网页排名算法PagaRank
网页排名算法PageRank
PageRank,网页排名,又叫做网页级别。是一种利用网页之间的超链接数据进行计算的方法。它是由Google的两位创始人提出的。
对于用户而言,网页排名一般是比较主观的,但也存在一些方法可以给出较为客观的排名,PageRank就是其中一种。它衡量的是网页之间的相对重要性,把每一个网页当成一个图结点,网页之间的超链接当成是结点之间的边,根据结点之间的链接关系来进行计算的,核心思想是一个网页被链接的次数越多,那么它就越受关注。
1.简单PR模型
假设有这样几个网页的图,他们的连接关系如下:
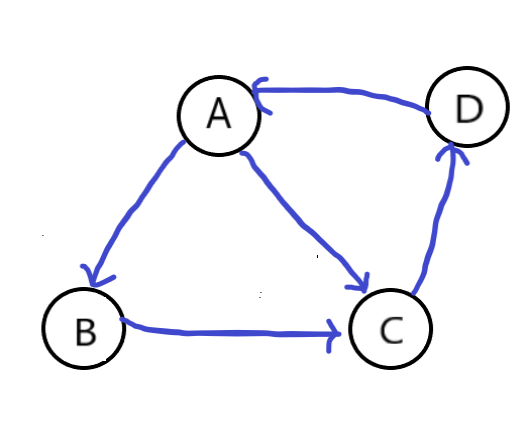
我们这样来看,这里有四个网页,分别是A,B,C,D,他们之间的连接用边表示。所以,A有两个外链接,出度为2,分别指向B和C,B有一个外链接,指向C。反过来,C就有两个入链,也就是入度为2。
因此,一个网页的影响力 = 所有入链集合的中页面的影响力的加权和,计算公式为:
\]
其中,u是当前要计算影响力的页面,\(IN_{u}\)是u的入链集合,\(N(v)\)是页面v的出链总数。把它当成是一个投票的过程,规定每个页面可以且仅可以投一票,它投的票的影响力大小就是它自身的影响力大小,由于只能投一票,所以它如果投给了多个网页,那么被投的网页只能把它的票撕开,平分。然后,大家互相投票,每投完一轮票之后,统计大家的得到的票数,就能够得到每个网页的新的影响力大小。
实际上,每个网页投给给其他网页的票数相当于一个跳转概率,以A为例,它投票给了B和C,所以用户在访问A时,跳转到B和C的概率都为1/2。
我们把每个网页对其他网页的投票写成一个列向量的形式,如对A
\]
四个列向量组合起来,就变成了一个转移矩阵:
\]
有了这个转移矩阵,我们在给定一个初始的影响力向量,就可以通过迭代的方式,不断计算计算新的影响力,直到收敛为止。
初始化每个页面的影响力都相同,为
\]
一次计算后得到:
\]
经过n(有限)次迭代后:
\begin{bmatrix}1/4\\1/4\\1/4\\1/4\\ \end{bmatrix}
=\begin{bmatrix}0.28613281\\0.14367676\\0.28588867\\0.28430176 \end{bmatrix}\]
这个最终求出来的收敛的值就是我们想要得到的网页的理论影响力大小,把它按照从大到小的顺序排列起来,就是网页的排名了。比如这里的排名是A>C>D>B。
代码实现(基于Python)
import numpy as np
#简易版
def pageRank1(G,delta):
#G为一个方阵,描述了结点间的游走概率
#delta为可接受误差,只要迭代过程中,前后两次算出来的权重列向量的差方小于delta,就认为收敛了
n = G.shape[0] #n为矩阵行数(结点个数)
w = np.ones(n)*(1/n) #初始化每个页面的权重,w是一个长为n的列向量,每个元素代表该网页的权重,初始值为1/n
maxIter = 1000 #最大迭代次数为1000次
for i in range(0,maxIter):
tw = w #暂存上次记录
w = np.dot(G,w) #计算新的概率
err = np.power((tw-w),2) #做差取平方
if(sum(err)<delta): #若收敛了,就停止迭代
break
return w #返回计算的结果
2.修正的PR模型
实际上,上面讨论的只是最基本的模型思想。这个简单的模型还是存在着不少缺陷,比如说,如果某个网页没有链接到其他网页的出链,那么,它的转移列向量就全是0了,也就是对应的转移矩阵里存在一个全为0的列。这样的话,在迭代的过程中,那个网页就像一个黑洞一样,渐渐的吸收其他网页的权重,但是不输出,最终导致全部权重都变成了0。显然这样是不行的,所以一个解决的方法是,对任何一个页面,用户都有一定的概率直接(输入链接地址)去访问,这样,就可以避免这种情况的发生。
于是,引入一个新的量d,叫做阻尼系数,描述的是用户不会随机跳转到某一网页的概率,那1-d就是他会随机跳转到该页面的概率,所以上面的公式修改为:
\]
下面给出修正版的实现,也很简单
#修正版
def pageRank2(G,D,E=0.00001):
#D是阻尼系数
