MySQL全面瓦解21(番外):一次深夜优化亿级数据分页的奇妙经历
背景
1月22号晚上10点半,下班后愉快的坐在在回家的地铁上,心里想着周末的生活怎么安排。
突然电话响了起来,一看是我们的一个开发同学,顿时紧张了起来,本周的版本已经发布过了,这时候打电话一般来说是线上出问题了。
果然,沟通的情况是线上的一个查询用户数据的接口被疯狂的失去理智般的调用,这个操作直接导致线上的MySql集群被拖慢了。
好吧,这问题算是严重了,下了地铁匆匆赶到家,开电脑,跟同事把Pinpoint上的慢查询日志捞出来。看到一个很奇怪的查询,如下
1 POST domain/v1.0/module/method?order=condition&orderType=desc&offset=1800000&limit=500
domain、module 和 method 都是化名,代表接口的域、模块和实例方法名,后面的offset和limit代表分页操作的偏移量和每页的数量,也就是说该同学是在 翻第(1800000/500+1=3601)页。初步捞了一下日志,发现 有8000多次这样调用。
这太神奇了,而且我们页面上的分页单页数量也不是500,而是 25条每页,这个绝对不是人为的在功能页面上进行一页一页的翻页操作,而是数据被刷了(说明下,我们生产环境用户数据有1亿+)。 详细对比日志发现,很多分页的时间是重叠的,对方应该是多线程调用。
通过对鉴权的Token的分析,基本定位了请求是来自一个叫做ApiAutotest的客户端程序在做这个操作,也定位了生成鉴权Token的账号来自一个QA的同学。立马打电话给同学,进行了沟通和处理。
分析
其实对于我们的MySQL查询语句来说,整体效率还是可以的,该有的联表查询优化都有,该简略的查询内容也有,关键条件字段和排序字段该有的索引也都在,问题在于他一页一页的分页去查询,查到越后面的页数,扫描到的数据越多,也就越慢。
我们在查看前几页的时候,发现速度非常快,比如 limit 200,25,瞬间就出来了。但是越往后,速度就越慢,特别是百万条之后,卡到不行,那这个是什么原理呢。先看一下我们翻页翻到后面时,查询的sql是怎样的:
1 select * from t_name where c_name1='xxx' order by c_name2 limit 2000000,25;
这种查询的慢,其实是因为limit后面的偏移量太大导致的。比如像上面的 limit 2000000,25 ,这个等同于数据库要扫描出 2000025条数据,然后再丢弃前面的 20000000条数据,返回剩下25条数据给用户,这种取法明显不合理。
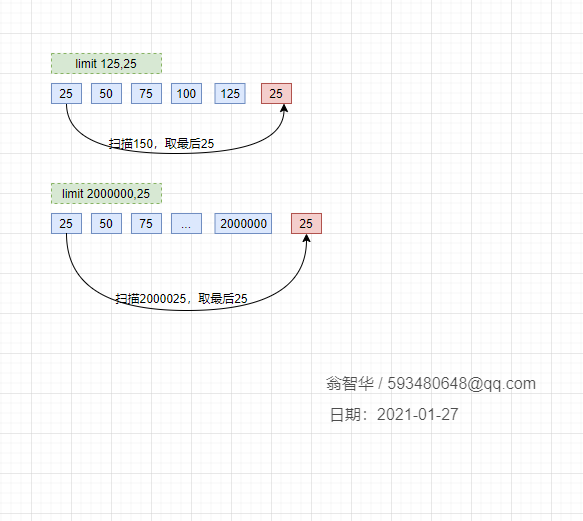
大家翻看《高性能MySQL》第六章:查询性能优化,对这个问题有过说明:
数据模拟
那好,了解了问题的原理,那就要试着解决它了。涉及数据敏感性,我们这边模拟一下这种情况,构造一些数据来做测试。
1、创建两个表:员工表和部门表
1 /*部门表,存在则进行删除 */
2 drop table if EXISTS dep;
3 create table dep(
4 id int unsigned primary key auto_increment,
5 depno mediumint unsigned not null default 0,
6 depname varchar(20) not null default "",
7 memo varchar(200) not null default ""
8 );
9
10 /*员工表,存在则进行删除*/
11 drop table if EXISTS emp;
12 create table emp(
13 id int unsigned primary key auto_increment,
14 empno mediumint unsigned not null default 0,
15 empname varchar(20) not null default "",
16 job varchar(9) not null default "",
17 mgr mediumint unsigned not null default 0,
18 hiredate datetime not null,
19 sal decimal(7,2) not null,
20 comn decimal(7,2) not null,
21 depno mediumint unsigned not null default 0
22 );
2、创建两个函数:生成随机字符串和随机编号
1 /* 产生随机字符串的函数*/
2 DELIMITER $
3 drop FUNCTION if EXISTS rand_string;
4 CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
5 BEGIN
6 DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmlopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
7 DECLARE return_str VARCHAR(255) DEFAULT '';
8 DECLARE i INT DEFAULT 0;
