关系型数据库查询语言 SQL 和图数据库查询语言 nGQL 对比
摘要:这篇文章将介绍图数据库 Nebula Graph 的查询语言 nGQL 和 SQL 的区别。
本文首发于 Nebula Graph 官方博客:https://nebula-graph.com.cn/posts/sql-vs-ngql-comparison/

虽然本文主要介绍 nGQL 和 SQL 的区别,但是我们不会深入探讨这两种语言,而是将这两种语言做对比,以帮助你从 SQL 过渡到 nGQL。
SQL (Structured Query Language) 是具有数据操纵和数据定义等多种功能的数据库语言,这种语言是一种特定目的编程语言,用于管理关系数据库管理系统(RDBMS),或在关系流数据管理系统(RDSMS)中进行流处理。
nGQL 是一种类 SQL 的声明型的文本查询语言,相比于 SQL, nGQL 为可扩展、支持图遍历、模式匹配、分布式事务(开发中)的图数据库查询语言。
概念对比
| 对比项 | SQL | nGQL |
|---|---|---|
| 点 | \ | 点 |
| 边 | \ | 边 |
| 点类型 | \ | tag |
| 边类型 | \ | edge type |
| 点 ID | 主键 | vid |
| 边 ID | 复合主键 | 起点、终点、rank |
| 列 | 列 | 点或边的属性 |
| 行 | 行 | 点或边 |
语法对比
数据定义语言 (DDL)
数据定义语言(DDL)用于创建或修改数据库的结构,也就是 schema。
| 对比项 | SQL | nGQL |
|---|---|---|
| 创建图空间(数据库) | CREATE DATABASE <database_name> |
CREATE SPACE <space_name> |
| 列出图空间(数据库) | SHOW DATABASES | SHOW SPACES |
| 使用图空间(数据库) | USE <database_name> |
USE <space_name> |
| 删除图空间(数据库) | DROP DATABASE <database_name> |
DROP SPACE <space_name> |
| 修改图空间(数据库) | ALTER DATABASE <database_name> alter_option |
\ |
| 创建 tags/edges | \ | CREATE TAG | EDGE <tag_name> |
| 创建表 | CREATE TABLE <tbl_name> (create_definition,...) |
\ |
| 列出表列名 | SHOW COLUMNS FROM <tbl_name> |
\ |
| 列出 tags/edges | \ | SHOW TAGS | EDGES |
| Describe tags/edge | \ | DESCRIBE TAG | EDGE <tag_name \| edge_name> |
| 修改 tags/edge | \ | ALTER TAG | EDGE <tag_name \| edge_name> |
| 修改表 | ALTER TABLE <tbl_name> |
\ |
索引
| 对比项 | SQL | nGQL |
|---|---|---|
| 创建索引 | CREATE INDEX | CREATE {TAG | EDGE} INDEX |
| 删除索引 | DROP INDEX | DROP {TAG | EDGE} INDEX |
| 列出索引 | SHOW INDEX FROM | SHOW {TAG | EDGE} INDEXES |
| 重构索引 | ANALYZE TABLE | REBUILD {TAG | EDGE} INDEX <index_name> [OFFLINE] |
数据操作语言(DML)
数据操作语言(DML)用于操作数据库中的数据。
| 对比项 | SQL | nGQL |
|---|---|---|
| 插入数据 | INSERT IGNORE INTO <tbl_name> [(col_name [, col_name] ...)] {VALUES | VALUE} [(value_list) [, (value_list)] |
INSERT VERTEX <tag_name> (prop_name_list[, prop_name_list]) {VALUES | VALUE} vid: (prop_value_list[, prop_value_list]) INSERT EDGE <edge_name> ( <prop_name_list> ) VALUES | VALUE <src_vid> -> <dst_vid>[@<rank>] : ( <prop_value_list> ) |
| 查询数据 | SELECT | GO, FETCH |
| 更新数据 | UPDATE <tbl_name> SET field1=new-value1, field2=new-value2 [WHERE Clause] |
UPDATE VERTEX <vid> SET <update_columns> [WHEN <condition>] UPDATE EDGE <edge> SET <update_columns> [WHEN <condition>] |
| 删除数据 | DELETE FROM <tbl_name> [WHERE Clause] |
DELETE EDGE <edge_type> <vid> -> <vid>[@<rank>] [, <vid> -> <vid> ...] DELETE VERTEX <vid_list> |
| 拼接数据 | JOIN | \| |
数据查询语言(DQL)
数据查询语言(DQL)语句用于执行数据查询。本节说明如何使用 SQL 语句和 nGQL 语句查询数据。
SELECT
[DISTINCT]
select_expr [, select_expr] ...
