Mysql之索引选择及优化
索引模型
- 哈希表
- 适用于只有等值查询的场景,Memory引擎默认索引
- InnoDB支持自适应哈希索引,不可干预,由引擎自行决定是否创建
- 有序数组:在等值查询和范围查询场景中的性能都非常优秀,但插入和删除数据需要进行数据移动,成本太高。因此,只适用于静态存储引擎
- 二叉平衡树:每个节点的左儿子小于父节点,父节点又小于右儿子,时间复杂度是 O(log(N))
- 多叉平衡树:索引不止存在内存中,还要写到磁盘上。为了让一个查询尽量少地读磁盘,就必须让查询过程访问尽量少的数据块。因此,要使用“N 叉”树。
B+Tree
B-Tree 与 B+Tree
- B-Tree
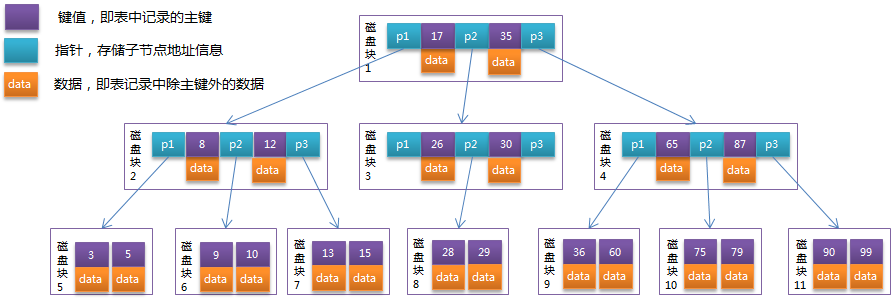
- B+Tree
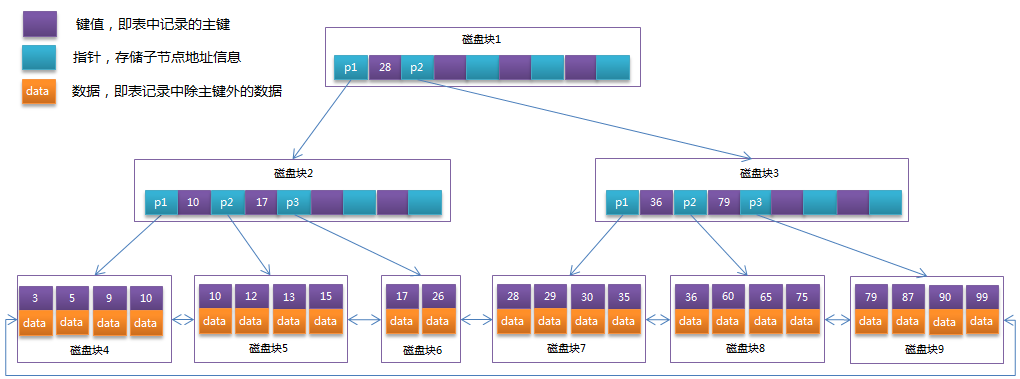
InnoDB 使用了 B+ 树索引模型。假设,我们有一个主键列为 ID 的表,表中有字段 k,并且在 k 上有索引,如下所示:

- 主键索引:也被称为聚簇索引,叶子节点存的是整行数据
- 非主键索引:也被称为二级索引,叶子节点内容是主键的值
注意事项
- 索引基于数据页有序存储,可能发生数据页的分裂(页存储空间不足)和合并(数据删除造成页利用率低)
- 数据的无序插入会造成数据的移动,甚至数据页的分裂
- 主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小
- 索引字段越小,单层可存储数据量越多,可减少磁盘IO
// 假设一个数据页16K、一行数据1K、索引间指针6字节、索引字段bigint类型(8字节)
// 索引个数
K = 16*1024/(8+6) =1170
// 单个叶子节点记录数
N = 16/1 = 16
// 三层B+记录数
V = K*K*N = 21902400
MyISAM也是使用B+Tree索引,区别在于不区分主键和非主键索引,均是非聚簇索引,叶子节点保存的是数据文件的指针
索引选择
优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。在数据库里面,扫描行数是影响执行代价的因素之一。扫描的行数越少,意味着访问磁盘数据的次数越少,消耗的 CPU 资源越少。
当然,扫描行数并不是唯一的判断标准,优化器还会结合是否使用临时表、是否排序等因素进行综合判断。
扫描行数如何计算
一个索引上不同的值越多,这个索引的区分度就越好。而一个索引上不同的值的个数,称之为“基数”(cardinality)。
-- 查看当前索引基数
mysql> show index from test;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| test | 0 | PRIMARY | 1 | id | A | 100256 | NULL | NULL | | BTREE | | |
| test | 1 | index_a | 1 | a | A | 98199 | NULL | NULL | YES | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
从性能的角度考虑,InnoDB 使用采样统计,默认会选择 N 个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。因此,上述两个索引显示的基数并不相同。
而数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过 1/M 的时候(innodb_stats_persistent=on时默认10,反之16),会自动触发重新做一次索引统计。
mysql> show variables like '%innodb_stats_persistent%';
+--------------------------------------+-------------+
| Variable_name | Value |
+--------------------------------------+-------------+
-- 是否自动触发更新统计信息,当被修改的数据超过10%时就会触发统计信息重新统计计算
| innodb_stats_auto_recalc | ON |
-- 控制在重新计算统计信息时是否会考虑删除标记的记录
| innodb_stats_include_delete_marked | OFF |
-- 对null值的统计方法,当变量设置为nulls_equal时,所有NULL值都被视为相同
| innodb_stats_method | nulls_equal |
-- 操作元数据时是否触发更新统计信息
| innodb_stats_on_metadata | OFF |
-- 统计信息是否持久化存储
| innodb_stats_persistent | ON |
-- innodb_stats_persistent=on,持久化统计信息采样的抽样页数
| innodb_stats_persistent_sample_pages | 20 |
-- 不推荐使用,已经被innodb_stats_transient_sample_pages替换
| innodb_stats_sample_pages | 8 |
-- 瞬时抽样page数
| innodb_stats_transient_sample_pages | 8 |
+--------------------------------------+-------------+
除了因为抽样导致统计基数不准外,MVCC也会导致基数统计不准确。例如:事务A先事务B开启且未提交,事务B删除部分数据,在可重复读中事务A还可以查询到删除的数据,此部分数据目前至少有两个版本,有一个标识为deleted的数据。
主键是直接按照表的行数来估计的,表的行数,优化器直接使用
show table status like 't'的值手动触发索引统计:
-- 重新统计索引信息
mysql> analyze table t;
