kubernets之计算资源
一 为pod分配cpu,内存以及其他的资源
1.1 创建一个pod,同时为这个pod分配内存以及cpu的资源请求量
apiVersion: v1
kind: Pod
metadata:
name: requests-pod
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
requests:
cpu: 200m
memory: 10Mi
- 如下配置的容器里面添加了requests字段,包括cpu以及内存的请求量
- cpu:200m的含义是容器最少可使用宿主机的200毫核(即一个cpu核心时间的1/5)
- memory:10Mi的含义是该容器使用10M的内存
1.2 来验证一下这个pod内的容器使用的cpu核数
Mem: 2904756K used, 977004K free, 179080K shrd, 0K buff, 2061448K cached
CPU: 4.4% usr 21.6% sys 0.0% nic 73.5% idle 0.0% io 0.0% irq 0.0% sirq
Load average: 1.04 1.07 1.05 2/424 15
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root R 1300 0.0 2 25.0 dd if /dev/zero of /dev/null
6 0 root S 1308 0.0 1 0.0 top
11 0 root R 1308 0.0 3 0.0 top [root@node01 Chapter14]# cat /proc/cpuinfo| grep "processor"| wc -l
4
- 由于这个机器是一个四核的虚拟机,,所有这个进程只能占据全部核数的1/4
- 可以看到通过这个参数,让容器最少可以使用20%,却不是只能使用20%
1.3 了解调度器如何判断一个pod是否适合调度某个节点
首先调度器在调度的适合并不关注各类资源在当前时刻的实际使用量,而只关心节点上pod的资源的申请量之和,原因是如果是看集群所有资源的实际使用总和的话,那么之前那些资源分配的额度就有可能达不到了
用一张图来看下所描述的现象
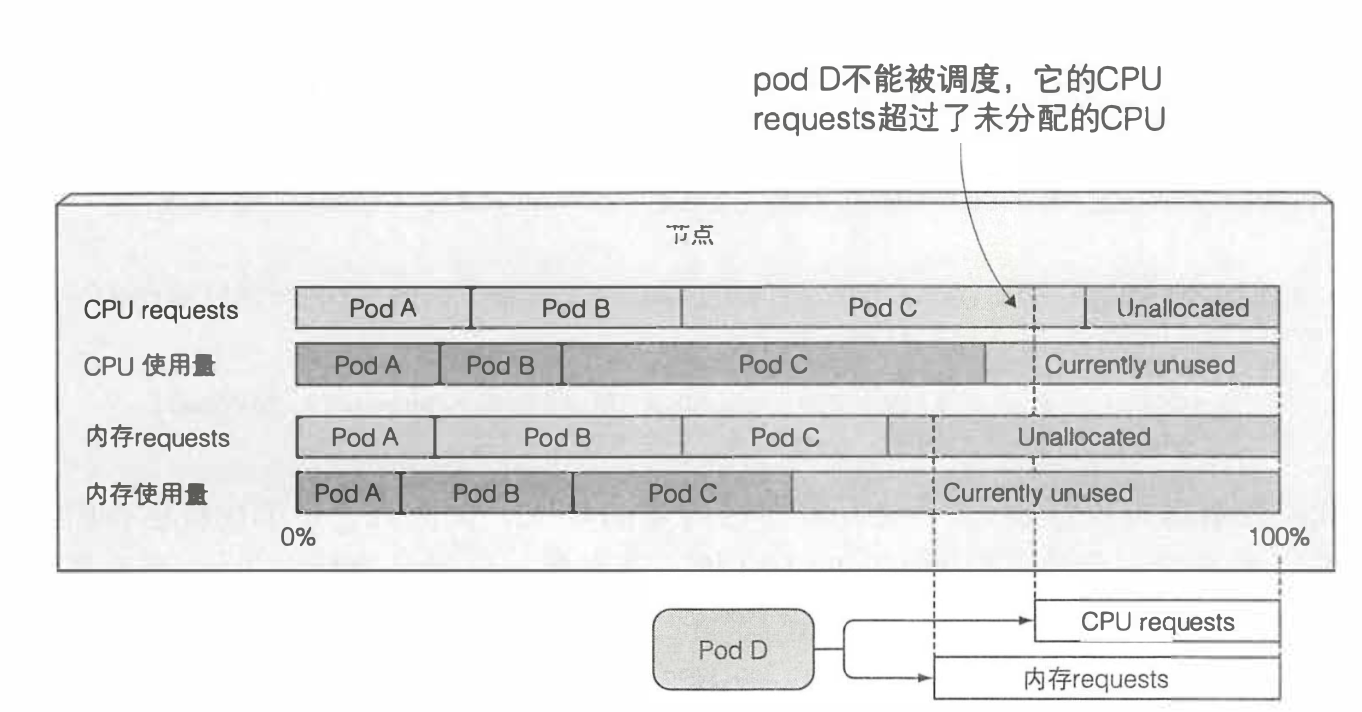
- 如下图所示,节点上CPU的申请量是80%,但是实际使用量只有70%,我们的podD的申请量是25%
- 若按照实际使用量来看,pod还是可以被调度上去的,但是实际上已经无法进行调度了,因为它是根据资源的申请量来计算的
1.4 调度器如何通过pod requests为其选择最佳节点
之前了解过调度器的调度原理的时候,首先会排除那些不满足需求的节点,之后会有一个LeastRequestPriority和MostRequestPriority,前者优先级将pod调度到请求量少的节点,而后者则是优先将pod调度到请求资源较多的节点,一般自家建设的kubernetes集群都倾向于使用前面的策略,这样的话负载均衡会好点,但是如果是运行云基础设施上面的话,使用后者的话,会省去一笔很大的开支
1.5 查看节点资源总量
Name: node01
......
InternalIP: 172.16.70.4
Hostname: node01
Capacity:
cpu: 4
ephemeral-storage: 8178Mi
hugepages-2Mi: 0
memory: 3881760Ki
pods: 110
Allocatable:
cpu: 4
ephemeral-storage: 7717729063
hugepages-2Mi: 0
memory: 3779360Ki
pods: 110
......
- 红色字体显示的节点的资源总量
- 绿色的字体显示的可分配给pod的资源量
- 之所以系统总量和可分配给pod的总量,是因为要预留一些资源给系统的pod
1.6 创建一个cpu请求量较大的pod,观察能否创建成功,如果失败又是如何
