采用Sharding-JDBC解决分库分表
一、Sharding-JDBC介绍
1,介绍
Sharding-JDBC是当当网研发的开源分布式数据库中间件,从 3.0 开始Sharding-JDBC被包含在 Sharding-Sphere中,之后该项目进入进入Apache孵化器,4.0版本之后的版本为Apache版本。
- 适用于任何基于Java的ORM框架,如: Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
上图展示了Sharding-Jdbc的工作方式,使用Sharding-Jdbc前需要人工对数据库进行分库分表,在应用程序中加入Sharding-Jdbc的Jar包,应用程序通过Sharding-Jdbc操作分库分表后的数据库和数据表,由于Sharding-Jdbc是对Jdbc驱动的增强,使用Sharding-Jdbc就像使用Jdbc驱动一样,在应用程序中是无需指定具体要操作的分库和分表的。
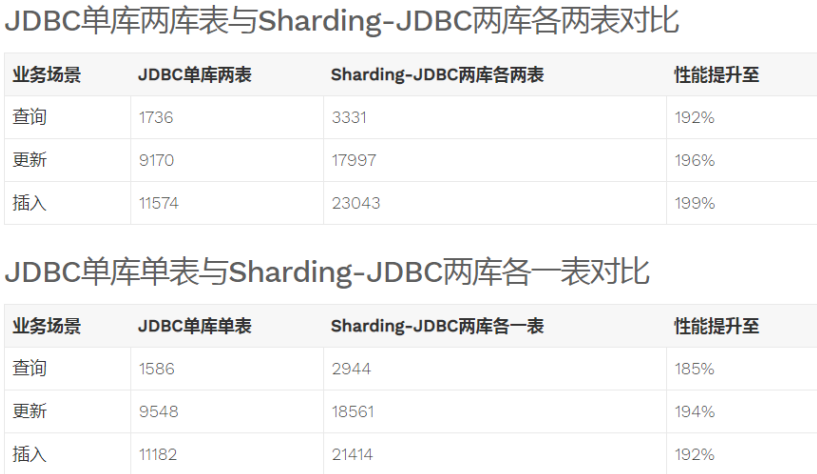
2,与jdbc性能对比
a)性能损耗测试
服务器资源充足、并发数相同,比较JDBC和Sharding-JDBC性能损耗,Sharding-JDBC相对JDBC损耗不超过7%。

b)性能对比测试
服务器资源使用到极限,相同的场景JDBC与Sharding-JDBC的吞吐量相当。

服务器资源使用到极限,Sharding-JDBC采用分库分表后,Sharding-JDBC吞吐量较JDBC不分表有接近2倍的提升。
二、Sharding-JDBC执行原理
1,基本概念
a)逻辑表
水平拆分的数据表的总称。例:订单数据表根据主键尾数拆分为10张表,分别是 t_order_0 、 t_order_1 到t_order_9 ,他们的逻辑表名为 t_order 。
b)真实表
在分片的数据库中真实存在的物理表。即上个示例中的 t_order_0 到 t_order_9 。
c)数据节点
数据分片的最小物理单元。由数据源名称和数据表组成,例: ds_0.t_order_0 。
d)绑定表
指分片规则一致的主表和子表。例如: t_order 表和 t_order_item 表,均按照 order_id 分片,绑定表之间的分区键完全相同,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11)
e)广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
f)分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,Sharding-Jdbc也支持根据多个字段进行分片。
g)分片算法
通过分片算法将数据分片,支持通过 = 、 BETWEEN 和 IN 分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。包括:精确分片算法 、范围分片算法 ,复合分片算法 等。例如:where order_id = ? 将采用精确分片算法,where order_id in (?,?,?)将采用精确分片算法,where order_id BETWEEN ? and ? 将采用范围分片算法,复合分片算法用于分片键有多个复杂情况。
h)分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。内置的分片策略大致可分为尾数取模、哈希、范围、标签、时间等。由用户方配置的分片策略则更加灵活,常用的使用行表达式配置分片策略,它采用Groovy表达式表示,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为 t_user_0 到 t_user_7 。
i)自增主键生成策略
通过在客户端生成自增主键替换以数据库原生自增主键的方式,做到分布式主键无重复。
2,SQL解析
当Sharding-JDBC接受到一条SQL语句时,会陆续执行 SQL解析 => 查询优化 => SQL路由 => SQL改写 => SQL执行 =>结果归并 ,最终返回执行结果。
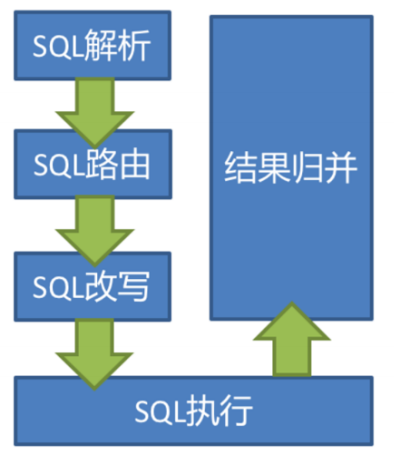
SQL解析过程分为词法解析和语法解析。 词法解析器用于将SQL拆解为不可再分的原子符号,称为Token。并根据不同数据库方言所提供的字典,将其归类为关键字、表达式、字面量和操作符。 再使用语法解析器将SQL转换为抽象语法树。
例如,SQL:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
解析之后的为抽象语法树见下图:

为了便于理解,抽象语法树中的关键字的Token用绿色表示,变量的Token用红色表示,灰色表示需要进一步拆分。
3,路由
a)标准路由
SELECT * FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
b)笛卡尔路由
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
笛卡尔路由查询性能较低,需谨慎使用。
c)全库表路由
对于不携带分片键的SQL,则采取广播路由的方式。根据SQL类型又可以划分为全库表路由、全库路由、全实例路由、单播路由和阻断路由这5种类型。其中全库表路由用于处理对数据库中与其逻辑表相关的所有真实表的操作,主要包括不带分片键的DQL(数据查询)和DML(数据操纵),以及DDL(数据定义)等。例如:
SELECT * FROM t_order WHERE good_prority IN (1, 10);
会遍历所有数据库中的所有表,逐一匹配逻辑表和真实表名,能够匹配得上则执行。路由后成为:
SELECT * FROM t_order_0 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_1 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_2 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_3 WHERE good_prority IN (1, 10);
4,SQL改写
SELECT order_id FROM t_order WHERE order_id=1;