[FROM table_references]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}]
[HAVING where_condition]
[ORDER BY {col_name | expr | position} [ASC | DESC]]
GO [[<M> TO] <N> STEPS ] FROM <node_list>
OVER <edge_type_list> [REVERSELY] [BIDIRECT]
[WHERE where_condition]
[YIELD [DISTINCT] <return_list>]
[| ORDER BY <expression> [ASC | DESC]]
[| LIMIT [<offset_value>,] <number_rows>]
[| GROUP BY {col_name | expr | position} YIELD <col_name>]
<node_list>
| <vid> [, <vid> ...]
| $-.id
<edge_type_list>
edge_type [, edge_type ...]
<return_list>
<col_name> [AS <col_alias>] [, <col_name> [AS <col_alias>] ...]
数据控制语言(DCL)
数据控制语言(DCL)包含诸如 GRANT 和 REVOKE 之类的命令,这些命令主要用来处理数据库系统的权限、其他控件。
| 对比项 | SQL | nGQL |
|---|---|---|
| 创建用户 | CREATE USER | CREATE USER |
| 删除用户 | DROP USER | DROP USER |
| 更改密码 | SET PASSWORD | CHANGE PASSWORD |
| 授予权限 | GRANT <priv_type> ON [object_type] TO <user> |
GRANT ROLE <role_type> ON <space> TO <user> |
| 删除权限 | REVOKE <priv_type> ON [object_type] TO <user> |
REVOKE ROLE <role_type> ON <space> FROM <user> |
数据模型
查询语句基于以下数据模型:
RDBMS 关系结构图
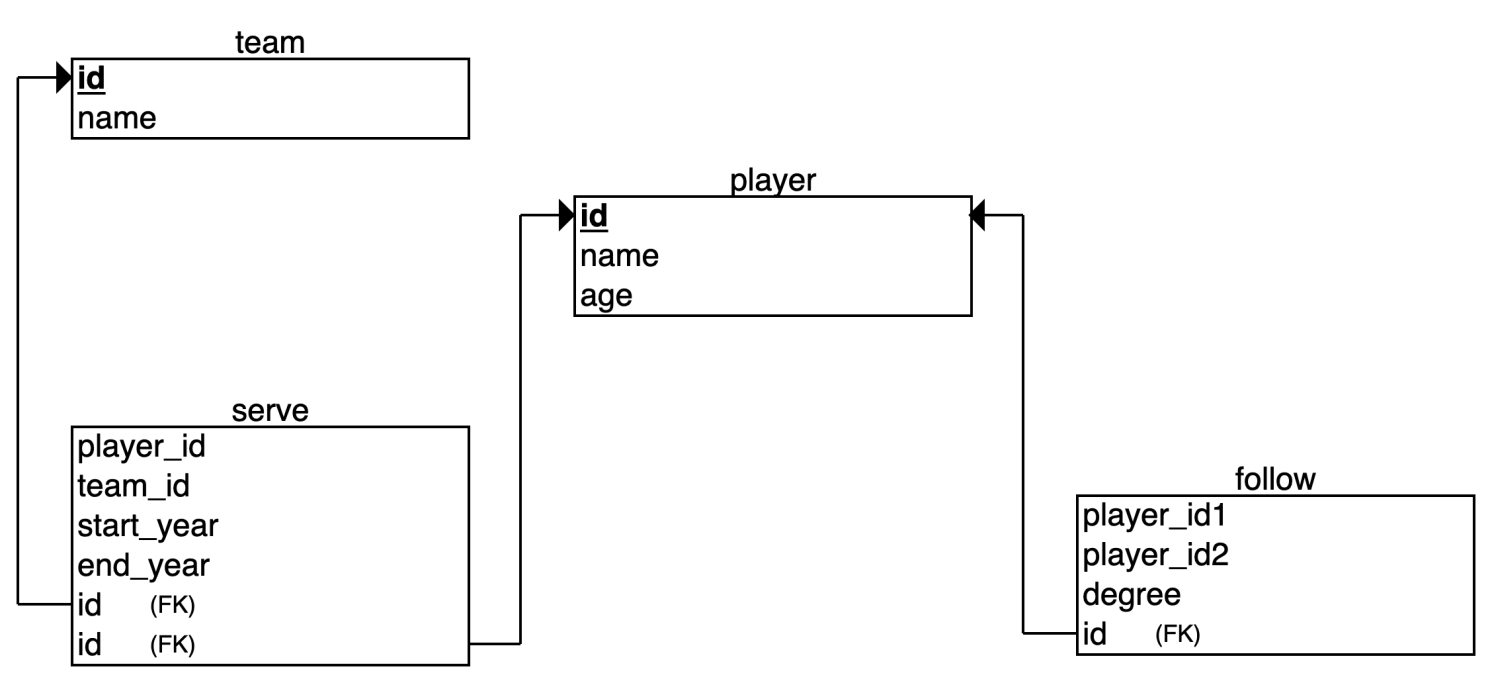
Nebula Graph 最小模型图
本文将使用 NBA 数据集。该数据集包含两种类型的点,也就是两个标签,即 player 和 team ;两种类型的边,分别是 serve 和 follow。
在关系型数据管理系统中(RDBMS)中,我们用表来表示点以及与点相关的边(连接表)。因此,我们创建了以下表格:player、team、serve 和 follow。在 Nebula Graph 中,基本数据单位是顶点和边。两者都可以拥有属性,相当于 RDBMS 中的属性。
在 Nebula Graph 中,点之间的关系由边表示。每条边都有一种类型,在 NBA 数据集中,我们使用边类型 serve 和 follow 来区分两种类型的边。
示例数据
在 RDBMS 插入数据
首先,让我们看看如何在 RDBMS 中插入数据。我们先创建一些表,然后为这些表插入数据。
CREATE TABLE player (id INT, name VARCHAR(100), age INT);