排序对索引选择的影响
-- 创建表
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `b` (`b`)
) ENGINE=InnoDB;
-- 定义测试数据存储过程
mysql> delimiter ;
CREATE PROCEDURE idata ()
BEGIN
DECLARE i INT ;
SET i = 1 ;
WHILE (i <= 100000) DO
INSERT INTO t
VALUES
(i, i, i) ;
SET i = i + 1 ;
END
WHILE ;
END;
delimiter ;
-- 执行存储过程,插入测试数据
mysql> CALL idata ();
-- 查看执行计划,使用了字段a上的索引
mysql> explain select * from t where a between 10000 and 20000;
+----+-------------+-------+-------+---------------+-----+---------+------+-------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+-----+---------+------+-------+-----------------------+
| 1 | SIMPLE | t | range | a | a | 5 | NULL | 10000 | Using index condition |
+----+-------------+-------+-------+---------------+-----+---------+------+-------+-----------------------+
-- 由于需要进行字段b排序,虽然索引b需要扫描更多的行数,但本身是有序的,综合扫描行数和排序,优化器选择了索引b,认为代价更小
mysql> explain select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1;
+----+-------------+-------+-------+---------------+-----+---------+------+-------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+-----+---------+------+-------+------------------------------------+
| 1 | SIMPLE | t | range | a,b | b | 5 | NULL | 50128 | Using index condition; Using where |
+----+-------------+-------+-------+---------------+-----+---------+------+-------+------------------------------------+
-- 方案1:通过force index强制走索引a,纠正优化器错误的选择,不建议使用(不通用,且索引名称更变语句也需要变)
mysql> explain select * from t force index(a) where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1;
+----+-------------+-------+-------+---------------+-----+---------+------+------+----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+-----+---------+------+------+----------------------------------------------------+
| 1 | SIMPLE | t | range | a | a | 5 | NULL | 999 | Using index condition; Using where; Using filesort |
+----+-------------+-------+-------+---------------+-----+---------+------+------+----------------------------------------------------+
-- 方案2:引导 MySQL 使用我们期望的索引,按b,a排序,优化器需要考虑a排序的代价
mysql> explain select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b,a limit 1;
+----+-------------+-------+-------+---------------+-----+---------+------+------+----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+-----+---------+------+------+----------------------------------------------------+
| 1 | SIMPLE | t | range | a,b | a | 5 | NULL | 999 | Using index condition; Using where; Using filesort |
+----+-------------+-------+-------+---------------+-----+---------+------+------+----------------------------------------------------+
-- 方案3:有些场景下,我们可以新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引
