mongodb简单运用
mongodb
NoSQL(Not Only SQL),意思是"不仅仅是 SQL",指的是非关系型数据库,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL 用于超大规模数据的存储。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
背景
随着互联网的飞速发展与普及,网民上网冲浪时所产生数据也逐日增多,从 GB 到 TB 到 PB。这些数据有很大一部分都是由关系型数据库管理系统(RDBMS)来进行处理的。
由于关系型数据库的范式约束、事务特性、磁盘 IO 等特点,若服务器使用关系型数据库,当有大量数据产生时,传统的关系型数据库已经无法满足快速查询与插入数据的需求。NoSQL 的出现解决了这一危机。它通过降低数据的安全性,减少对事务的支持,减少对复杂查询的支持,获取性能上的提升。但是,在某些特定场景下 NoSQL 仍然不是最佳人选,比如一些绝对要有事务与安全指标的场景。
NoSQL 是一项全新的数据库革命性运动,早期就有人提出,发展至 2009 年趋势越发高涨。NoSQL 的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
类型
键值(Key-Value)存储
特点:键值数据库就像传统语言中使用的哈希表。通过 Key 添加、查询或者删除数据。
优点:查询速度快。
缺点:数据无结构化,通常只被当作字符串或者二进制数据存储。
应用场景:内容缓存、用户信息比如会话、配置信息、购物车等,主要用于处理大量数据的高访问负载。
NoSQL 代表:Redis、Memcached…
文档(Document-Oriented)存储
特点:文档数据库将数据以文档的形式储存,类似 JSON,是一系列数据项的集合。每个数据项都有一个名称与对应的值,值既可以是简单的数据类型,如字符串、数字和日期等;也可以是复杂的类型,如有序列表和关联对象。
优点:数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构。
缺点:查询性能不高,缺乏统一的查询语法。
应用场景:日志、 Web 应用等。
NoSQL 代表:MongoDB、CouchDB…
列(Wide Column Store/Column-Family)存储
特点:列存储数据库将数据储存在列族(Column Family)中,将多个列聚合成一个列族,键仍然存在,但是它们的特点是指向了多个列。举个例子,如果我们有一个 Person 类,我们通常会一起查询他们的姓名和年龄而不是薪资。这种情况下,姓名和年龄就会被放入一个列族中,而薪资则在另一个列族中。
优点:列存储查找速度快,可扩展性强,更容易进行分布式扩展,适用于分布式的文件系统,应对分布式存储的海量数据。
缺点:查询性能不高,缺乏统一的查询语法。
应用场景:日志、 分布式的文件系统(对象存储)、推荐画像、时空数据、消息/订单等。
NoSQL 代表:Cassandra、HBase…
图形(Graph-Oriented)存储
特点:图形数据库允许我们将数据以图的方式储存。
优点:图形相关算法。比如最短路径寻址,N 度关系查找等。
缺点:很多时候需要对整个图做计算才能得出需要的信息,分布式的集群方案不好做,处理超级节点乏力,没有分片存储机制,国内社区不活跃。
应用场景:社交网络,推荐系统等。专注于构建关系图谱。
NoSQL 代表:Neo4j、Infinite Graph…
NoSQL 的优缺点
优点
- 高可扩展性
- 没有标准化
- 分布式计算
- 有限的查询功能(到目前为止)
- 低成本
缺点
- 最终一致是不直观的程序
- 架构的灵活性,半结构化数据
- 没有复杂的关系
总结
NoSQL 数据库在以下几种情况下比较适用:
- 数据模型比较简单
- 需要灵活性更强的 IT 系统
- 对数据库性能要求较高
- 不需要高度的数据一致性
- 对于给定的 Key,比较容易映射复杂值的环境
mongoDB
MongoDB 与关系型数据库术语对比
| SQL 术语概念 | MongoDB 术语概念 |
|---|---|
| database(数据库) | database(数据库) |
| table(表) | collection(集合) |
| row(行) | document or BSON document(文档) |
| column(列) | field(字段) |
| index(索引) | index(索引) |
| table joins(表连接) | embedded documents and linking(嵌入的文档和链接) |
| primary key Specify any unique column or column combination as primary key.(指定任意唯一的列或列组合作为主键) | primary keyIn MongoDB, the primary key isautomatically set to the_idfield.(在 MongoDB 中,主键被自动设置为_id字段) |
| aggregation (e.g. group by) | MongoDB provides three ways to perform aggregation: the aggregation pipeline, the map-reduce function, and single purpose aggregation methods.(聚合操作) |
MongoDB 数据类型