CREATE TABLE team (id INT, name VARCHAR(100));
CREATE TABLE serve (player_id INT, team_id INT, start_year INT, end_year INT);
CREATE TABLE follow (player_id1 INT, player_id2 INT, degree INT);
然后插入数据。
INSERT INTO player
VALUES
(100, 'Tim Duncan', 42),
(101, 'Tony Parker', 36),
(102, 'LaMarcus Aldridge', 33),
(103, 'Rudy Gay',32),
(104, 'Marco Belinelli', 32),
(105, 'Danny Green', 31),
(106, 'Kyle Anderson', 25),
(107, 'Aron Baynes', 32),
(108, 'Boris Diaw', 36),
(109, 'Tiago Splitter', 34),
(110, 'Cory Joseph', 27);
INSERT INTO team
VALUES
(200, 'Warriors'),
(201, 'Nuggets'),
(202, 'Rockets'),
(203, 'Trail'),
(204, 'Spurs'),
(205, 'Thunders'),
(206, 'Jazz'),
(207, 'Clippers'),
(208, 'Kings');
INSERT INTO serve
VALUES
(100,200,1997,2016),
(101,200,1999,2010),
(102,200,2001,2005),
(106,200,2000,2011),
(107,200,2001,2009),
(103,201,1999,2018),
(104,201,2006,2015),
(107,201,2007,2010),
(108,201,2010,2016),
(109,201,2011,2015),
(105,202,2015,2019),
(109,202,2017,2019),
(110,202,2007,2009);
INSERT INTO follow
VALUES
(100,101,95),
(100,102,91),
(100,106,90),
(101,100,95),
(101,102,91),
(102,101,75),
(103,102,70),
(104,103,50),
(104,105,60),
(105,104,83),
(105,110,87),
(106,100,88),
(106,107,81),
(107,106,92),
(107,108,97),
(108,109,95),
(109,110,78),
(110,109,72),
(110,105,85);
在 Nebula Graph 插入数据
在 Nebula Graph 中插入数据与上述类似。首先,我们需要定义好数据结构,也就是创建好 schema。然后可以选择手动或使用 Nebula Graph Studio (Nebula Graph 的可视化工具)导入数据。这里我们手动添加数据。
在下方的 INSERT 插入语句中,我们向图空间 NBA 插入了球员数据(这和在 MySQL 中插入数据类似)。
INSERT VERTEX player(name, age) VALUES