9 WHILE i < n DO
10 SET return_str = CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
11 SET i = i+1;
12 END WHILE;
13 RETURN return_str;
14 END $
15 DELIMITER;
16
17
18 /*产生随机部门编号的函数*/
19 DELIMITER $
20 drop FUNCTION if EXISTS rand_num;
21 CREATE FUNCTION rand_num() RETURNS INT(5)
22 BEGIN
23 DECLARE i INT DEFAULT 0;
24 SET i = FLOOR(100+RAND()*10);
25 RETURN i;
26 END $
27 DELIMITER;
3、编写存储过程,模拟500W的员工数据
1 /*建立存储过程:往emp表中插入数据*/
2 DELIMITER $
3 drop PROCEDURE if EXISTS insert_emp;
4 CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10))
5 BEGIN
6 DECLARE i INT DEFAULT 0;
7 /*set autocommit =0 把autocommit设置成0,把默认提交关闭*/
8 SET autocommit = 0;
9 REPEAT
10 SET i = i + 1;
11 INSERT INTO emp(empno,empname,job,mgr,hiredate,sal,comn,depno) VALUES ((START+i),rand_string(6),'SALEMAN',0001,now(),2000,400,rand_num());
12 UNTIL i = max_num
13 END REPEAT;
14 COMMIT;
15 END $
16 DELIMITER;
17 /*插入500W条数据*/
18 call insert_emp(0,5000000);
4、编写存储过程,模拟120的部门数据
1 /*建立存储过程:往dep表中插入数据*/
2 DELIMITER $
3 drop PROCEDURE if EXISTS insert_dept;
4 CREATE PROCEDURE insert_dept(IN START INT(10),IN max_num INT(10))
5 BEGIN
6 DECLARE i INT DEFAULT 0;
7 SET autocommit = 0;
8 REPEAT
9 SET i = i+1;
10 INSERT INTO dep( depno,depname,memo) VALUES((START+i),rand_string(10),rand_string(8));
11 UNTIL i = max_num
12 END REPEAT;
13 COMMIT;
14 END $
15 DELIMITER;
16 /*插入120条数据*/
17 call insert_dept(1,120);
5、建立关键字段的索引,这边是跑完数据之后再建索引,会导致建索引耗时长,但是跑数据就会快一些。
1 /*建立关键字段的索引:排序、条件*/
2 CREATE INDEX idx_emp_id ON emp(id);
3 CREATE INDEX idx_emp_depno ON emp(depno);
4 CREATE INDEX idx_dep_depno ON dep(depno);
测试
1 /*偏移量为100,取25*/
2 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
3 from emp a left join dep b on a.depno = b.depno order by a.id desc limit 100,25;
4 /*偏移量为4800000,取25*/
5 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
6 from emp a left join dep b on a.depno = b.depno order by a.id desc limit 4800000,25;
1 [SQL]
2 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
3 from emp a left join dep b on a.depno = b.depno order by a.id desc limit 100,25;
4 受影响的行: 0
5 时间: 0.001s
6 [SQL]
7 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
8 from emp a left join dep b on a.depno = b.depno order by a.id desc limit 4800000,25;
9 受影响的行: 0
10 时间: 12.275s
解决方案
1、使用索引覆盖+子查询优化
1 /*子查询获取偏移100条的位置的id,在这个位置上往后取25*/
