你知道MySQL是如何处理千万级数据的吗?
mysql 分表思路
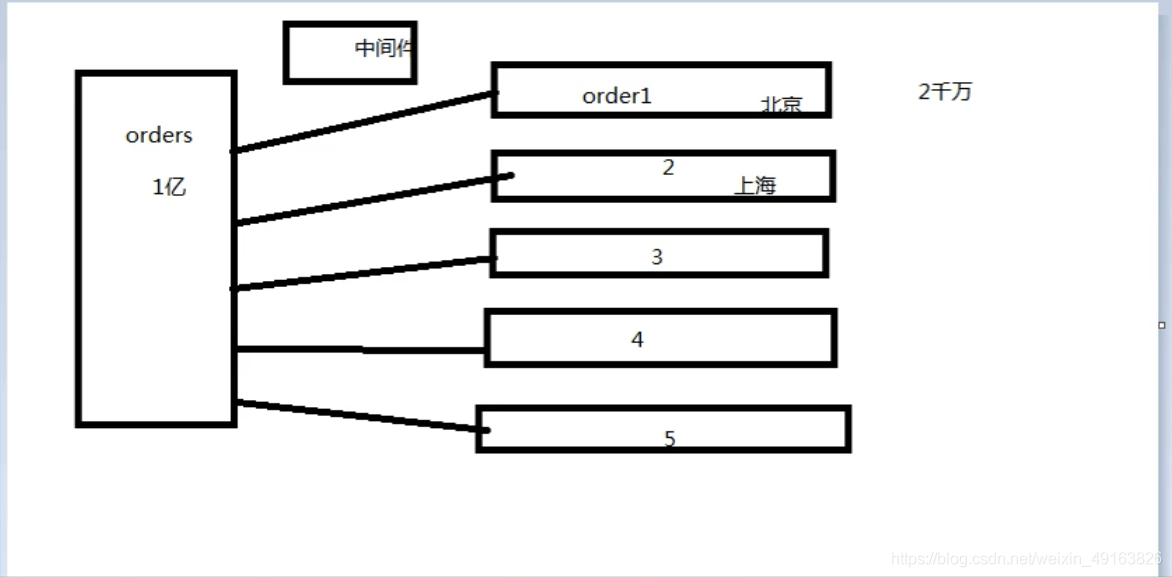
一张一亿的订单表,可以分成五张表,这样每张表就只有两千万数据,分担了原来一张表的压力,分表需要根据某个条件进行分,这里可以根据地区来分表,需要一个中间件来控制到底是去哪张表去找到自己想要的数据。
中间件:根据主表的自增 id 作为中间件(什么样的字段适合做中间件?要具备唯一性)
怎么分发?主表插入之后返回一个 id,根据这个 id 和表的数量进行取模,余数是几就往哪张表中插入数据。
注意:子表中的 id 要与主表的 id 保持一致
以后只有插入操作会用到主表,修改,删除,读取,均不需要用到主表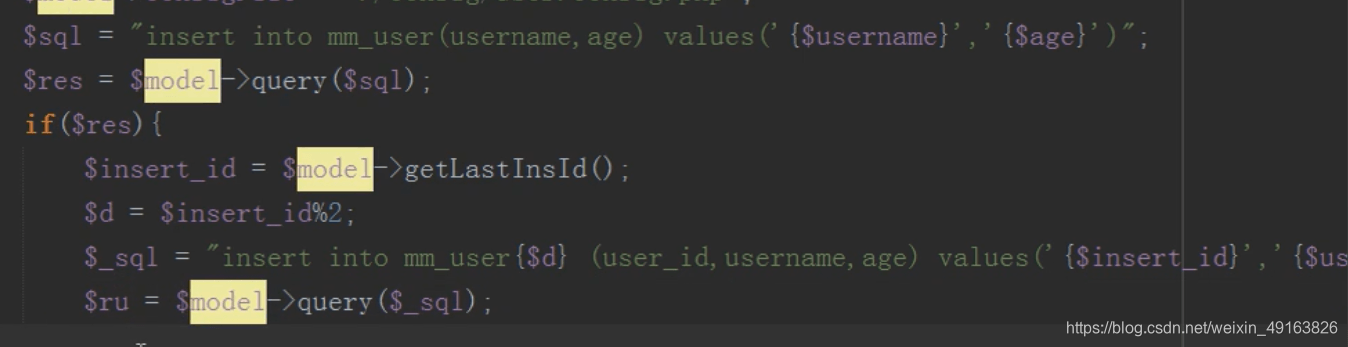
redis 消息队列
- 什么是消息队列?