#假设该SQL配置分片键order_id,并且order_id=1的情况,将路由至分片表1。那么改写之后的SQL应该为
SELECT order_id FROM t_order_1 WHERE order_id=1;
Sharding-JDBC需要在结果归并时获取相应数据,但该数据并未能通过查询的SQL返回。 这种情况主要是针对GROUP BY和ORDER BY。结果归并时,需要根据 GROUP BY 和 ORDER BY 的字段项进行分组和排序,但如果原始SQL的选择项中若并未包含分组项或排序项,则需要对原始SQL进行改写。
例如:
#如果选择项中不包含结果归并时所需的列,则需要进行补列,如以下SQL:
SELECT order_id FROM t_order ORDER BY user_id;
#原始SQL中并不包含需要在结果归并中需要获取的user_id,因此需要对SQL进行补列改写。
SELECT order_id, user_id AS ORDER_BY_DERIVED_0 FROM t_order ORDER BY user_id;
5,SQL执行
Sharding-JDBC采用一套自动化的执行引擎,负责将路由和改写完成之后的真实SQL安全且高效发送到底层数据源执行。 它不是简单地将SQL通过JDBC直接发送至数据源执行;也并非直接将执行请求放入线程池去并发执行。它更关注平衡数据源连接创建以及内存占用所产生的消耗,以及最大限度地合理利用并发等问题。 执行引擎的目标是自动化的平衡资源控制与执行效率,他能在以下两种模式自适应切换:
a)内存限制模式
b)连接限制模式
6,结果归并

a)内存归并
b)流式归并
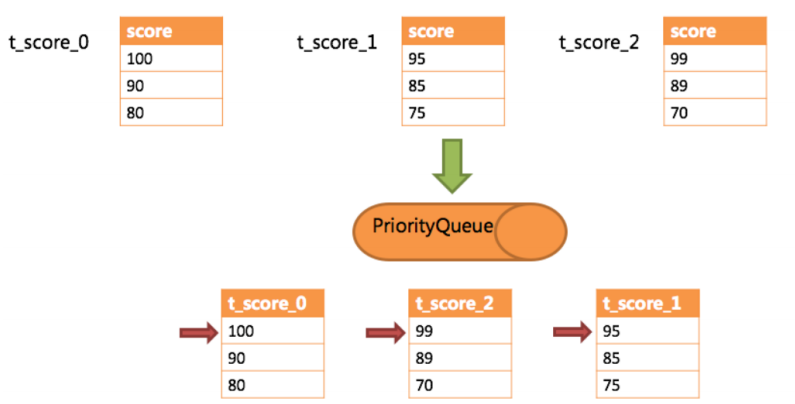
c)装饰者归并
是对所有的结果集归并进行统一的功能增强,比如归并时需要聚合SUM前,在进行聚合计算前,都会通过内存归并或流式归并查询出结果集。因此,聚合归并是在之前介绍的归并类型之上追加的归并能力,即装饰者模式。
三、水平分表
1,建表
#创建数据库
CREATE DATABASE `order_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
#建表
USE order_db;
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` BIGINT (20) NOT NULL COMMENT '订单id',
`price` DECIMAL (10, 2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT (20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` BIGINT (20) NOT NULL COMMENT '订单id',
`price` DECIMAL (10, 2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT (20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2,添加maven依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
3,properties配置
#数据源
spring.shardingsphere.datasource.names=m1
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://hadoop102:3306/order_db?useUnicode=true
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
# 指定t_order表的数据分布情况,配置数据节点 m1.t_order_1,m1.t_order_2
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=m1.t_order_$->{1..2}
# 指定t_order表的主键生成策略为SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
# 指定t_order表的分片策略,分片策略包括分片键(order_id)和分片算法(t_order_$->{order_id % 2 + 1})
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 2 + 1}
四、水平分库
1,建表
创建数据库:order_db_1,order_db_2,在两个数据库均建立表:t_order_1,t_order_2


#创建数据库
CREATE DATABASE `order_db_1` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
#建表
USE order_db_1;
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` BIGINT (20) NOT NULL COMMENT '订单id',
`price` DECIMAL (10, 2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT (20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` BIGINT (20) NOT NULL COMMENT '订单id',
`price` DECIMAL (10, 2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT (20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; #创建数据库
CREATE DATABASE `order_db_2` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
#建表
USE order_db_2;
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` BIGINT (20) NOT NULL COMMENT '订单id',