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Arrays | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
安装
官网:https://www.mongodb.com/
下载地址:https://www.mongodb.com/try/download/community
将资源上传至服务器/usr/local/src,解压至/usr/local并重命名为mongodb。
# 创建 mongodb 目录
mkdir -p /usr/local/mongodb
# 解压 mongodb 至指定目录
tar -zxvf /usr/local/src/mongodb-linux-x86_64-rhel70-4.4.1.tgz -C /usr/local/
# 重命名解压目录为 mongodb
mv /usr/local/mongodb-linux-x86_64-rhel70-4.4.1/ /usr/local/mongodb/
# 创建存放数据的目录
mkdir -p /usr/local/mongodb/data/db
# 创建存放日志的目录
mkdir -p /usr/local/mongodb/logs
# 创建日志记录文件
touch /usr/local/mongodb/logs/mongodb.log
运行
配置文件解压目录下的bin创建mongodb.conf
# 数据文件存放目录
dbpath = /usr/local/mongodb/data/db
# 日志文件存放目录
logpath = /usr/local/mongodb/logs/mongodb.log
# 以追加的方式记录日志
logappend = true
# 端口默认为 27017
port = 27017
# 对访问 IP 地址不做限制,默认为本机地址
bind_ip = 0.0.0.0
# 以守护进程的方式启用,即在后台运行
fork = true
通过配置文件运行
# 切换至指定目录
cd /usr/local/mongodb/
# 指定配置文件的方式启动服务
bin/mongod -f bin/mongodb.conf
连接
bin/mongo
关闭
bin/mongod -f bin/mongodb.conf --shutdown
#或者万能关闭法
# 查看 mongodb 运行的进程信息
ps -ef | grep mongodb
# kill -9 强制关闭
kill -9 pid
作为一个很懒的人,我建议docker安装
从菜鸟教程扒过来的
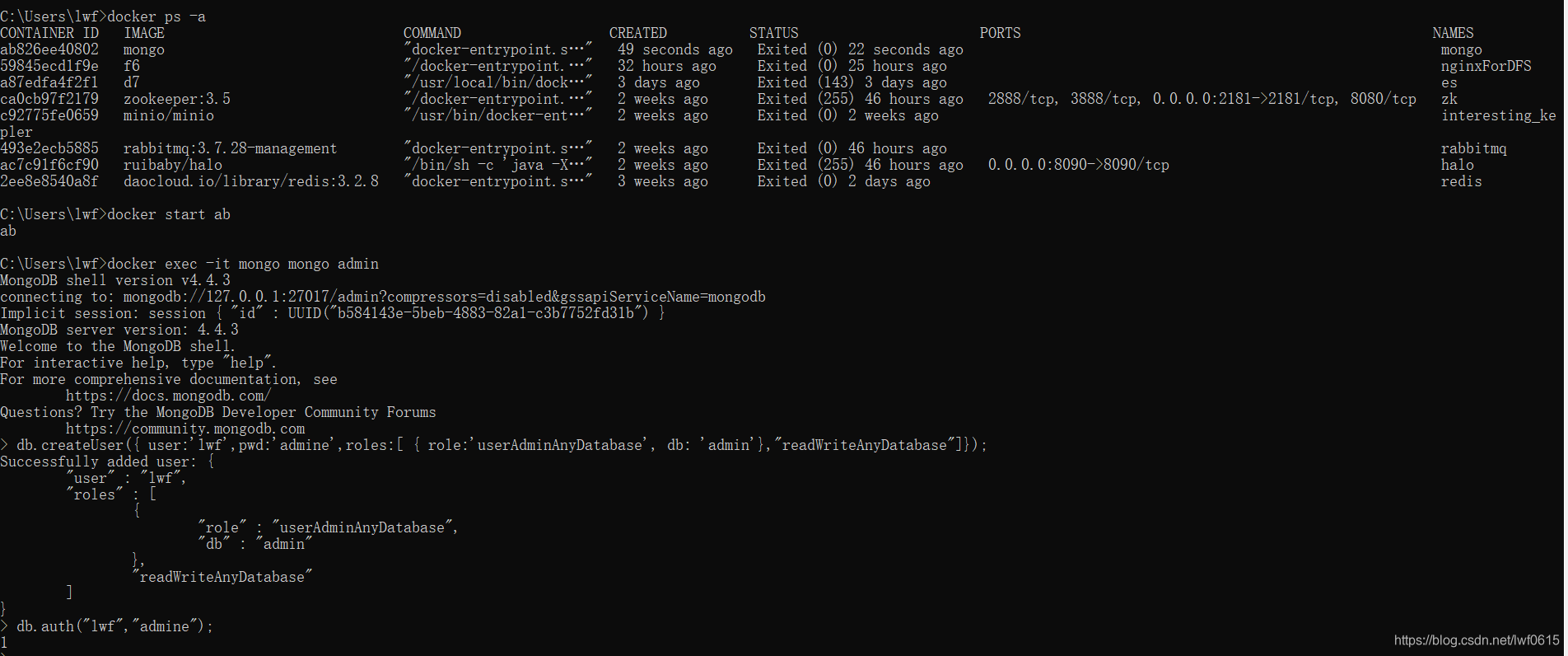
docker pull mongo:latest
#查看mongo镜像id
docker images
#运行
docker run -itd --name mongo -p 27017:27017 mongo --auth
#添加用户和密码
$ docker exec -it mongo mongo admin
# 创建一个名为 admin,密码为 123456 的用户。
> db.createUser({ user:'admin',pwd:'123456',roles:[ { role:'userAdminAnyDatabase', db: 'admin'},"readWriteAnyDatabase"]});
# 尝试使用上面创建的用户信息进行连接。
> db.auth('admin', '123456')
用户管理
| 权限 | 说明 |
|---|---|
| read | 允许用户读取指定数据库。 |
| readWrite | 允许用户读写指定数据库。 |
| userAdmin | 允许用户向 system.users 集合写入,可以在指定数据库里创建、删除和管理用户。 |
| dbAdmin | 允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问 system.profile。 |
| clusterAdmin | 必须在 admin 数据库中定义,赋予用户所有分片和复制集相关函数的管理权限。 |
| readAnyDatabase | 必须在 admin 数据库中定义,赋予用户所有数据库的读权限。 |
| readWriteAnyDatabase | 必须在 admin 数据库中定义,赋予用户所有数据库的读写权限。 |
| userAdminAnyDatabase | 必须在 admin 数据库中定义,赋予用户所有数据库的 userAdmin 权限。 |
| dbAdminAnyDatabase | 必须在 admin 数据库中定义,赋予用户所有数据库的 dbAdmin 权限。 |
| root | 必须在 admin 数据库中定义,超级账号,超级权限。 |
管理用户
MongoDB 有一个用户管理机制,简单描述为管理用户组,这个组的用户是专门为管理普通用户而设的,暂且称之为管理员。
管理员通常没有数据库的读写权限,只有操作用户的权限,我们只需要赋予管理员
userAdminAnyDatabase角色即可。另外管理员账户必须在 admin 数据库下创建。
#切换数据库
use admin
#查看用户
db.system.users.find()
添加管理用户
db.createUser({
user: "<name>",
pwd: "<cleartext password>",
customData: { <any information> },
roles: [
{ role: "<role>", db: "<database>" } | "<role>",
...
