Kafka分区分配策略(Partition Assignment Strategy)
众所周知,Apache Kafka是基于生产者和消费者模型作为开源的分布式发布订阅消息系统(当然,目前Kafka定位于an open-source distributed event streaming platform),由Scala和Java编写。
Kafka提供了类似于JMS的特性,但设计上又有很大区别,它不是JMS规范的实现,如Kafka允许多个消费者主动拉取数据,而在JMS中只有点对点模式消费者才会主动拉取数据。
Kafka producer在向Kafka集群发送消息时,需要指定topic,Kafka根据topic对消息进行归类(逻辑划分),而一个topic通常会有多个partition分区,落到磁盘上就是多个partition目录。
Kafka consumer为了及时消费消息,会以Consumer Group(消费组)的形式,启动多个consumer消费消息。不同的消费组在消费消息时彼此互不影响,同一个消费组的consumer协调在一起消费订阅的topic所有分区消息。这就引申一个问题:消费组中的consumer是如何确定自己该消费哪些分区的数据的?
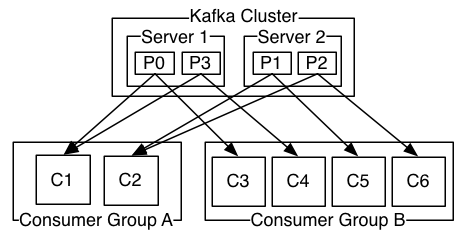
Kafka提供了多种分区策略如RoundRobin(轮询)、Range(按范围),可通过参数partition.assignment.strategy进行配置。
一般情况下,在topic和消费组不发生变化,Kafka会根据topic分区、消费组情况等确定分区策略,但是当发生以下情况时,会触发Kafka的分区重分配:
1. Consumer Group中的consumer发生了新增或者减少
同一个Consumer Group新增consumer
- Consumer Group订阅的topic分区发生变化如新增分区
2. Consumer Group订阅的topic分区发生变化如新增分区
本文通过下面的场景,来分别阐述Kafka主要的分配策略RoundRobin和Range:
Range Strategy
Range策略是针对topic而言的,在进行分区分配时,为了尽可能保证所有consumer均匀的消费分区,会对同一个topic中的partition按照序号排序,并对consumer按照字典顺序排序。
然后为每个consumer划分固定的分区范围,如果不够平均分配,那么排序靠前的消费者会被多分配分区。具体就是将partition的个数除于consumer线程数来决定每个consumer线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多分配分区。
通过下面公式更直观:
假设n = 分区数 / 消费者数量,m = 分区数 % 消费者线程数量,那么前m个消费者每个分配n+1个分区,后面的(消费者线程数量 - m)个消费者每个分配n个分区。
举个例子:
一个消费组CG1中有C0和C1两个consumer,消费Kafka中的主题t1。t1的分区数为10,并且C1的num.streams为1,C2的num.streams为2。
经过排序后,分区为:0, 1, 2, 3, 4, 5, 6, 7, 8, 9;CG1中消费者线程为C0-0、C1-0、C1-1。然后因为 10除3除不尽,那么消费者线程C0-0将会多分配分区,所以分区分配之后结果如下:
C0-0 将消费0、1、2、3分区
C1-0 将消费4、5、6分区
C1-1 将消费7、8、9分区
当存在有2个Kafka topic(t1和t2),它们都有有10个partition,那么最后分区结果为:
C0-0 将消费t1主题的0、1、2、3分区以及t2主题的0、1、2、3分区
C1-0 将消费t1主题的4、5、6分区以及t2主题的4、5、6分区
C2-1 将消费t1主题的7、8、9分区以及t2主题的7、8、9分区
如上场景,随着topic的增多,那么针对每个topic,消费者C0-0都将多消费1个分区,topic越多比如为N个,C0-0消费的分区会比其他消费者明显多消费N个分区。
可以明显的看到这样的分配并不均匀,如果将类似的情形扩大,有可能会出现部分消费者过载的情况,这就是Range分区策略的一个很明显的弊端。
RoundRobin Strategy
RoundRobin策略的工作原理:将所有topic的partition组成TopicAndPartition列表,然后对TopicAndPartition列表按照hashCode进行排序:
val allTopicPartitions = ctx.partitionsForTopic.flatMap { case(topic, partitions) =>
info("Consumer %s rebalancing the following partitions for topic %s: %s"
.format(ctx.consumerId, topic, partitions))
partitions.map(partition => {
TopicAndPartition(topic, partition)
})
}.toSeq.sortWith((topicPartition1, topicPartition2) => {
/*
* Randomize the order by taking the hashcode to reduce the likelihood of all partitions of a given topic ending
* up on one consumer (if it has a high enough stream count).