100: ('Tim Duncan', 42),
101: ('Tony Parker', 36),
102: ('LaMarcus Aldridge', 33),
103: ('Rudy Gay', 32),
104: ('Marco Belinelli', 32),
105: ('Danny Green', 31),
106: ('Kyle Anderson', 25),
107: ('Aron Baynes', 32),
108: ('Boris Diaw', 36),
109: ('Tiago Splitter', 34),
110: ('Cory Joseph', 27);
考虑到篇幅限制,此处我们将跳过插入球队和边的重复步骤。你可以点击此处下载示例数据亲自尝试。
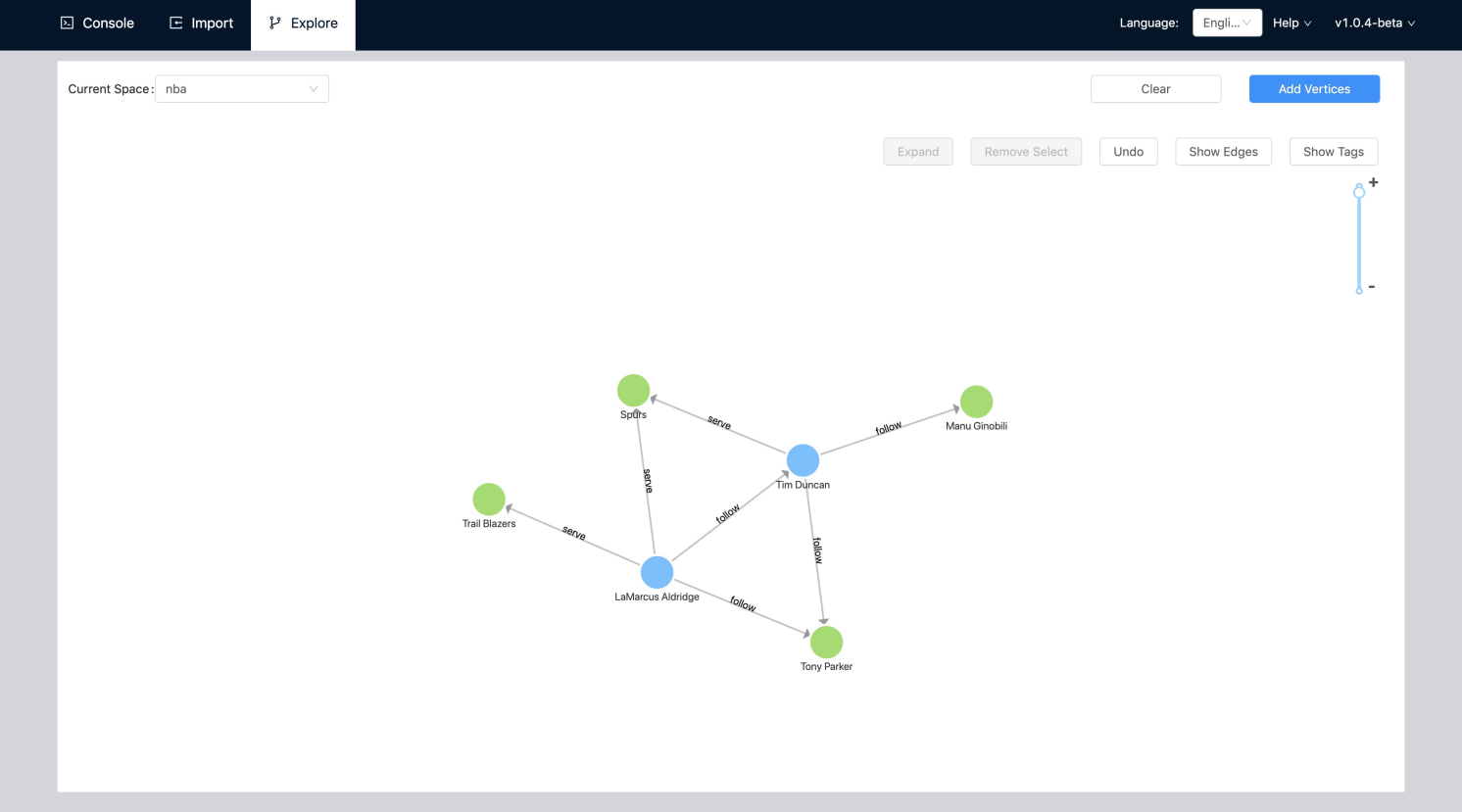
增删改查(CRUD)
本节介绍如何使用 SQL 和 nGQL 语句创建(C)、读取(R)、更新(U)和删除(D)数据。
插入数据
mysql> INSERT INTO player VALUES (100, 'Tim Duncan', 42);
nebula> INSERT VERTEX player(name, age) VALUES 100: ('Tim Duncan', 42);
查询数据
查找 ID 为 100 的球员并返回其 name 属性:
mysql> SELECT player.name FROM player WHERE player.id = 100;
nebula> FETCH PROP ON player 100 YIELD player.name;
更新数据
mysql> UPDATE player SET name = 'Tim';
nebula> UPDATE VERTEX 100 SET player.name = "Tim";
删除数据
mysql> DELETE FROM player WHERE name = 'Tim';
nebula> DELETE VERTEX 121;
nebula> DELETE EDGE follow 100 -> 200;
建立索引
返回年龄超过 36 岁的球员。
SELECT player.name
FROM player
WHERE player.age < 36;
使用 nGQL 查询有些不同,因为您必须在过滤属性之前创建索引。更多信息请参见 索引文档。
CREATE TAG INDEX player_age ON player(age);
REBUILD TAG INDEX player_age OFFLINE;
LOOKUP ON player WHERE player.age < 36;
示例查询
本节提供一些示例查询供您参考。
示例 1
在表 player 中查询 ID 为 100 的球员并返回其 name 属性。
SELECT player.name
FROM player
WHERE player.id = 100;
接下来使用 Nebula Graph 查找 ID 为 100 的球员并返回其 name 属性。
FETCH PROP ON player 100 YIELD player.name;
Nebula Graph 使用 FETCH 关键字获取特定点或边的属性。本例中,属性即为点 100 的名称。nGQL 中的 YIELD 关键字相当于 SQL 中的 SELECT。
示例 2
查找球员 Tim Duncan 并返回他效力的所有球队。
SELECT a.id, a.name, c.name