2 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
3 from emp a left join dep b on a.depno = b.depno
4 where a.id >= (select id from emp order by id limit 100,1)
5 order by a.id limit 25;
6
7 /*子查询获取偏移4800000条的位置的id,在这个位置上往后取25*/
8 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
9 from emp a left join dep b on a.depno = b.depno
10 where a.id >= (select id from emp order by id limit 4800000,1)
11 order by a.id limit 25;
执行结果
1 [SQL]
2 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
3 from emp a left join dep b on a.depno = b.depno
4 where a.id >= (select id from emp order by id limit 100,1)
5 order by a.id limit 25;
6 受影响的行: 0
7 时间: 0.106s
8
9 [SQL]
10 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
11 from emp a left join dep b on a.depno = b.depno
12 where a.id >= (select id from emp order by id limit 4800000,1)
13 order by a.id limit 25;
14 受影响的行: 0
15 时间: 1.541s
2、起始位置重定义
1 /*记住了上次的分页的最后一条数据的id是100,这边就直接跳过100,从101开始扫描表*/
2 SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
3 from emp a left join dep b on a.depno = b.depno
4 where a.id > 100 order by a.id limit 25;
5
6 /*记住了上次的分页的最后一条数据的id是4800000,这边就直接跳过4800000,从4800001开始扫描表*/
7 SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
8 from emp a left join dep b on a.depno = b.depno
9 where a.id > 4800000
10 order by a.id limit 25;
执行结果
1 [SQL]
2 SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
3 from emp a left join dep b on a.depno = b.depno
4 where a.id > 100 order by a.id limit 25;
5 受影响的行: 0
6 时间: 0.001s
7
8 [SQL]
9 SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
10 from emp a left join dep b on a.depno = b.depno
11 where a.id > 4800000
12 order by a.id limit 25;
13 受影响的行: 0
14 时间: 0.000s
3、降级策略
小结:
MySQL全面瓦解21(番外):一次深夜优化亿级数据分页的奇妙经历的更多相关文章
- 正式学习 React(三)番外篇 reactjs性能优化之shouldComponentUpdate
性能优化 每当开发者选择将React用在真实项目中时都会先问一个问题:使用react是否会让项目速度更快,更灵活,更容易维护.此外每次状态数据发生改变时都会进行重新渲染界面的处理做法会不会造成性能瓶颈 ...
- MySQL全面瓦解23:MySQL索引实现和使用
MySQL索引实现 上一篇我们详细了解了B+树的实现原理(传送门).我们知道,MySQL内部索引是由不同的引擎实现的,主要包含InnoDB和MyISAM这两种,并且这两种引擎中的索引都是使用b+树的结 ...
- MySQL全面瓦解24:构建高性能索引(策略篇)
学习如果构建高性能的索引之前,我们先来了解下之前的知识,以下两篇是基础原理,了解之后,对面后续索引构建的原则和优化方法会有更清晰的理解: MySQL全面瓦解22:索引的介绍和原理分析 MySQL全面瓦 ...
- 给深度学习入门者的Python快速教程 - 番外篇之Python-OpenCV
这次博客园的排版彻底残了..高清版请移步: https://zhuanlan.zhihu.com/p/24425116 本篇是前面两篇教程: 给深度学习入门者的Python快速教程 - 基础篇 给深度 ...