]
});
user:用户名pwd:密码customData:存放用户相关的自定义数据,该属性也可忽略roles:数组类型,配置用户的权限重启以密码认证
管理员账户创建完成以后,需要重新启动 MongoDB,并开启身份验证功能。
先通过
db.shutdownServer()函数关闭服务。配置文件:mongo.conf
# 数据文件存放目录
dbpath = /usr/local/mongodb/data/db
# 日志文件存放目录
logpath = /usr/local/mongodb/logs/mongodb.log
# 以追加的方式记录日志
logappend = true
# 端口默认为 27017
port = 27017
# 以守护进程的方式启用,即在后台运行
fork = true
# 对访问 IP 地址不做限制
bind_ip = 0.0.0.0
# 启动身份验证
auth = true
身份认证
show users所有用户
db.auth("name","password")认证创建普通用户
#登录管理员
use admin
db.auth("lwf","admine") #创建数据库
use test
#创建用户对test数据库的读和写
db.createUser({user:"ppl",pwd:"123456",roles:[{role:"readWrite",db:"test"}]}) #使用ppl认证,1成功,0失败
use test
db.auth("ppl","123456")
#进行集合的添加,类似于js对象,直接 db.集合名.insert(json字符串)
db.dog.insert({"name":"ppl"})
更新用户
角色
db.updateUser("用户名", {"roles":[{"role":"角色名称",db:"数据库"},{"更新项2":"更新内容"}]})
更新密码
更新用户密码有以下两种方式,更新密码时需要切换到该用户所在的数据库。注意:需要使用具有
userAdmin或userAdminAnyDatabse或root角色的用户执行:
- 使用
db.updateUser("用户名", {"pwd":"新密码"})函数更新密码- 使用
db.changeUserPassword("用户名", "新密码")函数更新密码删除用户
通过
db.dropUser()函数可以删除指定用户,删除成功以后会返回 true。删除用户时需要切换到该用户所在的数据库。注意:需要使用具有userAdmin或userAdminAnyDatabse或root角色的用户才可以删除其他用户。
操作
数据库操作(数据库级DDL)
切换数据库加创建数据库
use test列出数据库
show dbsshow databases删除数据库(当前所在数据库)
db.dropDatabase()
集合操作(表级DML)
创建自定义集合
db.createCollection(name, options)
name:要创建的集合名称。options:可选参数,指定有关内存大小及索引的选项。
字段 类型 描述 capped 布尔 (可选)如果为 true,则创建固定集合。固定集合是指有固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。当该值为 true 时,必须指定 size 参数。 size 数值 (可选)限制集合空间的大小,默认为没有限制(以字节计)。如果 capped 为 true,必须指定该字段。 autoIndexId 布尔 (可选)如果为 true,自动在 _id字段创建索引。默认为 true。max 数值 (可选)限制集合中包含文档的最大数量,默认为没有限制。 和js属性一样,当你用到它是,就会自动创建,创建使用的默认属性
# 方式一:
db.c2.insert({"a":1}) # 当第一个文档插入时,集合就会被创建并包含该文档
# 方式二:
db.c3 # 创建一个空集合,里面没有数据时通过 show tables 或 show collections 是无法查看到的。需要向集合中插入一个文档才能看见。
查看集合
通过
show tables或show collections查看所有集合。查看使用情况
db.dog.stats()
删除
db.dog.drop()

文档操作(记录,相当数据库表的一行数据)
插入
可以使用
insert/insertOne/save插入单条文档:
db.c1.insert({"name":"a"})db.c1.insertOne({"name":"a"})db.c1.save({"name":"a"})可以使用
insert/insertMany/save插入多条文档。区别在于把单条插入时函数参数的对象类型{}变成数组类型[{}, {}]:
db.c1.insert([{name:"a"}, {name:"b"}])db.c1.insertMany([{name:"a"}, {name:"b"}])db.c1.save([{name:"a"}, {name:"b"}])如果不指定
_id字段save()方法等同于insert()方法。如果指定_id字段,则变为更新文档的操作。#insert 1
db.place.insert({"name":"jiangxi1"})
db.place.save({"name":"shanghai"})
#insert many
db.place.insert([{"name":"guangdong"},{"name":"jiangxi"}])
db.place.insertMany([{"name":"beijing"},{"name":"zhejiang"}])
db.place.save([{"name":"xingjiang"},{"name":"hebei"}])
删除
通过
remove()函数是用来移除集合中的数据,其语法格式如下所示:db.COLLECTION_NAME.remove(<query>, {justOne: <boolean>})
query:(可选)删除的文档的条件。
justOne:(可选)如果设为 true,则只删除一个文档,False删除所有匹配的数据等价于
#删除符合条件的第一个文档
db.user.deleteOne(<query>)
#删除所有数据命令
db.user.remove({})
#清空该集合(表) 等价于上一条
db.user.deleteMany({})
更新
通过
update系列函数或者save函数可以更新集合中的文档。我们来详细看下update函数的使用,上一节已经介绍过save函数。
update()函数用于更新已存在的文档。语法格式如下:db.COLLECTION_NAME.update(query, update, options)
query:update 的查询条件,类似 SQL update 语句中的 where 部分。update:update 的对象和一些更新的操作符(如 s e t , set,set,inc…)等,也可以理解为 SQL update 语句中的 set 部分。upsert:可选,如果不存在 update 的文档,是否插入该文档。true 为插入,默认是 false,不插入。multi:可选,是否批量更新。true 表示按条件查询出来的多条记录全部更新,false 只更新找到的第一条记录,默认是 false。#update
place={
"name":"西藏"