答:消息传播过程中保存消息的容器 - 消息队列产生的历史原因
答:主要原因是由于在高并发环境下,由于来不及同步处理,请求往往会发生堵塞,比如说,大量的insert,update之类的请求同时到达MySQL,直接导致无数的行锁表锁,甚至最后请求会堆积过多,从而触发并发错误。通过使用消息队列,我们可以异步处理请求,从而缓解系统的压力。
消息队列的特点: 先进先出
把要执行的 sql 语句先保存在消息队列中,然后依次按照顺利异步插入的数据库中
应用: 新浪,把瞬间的评论先放入消息队列,然后通过定时任务把消息队列里面的 sql 语句依次插入到数据库中
修改
操作子表进行修改
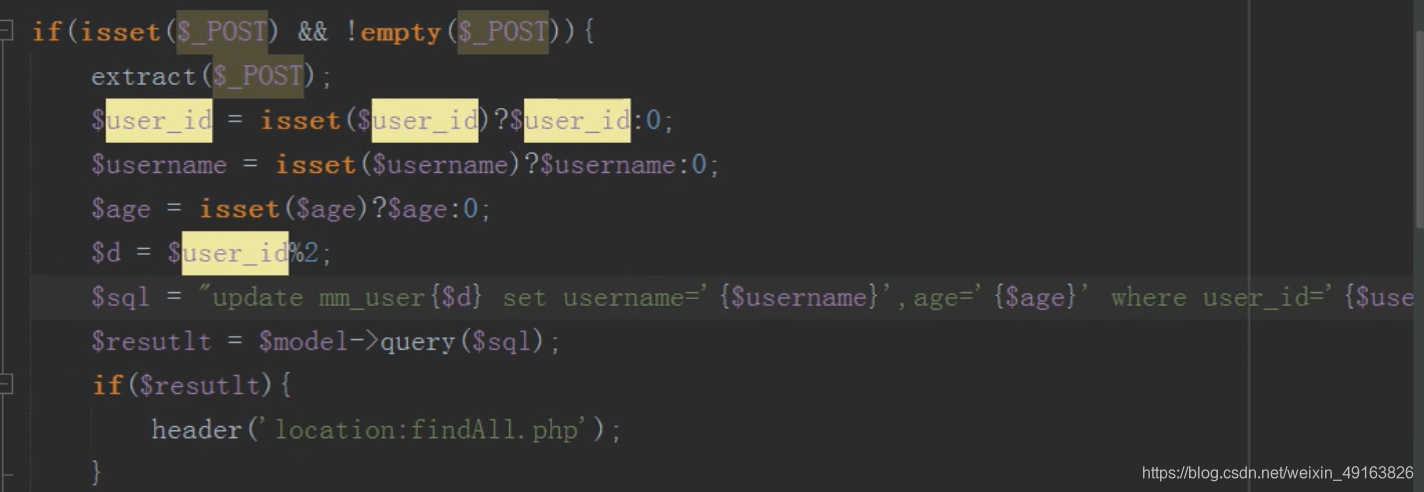