`price` DECIMAL (10, 2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT (20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` BIGINT (20) NOT NULL COMMENT '订单id',
`price` DECIMAL (10, 2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT (20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2,maven配置
同上
3,properties配置
#数据源
spring.shardingsphere.datasource.names=m1,m2
#数据源m1 连接order_db_1数据库
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://hadoop102:3306/order_db_1?useUnicode=true
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
#数据源m2 连接order_db_2数据库
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://hadoop102:3306/order_db_2?useUnicode=true
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=123456 # 分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作m1数据源,否则操作m2。
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression = m$->{user_id % 2 + 1} # 指定t_order表的数据分布情况,配置数据节点 m1.t_order_1,m1.t_order_2,m2.t_order_1,m2.t_order_2
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=m$->{1..2}.t_order_$->{1..2}
# 指定t_order表的主键生成策略为SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
# 指定t_order表的分片策略,分片策略包括分片键(order_id)和分片算法(t_order_$->{order_id % 2 + 1})
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 2 + 1}
五、垂直分库
1,建表
建立垂直的业务表,用户信息表:
#创建数据库
CREATE DATABASE `user_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
#建表
USE user_db;
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`user_id` BIGINT (20) NOT NULL COMMENT '用户id',
`fullname` VARCHAR (255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用户姓名',
`user_type` CHAR (1) DEFAULT NULL COMMENT '用户类型',
PRIMARY KEY (`user_id`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2,配置properties
application.properties配置:这里将m0,m1和m2共存了,但是真正使用的是m0
#数据源
spring.shardingsphere.datasource.names=m0,m1,m2
#数据源m0 连接user_db数据库
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://hadoop102:3306/user_db?useUnicode=true
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123456
# t_user分表策略,固定分配至m0的t_user真实表 可将t_user也进行表操作
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes = m0.t_user
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression = t_user
六、公共表
1,建表
需要在所有使用到的数据库中都建表
#在数据库 user_db、order_db_1、order_db_2中均要建表
CREATE TABLE `t_dict` (
`dict_id` BIGINT (20) NOT NULL COMMENT '字典id',
`type` VARCHAR (50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典类型',
`code` VARCHAR (50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典编码',
`value` VARCHAR (50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典值',
PRIMARY KEY (`dict_id`) USING BTREE
) ENGINE = INNODB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2,配置properties
# 指定t_dict为公共表
spring.shardingsphere.sharding.broadcast‐tables=t_dict
七、读写分离
Sharding-JDBC读写分离是根据SQL语义的分析,将读操作和写操作分别路由至主库与从库。它提供透明化读写分离,让使用方尽量像使用一个数据库一样使用主从数据库集群。

1,配置mysql的主从
略
2,配置application