FROM player a
JOIN serve b ON a.id=b.player_id
JOIN team c ON c.id=b.team_id
WHERE a.name = 'Tim Duncan'
使用如下 nGQL 语句完成相同操作:
CREATE TAG INDEX player_name ON player(name);
REBUILD TAG INDEX player_name OFFLINE;
LOOKUP ON player WHERE player.name == 'Tim Duncan' YIELD player.name AS name | GO FROM $-.VertexID OVER serve YIELD $-.name, $$.team.name;
这里需要注意一下,在 nGQL 中的等于操作采用的是 C 语言风格的 ==,而不是SQL风格的 =。
示例 3
以下查询略复杂,现在我们来查询球员 Tim Duncan 的队友。
SELECT a.id, a.name, c.name
FROM player a
JOIN serve b ON a.id=b.player_id
JOIN team c ON c.id=b.team_id
WHERE c.name IN (SELECT c.name
FROM player a
JOIN serve b ON a.id=b.player_id
JOIN team c ON c.id=b.team_id
WHERE a.name = 'Tim Duncan')
nGQL 则使用管道将前一个子句的结果作为下一个子句的输入。
GO FROM 100 OVER serve YIELD serve._dst AS Team | GO FROM $-.Team OVER serve REVERSELY YIELD $$.player.name;
您可能已经注意到了,我们仅在 SQL 中使用了 JOIN。这是因为 Nebula Graph 只是使用类似 Shell 的管道对子查询进行嵌套,这样更符合我们的阅读习惯也更简洁。
参考资料
我们建议您亲自尝试上述查询语句,这将帮您更好地理解 SQL 和 nGQL,并节省您上手 nGQL 的学习时间。以下是一些参考资料:
作者有话说:Hi,Hi ,大家好,我是 Amber,Nebula Graph 的文档工程师,希望上述内容可以给大家带来些许启发。限于水平,如有不当之处还请斧正,在此感谢^^
喜欢这篇文章?来来来,给我们的 GitHub 点个 star 表鼓励啦~~ ♂️♀️ [手动跪谢]
交流图数据库技术?交个朋友,Nebula Graph 官方小助手微信:NebulaGraphbot 拉你进交流群~~
{kind=link}
关系型数据库查询语言 SQL 和图数据库查询语言 nGQL 对比的更多相关文章
- 初识SQL Server2017 图数据库(一)
背景: 图数据库对于表现和遍历复杂的实体之间关系是很有效果的.而这些在传统的关系型数据库中尤其是对于报表而言很难实现.如果把传统关系型数据库比做火车的话,那么到现在大数据时代,图数据库可比做高铁.它已 ...
- SQL语句创建数据库,SQL语句删除数据库,SQL语句创建表,SQL语句删除表,SQL语句添加约束,SQL语句删除约束
创建数据库: CREATE DATABASE Test --要创建的数据库名称 ON PRIMARY ( --数据库文件的具体描述 NAME='Test_data', --主数据文件的逻辑名称 FIL ...