这样修改有一个问题,主表和子表的数据会出现不一致,如何让主表和字表数据一致?
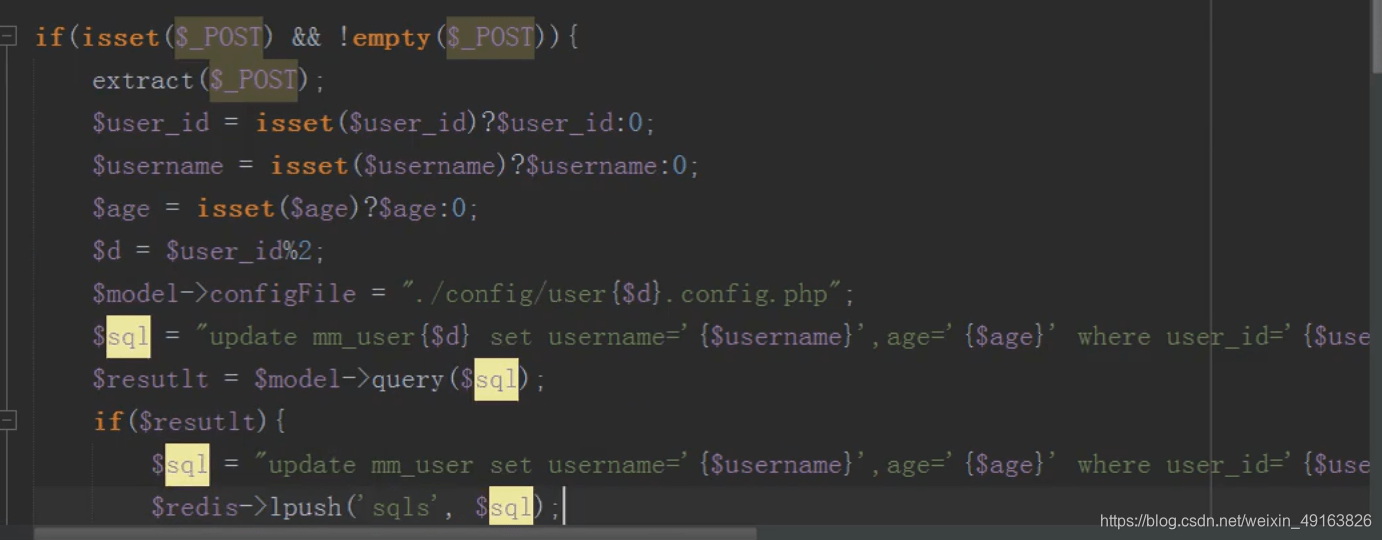
redis 队列保持主表子表数据一致
修改完成后将要修改主表的数据,存入 redis 队列中
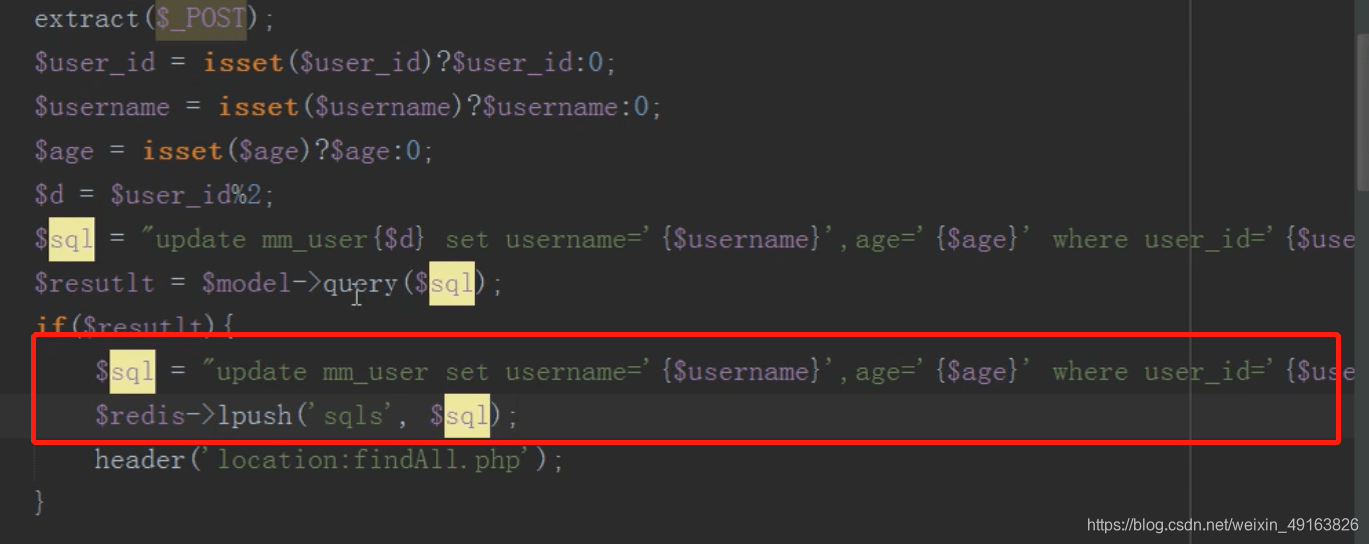
然后 linux 定时任务(contble)循环执行 redis 队列中的 sql 语句,同步更新主表的内容
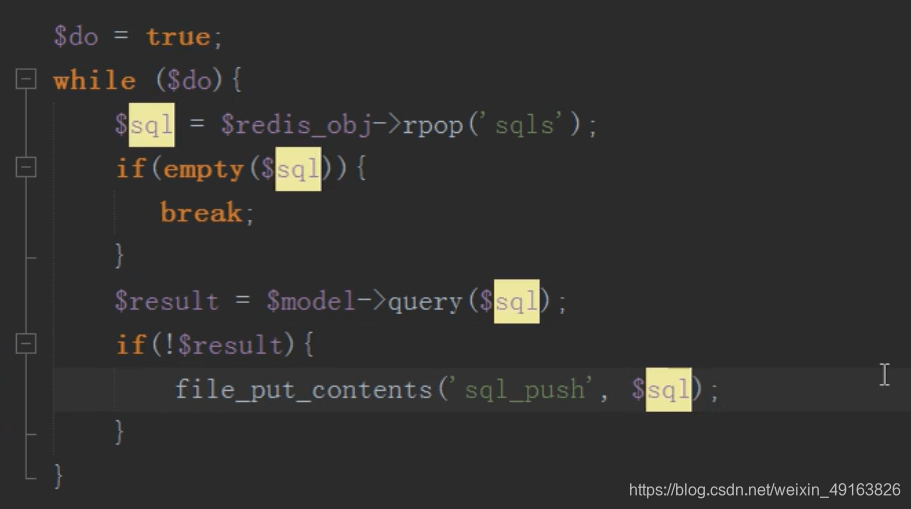
mysql 分布式之分表(查,删)