application.properties配置:这里将m0、s0;定义m0为主服务器,s0为从服务器。
#数据源 主从
spring.shardingsphere.datasource.names=m0,s0
#数据源m0 连接user_db数据库
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/user_db?useUnicode=true&characterEncoding=utf8&useSSL=false
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123456
#数据源m0 连接user_db数据库
spring.shardingsphere.datasource.s0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s0.url=jdbc:mysql://localhost:3307/user_db?useUnicode=true&characterEncoding=utf8&useSSL=false
spring.shardingsphere.datasource.s0.username=root
spring.shardingsphere.datasource.s0.password=123456
# 主库从库逻辑数据源定义 ds0为user_db
spring.shardingsphere.sharding.master‐slave‐rules.ds0.master-data-source-name=m0
spring.shardingsphere.sharding.master‐slave‐rules.ds0.slave-data-source-names=s0
# t_user分表策略 固定分配至ds0的t_user真实表
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=ds0.t_user
八、综合案例
源码:购物商品分库分表
1,数据库设计
数据库设计如下,其中商品与店铺信息之间进行了垂直分库,分为了PRODUCT_DB(商品库)和STORE_DB(店铺库);商品信息还进行了垂直分表,分为了商品基本信息(product_info)和商品描述信息(product_descript),地理区域信息(region)作为公共表,冗余在两库中:
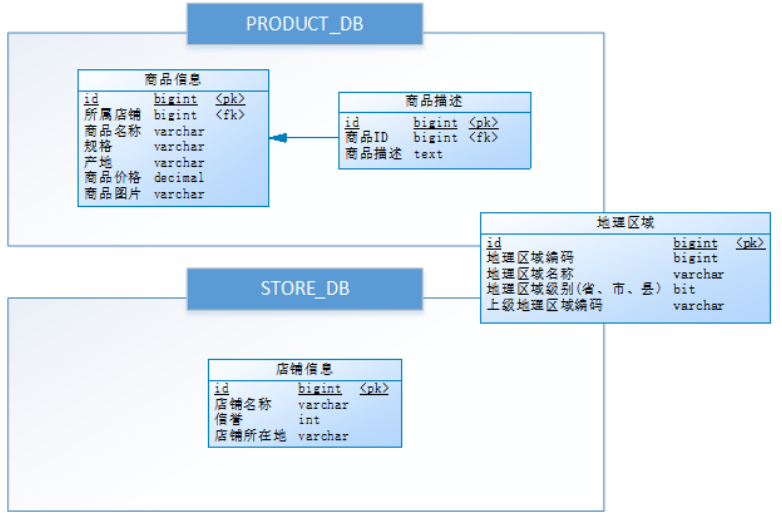
考虑到商品信息的数据增长性,对PRODUCT_DB(商品库)进行了水平分库,分片键使用店铺id,分片策略为店铺ID%2 + 1,因此商品描述信息对所属店铺ID进行了冗余;
对商品基本信息(product_info)和商品描述信息(product_descript)进行水平分表,分片键使用商品id,分片策略为商品ID%2 + 1,并将为这两个表设置为绑定表,避免笛卡尔积join;
为避免主键冲突,ID生成策略采用雪花算法来生成全局唯一ID,最终数据库设计为下图:
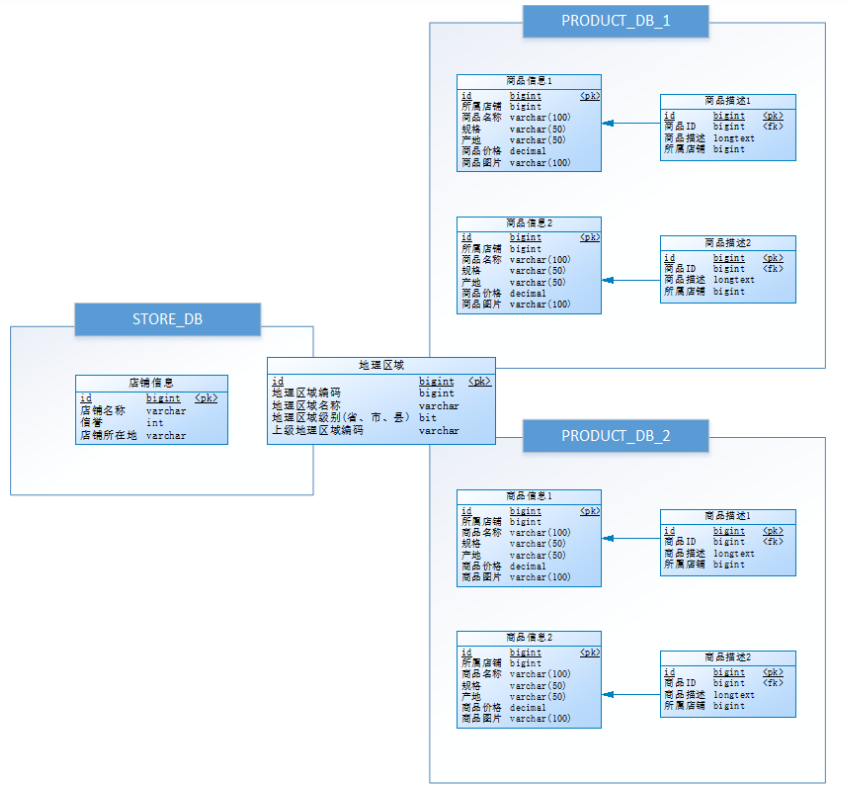
2,建表
CREATE DATABASE store_db;
USE store_db;
DROP TABLE IF EXISTS `region`;
CREATE TABLE `region` (
`id` bigint(20) NOT NULL COMMENT 'id',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '地理区域编码',
`region_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '地理区域名称',
`level` tinyint(1) NULL DEFAULT NULL COMMENT '地理区域级别(省、市、县)',
`parent_region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '上级地理区域编码',
PRIMARY KEY USING BTREE (`id`)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; INSERT INTO `region`
VALUES (1, '110000', '北京', 0, NULL); INSERT INTO `region`
VALUES (2, '410000', '河南省', 0, NULL); INSERT INTO `region`
VALUES (3, '110100', '北京市', 1, '110000'); INSERT INTO `region`
VALUES (4, '410100', '郑州市', 1, '410000'); DROP TABLE IF EXISTS `store_info`; CREATE TABLE `store_info` (
`id` bigint(20) NOT NULL COMMENT 'id',
`store_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '店铺名称',
`reputation` int(11) NULL DEFAULT NULL COMMENT '信誉等级',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '店铺所在地',
PRIMARY KEY USING BTREE (`id`)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; INSERT INTO `store_info`
VALUES (1, 'XX零食店', 4, '110100'); INSERT INTO `store_info`
VALUES (2, 'XX饮品店', 3, '410100');
创建product_db_1、product_db_2数据库(主从数据库均要执行),并分别执行以下脚本创建表
DROP TABLE IF EXISTS `product_descript_1`; CREATE TABLE `product_descript_1` (
`id` bigint(20) NOT NULL COMMENT 'id',