[root@node01 Chapter14]# k run request-pod-3 --image=busybox --restart Never --requests='cpu=4,memory=20Mi' -- dd if=/dev/zero of=/dev/null
pod/request-pod-3 created [root@node01 Chapter14]# k get po
NAME READY STATUS RESTARTS AGE
request-pod-2 1/1 Running 0 3m4s
request-pod-3 0/1 Pending 0 3s
requests-pod 1/1 Running 0 4h52m
[root@node01 Chapter14]# k describe po request-pod-3
Name: request-pod-3
Namespace: default
Priority: 0
Node: <none>
Labels: run=request-pod-3
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Containers:
request-pod-3:
Image: busybox
Port: <none>
Host Port: <none>
Args:
dd
if=/dev/zero
of=/dev/null
Requests:
cpu: 4
memory: 20Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-tzwwt (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
default-token-tzwwt:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-tzwwt
Optional: false
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 13s (x2 over 13s) default-scheduler 0/3 nodes are available: 3 Insufficient cpu.
- 创建一个超级大cpu请求量之后,集群的任何节点都无法满足这个pod
- 如红色字体显示,无法调度到任何的节点,因为任何节点都没有足够的cpu可以分配
kubernets之计算资源的更多相关文章
- Compute Resource Consolidation Pattern 计算资源整合模式
Consolidate multiple tasks or operations into a single computational unit. This pattern can increase ...
- 云计算被视为继大型计算机、个人计算机、互联网之后的第4次IT产业革命,顺应了当前各行业整合计算资源和服务能力的要求(转)
云计算被视为继大型计算机.个人计算机.互联网之后的第4次IT产业革命,顺应了当前各行业整合计算资源和服务能力的要求,成为引领当今世界信息技术变革的主力军.越来越多的金融企业认识到只有与云计算结合,才能 ...
- kubernetes之管理容器的计算资源
资源类型 CPU 和 memory 都是 资源类型.资源类型具有基本单位.CPU 的单位是 core,memory 的单位是 byte.这些都统称为计算资源. CPU含义: CPU 资源的限制和请求以 ...
- 华为FusionSphere概述——计算资源、存储资源、网络资源的虚拟化,同时对这些虚拟资源进行集中调度和管理
华为FusionSphere概述 FusionSphere是华为自主知识产权的云操作系统,集虚拟化平台和云管理特性于一身,让云计算平台建设和使用更加简捷,专门满足企业和运营商客户云计算的需求.华为云操 ...