}
db.place.update({"name":"jiangxi1"},place)
# 修改单条
db.place.updateOne({"name":"西藏"}, {"$set": {"name":"东北"}})
# 查找到的匹配数据如果是多条,只会修改第一条
db.place.update({"name":"lisi"}, place) # 修改单条等价于 updateOne()
# 查找到的匹配数据如果是多条,修改所有匹配到的记录
db.place.update({"name":"lisi"}, {"$set": place}, false, true) # 修改多条
db.place.updateMany({"name":"123123"}, {"$set":place}) # 修改多条
查询
# 等同于db.place.find({})
db.place.find()
# 去重
db.place.distinct('name')
# pretty() 方法以格式化的方式来显示所有文档
db.place.find().pretty()
运算
比较
#1、select * from user where id = 3
db.user.find({"_id":3}) #2、select * from user where id != 3
db.user.find({"_id":{"$ne":3}}) #3、select * from user where id > 3
db.user.find({"_id":{"$gt":3}}) #4、select * from user where age < 3
db.user.find({"age":{"$lt":3}}) #5、select * from user where id >= 3
db.user.find({"_id":{"$gte":3}}) #6、select * from user where id <= 3
db.user.find({"_id":{"$lte":3}})
逻辑
MongoDB中字典内用逗号分隔多个条件是and关系,或者直接用
$and,$or,$not(与或非)#逻辑运算:$and,$or,$not
#1 select * from user where id >=3 and id <=4;
db.user.find({"_id":{"$gte":3,"$lte":4}}) #2 select * from user where id >=3 and id <=4 and age >=4;
db.user.find({
"_id":{"$gte":3,"$lte":4},
"age":{"$gte":4}
}) db.user.find({
"$and": [
{"_id": {"$gte":3, "$lte":4}},
{"age": {"$gte":4}}
]
}) #3 select * from user where id >=0 and id <=1 or id >=4 or name = "tianqi";
db.user.find({
$or: [
{"_id": {$gte:0, $lte:1}},
{"_id": {$lte:4}},
{"name": "tianqi"}
]
}) db.user.find({
"$or": [
{"$and": [
{"_id": {"$gte": 0}},
{"_id": {"$lte": 1}}
]},
{"_id": {"$gte": 4}},
{"name": "tianqi"}
]
}); #4 select * from user where id % 2 = 1;
db.user.find({"_id":{"$mod":[2,1]}}) #上一条取反
db.user.find({
"_id":{"$not":{"$mod":[2,1]}}
})
成员
成员运算无非in和not in,MongoDB中形式为
$in,$nin#1、select * from user where age in (1,2,3);
db.user.find({"age":{"$in":[1,2,3]}}) #2、select * from user where name not in ("zhangsan","lisi");
db.user.find({"name":{"$nin":["zhangsan","lisi"]}})
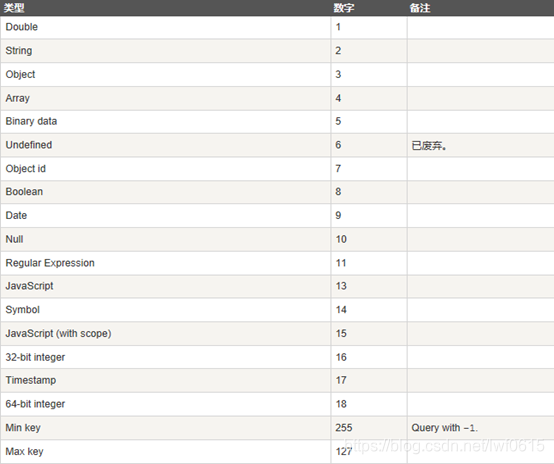
$type
MongoDB中可以使用的类型如下表所示:
# 查询name是字符串类型的数据
db.user.find({name:{$type:2}})
正则
正则定义在
/ /内#1、select * from user where name regexp '^z.*?(n|u)$';
#匹配规则:z开头、n或u结尾,不区分大小写
db.user.find({'name':/^z.*?(n|u)$/i})
投影
MongoDB投影意思是只选择必要的数据而不是选择一整个文件的数据。
在MongoDB中,当执行
find()方法,那么它会显示一个文档所有字段。要限制这一点,需要设置的字段列表值1或0。1用来显示字段而0是用来隐藏字段,
_id会默认显示出来。#1、select name,age from user where id=3;
db.user.find({'_id':3},{'_id':0,'name':1,'age':1}) #2、select name,age from user where name regexp "^z.*(n|u)$";
db.user.find({
"name":/^z.*(n|u)$/i
},
{
"_id":0,
"name":1,
"age":1
}
)
数组
#查询数组相关
#查hobbies中有dancing的人
db.user.find({
"hobbies":"dancing"
}) #查看既有dancing爱好又有tea爱好的人
db.user.find({
"hobbies":{"$all":["dancing","tea"]}
}) #查看索引第2个爱好为dancing的人(索引从0开始计算)
db.user.find({
"hobbies.2":"dancing"
}) #查看所有人的第1个到第2个爱好,第一个{}表示查询条件为所有,第二个是显示条件(左闭右开)
db.user.find(
{},
{
"_id":0,
"name":0,
"age":0,
"addr":0,
"hobbies":{"$slice":[0,2]},
}
) #查看所有人最后两个爱好,第一个{}表示查询条件为所有,第二个是显示条件
db.user.find(
{},
{
"_id":0,
"name":0,
"age":0,
"addr":0,
"hobbies":{"$slice":-2},
}
) #查询子文档有"country":"China"的人
db.user.find(
{
"addr.country":"China"
}
)
排序
在MongoDB中使用使用
sort()方法对数据进行排序,sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列# 按姓名正序
db.user.find().sort({"name":1})
# 按年龄倒序 按id正序
db.user.find().sort({"age":-1,'_id':1})
