MySQL索引性能分析
为什么要做性能分析
你有没有这样的情况。
面对一个你没怎么写过的、复杂的业务,你构思了很久,终于开始敲下了第一段代码。
写的过程迷迷糊糊,有的时候还能把自己搞晕了。
但你还是终于把它写完了。
但是点击一运行,完了,有bug。
怎么办?
debug的方式有很多,控制台打印是一种。
通过控制台打印的信息,我们能根据反馈去修改代码,直到代码能正常运行为止。
其实建索引也是一样的。
上篇帖子《浅谈sql索引》,说过索引的难点在于针对一个具体的表去做出最合适的索引。
因为这不只要看你表里有什么内容,更多要看你的业务,你的业务会经常根据哪些关键词查找。
代码我们可以天天写,索引不能天天建吧。
所以多数情况下,因为不熟悉,我们一开始建立的索引往往都不是最好的,唯有根据反馈去调整索引,才能做出一个最合适这个表的索引。
今天要分享的就是怎么去看懂这个反馈,即怎么去做性能分析。
怎么做性能分析
使用EXPLAIN关键字!
使用EXPLAIN关键字可以知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈。
但EXPLAIN并不能直接反馈我们建的索引的好坏。
用法是这样的,我们建好了索引,拿着业务中最常用的几句SQL语句来EXPLAIN一下,如果反馈的效果好,那么建立的索引就是最适合这个表的,反之则需要改进。
要不改索引,要不改SQL。
EXPLAIN玩法
语句
explain 要查看的sql语句(横表)或explain 要查看的sql语句\G(竖表)
一个具体的例子

各个字段解释
从上图中我们可以看到,explain出来的信息有以下字段:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|
你仔细看看,这么长是不是有点像工资条?
其中各个字段代表的意思是这样的:
id: 查看表的读取顺序。
咱们上图中的例子只查询了一个表,但若是多表联合查询,则有: id相同的话,执行顺序由上至下; id不同的话,id值越大优先级越高;
select_type: 显示区别联合查询、子查询、普通查询等。
以下为其可能的值,以及对应所代表的信息: SIMPLE -- 简单的select查询,不包含子查询或union; PRIMARY -- 查询中若包含任何复杂的子部分,最外层查询则被标记为PRIMARY; SUBQUERY -- 在select或where包含的子查询; DERIVED -- 在from列表包含的子查询被标记为DERIVED(衍生),MySQL会递归执行这些子查询,把结果放在临时表里; UNION -- 若第二个select出现在union后,则被标记为union;若union包含在from子句的子查询中,外层select将被标记为:DERIVED; UNION RESULT -- 从union表获取结果的select;
table: 显示表名。
type: 显示查询用了何种类型。
以下为其可能的值,以及对应所代表的信息: system -- 表只有一行记录(等于系统表),这是const类型的特例,平时不会出现,可以忽略不记。 const -- 表示通过索引一次就找到了,const用于比较primary key(主键)或者unique(唯一)索引。因为只匹配一行数据,所以很快,如果将主键置于where列表中,mysql就能将该查询转换到一个常量。 eq_ref -- 唯一性扫描索引,对于每个索引键,表中**刚好只**有一条记录与之匹配。常用于主键或唯一索引扫描。 ref -- 非唯一性扫描索引,返回匹配某个单独值的所有行。上面`eq_ref`的多值情况。如where age=1,age=1的数据刚好只有一行,便显示eq_ref,age=1的数据有多行,便显示ref。 range -- 只检索给定范围的行,使用一个索引来选择行。如果type列的值为`range`,key列便会显示使用了哪个索引。一般就是在where语句中出现了between、<、>、in等的查询。这种范围扫描查询比全表扫描要好。 index -- Full Index Scan(扫描全部索引),index与ALL区别为index类型只遍历索引树。都是读全表,但是index是从索引中读取,all是从硬盘中读,而且索引文件通常比数据文件小。 all -- Full Table Scan(扫描全表),遍历全表来找到匹配的行,即索引完全没用上。 从最好到最差依次是:system>const>eq_ref>ref>range>index>ALL 细节: 1. type 是 ALL,当数据到达百万以上一定要优化。 2. 一般来说,如果要优化得保证查询至少达到range级别,最好达到ref。
possible_keys和key
possible_key: 显示可能应用在这张表中的索引,一个或多个。理论上可能被使用的索引,但不一定被查询实际使用。 key: 实际使用的索引,如果为null,则没有使用索引。 这两列有四种情况:
1. possible_key有值,key有值:正常,有的时候前者有多个值但后者只有一个也正常。
2. possible_key有值,key无值:**索引失效了,出现问题了**。
3. possible_key无值,key有值:条件查询(如where)没有用到索引或没有条件查询,但查询的列(select后面的字段)刚好顺序、数量和索引一致。
4. possible_key无值,key无值:正常,就是你没建索引。