`product_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所属商品id',
`descript` longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL COMMENT '商品描述',
`store_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所属店铺id',
PRIMARY KEY USING BTREE (`id`),
INDEX `FK_Reference_2` USING BTREE(`product_info_id`)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; DROP TABLE IF EXISTS `product_descript_2`; CREATE TABLE `product_descript_2` (
`id` bigint(20) NOT NULL COMMENT 'id',
`product_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所属商品id',
`descript` longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL COMMENT '商品描述',
`store_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所属店铺id',
PRIMARY KEY USING BTREE (`id`),
INDEX `FK_Reference_2` USING BTREE(`product_info_id`)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; DROP TABLE IF EXISTS `product_info_1`; CREATE TABLE `product_info_1` (
`product_info_id` bigint(20) NOT NULL COMMENT 'id',
`store_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所属店铺id',
`product_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '商品名称',
`spec` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '规 格',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '产地',
`price` decimal(10, 0) NULL DEFAULT NULL COMMENT '商品价格',
`image_url` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '商品图片',
PRIMARY KEY USING BTREE (`product_info_id`),
INDEX `FK_Reference_1` USING BTREE(`store_info_id`)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; DROP TABLE IF EXISTS `product_info_2`; CREATE TABLE `product_info_2` (
`product_info_id` bigint(20) NOT NULL COMMENT 'id',
`store_info_id` bigint(20) NULL DEFAULT NULL COMMENT '所属店铺id',
`product_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '商品名称',
`spec` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '规 格',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '产地',
`price` decimal(10, 0) NULL DEFAULT NULL COMMENT '商品价格',
`image_url` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '商品图片',
PRIMARY KEY USING BTREE (`product_info_id`),
INDEX `FK_Reference_1` USING BTREE(`store_info_id`)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; DROP TABLE IF EXISTS `region`; CREATE TABLE `region` (
`id` bigint(20) NOT NULL COMMENT 'id',
`region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '地理区域编码',
`region_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '地理区域名称',
`level` tinyint(1) NULL DEFAULT NULL COMMENT '地理区域级别(省、市、县)',
`parent_region_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '上级地理区域编码',
PRIMARY KEY USING BTREE (`id`)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; INSERT INTO `region`
VALUES (1, '110000', '北京', 0, NULL); INSERT INTO `region`
VALUES (2, '410000', '河南省', 0, NULL); INSERT INTO `region`
VALUES (3, '110100', '北京市', 1, '110000'); INSERT INTO `region`