- CUP计算资源争抢通过IIS启用处理器关联解决
由于业务的复杂性,我们在客户环境部署的时候,采用的是预装好在一台机器然后再把机器安装到客户环境,所以为了简单方便,我们把所有的服务都安装到一台机器上面了. 在正常的使用过程中是没有任何问题的.但是当有 ...
- kubernetes 降本增效标准指南| 容器化计算资源利用率现象剖析
作者:詹雪娇,腾讯云容器产品经理,目前主要负责腾讯云集群运维中心的产品工作. 张鹏,腾讯云容器产品工程师,拥有多年云原生项目开发落地经验.目前主要负责腾讯云TKE集群和运维中心开发工作. 引言 降本增 ...
- k8s中计算资源策略 Limit Range
文章转载自:https://www.kuboard.cn/learning/k8s-advanced/policy/lr.html 默认情况下,容器在 Kubernetes 集群上运行时,不受 计算资 ...
- Spark Streaming性能优化系列-怎样获得和持续使用足够的集群计算资源?
一:数据峰值的巨大影响 1. 数据确实不稳定,比如晚上的时候訪问流量特别大 2. 在处理的时候比如GC的时候耽误时间会产生delay延迟 二:Backpressure:数据的反压机制 基本思想:依据上 ...
- kubernets之statefulset资源
一 了解Statefulset 1.1 对比statefulset与RS以及RC的区别以及相同点 Statefulset是有状态的,而RC以及RS等是没有状态的 Statefulset是有序的,拥 ...
随机推荐
- 双端口RAM和多模块存储器
目录 双端口RAM 存取周期 双端口RAM 多模块存储器 普通存储器 单体多字存储器 多体并行的存储器 高位交叉编址的多体存储器 低位交叉编址的多提存储器 为什么要这么弄? 高位 低位 流水线(考试常 ...
- 精尽Spring MVC源码分析 - 一个请求的旅行过程
该系列文档是本人在学习 Spring MVC 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释 Spring MVC 源码分析 GitHub 地址 进行阅读 Spring 版本:5.2. ...
- [日常摸鱼]bzoj2724蒲公英-分块
区间众数经典题~ http://begin.lydsy.com/JudgeOnline/problem.php?id=4839这里可以提交~ 题意大概就是没有修改的询问区间众数,如果有一样的输出最小的 ...
- Shell-匹配行及date日期转换
#将指定字符串转化为从1970年1月1日到现在的秒数. date -d '20170506' "+%s" #将1970年1月1日到现在累计的秒数转化为日期 date -d @149 ...
- CentOS8/Windows 安装RabbitMQ
Centos8安装rabbitmq 1.安装erlang(rabbitmq是用erlang语言开发的,erlang版本需要22.x以上) yum install erlang 2.下载rabbitmq ...
- 技术基础 | 用JSON在抖音上发布动态——使用Stargate即可轻松实现
Cassandra是世界上经受住最多实战考验的数据库,通过其快速且易于使用的数据API,让你的程序开发升级. 本文将介绍什么是Stargate以及Stargate的最新进展,如果您想快速浏览相关代码和 ...
- [LeetCode]141. Linked List Cycle判断循环链表
快慢指针用来判断循环链表 记住 快慢指针有四种常用的应用场景: 1.找到有序链表的中点,快指针到头的时候,慢指针就是中点. 2.判断是不是循环链表,快慢指针相遇就是 3.找到循环链表的起点,以链表头 ...
- [LeetCode]319. Bulb Switcher灯泡开关
智商压制的一道题 这个题有个数学定理: 一般数(非完全平方数)的因子有偶数个 完全平凡数的因子有奇数个 开开关的时候,第i个灯每到它的因子一轮的时候就会拨动一下,也就是每个灯拨动的次数是它的因子数 而 ...
- Java对象赋值与引用
当需要创建多个相同类型的对象且有某些字段的值是相同的,如果直接 get,set 的话,属性多的时候代码会很长,于是乎,以下代码产生了( java 基础差没搞清楚赋值与引用) 复制代码 1 User u ...
- KafkaProducer 简析
使用方式 KafkaProducer 发送消息主要有以下 3 种方式: Properties properties = new Properties(); properties.setProperty ...