查询只需要查询子表,不要查询总表

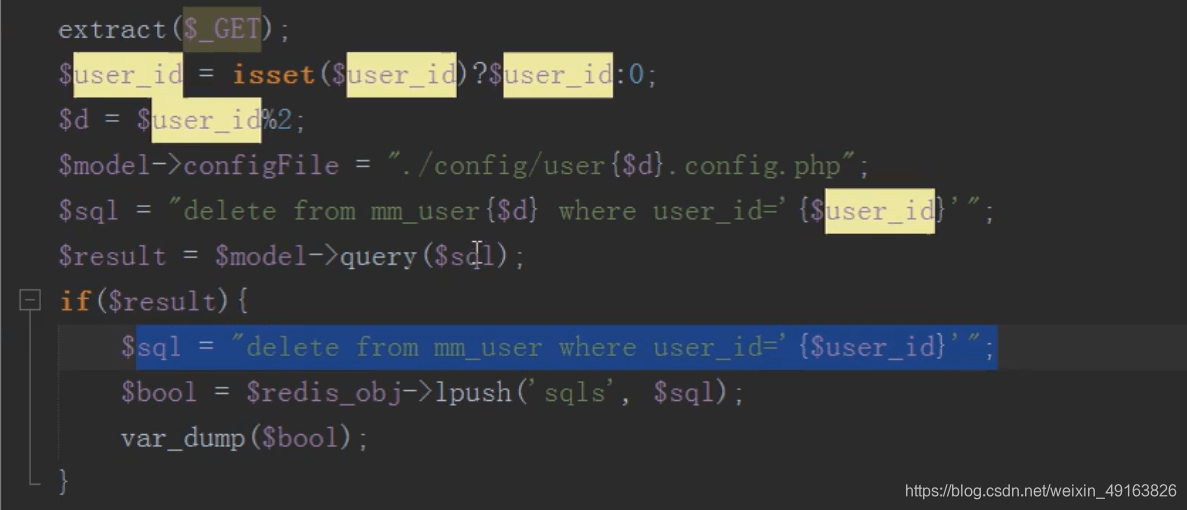
删除,先根据 id 找到要删除的子表,然后删除,然后往消息队列中压入一条删除总表数据的 sql 语句
然后执行定时任务删除总表数据
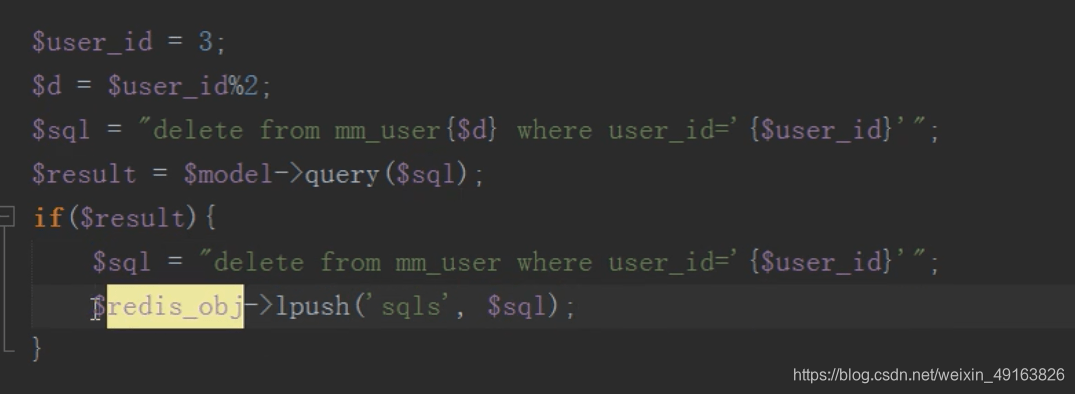
定时任务:
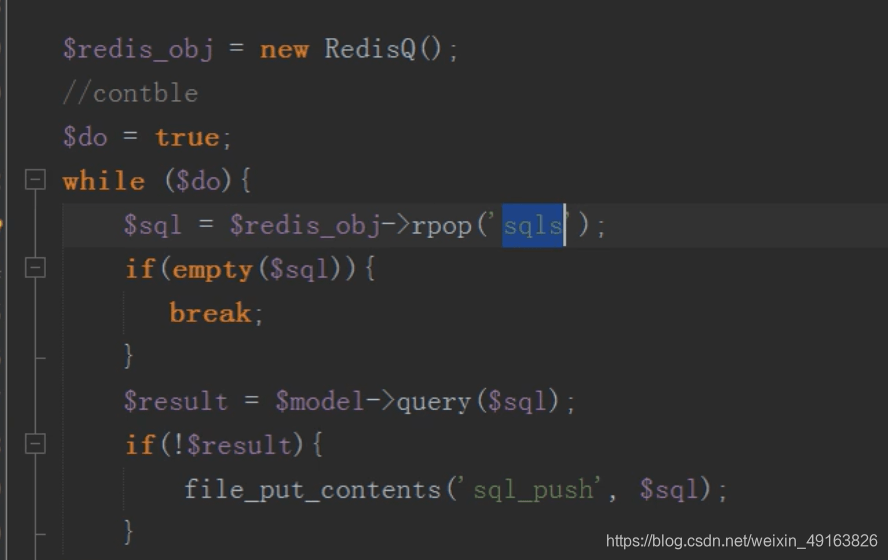
mysql 分布式之分库
分库思路
- 单库单表
单库单表是最常见的数据库设计,例如,有一张用户(user)表房子啊数据库db中,所有的用户都是可以在db库中的user表中查到。 - 单库多表