VALUES (4, '410100', '郑州市', 1, '410000');
3,配置主从同步
主库
# 设置需要同步的数据库
binlog_do_db=store_db
binlog_do_db=product_db_1
binlog_do_db=product_db_2
从库
#设置需要同步的数据库
replicate_wild_do_table=store_db.%
replicate_wild_do_table=product_db_1.%
replicate_wild_do_table=product_db_2.%
4,配置分片策略
application配置:分别配置db_store的主从、水平分库product_db_1和product_db_2的主从以及逻辑库(product_db)中的水平分表product_info_1和product_info_2等
#数据源
spring.shardingsphere.datasource.names = m0,m1,m2,s0,s1,s2 spring.shardingsphere.datasource.m0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m0.url = jdbc:mysql://localhost:3306/store_db?useUnicode=true
spring.shardingsphere.datasource.m0.username = root
spring.shardingsphere.datasource.m0.password = 123456 spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/product_db_1?useUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = 123456 spring.shardingsphere.datasource.m2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url = jdbc:mysql://localhost:3306/product_db_2?useUnicode=true
spring.shardingsphere.datasource.m2.username = root
spring.shardingsphere.datasource.m2.password = 123456 spring.shardingsphere.datasource.s0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s0.url = jdbc:mysql://localhost:3307/store_db?useUnicode=true
spring.shardingsphere.datasource.s0.username = root
spring.shardingsphere.datasource.s0.password = 123456 spring.shardingsphere.datasource.s1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s1.url = jdbc:mysql://localhost:3307/product_db_1?useUnicode=true
spring.shardingsphere.datasource.s1.username = root
spring.shardingsphere.datasource.s1.password = 123456 spring.shardingsphere.datasource.s2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s2.url = jdbc:mysql://localhost:3307/product_db_2?useUnicode=true
spring.shardingsphere.datasource.s2.username = root
spring.shardingsphere.datasource.s2.password = 123456 # 主库从库逻辑数据源定义 ds0为store_db
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=s0 # 主库从库逻辑数据源定义 ds1为product_db_1
spring.shardingsphere.sharding.master-slave-rules.ds1.master-data-source-name=m1
spring.shardingsphere.sharding.master-slave-rules.ds1.slave-data-source-names=s1 # 主库从库逻辑数据源定义 ds2为product_db_2
spring.shardingsphere.sharding.master-slave-rules.ds2.master-data-source-name=m2
spring.shardingsphere.sharding.master-slave-rules.ds2.slave-data-source-names=s2 #默认数据库分库策略,以store_info_id为分片键,定义分片键策略为store_info_id % 2 + 1,store_info_id为偶数操作ds1数据源,否则操作ds2。
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=store_info_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{store_info_id % 2 + 1} # 指定product_info表的数据分布情况,配置数据节点 ds1.product_info_1,ds1.product_info_2,ds2.product_info_1,ds2.product_info_2
spring.shardingsphere.sharding.tables.product_info.actual-data-nodes = ds$->{1..2}.product_info_$->{1..2}