- MySQL数据库执行sql语句创建数据库和表提示The 'InnoDB' feature is disabled; you need MySQL built with 'InnoDB' to have it working
MySQL创建数据库 只想sql文件创建表时候提示 The 'InnoDB' feature is disabled; you need MySQL built with 'InnoDB' to ha ...
- 陈宏智:字节跳动自研万亿级图数据库ByteGraph及其应用与挑战
导读: 作为一种基础的数据结构,图数据的应用场景无处不在,如社交.风控.搜广推.生物信息学中的蛋白质分析等.如何高效地对海量的图数据进行存储.查询.计算及分析,是当前业界热门的方向.本文将介绍字节跳动 ...
- [SQL] SQL 基础知识梳理(一)- 数据库与 SQL
SQL 基础知识梳理(一)- 数据库与 SQL [博主]反骨仔 [原文地址]http://www.cnblogs.com/liqingwen/p/5902856.html 目录 What's 数据库 ...
- Cayley图数据库的简介及使用
图数据库 在如今数据库群雄逐鹿的时代中,非关系型数据库(NoSQL)已经占据了半壁江山,而图数据库(Graph Database)更是攻城略地,成为其中的佼佼者. 所谓图数据库,它应用图理论( ...
- 数据库学习---SQL基础(一)
数据库学习---SQL基础(一) 数据库学习---SQL基础(二) 数据库学习---SQL基础(三) SQL(struct query language)结构化查询语言:一种专门与数据库通信的语言, ...
- 图数据库:AgensGraph
文章目录 AgensGraph简介 官网及下载 安装AgensGraph 上传并解压 添加agens用户 配置.bashrc 初始化并启动 初始化数据库 启动数据库 执行交互式终端 图数据库基础概念 ...
- 微软亚洲研究院开源图数据库GraphView
我们很高兴地宣布,由微软亚洲研究院系统算法组开发的图数据库GraphView通过GitHub平台开源.GraphView是一款中间件软件,方便用户使用关系数据库SQL Server 或Azure SQ ...
随机推荐
- 吉比特&雷霆游戏--2020春招实习
笔试 题量较大,仅记了一些印象比较深刻的题. 题型为选择 + 填空(给C++代码填输出结果) + 编程 编程题不会太难,最难的就一道字符串的全排列(类似剑指offer第38题LeetCode链接)可以 ...
- .NET 5.0预览版6发布:支持Windows ARM64设备
2020年6月25日,微软dotnet团队在博客宣布了第六个 .NET 5.0 的预览版:https://devblogs.microsoft.com/dotnet/announcing-net-5- ...
- 浅谈pyautogui模块
pyautogui模块 PyAutoGUI--让所有GUI都自动化 安装代码: pip install pyautogui 目的 PyAutoGUI是一个纯Python的GUI自动化工具,其目的是可以 ...
- C#模拟HTTP协议请求
1 前言 http协议详解参考HTTP协议. WEB常用Get和Post请求. 地址栏参数:url为www.viwofer.com?id=12&name=viwofer则id=12 ...
- python unittest自动测试框架
编写函数或者类时进行测试,确保代码正常工作 python unittest 模块提供了代码测试工具.按照定义测试包括两部分:管理测试依赖库的代码(称为‘固件’)和测试本身. 单元测试用于核实函数的某 ...
- 每日一题 - 剑指 Offer 32 - I. 从上到下打印二叉树
题目信息 时间: 2019-06-25 题目链接:Leetcode tag:BFS(广度优先搜索) 队列 难易程度:中等 题目描述: 从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印 ...
- 揭秘JAVA JVM内幕
在之前的文章 一步步解析java执行内幕 中,比较详细分析了java代码是如何一步一步在jvm中执行的,然而设计的的jvm核心技术点,并未做深入分析,本篇文章将重点分析jvm,涉及到的内容包括jvm内 ...
- 棋子游戏 51Nod - 1534 思维题
题目描述 波雷卡普和瓦西里喜欢简单的逻辑游戏.今天他们玩了一个游戏,这个游戏在一个很大的棋盘上进行,他们每个人有一个棋子.他们轮流移动自己的棋子,波雷卡普先开始.每一步移动中,波雷卡普可以将他的棋子从 ...
- Java实现上传文件到指定服务器指定目录(ChannelSftp实现文件上传下载)
package com.tianyang.task.utils; import java.io.File;import java.io.FileInputStream;import java.io.I ...
- Java入门系列之final
前言 在C#经典面试中掺杂过Java的final关键字,主要用于类不能被继承,在C#则是利用关键字seal修饰类为密封类,而在Java中的final关键字的具体用法包含C#中const.readonl ...