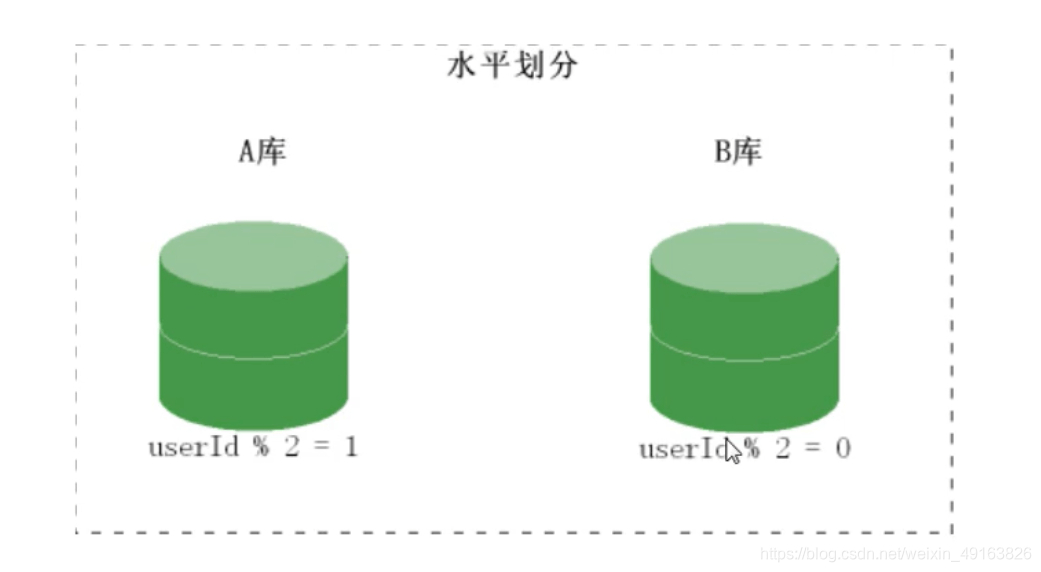
随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度的时候对user表的查询会渐渐的变慢,从而影响整个DB的性能。可以通过某种方式将user进行水平的切分,产生两个表结构完全一样的user_0000,user-0001等表,user_0000 + user-0001 + …的数据刚好是一份完整的数据。 - 多库多表
随着数据量增加也许单台DB的存储空间不够,随着查询量的增加单台数据库服务器已经没办法支撑。这个时候可以再对数据库进行水平区分。
分库原理图:
mysql 分布式之分库(增)