# 指定product_info表的主键生成策略为SNOWFLAKE
spring.shardingsphere.sharding.tables.product_info.key-generator.column=product_info_id
spring.shardingsphere.sharding.tables.product_info.key-generator.type=SNOWFLAKE
# 分表策略,指定product_info表的分片策略,分片策略包括分片键和分片算法
spring.shardingsphere.sharding.tables.product_info.table-strategy.inline.sharding-column = product_info_id
spring.shardingsphere.sharding.tables.product_info.table-strategy.inline.algorithm-expression = product_info_$->{product_info_id % 2 + 1} # 指定store_info表的数据分布情况,配置数据节点 ds0.store_info
spring.shardingsphere.sharding.tables.store_info.actual-data-nodes = ds$->{0}.store_info
spring.shardingsphere.sharding.tables.store_info.table-strategy.inline.sharding-column = id
spring.shardingsphere.sharding.tables.store_info.table-strategy.inline.algorithm-expression = store_info # 指定product_descript表的数据分布情况,配置数据节点 ds1.product_descript_1,ds1.product_descript_2,ds2.product_descript_1,ds2.product_descript_2
spring.shardingsphere.sharding.tables.product_descript.actual-data-nodes = ds$->{1..2}.product_descript_$->{1..2}
# 指定product_descript表的主键生成策略为SNOWFLAKE
spring.shardingsphere.sharding.tables.product_descript.key-generator.column=id
spring.shardingsphere.sharding.tables.product_descript.key-generator.type=SNOWFLAKE
# 分表策略,指定product_descript表的分片策略,分片策略包括分片键和分片算法
spring.shardingsphere.sharding.tables.product_descript.table-strategy.inline.sharding-column = product_info_id
spring.shardingsphere.sharding.tables.product_descript.table-strategy.inline.algorithm-expression = product_descript_$->{product_info_id % 2 + 1} #绑定表product_descript与product_info 避免出现笛卡尔积
spring.shardingsphere.sharding.binding-tables[0]=product_info,product_descript #设置region为广播表(公共表)
spring.shardingsphere.sharding.broadcast-tables=region
5,分库分表后的操作
a)查询商品列表
分页查询是业务中最常见的场景,Sharding-jdbc支持常用关系数据库的分页查询,不过Sharding-jdbc的分页功能比较容易让使用者误解,用户通常认为分页归并会占用大量内存。 在分布式的场景中,将 LIMIT 10000000 , 10改写为 LIMIT 0, 10000010 ,才能保证其数据的正确性。 用户非常容易产生ShardingSphere会将大量无意义的数据加载至内存中,造成内存溢出风险的错觉。 其实大部分情况都通过流式归并获取数据结果集,因此ShardingSphere会通过结果集的next方法将无需取出的数据全部跳过,并不会将其存入内存。
但同时需要注意的是,由于排序的需要,大量的数据仍然需要传输到Sharding-Jdbc的内存空间。 因此,采用LIMIT这种方式分页,并非最佳实践。 由于LIMIT并不能通过索引查询数据,因此如果可以保证ID的连续性,通过ID进行分页是比较好的解决方案,例如:
SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id;
#或者是
SELECT * FROM t_order WHERE id > 10000000 LIMIT 10;
b)分组统计
举例说明,假设根据科目分片,表结构中包含考生的姓名(为了简单起见,不考虑重名的情况)和分数。通过SQL获取每位考生的总分,可通过如下SQL:
SELECT name, SUM(score) FROM t_score GROUP BY name ORDER BY name;
采用Sharding-JDBC解决分库分表的更多相关文章
- Sharding Sphere的分库分表
什么是 ShardingSphere? 1.一套开源的分布式数据库中间件解决方案 2.有三个产品:Sharding-JDBC 和 Sharding-Proxy 3.定位为关系型数据库中间件,合理在分布 ...
- 【MySQL】如何解决分库分表遇到的自增主键的问题?
雪花算法 Redis生成主键
- Mysql系列四:数据库分库分表基础理论
一.数据处理分类 1. 海量数据处理,按照使用场景主要分为两种类型: 联机事务处理(OLTP) 面向交易的处理系统,其基本特征是原始数据可以立即传送到计算机中心进行处理,并在很短的时间内给出处理结果. ...