分页
limit表示取多少个document,skip代表跳过几个document
分页公式如下:
db.user.find().skip((pageNum–1)*pageSize).limit(pageSize)
db.user.find().limit(2).skip(0) # 前两个
db.user.find().limit(2).skip(2) # 第三个和第四个
db.user.find().limit(2).skip(4) # 第五个和第六个
统计
# 查询_id大于3的人数
# 方式一
db.user.count({'_id':{"$gt":3}})
# 方式二
db.user.find({_id:{"$gt":3}}).count()
聚合
我们在查询时肯定会用到聚合,在MongoDB中聚合为aggregate,聚合函数主要用到
$match,$group,$avg.$project,$concat,可以加$match也可以不加$match
Aggregate语法
基本格式:
db.collection.aggregate(pipeline, options)
pipeline:一系列数据聚合操作或阶段。在版本2.6中更改:该方法仍然可以将流水线阶段作为单独的参数接受,而不是作为数组中的元素;但是,如果不将管道指定为数组,则不能指定options参数。目前所使用的4.0.4版本必须使用数组。options:可选。 aggregate()传递给聚合命令的其他选项。 2.6版中的新增功能:仅当将管道指定为数组时才可用。注意:使用db.collection.aggregate()直接查询会提示错误,但是传一个空数组如db.collection.aggregate([])则不会报错,且会和find一样返回所有文档。
m a t c h 和 match和match和group
相当于sql语句中的where和group by
{"$match":{"字段":"条件"}},可以使用任何常用查询操作符$gt,$lt,$in等 # select * from db1.emp where post='公务员';
db.emp.aggregate([{"$match":{"post":"公务员"}}]) # select * from db1.emp where id > 3 group by post;
db.emp.aggregate([
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}}
]) # select * from db1.emp where id > 3 group by post having avg(salary) > 10000;
db.emp.aggregate([
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}},
{"$match":{"avg_salary":{"$gt":10000}}}
]) {"$group":{"_id":分组字段,"新的字段名":聚合操作符}} #1、将分组字段传给$group函数的_id字段即可
{"$group":{"_id":"$sex"}} #按照性别分组
{"$group":{"_id":"$post"}} #按照职位分组
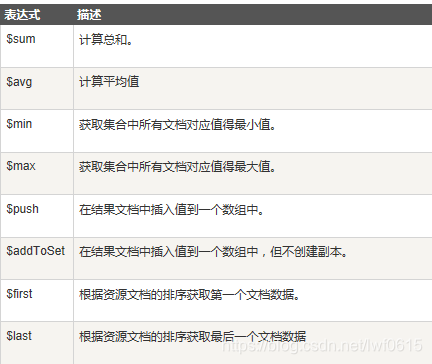
{"$group":{"_id":{"state":"$state","city":"$city"}}} #按照多个字段分组,比如按照州市分组 #2、分组后聚合得结果,类似于sql中聚合函数的聚合操作符:$sum、$avg、$max、$min、$first、$last
#例1:select post,max(salary) from db1.emp group by post;
db.emp.aggregate([{"$group":{"_id":"$post","max_salary":{"$max":"$salary"}}}]) #例2:取每个部门最大薪资与最低薪资
db.emp.aggregate([{"$group":{"_id":"$post","max_salary":{"$max":"$salary"},"min_salary":{"$min":"$salary"}}}]) #例3:如果字段是排序后的,那么$first,$last会很有用,比用$max和$min效率高
db.emp.aggregate([{"$group":{"_id":"$post","first_id":{"$first":"$_id"}}}]) #例4:求每个部门的总工资
db.emp.aggregate([{"$group":{"_id":"$post","count":{"$sum":"$salary"}}}, {"$sort": {"count": 1}}]) #例5:求每个部门的人数
db.emp.aggregate([{"$group":{"_id":"$post","count":{"$sum":1}}}, {"$sort": {"count": 1}}]) #3、数组操作符
{"$addToSet":expr}#不重复
{"$push":expr}#重复 #例:查询岗位名以及各岗位内的员工姓名:select post,group_concat(name) from db1.emp group by post;
# 重复的也查询出来
db.emp.aggregate([{"$group":{"_id":"$post","names":{"$push":"$name"}}}])
# 查询不重复的,如果有重复的保留一个
db.emp.aggregate([{"$group":{"_id":"$post","names":{"$addToSet":"$name"}}}])
$project
用于投射,即设定该键值对是否保留。1为保留,0为不保留,可对原有键值对做操作后增加自定义表达式(查询哪些要显示的列)
{"$project":{"要保留的字段名":1,"要去掉的字段名":0,"新增的字段名":"表达式"}} # select name,post,(age+1) as new_age from db1.emp;
db.emp.aggregate([
{
$project:{
"name":1,
"post":1,
"new_age":{"$add":["$age",1]}
}
}
])
s o r t 和 sort和sort和limit和$skip
排序:{"$sort":{"字段名":1,"字段名":-1}} #1升序,-1降序
限制:{"$limit":n}
跳过:{"$skip":n} #跳过多少个文档 #例1、取平均工资最高的前两个部门
db.emp.aggregate([
{
"$group":{"_id":"$post","平均工资":{"$avg":"$salary"}}
},
{
"$sort":{"平均工资":-1}
},
{
"$limit":2
}
])
#例2、取平均工资最高的第二个部门
db.emp.aggregate([
{
"$group":{"_id":"$post","平均工资":{"$avg":"$salary"}}
},
{
"$sort":{"平均工资":-1}
},
{
"$limit":2
},
{
"$skip":1
}
])
$sample