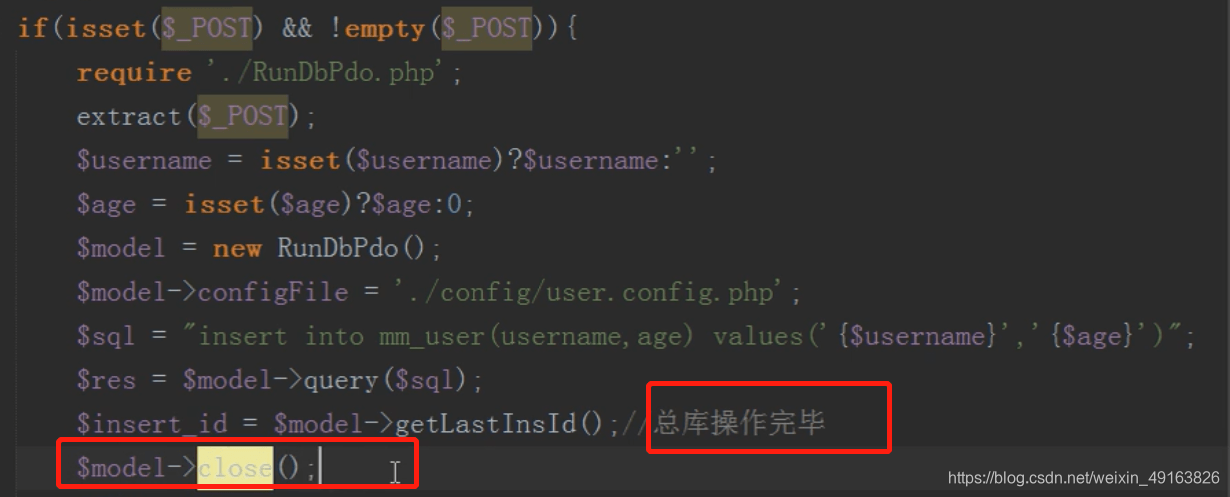
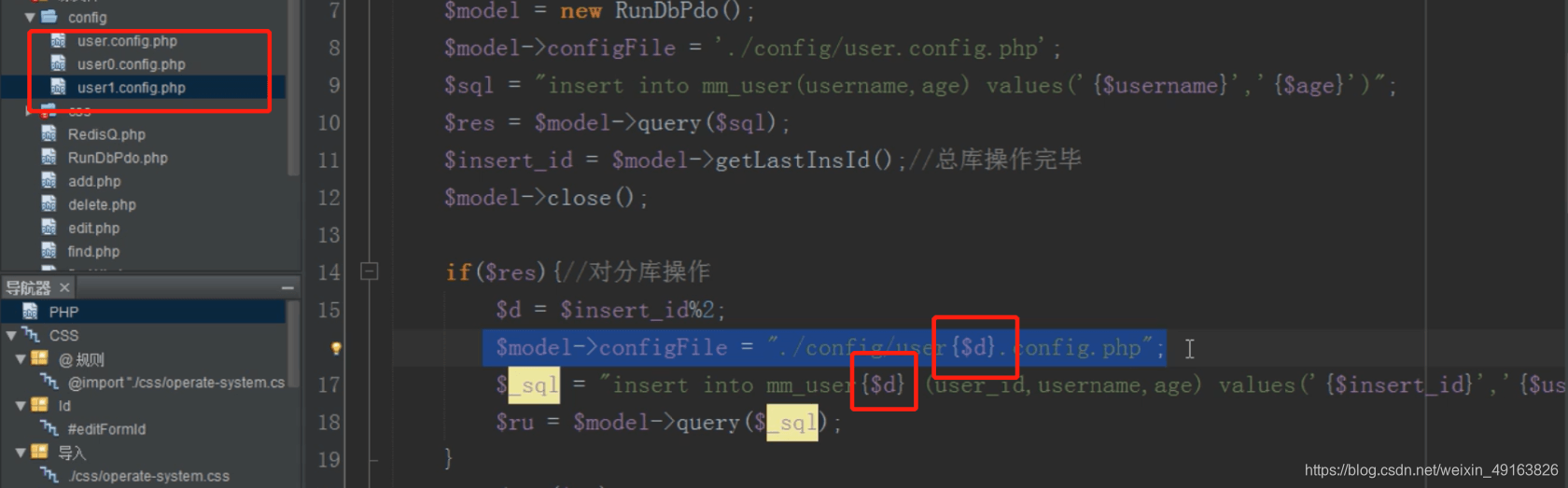
注意:操作完一个数据库一定要把数据库连接关闭,不然 mysql 会以为一直连接的同一个数据库
还是取模确定加载哪个配置文件连接哪个数据库
mysql 分布式之分库(改)
原理同新增
mysql 分布式之分库(查,删)
原理类似

删除
执行队列
mysql 分布式之缓存(memcache)的应用
将数据放入缓存中,节省数据库开销,先去缓存中查,如果有直接取出,如果没有,去数据库查,然后存入缓存中
