndexQueryBuilder() // .withId(goods.getId()+"") // .withObject(goods) // .build(); // String documentId = elasticsearchRestTemplate.index(indexQuery,IndexCoordinates.of("goods")); // System.out.println(documentId); } |
数据查询详情
|
/** * 测试通过ID查询 */ @Test void searchById() { Goods goods = elasticsearchRestTemplate.get("1092", Goods.class, IndexCoordinates.of("goods")); System.out.println(goods.toString()); } |
注意:
查询的时候如果是根据ID查询,那么这个ID指的是文档id(_id),而且查询返回的实体里面的id也是文档id(分页查询返回结果中的实体id也是文档id),所以最好让文档id和业务数据的id保持一致,如果不一致,请注意实体id和ES文档id类型兼容,因为ES默认生成的文档id是字符串,如果业务id为long类型的话查询会报错。
数据修改
|
/** * 测试修改数据 */ @Test void update() { Map<String, Object> map = new HashMap<>(); map.put("name", "测试数据修改"); UpdateQuery updateQuery = UpdateQuery.builder("1093").withDocument(Document.from(map)).build(); UpdateResponse updateResponse = elasticsearchRestTemplate.update(updateQuery, IndexCoordinates.of("goods")); System.out.println(updateResponse.getResult()); } |
分页查询
|
/** * 分页查询 */ @Test void getByMatch() { MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", "测试"); NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder(); //id排序 FieldSortBuilder sortBuilder = SortBuilders.fieldSort("id").order(SortOrder.ASC); //分页 Pageable pageable = PageRequest.of(0, 10); nativeSearchQueryBuilder.withFilter(matchQueryBuilder).withSort(sortBuilder).withPageable(pageable); NativeSearchQuery nativeSearchQuery = nativeSearchQueryBuilder.build(); SearchHits<Goods> goods = elasticsearchRestTemplate .search(nativeSearchQuery, Goods.class, IndexCoordinates.of("goods")); goods.getSearchHits().forEach(info -> { Goods good = info.getContent(); System.out.println(good.toString()); }); } |
Elasticsearch安装、原理学习总结的更多相关文章
- elasticsearch原理学习笔记
https://mp.weixin.qq.com/s/dn1n2FGwG9BNQuJUMVmo7w 感谢,透彻的讲解 整理笔记 请说出 唐诗中 包含 前 的诗句 ...... 其实你都会,只是想不起 ...
- Elasticsearch工作原理
一.关于搜索引擎 各位知道,搜索程序一般由索引链及搜索组件组成. 索引链功能的实现需要按照几个独立的步骤依次完成:检索原始内容.根据原始内容来创建对应的文档.对创建的文档进行索引. 搜索组件用于接收用 ...
- ElasticSearch 安装, 带视频
疯狂创客圈 Java 高并发[ 亿级流量聊天室实战]实战系列 [博客园总入口 ] 架构师成长+面试必备之 高并发基础书籍 [Netty Zookeeper Redis 高并发实战 ] 疯狂创客圈 高并 ...
- redis 安装配置学习笔记
redis 安装配置学习笔记 //wget http://download.redis.io/releases/redis-2.8.17.tar.gz 下载最新版本 wget http://downl ...
- ElasticSearch概述及Linux下的单机ElasticSearch安装
原文链接:http://blog.csdn.net/w12345_ww/article/details/52182264 这两天在项目中要涉及到ElasticSearch的使用,就上网去搜索了一些这方 ...
- elasticsearch安装与使用(1)-- centos7 elasticsearch的两种简单安装方法
转自:http://www.cnblogs.com/miao-zp/p/6003160.html 简单修改 前言 elasticsearch(下面称为ES)是一个基于Lucene的搜索服务器(By 百 ...
- elasticsearch安装及与springboot2.x整合
关于elasticsearch是什么.elasticsearch的原理及elasticsearch能干什么,就不多说了,主要记录下自己的一个使用过程. 1.安装 elasticsearch是用java ...
- elasticsearch安装教程
目录 1 java8 环境 2 安装elasticsearch 3 安装kibana 4. 单服务器部署多个节点 参考: 1 java8 环境 elasticsearch需要安装java 8 环境,配 ...
- Android自复制传播APP原理学习(翻译)
Android自复制传播APP原理学习(翻译) 1 背景介绍 论文链接:http://arxiv.org/abs/1511.00444 项目地址:https://github.com/Tribler ...
随机推荐
- Mockito鸡尾酒第一杯 单测Mock
鸡尾酒 Mockito是Java的单元测试Mock框架. 它的logo是一杯古巴最著名的鸡尾酒Mojito, Mojito鸡尾酒,源自古巴的哈瓦那,带有浓厚的加勒比海风情. 并不浓烈,但是喝一杯下去, ...
- 从《三体》到“中美科技战”,3分钟理解“网络”D丝为什么要迎娶“算力”白富美
摘要:在多维的世界里,高维的文明对于低维文明具有碾压的优势,而网络也正在从二维走向三维!网络硬件的竞争主要是“芯片+算法”. 从三体到中美科技战,理解网络与算力深度融合助力高维度竞争 1:对抗封锁,需 ...
- 服务应用突然宕机了?别怕,Dubbo 帮你自动搞定服务隔离!
某日中午,午睡正香的时候,接到系统的报警电话,提示生产某物理机异常宕机了,目前该物理机已恢复,需要重启上面部署的应用. 这时瞬间没有了睡意,登上堡垒机,快速重启了应用,系统恢复正常.本想着继续午睡,但 ...
- ClassFile与JClass
本次大作业中 java程序——>二进制流(byte[ ]表示)——>ClassFile对象——>JClass ClassFile的字段:magic,minorversion..... ...
- SpringBoot中关于Excel的导入和导出
前言 由于在最近的项目中使用Excel导入和导出较为频繁,以此篇博客作为记录,方便日后查阅.本文前台页面将使用layui,来演示对Excel文件导入和导出的效果.本文代码已上传至我的gitHub, ...
- 科赫雪花利用python海龟绘图代码
#KochDraw.py import turtle //海龟绘图 def koch(size, n): if n == 0: turtle.fd(size) else: for angle in [ ...
- ES6常用总结(一)
let,const let声明变量,const声明常量,两者均为块级作用域 let,const在块级作用域内不允许重复声明 const声明的基本数据类型不可以修改,引用数据类型可以修改.具体看我的另一 ...
- 攻防世界——web新手练习区解题总结<3>(9-12题)
第九题simple_php: 看题目说是php代码,那必定要用到php的知识,让我们先获取在线场景,得到如下网页 仔细看这个代码,意思大概是: 1.当a==0且a为真时输出flag1 2.当b为数字退 ...
- IOS 提审
关于上架AppStore最后一步的“出口合规信息”.“内容版权”.“广告标识符”的选择 https://blog.csdn.net/ashimar_a/article/details/51745675
- 【代码优化】Unity查漏补缺
1.XML: 使用Unity社区中的开源脚本(Js语言)解析XML文件,网址:http://dev.grumpyferret.com/unity/,已打包XMLParser.unitypackage, ...