- Java微信公众平台开发--番外篇,对GlobalConstants文件的补充
转自:http://www.cuiyongzhi.com/post/63.html 之前发过一个[微信开发]系列性的文章,也引来了不少朋友观看和点评交流,可能我在写文章时有所疏忽,对部分文件给出的不是 ...
- 番外:你真的了解 Oracle 的启动流程吗?
番外系列说明:该系列所有文章都将作为独立篇章进行知识点讲解,是对其他系列博文进行的补充说明,来自于博客园AskScuti. 主题:关于数据库启动流程的三个阶段 内容预览:本篇涉及数据库启动的三个阶段分 ...
- 番外:Oracle 中关于 Control File 的备份说明
番外系列说明:该系列所有文章都将作为独立篇章进行知识点讲解,是对其他系列博文进行的补充说明,来自于博客园AskScuti. 主题:关于 Control File 控制文件备份的说明 内容预览:本篇涉及 ...
- 番外篇!全球首个微信应用号开发教程!小程序 DEMO 视频奉上!
大家好,我是博卡君.经过国庆节的七天假期,相信很多朋友都已经研究出自己的小程序 demo 了吧?我最近也利用休息时间关注了一下网上关于小程序开发的讨论,今天就利用这个番外篇谈谈自己对小程序的一些想法吧 ...
- MySQL全面瓦解13:系统函数相关
概述 提到MySQL的系统函数,我们前面有使用过聚合函数,其实只是其中一小部分.MySQL提供很多功能强大.方便易用的函数,使用这些函数,可以极大地提高用户对于数据库的管理效率,并更加灵活地满足不同用 ...
随机推荐
- grafana 的主体架构是如何设计的?
grafana 的主体架构是如何设计的? grafana 是非常强大的可视化项目,它最早从 kibana 生成出来,渐渐也已经形成了自己的生态了.研究完 grafana 生态之后,只有一句话:可视化 ...
- 利用基于Go Lang的Hugo配合nginx来打造属于自己的纯静态博客系统
Go lang无疑是目前的当红炸子鸡,极大地提高了后端编程的效率,同时有着极高的性能.借助Go语言我们 可以用同步的方式写出高并发的服务端软件,同时,Go语言也是云原生第一语言,Docker,Kube ...
- 5分钟看懂系列:Python 线程池原理及实现
概述 传统多线程方案会使用"即时创建, 即时销毁"的策略.尽管与创建进程相比,创建线程的时间已经大大的缩短,但是如果提交给线程的任务是执行时间较短,而且执行次数极其频繁,那么服务器 ...
- Xrdp远程连接到CentOS7系统配置
1 服务器端配置 1.1 查询是否已经安装epel库 打开已经安装了CentOS7的主机,以root用户登录,在桌面上打开一个终端,输入命令:rpm -qa|grep epel,查询 ...
- python初学者-计算1-99奇数的和
s = 0 for i in range(1,100,2): s = s + i print(s)
- 记 CentOS 服务器上安装 neo4j 图数据库及本地访问
下载 去官网下载压缩包放到服务器上.地址为neo4j 下载中心,我这里选择的是 Neo4j 3.5.25 (tar).具体如何做呢?我这里使用的是土方法,即先压缩包下载到本地电脑(win 10系统), ...
- HTML颜色
- spark集群运行模式
spark的集中运行模式 Local .Standalone.Yarn 关闭防火墙:systemctl stop firewalld.service 重启网络服务:systemctl restart ...
- java数组之binarySearch查找
/** * 1.如果找到目标对象则返回<code>[公式:-插入点-1]</code> * 插入点:第一个大与查找对象的元素在数组中的位置,如果数组中的所有元素都小于要查找的对 ...
- Python基础(中篇)
本篇文章主要内容:数据类型的常用方法,条件语句,循环语句. 在开始正篇之前我们先来看看上一篇留下的题目. 题目: 定义一个字典a,有两个键值对:一个键值对key是可乐,value是18:另一个键值对k ...