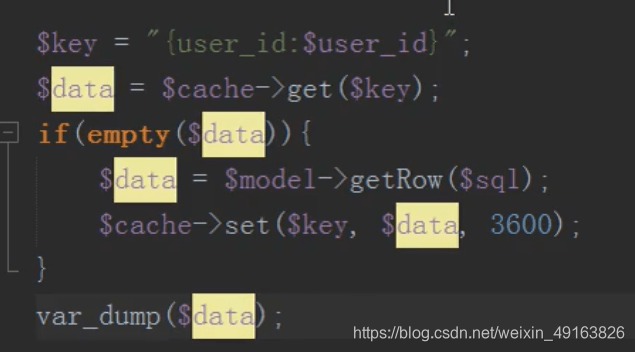
在编辑信息之后需要删除缓存,不然一直读取的是缓存的数据而不是修改过的数据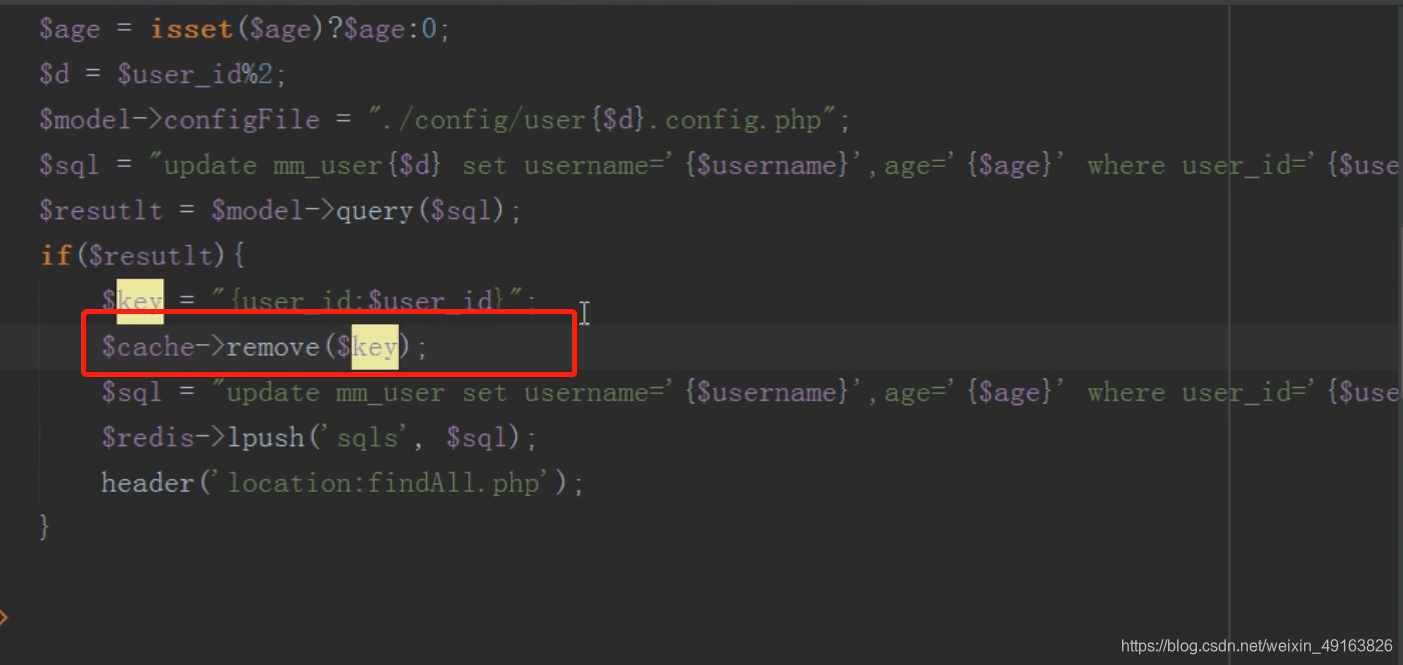
还有更多进阶学习资料在这噢进阶PHP月薪30k>>>架构师成长路线【视频、面试文档免费获取】
你知道MySQL是如何处理千万级数据的吗?的更多相关文章
- 转载:mysql 对于百万 千万级数据的分表实现方法
一般来说,当我们的数据库的数据超过了100w记录的时候就应该考虑分表或者分区了,这次我来详细说说分表的一些方法.目前我所知道的方法都是MYISAM的,INNODB如何做分表并且保留事务和外键,我还不是 ...