*/
topicPartition1.toString.hashCode < topicPartition2.toString.hashCode
})
最后按照RoundRobin风格将分区分别分配给不同的消费者。
使用RoundRobin策略必须满足以下条件:
1. 同一个Consumer Group里面的所有consumer的num.streams必须相等
2.每个consumer订阅的topic必须相同
假设消费组CG1中有C0和C1两个consumer的num.streams都为2。按照hashCode排序完的topic-partition组依次为t1-5, t1-3, t1-0, t1-8, t1-2, t1-1, t1-4, t1-7, t1-6, t1-9,我们的消费者排序为C0-0, C0-1, C1-0, C1-1,最后分区分配的结果为:
C0-0将消费t1-5、t1-2、t1-6分区
C0-1将消费t1-3、t1-1、t1-9分区
C1-0将消费t1-0、t1-4分区
C1-1将消费t1-8、t1-7分区
多个主题的分区分配和单个主题类似,这里就不在介绍了。
上面RoundRobin要求每个consumer订阅的topic必须相同,当订阅的topic不同时,那么在执行分区分配的时候就不是完全的轮询分配,有可能会导致分区分配的不均匀。比如,某个consumer没有订阅消费组内的某个topic,那么在分配分区的时候,这个consumer将分配不到这个topic的分区。
除了上述的介绍的RoundRobin和Range分配策略,Kafka还有Sticky分配策略,它主要有两个目的:
分区的分配要尽可能的均匀
分区的分配尽可能的与上次分配的保持相同
当两者发生冲突时,第一个目标优先于第二个目标。鉴于这两个目标,StickyAssignor策略的具体实现要比RangeAssignor和RoundRobinAssignor这两种分配策略要复杂很多。
推荐文章:
Kafka中sequence IO、PageCache、SendFile的应用详解
SparkStreaming和Kafka基于Direct Approach如何管理offset
关注微信公众号:大数据学习与分享,获取更对技术干货
Kafka分区分配策略(Partition Assignment Strategy)的更多相关文章
- Kafka分区分配策略(Partition Assignment Strategy
问题 用过 Kafka 的同学用过都知道,每个 Topic 一般会有很多个 partitions.为了使得我们能够及时消费消息,我们也可能会启动多个 Consumer 去消费,而每个 Consumer ...
- Kafka分区分配策略分析——重点:StickyAssignor
“ 为什么Kafka在RangeAssigor.RoundRobinAssignor的基础上,又新增了PartitionAssignor,它解决了什么问题?” 背景 用过Kafka的同学应该都知道Ka ...
- Kafka分区分配策略-RangeAssignor、RoundRobinAssignor、StickyAssignor
引言按照Kafka默认的消费逻辑设定,一个分区只能被同一个消费组(ConsumerGroup)内的一个消费者消费.假设目前某消费组内只有一个消费者C0,订阅了一个topic,这个topic包含7个分区 ...
- Kafka消费分组和分区分配策略
Kafka消费分组,消息消费原理 同一个消费组里的消费者不能消费同一个分区,不同消费组的消费组可以消费同一个分区 Kafka分区分配策略 在 Kafka 内部存在两种默认的分区分配策略:Range 和 ...
- kafka的分区分配策略
用过 Kafka 的同学应该都知道,每个 Topic 一般会有很多个 partitions.为了使得我们能够及时消费消息,我们也可能会启动多个 Consumer 去消费,而每个 Consumer 又会 ...
- Kafka 消费组消费者分配策略
body { margin: 0 auto; font: 13px / 1 Helvetica, Arial, sans-serif; color: rgba(68, 68, 68, 1); padd ...
- Kafka分区与消费者的关系
1. 前言 我们知道,生产者发送消息到主题,消费者订阅主题(以消费者组的名义订阅),而主题下是分区,消息是存储在分区中的,所以事实上生产者发送消息到分区,消费者则从分区读取消息,那么,这里问题来了, ...
- 深入了解Kafka【五】Partition和消费者的关系
1.消费者与Partition 以下来自<kafak权威指南>第4章. 假设主题T1有四个分区. 1.1.一个消费者组 1.1.1.消费者数量小于分区数量 只有一个消费者时,消费者1将收到 ...
- kafka分区及副本在broker的分配
kafka分区及副本在broker的分配 部分内容參考自:http://blog.csdn.net/lizhitao/article/details/41778193 以下以一个Kafka集群中4个B ...
随机推荐
- SSH,公钥,私钥的理解
参考大佬的文章:https://blog.csdn.net/li528405176/article/details/82810342 https://www.cnblogs.com/Bravew ...
- gcc编译阶段打印宏定义的内容
背景 总所周知,代码量稍微大一点的C/C++项目的一些宏定义都会比较复杂,有时候会嵌套多个#if/#else判断分支和一堆#ifdef/#undef让你单看代码的话很难判断出宏定义的具体内容. 如果有 ...
- 附029.Kubernetes安全之网络策略
目录 环境构建 基础环境构建 网络测试 安全策略 策略配置 策略测试 ingress方向测试 egress方向测试 to和from行为 默认策略 环境构建 基础环境构建 [root@master01 ...
- Python学习之多项式回归
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 线性回归的改进版本中的多项式回归.如果您知道线性回归,那么对您来说很简单.如果没有,我将在本文中解释 ...
- Latex向上\向下取整语法 及卷积特征图高宽计算公式编辑
向下\向上取整 在编辑卷积网络输出特征高宽公式时,需用到向下取整,Mark一下. 向下取整 \(\lfloor x \rfloor\) $\lfloor x \rfloor$ 向上取整 \(\lcei ...
- x264编码demo定制修改介绍
x264编码器,提供了两个demo来验证编码功能:一个是大而全的x264.c,另外一个是简洁版的example.c. 其中,前者demo,可以配置很多编码参数,但太冗长繁杂,对初学者不太友好. 后者 ...
- Tomcat启动web项目静态页面中文乱码问题解决
1 首先查看静态页面在编辑器中是否正常, 如果是eclipse ,需要设置一下项目编码格式为utf-8, 如果是idea , 一般会自动识别, 也可以自己手动检查一下, 检查html上面是否有 ...
- C#自定义TemplateImage使用模板底图,运行时根据用户或产品信息生成海报图(1)
由于经常需要基于固定的一个模板底图,生成微信小程序分享用的海报图,如果每次都调用绘图函数,手动编写每个placeholder的填充,重复而且容易出错,因此,封装一个TemplateImage,用于填充 ...
- java 去掉html标签 使用正则表达式删除HTML标签。
import java.util.regex.Matcher; import java.util.regex.Pattern; public class HTMLSpirit{ public stat ...
- JavaDailyReports10_19
今日学习超链接 1.文本链接 使用一对<a>标签 格式:< href ="目标URL" target="目标窗口"> 指针文本 & ...