key_len: 表示索引中使用的字节数。
可通过该列计算【查询中使用的索引的长度】,在查询结果一样的情况下,该值越小越好。 key_len显示的值为索引字段的最大可能长度,而非实际使用长度,即通过表定义计算而得,不是通过表内检索而得。 假设你建立复合索引(col1,col2),如果【通过col1条件查询】和【通过col1和col2条件查询】的结果一样,那么前者比较好,因为只需要用一个字段,key_len的值会比较小,上面也说过是通过表定义的长度来决定key_len的值。
ref: 显示key列中索引参照的值。
有两种可能的值,以及对应所代表的信息: 库名.表名.字段名 -- 表示索引参照的值是哪个库的哪个表的哪个字段; const -- 表示索引参照的值是常量,一般是where id=1这样才会出现;
rows: 根据表统计信息以及索引选用情况,大致估算出找到要查找的记录需要读取的行数。
Extra: 十分重要的额外信息。
以下为其可能的值,以及对应所代表的信息: Using filesort -- 说明mysql完全或部分没有按照你所建的索引排序,比较需要优化了。MySQL无法利用索引完成的排序操作称为“文件排序”; Using temporary-- 使用了临时表保存中间结果,mysql对查询结果排序时使用临时表。这也比较需要优化,因为临时表的创建和删除都是比较费性能的,常见于order by和group by; Using index -- 表示相应的select操作中使用了覆盖索引,避免了访问表的数据行,效率不错。如果同时出现Using where,表明索引被用来执行索引键值的查询,如果没有出现,表明索引被用来读取数据而非执行查找动作; Using where -- 使用了where过滤; Using join buffer -- 使用了连接缓存,如果总是出现这个字段,可以去配置文件中适当调大这个值; Impossible where -- where子句的值总是false,不能用来获取任何元组; Select tables optimized away -- 在没有group by子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化count(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化; distinct -- 优化distinct操作,在找到第一组匹配的元组后马上停止找相同值的动作。 注意: 1. 使用group by等排序时,如果有用到索引,最好严格按照索引的顺序来,比如,存在复合索引(col1,col2),排序时如果跳过col1,直接使用col2排序,会导致出现Using filesort、Using temporary等比较严重的问题。 2. 尽量使用覆盖索引,select后面的列名完全与建立的索引顺序、数量一致。这样可以直接使用索引读取数据,避免读取表的数据行。
案例
最后来看一个简单的案例,我会先放题目,再放思路,最后放答案。
题目
要求是写出SQL的执行顺序。
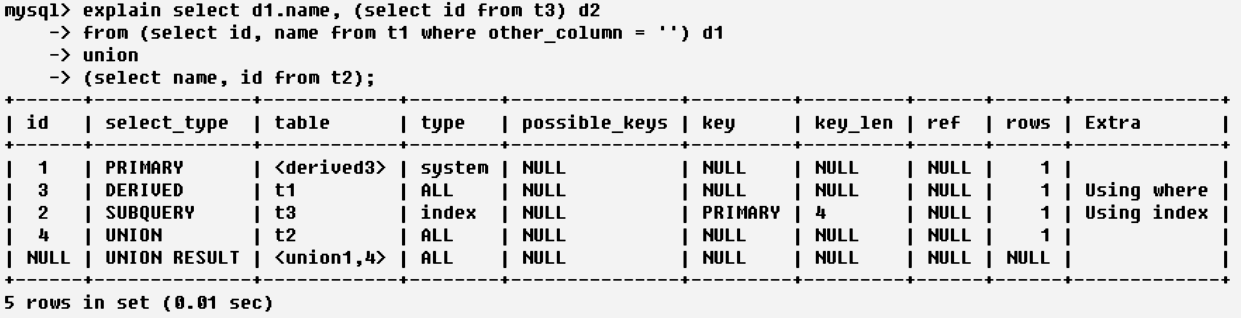
思路
首先看id列,id越大优先级越高,索引从id为4的那一行开始看,这一行的table为t2,即查询的是t2,所以最先查找的反而是最后的部分
select name,id from t2。id为3的这一行,table是t1,所以查的是
select id,name from t1 where other_column='';这一行后面的Extra列的Using where同样佐证了这点。id为2的这一行,table是t3,所以查的是
select id from t3;另外,key列是primary说明用到了主键作为索引,Extra列的Using Index表示用到了覆盖索引(即索引用在了select后面)。id为1的这一行,table是,意思是根据【id为3的那一行的查询结果】来查询(对应的你也可以看到id为3的那一行的select_type列为Derived),所以查的是
select d1.name,(select id from t3)d2 from (select id,name from t1 where other_column = '') d1id为NULL这一行,table是<union1,4>,意思是根据【id为1和4的那两行的查询结果】来实现union查询。
答案
1.select name,id from t2
2.select id,name from t1 where other_column=''
3.select id from t3
4.select d1.name,(3.result)d2 from (2.result) d1
5.(4.result) union (1.result)
最后还是建议结合前面每个字段的解释,有自己的一个思考过程是最好的。
最后
今天说的是如何看explain的结果。
就好像咱们控制台打印信息是为了看代码运行的情况一样,看完了,如果有bug,还要动手改的。
而我们今天只是说如何看而已,下一步,就是如何改了。
MySQL索引性能分析的更多相关文章
- MySQL 索引性能分析概要
上一篇文章 MySQL 索引设计概要 介绍了影响索引设计的几大因素,包括过滤因子.索引片的宽窄与大小以及匹配列和过滤列.在文章的后半部分介绍了 数据库索引设计与优化 一书中,理想的三星索引的设计流程和 ...