ALTER TABLE `t`
DROP INDEX `a`,
DROP INDEX `b`,
ADD INDEX `ab` (`a`,`b`) ;
索引优化
索引选择性
索引选择性 = 基数 / 总行数
-- 表t中字段xxx的索引选择性
select count(distinct xxx)/count(id) from t;
索引的选择性,指的是不重复的索引值(基数)和表记录数的比值。选择性是索引筛选能力的一个指标,索引的取值范围是 0~1 ,当选择性越大,索引价值也就越大。
在使用普通索引查询时,会先加载普通索引,通过普通索引查询到实际行的主键,再使用主键通过聚集索引查询相应的行,以此循环查询所有的行。若直接全量搜索聚集索引,则不需要在普通索引和聚集索引中来回切换,相比两种操作的总开销可能扫描全表效率更高。
实际工作中,还是要看业务情况,如果数据分布不均衡,实际查询条件总是查询数据较少的部分,在索引选择较低的列上加索引,效果可能也很不错。
覆盖索引
覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段
-- 只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表
select ID from T where k between 3 and 5
-- 增加字段V,每次查询需要返回V,可考虑把k、v做成联合索引
select ID,V from T where k between 3 and 5
最左前缀原则+索引下推
-- id、name、age三列,name、age上创建联合索引
-- 满足最左前缀原则,name、age均走索引
select * from T where name='xxx' and age=12
-- Mysql自动优化,调整name、age顺序,,name、age均走索引
select * from T where age=12 and name='xxx'
-- name满足最左前缀原则走索引,MySQL5.6引入索引下推优化(index condition pushdown),即索引中先过滤掉不满足age=12的记录再回表
select * from T where name like 'xxx%' and age=12
-- 不满足最左前缀原则,均不走索引
select * from T where name like '%xxx%' and age=12
-- 满足最左前缀原则,name走索引
select * from T where name='xxx'
-- 不满足最左前缀原则,不走索引
select * from T where age=12
联合索引建立原则:
- 如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的
- 空间:优先小字段单独建立索引,例如:name、age,可建立(name,age)联合索引和(age)单字段索引
前缀索引
mysql> create table SUser(
ID bigint unsigned primary key,
name varchar(64),
email varchar(64),
...
)engine=innodb;
-- 以下查询场景
mysql> select name from SUser where email='xxx';
-- 方案1:全文本索引,回表次数由符合条件的数据量决定
mysql> alter table SUser add index index1(email);
-- 方案2:前缀索引,回表次数由前缀匹配结果决定
mysql> alter table SUser add index index2(email(6));
前缀索引可以节省空间,但需要注意前缀长度的定义,在节省空间的同时,不能增加太多查询成本,即减少回表验证次数
如何设置合适的前缀长度?
-- 预设一个可以接受的区分度损失比,选择满足条件中最小的前缀长度
select count(distinct left(email,n))/count(distinct email) from SUser;
如果合适的前缀长度较长?
比如身份证号,如果满足区分度要求,可能需要12位以上的前缀索引,节约的空间有限,又增加了查询成本,就没有必要使用前缀索引。此时,我们可以考虑使用以下方式:
- 倒序存储
-- 查询时字符串反转查询
mysql> select field_list from t where id_card = reverse('input_id_card_string');
使用hash字段
-- 创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引
mysql> alter table t add id_card_crc int unsigned, add index(id_card_crc); -- 查询时使用hash字段走索引查询,再使用原字段精度过滤
mysql> select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
以上两种方式的缺点:
- 不支持范围查询
- 使用hash字段需要额外占用空间,新增了一个字段
- 读写时需要额外的处理,reverse或者crc32等
前缀索引对覆盖索引的影响?
-- 使用前缀索引就用不上覆盖索引对查询性能的优化
select id,email from SUser where email='xxx';
唯一索引
建议使用普通索引,唯一索引无法使用change buffer,内存命中率低
索引失效
- 不做列运算,包括函数的使用,可能破坏索引值的有序性
- 避免
%xxx式查询使索引失效 - or语句前后没有同时使用索引,当or左右查询字段只有一个是索引,该索引失效
- 组合索引ABC问题,最左前缀原则
- 隐式类型转化
- 隐式字符编码转换
- 优化器放弃索引,回表、排序成本等因素影响,改走其它索引或者全部扫描
Mysql之索引选择及优化的更多相关文章
- 为什么MySQL数据库索引选择使用B+树?