随机选取n个:
$sample# 随机获取3个文档
db.emp.aggregate([
{$sample: {size:3}}
])
c o n c a t 和 concat和concat和substr和t o L o w e r 和 toLower和toLower和toUpper
{"$substr":[$值为字符串的字段名,起始位置,截取几个字节]}
{"$concat":[expr1,expr2,...,exprN]} #指定的表达式或字符串连接在一起返回,只支持字符串拼接
{"$toLower":expr} # 转小写
{"$toUpper":expr} # 转大写 # 截取字符串
db.emp.aggregate([
{
$project:{
"_id":0,
"str": {$substr: ["$sex", 0, 2]}
}
}
]) # 拼接
db.emp.aggregate([
{
$project:{
"name":1,
"post":1,
"name_sex": {$concat: ["$name", "测试拼接", "$sex"]}
}
}
]) # 将性别的英文转为大写
db.emp.aggregate([{"$project":{"sex":{"$toUpper":"$sex"}}}])
索引
创建索引
索引通常能够极大的提高查询的效率,MongoDB使用 ensureIndex()方法来创建索引,其基本语法格式如下所示:
db.COLLECTION_NAME.ensureIndex({KEY:1})
key:创建的索引字段,1为指定按升序创建索引,-1则为按降序来创建索引。db.user.ensureIndex({"name":-1})
# 指定所建立索引的名字
db.user.ensureIndex({"name":1},{"name":"nameIndex"})
ensureIndex()接收可选参数,可选参数列表如下:查询索引
查询索引的语法格式如下所示:
db.COLLECTION_NAME.getIndexes()
删除索引
删除索引的语法格式如下所示:
db.COLLECTION_NAME.dropIndex(INDEX_NAME)
普通java
依赖
<!-- mongodb java依赖 -->
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.12.7</version>
</dependency>
连接
无密码
/**
* 无需账号密码连接服务器
*/
@Test
public void init01() {
//连接mongodb服务器,自带连接池效果
MongoClient mongoClient = MongoClients.create("mongodb://192.168.10.102:27017");
//获取数据库,如果数据库不存在,为该数据库首次存储数据时,自动创建数据库。
MongoDatabase database = mongoClient.getDatabase("test");
//获取集合,如果集合不存在,首次存储数据时,自动创建集合
MongoCollection<Document> collection = database.getCollection("user");
//获取数据,获取集合中第一个文档,并转成json打印
System.out.println("collection.find().first().toJson() = " + collection.find().first().toJson());
System.out.println("connect to database successful");
//关闭客户端
if (mongoClient != null) {
mongoClient.close();
}
}有密码
/**
* 需要账号密码登录
*/
@Test
public void init02() {
/**
* 连接mongodb服务器
* mongodb://user1:pwd1@host1/?authSource=db1
* user1:用户名
* pwd1:密码
* host1:服务器
* authSource:认证数据库
*/
MongoClient mongoClient = MongoClients.create("mongodb://lwf:admine@192.168.10.100/?authSource=admin");
//获取数据库
MongoDatabase database = mongoClient.getDatabase("test");
//获取集合
MongoCollection<Document> collection = database.getCollection("place");
//获取数据
System.out.println("collection.find().first().toJson() = " + collection.find().first().toJson());
System.out.println("connect to database successful");
//关闭客户端
if (mongoClient != null) {
mongoClient.close();
}
}
集合操作
/**
* 操作集合
*/
@Test
public void testCollection() {
//获取集合,如果集合不存在,会在第一次为该集合创建数据时创建集合
MongoCollection<Document> emp = database.getCollection("emp");
//获取集合命名空间,格式数据库.集合
System.out.println(emp.getNamespace()); //创建固定大小的集合,大小1MB
database.createCollection("cappedCollection",
new CreateCollectionOptions().capped(true).sizeInBytes(0x100000)); /**
* 创建带校验规则的集合
* 在更新和插入期间验证文档的功能
* 验证规则是使用ValidationOptions在每个集合的基础上指定的,它接受指定验证规则或表达式的筛选器文档。
* 文档插入数据时必须存在emali字段或者phone字段
*/
ValidationOptions collOptions = new ValidationOptions().validator(
Filters.or(Filters.exists("email"), Filters.exists("phone")));
database.createCollection("contacts",
new CreateCollectionOptions().validationOptions(collOptions));
}
整合spring boot
配置文件application.yml
# 应用名称
spring:
application:
name: spring_boot_mongo
data:
# mongodb配置
mongodb:
# 服务器地址
host: 192.168.10.102
# 端口
port: 27017
# 用户名
username: lwf
# 密码
password: admine