- Mysql 索引优化分析
MySQL索引优化分析 为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字 ...
- mySql索引优化分析
MySQL索引优化分析 为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字 ...
- MySQL优化 - 性能分析与查询优化(转)
出处: MySQL优化 - 性能分析与查询优化 优化应贯穿整个产品开发周期中,比如编写复杂SQL时查看执行计划,安装MySQL服务器时尽量合理配置(见过太多完全使用默认配置安装的情况),根据应用负载 ...
- MySQL优化 - 性能分析与查询优化
优化应贯穿整个产品开发周期中,比如编写复杂SQL时查看执行计划,安装MySQL服务器时尽量合理配置(见过太多完全使用默认配置安装的情况),根据应用负载选择合理的硬件配置等. 1.性能分析 性能分析包含 ...
- mysql索引性能验证,高性能的索引策略
索引性能验证 1.无索引列的查询 在where条件中查询没有添加索引的列,性能会比较差.我们可以先在sqlyog中打开表t_user的数据,然后复制一个名字出来进行查询. /*无索引列的查询,索引不会 ...
- oracle使用索引和不使用索引性能分析
首先准备一张百万条数据的表,这样分析数据差距更形象! 下面用分页表数据对表进行分析,根据EMP_ID 字段排序,使用索引和不使用索引性能差距! sql查询语法准备,具体业务根据具体表书写sql语法: ...
- mysql Explain 性能分析关键字
EXPLAIN 输出格式select_typetabletypepossible_keyskeykey_lenrowsExtra MySQL 提供了一个 EXPLAIN 命令, 它可以对 SELECT ...
- mysql索引简单分析
索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点.考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存储100条记录.如果没有索引,查询将对整个表进 ...
随机推荐
- react第十九单元(react+react-router-dom+redux综合案例1)
第十九单元(react+react-router-dom+redux综合案例1) #课程目标 复习 综合练习 实战能力 #知识点 react react-router redux #授课思路 #案例和 ...
- Unity射击实例讲解—子弹创建
前言: 这一篇章会介绍如何创建最基本的射击用子弹,示例用工程进度也往后推了许多,有时间会都整理了发出来,学艺尚浅有一些东西不能讲明白,后续学习深入会慢慢补足.另外自己魔改过的版本也是花钱买了一些模型, ...
- 【python爬虫】一个简单的爬取百家号文章的小爬虫
需求 用"老龄智能"在百度百家号中搜索文章,爬取文章内容和相关信息. 观察网页 红色框框的地方可以选择资讯来源,我这里选择的是百家号,因为百家号聚合了来自多个平台的新闻报道.首先看 ...
- [.NET] - OleDb读取CSV文件:使用指定的分隔符号
今天在用OleDb方式读取一个CSV文件的时候,发现得到的文本不是通常用逗号隔开的.而是用Tab制表符来隔开的. OrderID OrderName 1 1 2 2 3 3 然后去MSND查询了了下发 ...
- 每日CSS_纯CSS制作进度条
每日CSS_纯CSS制作进度条 2020_12_26 源码 1. 代码解析 1.1 html 代码解析 设置整个容器 <div class="container"> . ...
- JVM 经典垃圾收集器 —— CMS 收集器
本文部分摘自<深入理解 Java 虚拟机第三版> 概述 CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器.由于大部分 Java 应用主要 ...
- 【代码周边】-GitHub笔记
------------恢复内容开始------------ 程序员的宝库github是个好东西,其中开源的项目足够我们的使用,但是如何去精准的获取我们的项目是很多初学者的问题.特别是英语不好的我,一 ...
- [leetcode]79.Search Word 回溯法
/** * Given a 2D board and a word, find if the word exists in the grid. The word can be constructed ...
- centos7下mysql安装与卸载
彻底卸载mysql 一.chak 是否有安装mysql a) rpm -qa | grep -i mysql // 查看命令1 b) yum list install mysql* ...
- springboot 不同环境读取不同配置
1. 3个配置文件(更多环境可以建多个): application.properties (公共配置文件) application-dev.properties (开发环境) applicatio ...