在进一步分析为什么MySQL数据库索引选择使用B+树之前,我相信很多小伙伴对数据结构中的树还是有些许模糊的,因此我们由浅入深一步步探讨树的演进过程,在一步步引出B树以及为什么MySQL数据库索引选择使 ...
- MySQL的索引单表优化案例分析
建表 建立本次优化案例中所需的数据库及数据表 CREATE DATABASE db0206; USE db0206; CREATE TABLE `db0206`.`article`( `id` INT ...
- B树和B+树对比,为什么MySQL数据库索引选择使用B+树?
一 基础知识 二叉树 根节点,第一层的节点 叶子节点,没有子节点的节点. 非叶子节点,有子节点的节点,根节点也是非叶子节点. B树 B树的节点为关键字和相应的数据(索引等) B+树 B+树是B树的一个 ...
- 巧用MySQL之Explain进行数据库优化
前记:很多东西看似简单,那是因为你并未真正了解它. Explain命令用于查看执行效果.虽然这个命令只能搭配select类型语句使用,如果你想查看update,delete类型语句中的索引效果,也不是 ...
- mysql use index () 优化查询的例子
USE INDEX在你查询语句中表名的后面,添加 USE INDEX 来提供你希望 MySQ 去参考的索引列表,就可以让 MySQL 不再考虑其他可用的索引.Eg:SELECT * FROM myta ...
- 【夯实Mysql基础】MySQL性能优化的21个最佳实践 和 mysql使用索引
本文地址 分享提纲: 1.为查询缓存优化你的查询 2. EXPLAIN 你的 SELECT 查询 3. 当只要一行数据时使用 LIMIT 1 4. 为搜索字段建索引 5. 在Join表的时候使用相当类 ...
- mysql使用索引优化查询效率
索引的概念 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针.更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度.在没 ...
- 【mysql】索引的优化
写在前面的话 查询容易,优化不易,且写且珍惜 mysql结构 从MySQL逻辑架构来看,MySQL有三层架构,第一层连接,第二层查询解析.分析.优化.视图.缓存,第三层,存储引擎 MySQL有哪些索引 ...
- MySQL索引分析与优化
1.MySQL能够在name的索引中查找“Mike”值,然后直接转到数据文件中相应的行,准确地返回该行的 peopleid(999).在这个过程中,MySQL只需处理一个行就可以返回结果.如果没有“n ...
随机推荐
- js uppercase first letter
js uppercase first letter const str = `abc`; str.slice(0, 1).toUpperCase(); // "A" str.sli ...
- css variables & CSS 变量
css variables & CSS 变量 https://gist.github.com/xgqfrms-GitHub/5d022a13292c615d2730e84d909e1aba c ...
- Node.js require 模块加载原理 All In One
Node.js require 模块加载原理 All In One require 加载模块,搜索路径 "use strict"; /** * * @author xgqfrms ...
- zrender & svg
zrender & svg window.prompt double click https://codepen.io/xgqfrms/pen/jOEGNvw // https://cdn.x ...
- NGK推出SPC算力币,开启算力新玩法!
这两天,NGK公链再度上了热搜.因为既成功的打造DeFi生态以后,NGK又将目光对准了算力市场.试图通过算力代币化,让NGK算力持有者可以获得算力代币,同时,如果不想要了,算力持有者也可以抛售代币. ...
- Baccarat项目专用代币BGV的价值如何?
NGK投资者对于NGK平台自身的DeFi项目呼声越来越高,经过数月的紧张研发,检验和内测工作,NGK官方将于近日推出其去中心化金融项目--Baccarat,此项目为避免以太坊易被攻击,网络拥堵出块慢以 ...
- TCP编程详解
目录 数据包格式 建立连接(三次握手) 数据传输 断开连接(四次挥手) 基础 客户端流程 编码 TCP服务端流程 TCP服务端编码 参考文献 TCP把连接作为最基本的对象,每一条TCP连接都有两个端点 ...
- 为什么 Python 的 f-string 可以连接字符串与数字?
本文出自"Python为什么"系列,归档在 Github 上:https://github.com/chinesehuazhou/python-whydo 毫无疑问,Python ...
- 27_MySQL数字函数(重点)
/* SALES部门中工龄超过20年的,底薪增加10% SALES部门中工龄不满20年的,底薪增加5% ACCOUNTING部门,底薪增加300元 RESEARCH部门里低于部门平均底薪的,底薪增加2 ...
- 一些小Tip
导语 个人感悟,持续更新中... 正文 无论NIO还是AIO,都没有在数据传输过程(tcp/udp)作革命性的创新.他们在传输过程的效率和传统BIO是一样的,还是会产生阻塞(网络延迟,Socket缓冲 ...