# 认证数据库
authentication-database: admin
# 操作的数据库
database: test
# 应用服务 WEB 访问端口
server:
port: 8080
依赖
springDataMongo
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
代码
使用MongoTemplate
import com.lwf.mongo.pojo.Panda;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.result.InsertOneResult;
import org.bson.Document;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.mongodb.core.CollectionOptions;
import org.springframework.data.mongodb.core.ExecutableRemoveOperation;
import org.springframework.data.mongodb.core.ExecutableUpdateOperation;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Collation;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.web.bind.annotation.ResponseBody; import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List; @SpringBootTest
class SpringBootMongoApplicationTests {
@Resource
private MongoTemplate template;
//创建集合并插入
@Test
void contextLoads() {
//MongoCollection<Document> collection = template.createCollection(Panda.class, CollectionOptions.empty());
//InsertOneResult insertOne = collection.insertOne(new Document("name", "熊猫").append("location", "四川"));
Panda panda = new Panda("id124","熊猫","成都");
Panda insert = template.insert(panda);
System.out.println("insert = " + insert);
List<Panda> pandas=new ArrayList<>();
pandas.add(new Panda("1","小能苗","上海"));
pandas.add(new Panda("2","大能苗","上海"));
System.out.println(template.insert(pandas, "panda").size());
}
//更新
@Test
public void update(){
ExecutableUpdateOperation.FindAndReplaceWithProjection<Panda> replace = template.update(Panda.class).replaceWith(new Panda("id123", "食铁兽", "四川"));
System.out.println("replace.findAndReplaceValue() = " + replace.findAndReplaceValue());
}
//删除
@Test
public void delete(){
//相当于sql: delete from panda where name=#{name} and id=#{id}
ExecutableRemoveOperation.TerminatingRemove<Panda> remove = template.remove(Panda.class).matching(Query.query(Criteria.where("name").is("食铁兽").and("id").is("id123")));
System.out.println("remove.one().getDeletedCount() = " + remove.one().getDeletedCount());
}
//查询
@Test
public void select(){
//name 匹配 熊
template.find(Query.query(Criteria.where("name").regex("熊")),Panda.class).forEach(System.out::println);
//查询所有
template.findAll(Panda.class).forEach(System.out::println); } }
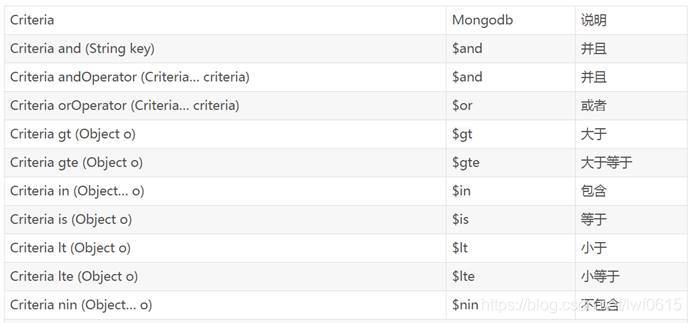
MongoTemplate的crud方式见名知意,条件操作Query:
Query.query(Criteria)
Criteria的方法如上图,方法都是静态且返回Criterta,可以链式操作;
操作 sql形式 Query构造 查询名字包含’熊’,id大于2的熊猫 select * from panda where name like “%熊%” and id>2 Query.query(Criteria.where(“name”).regex(“熊”).and(“id”).gt(2)) 查询名字包含“熊”,或者在上海 select * from panda where name like “%熊%” or place=“上海” Query.query(Criteria.where(“name”).regex(“熊”).orOperator(Criteria.where(“place”).is(“上海”)))
使用类似jpa方式
import com.lwf.mongo.pojo.Panda;
import org.springframework.data.mongodb.repository.MongoRepository; /**
* Created by lwf on 2021/1/22 16:12
*/
public interface PandaReposiry extends MongoRepository<Panda,String> {
}
//jpa
@Resource
private PandaReposiry pandaReposiry;
@Test
public void jpa(){
pandaReposiry.findAll().forEach(System.out::println);
}
mongodb简单运用的更多相关文章
- MongoDB学习:(二)MongoDB简单使用
MongoDB学习:(二)MongoDB简单使用 MongoDB使用: 执行mongodb的操作之前,我们需要运行命令,来进入操作命令界面 >mongo 提示该错误,说明我们系统缺少一个补丁,该 ...