- 分库分表后跨分片查询与Elastic Search
携程酒店订单Elastic Search实战:http://www.lvesu.com/blog/main/cms-610.html 为什么分库分表后不建议跨分片查询:https://www.jian ...
- 【大数据和云计算技术社区】分库分表技术演进&最佳实践笔记
1.需求背景 移动互联网时代,海量的用户每天产生海量的数量,这些海量数据远不是一张表能Hold住的.比如 用户表:支付宝8亿,微信10亿.CITIC对公140万,对私8700万. 订单表:美团每天几千 ...
- 分库分表中间件sharding-jdbc的使用
数据分片产生的背景,可以查看https://shardingsphere.apache.org/document/current/cn/features/sharding/,包括了垂直拆分和水平拆分的 ...
- 带你剖析淘宝TDDL——Matrix层的分库分表配置与实现
前言 在开始讲解淘宝的TDDL(Taobao Distribute Data Layer)技术之前,请允许笔者先吐槽一番.首先要开喷的是淘宝的社区支持做的无比的烂,TaoCode开源社区上面,几乎从来 ...
- 分库分表技术演进&最佳实践
每个优秀的程序员和架构师都应该掌握分库分表,这是我的观点. 移动互联网时代,海量的用户每天产生海量的数量,比如: 用户表 订单表 交易流水表 以支付宝用户为例,8亿:微信用户更是10亿.订单表更夸张, ...
- java 取模运算% 实则取余 简述 例子 应用在数据库分库分表
java 取模运算% 实则取余 简述 例子 应用在数据库分库分表 取模运算 求模运算与求余运算不同.“模”是“Mod”的音译,模运算多应用于程序编写中. Mod的含义为求余.模运算在数论和程序设计中 ...
随机推荐
- 一步步分析:C语言如何面向对象编程
这是道哥的第009篇原创 一.前言 在嵌入式开发中,C/C++语言是使用最普及的,在C++11版本之前,它们的语法是比较相似的,只不过C++提供了面向对象的编程方式. 虽然C++语言是从C语言发展而来 ...
- 教你用Python自制拼图小游戏,一起来制作吧
摘要: 本文主要为大家详细介绍了python实现拼图小游戏,文中还有示例代码介绍,感兴趣的小伙伴们可以参考一下. 开发工具 Python版本:3.6.4 相关模块: pygame模块: 以及一些Pyt ...
- Python求一个数字列表的元素总和
Python求一个数字列表的元素总和.练手: 第一种方法,直接sum(list): 1 lst = list(range(1,11)) #创建一个1-10的数字列表 2 total = 0 #初始化总 ...
- C# 高并发、抢单解决思路
高并发 高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求.高并发相关常用的一些指标有响应时间(Respon ...
- 【磁盘/文件系统】第三篇:标准磁盘分区流程针对parted(一般硬盘容量大于2T(但是小于2T也可以进行分区);分区数最大是支持100多个分区)
说明: 在 Linux 上可以采用 parted 来对磁盘进行分区 1.通过 fdisk -l 可以查看磁盘是否存在, 由于使用的是大磁盘(大于2T),fdisk 不能用来作为分区工具了,而应该使用 ...
- A child container failed during start
先贴一下bug详情 严重: A child container failed during start java.util.concurrent.ExecutionException: org.apa ...
- PIX
[开启]后,如图: [新建]:如图中设定: Program: 你要准备监测的应用程序路径 [点击]:Start Experiment 如图,会出现一个新窗口(你运行的应用程序窗口) [点击F12](确 ...
- mysql中order by优化的那些事儿
为了测试方便和直观,我们需要先创建一张测试表并插入一些数据: CREATE TABLE `shop` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '记 ...
- django-mdeditor支持七牛云存储图片
由于django-mdeditor官方插件没有支持第三方存储,所以,我们只能进行修改源码的方式实现了. 本次改写即使替换了其文件,不使用七牛云也是无关紧要的,因为在存储时,去settings.py中判 ...
- msf ms17-010利用笔记
nmap -sV -Pn xxxxx 扫描端口and系统信息 use auxiliary/scanner/smb/smb_ms17_010 扫描模块 set Rhosts 扫描目标 use ex ...