- MySQL千万级数据分区存储及查询优化
作为传统的关系型数据库,MySQL因其体积小.速度快.总体拥有成本低受到中小企业的热捧,但是对于大数据量(百万级以上)的操作显得有些力不从心,这里我结合之前开发的一个web系统来介绍一下MySQL数据 ...
- mysql千万级数据量查询出所有重复的记录
查询重复的字段需要创建索引,多个条件则创建组合索引,各个条件的索引都存在则不必须创建组合索引 有些情况直接使用GROUP BY HAVING则能直接解决:但是有些情况下查询缓慢,则需要使用下面其他的方 ...
- MySQL百万级、千万级数据多表关联SQL语句调优
本文不涉及复杂的底层数据结构,通过explain解释SQL,并根据可能出现的情况,来做具体的优化,使百万级.千万级数据表关联查询第一页结果能在2秒内完成(真实业务告警系统优化结果).希望读者能够理解S ...
- 如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案
如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案
- Mysql千万级数据删除实操-企业案例
某天,在生产环节中,发现一个定时任务表,由于每次服务区查询这个表就会造成慢查询,给mysql服务器带来不少压力,经过分析,该表中绝对部分数据是垃圾数据 需要删除,约1050万行,由于缺乏处理大数据的额 ...
- (转载)MYSQL千万级数据量的优化方法积累
转载自:http://blog.sina.com.cn/s/blog_85ead02a0101csci.html MYSQL千万级数据量的优化方法积累 1.分库分表 很明显,一个主表(也就是很重要的表 ...
- 转载自lanceyan: 一致性hash和solr千万级数据分布式搜索引擎中的应用
一致性hash和solr千万级数据分布式搜索引擎中的应用 互联网创业中大部分人都是草根创业,这个时候没有强劲的服务器,也没有钱去买很昂贵的海量数据库.在这样严峻的条件下,一批又一批的创业者从创业中获得 ...
- 完全用nosql轻松打造千万级数据量的微博系统(转)
原文:http://www.cnblogs.com/imxiu/p/3505213.html 其实微博是一个结构相对简单,但数据量却是很庞大的一种产品.标题所说的是千万级数据量 也并不是一千万条微博信 ...
随机推荐
- git怎么合并远程分支
一共就五步: 1.把代码clone到本地仓库 git clone https://github.com/573734817pc/shop.git 2.在本地创建dev分支并与远程dev分支对应 git ...
- DEP(Data Execution Prevention) 数据执行保护
1.原理 数据执行保护,简称“DEP”,英文全称为“Data Execution Prevention”,是一组在存储器上运行额外检查的硬件和软件技术,有助于防止恶意程序码在系统上运行. 此技术由Mi ...
- Python Ethical Hacking - MODIFYING DATA IN HTTP LAYER(2)
MODIFYING DATA IN HTTP LAYER Edit requests/responses. Replace download requests. Inject code(html/Ja ...
- 评测Loki日志工具
评测Loki日志工具 目录 评测Loki日志工具 部署Loki 配置grafana 总结: 优势: 劣势: 本文仅对Loki进行简单评测,不涉及原理和细节. 部署Loki Loki是grafana团队 ...
- Spark入门(第1讲)
一.Spark是什么 引用官方文档的一句话 Apache Spark is a unified analytics engine for large-scale data processing. Ap ...
- 遇到的spring问题,或许需要下载新的java jdk
org.springframework.context.support.AbstractApplicationContext
- SpringCloud Bus 动态刷新全局广播和定点通知
全局广播 前提: 先具备良好的 RabbitMQ 环境 1. 演示广播效果,增加复杂度,再以3355为模板再制做一个3366模块 <!--pom.xml--> <?xml versi ...
- 每日一道 LeetCode (5):最长公共前缀
前文合集 每日一道 LeetCode 前文合集 代码仓库 GitHub: https://github.com/meteor1993/LeetCode Gitee: https://gitee.com ...
- LVS-DR:搭建HTTP和HTTPS负载均衡集群
目录 LVS-DR实战:搭建HTTP和HTTPS负载均衡集群 1. 搭建lvs-dr模式的http负载集群 1.1 LVS上配置IP 1.2 RS上配置arp内核参数 1.3 RS上配置VIP 1.4 ...
- Hibernate 映射
在使用单纯hibernate文件映射时,项目应包含以下文件: hibernate.cfg.xml 放在src/或根目录下 1 <?xml version='1.0' encoding='utf ...