- mongodb 简单部署方案及实例
mongodb 简单部署方案及实例 转载:http://my.oschina.net/zhuzhu0129/blog/53290 第一节 准备工作 一 安装mongodb 我这里选用rehl 5.6 ...
- .Net Core MongoDB 简单操作。
一:MongoDB 简单操作类.这里引用了MongoDB.Driver. using MongoDB.Bson; using MongoDB.Driver; using System; using S ...
- python和mongodb简单交互
python和mongodb简单交互 1.安装pymongo: pip3 install pymongo 2.pymongo的简单用法: # /usr/bin/env python3 import p ...
- MongoDB简单CRUD场景
MongoDB简单CRUD命令操作 (1)新建数据库:use 数据库名 (2)显示所有数据库:show dbs; (3)新建集合(两种方式) 隐式创建:在创建集合的同时往集合里面添加数据---db. ...
- NodeJS+Express+MongoDB 简单实现数据录入及回显展示【适合新人刚接触学习】
近期在看NodeJS相关 不得不说NodeJS+Express 进行网站开发是很不错,对于喜欢玩JS的来说真是很好的一种Web开发组合 在接触NodeJS时受平时Java或者C#中API接口等开发的思 ...
- 存储库-MongoDB简单的操作
简介: MongoDB是一款强大.灵活.且易于扩展的通用型数据库 1.易用性 MongoDB是一个面向文档的数据库,而不是关系型的数据库: 不采用关系型主要是为了可扩展性 2.易扩展性 存储在Mong ...
- nodejs+express+mongodb简单的例子
简单的介绍下node+express+mongodb这三个东西.node:是运行在服务器端的程序语言,表面上看过去就是javascript一样的东西,但是呢,确实就是服务器语言,个人觉得在一定层次上比 ...
- scrapy使用MongoDB简单示例
1.下载安装MongoDBhttps://www.mongodb.com/download-center#community找到合适的版本下载,安装.安装好之后,找到安装目录下D:\Program F ...
- MongoDB简单使用 —— 安装
下载 MongoDB的下载路径为:MongoDB Download Center.Win.Linux.Mac平台的都有,光Win平台的就提供msi和zip绿色版本的,这里我下载的是zip版本的. 命令 ...
随机推荐
- win10删除文件没有提示框
步骤 右键 回收站, 显示删除确认对话框
- 十个最常用的JVM 配置参数
1.-Xms:初始堆大小.只要启动,就占用的堆大小. 2.-Xmx:最大堆大小.java.lang.OutOfMemoryError:Java heap这个错误可以通过配置-Xms和-Xmx参数来设置 ...
- JDBC(五)—— 批量插入数据
批量插入数据 @Test public void testInsert() throws Exception { Connection conn = null; PreparedStatement p ...
- editmd输出到前端显示
官方案例:html-preview-markdown-to-html.html 输出后台数据显示在前端,格式化内容<!DOCTYPE html> <html lang="z ...
- JVM的艺术-对象创建与内存分配机制深度剖析
JVM的艺术-对象创建与内存分配机制深度剖析 引言 本章将介绍jvm的对象创建与内存分配.彻底带你了解jvm的创建过程以及内存分配的原理和区域,以及包含的内容. 对象的创建 类加载的过程 固定的类加载 ...
- webservcie学习之webservice是什么
之前写代码,只是用到的时候才去看相关技术,用过后也没有再回头特别 去看,现在突然发现对一些技术的了解不够深刻,故现在准备再从头对用到的技术深入的学习下.就从webservice开始.首先对我不解的地方 ...
- 每日一个linux命令4
mkdir命令 linux mkdir 命令用来创建指定的名称的目录,要求创建目录的用户在当前目录中具有写权限,并且指定的目录名不能是当前目录中已有的目录. mkdir test 创建一个空目录 ...
- Vue自动化路由(基于Vue-Router)开篇
vue自动化路由 好久不见~ 若羽又开篇Vue的内容了. 年初的时候发布了第一版的ea-router自动化路由库,欢迎大家安装使用.[Github地址] [npm地址] 经历一年的使用.还是发现了不少 ...
- spring*.xml配置文件明文加密
spring*.xml配置文件明文加密 说明:客户要求spring*.xml中Oracle/Redis/MongoDB的IP.端口.用户名.密码不能明文存放,接到需求的我,很无奈,但是还是的硬着头皮搞 ...
- 风炫安全WEB安全学习第十八节课 使用SQLMAP自动化注入(二)
风炫安全WEB安全学习第十八节课 使用SQLMAP自动化注入(二) –is-dba 当前用户权限(是否为root权限) –dbs 所有数据库 –current-db 网站当前数据库 –users 所有 ...