#E是可接受误差
n = G.shape[0] #n为矩阵行数(结点个数)
w = np.ones(n)*(1/n)
maxIter = 1000 #最大迭代次数为1000次
for i in range(0,maxIter):
tw = w #暂存上次记录
w = (1-D)/ n + D * np.dot(G, w) #计算新的概率
err = np.power((tw - w), 2) #做差取平方
if(sum(err)<E):
break
return w
3.简单总结
以上就是对pr算法的简单理解与实现,其实核心思想很简单,就是一个网页它拥有的“粉丝”越多或者它的“粉丝”本身就很具备影响力的话,那就可以推断它的影响力相应的也比较大,对应到计算层面就是用了转移矩阵和初始影响力向量做多次乘积运算,直到找到一个接近稳定的值作为网页的影响力。
参考资料:
【1】机器学习经典算法之PageRank https://www.cnblogs.com/jpcflyer/p/11180263.html
【2】PageRank算法原理与实现 https://blog.csdn.net/leadai/article/details/81230557
网页排名算法PagaRank的更多相关文章
- 第十章 PageRank——Google的民主表决式网页排名技术
搜索引擎的结果取决于两组信息:网页的质量信息,这个查询与每个网页的相关性信息.这里,我们介绍前一个. 1.PageRank算法原理 算法的原理很简单,在互联网上,如果一个网页被很多其他网页所链接,说明 ...
- PageRank 算法-Google 如何给网页排名
公号:码农充电站pro 主页:https://codeshellme.github.io 在互联网早期,随着网络上的网页逐渐增多,如何从海量网页中检索出我们想要的页面,变得非常的重要. 当时著名的雅虎 ...
- 2015最新百度搜索引擎(seo优化)排名算法
多少年来,对于弄清百度排名算法成为了一代又一代站长的最高目标.随着百度推出了搜索引擎网页质量**,直接揭开了神秘的百度排名算法,这是作为站长福音啊.现在小编就来为大家介绍一下. 首先想要得到直接需要的 ...
- 谷歌的网页排序算法(PageRank Algorithm)
本文将介绍谷歌的网页排序算法(PageRank Algorithm),以及它如何从250亿份网页中捞到与你的搜索条件匹配的结果.它的匹配效果如此之好,以至于“谷歌”(google)今天已经成为一个被广 ...
- 转:Reddit排名算法工作原理
http://www.aqee.net/how-reddit-ranking-algorithms-work/ 这是一篇继<Hacker News 排名算法工作原理>之后的又一篇关于排名算 ...
- 基于视觉信息的网页分块算法(VIPS) - yysdsyl的专栏 - 博客频道 - CSDN.NET
基于视觉信息的网页分块算法(VIPS) - yysdsyl的专栏 - 博客频道 - CSDN.NET 于视觉信息的网页分块算法(VIPS) 2012-07-29 15:22 1233人阅读 评论(1) ...
- Hacker News网站的文章排名算法工作原理
In this post I'll try to explain how Hacker News ranking algorithm works and how you can reuse it in ...
- 高效网页去重算法-SimHash
记得以前有人问过我,网页去重算法有哪些,我不假思索的说出了余弦向量相似度匹配,但如果是数十亿级别的网页去重呢?这下糟糕了,因为每两个网页都需要计算一次向量内积,查重效率太低了!我当时就想:论查找效率肯 ...
- Hacker News排名算法工作原理
这篇文章我要向大家介绍Hacker News网站的文章排名算法工作原理,以及如何在自己的应用里使用这种算法,这个算法非常简单,但却在突出热门文章和遴选新文章上表现的非常优秀.本质上,这段Hacker ...
随机推荐
- MSSQL2008下备份好的*.bak--->>>恢复到--->>>MSSQL2014(解决办法)
MSSQL2008下备份好的*.bak--->>>恢复到--->>>MSSQL2014(解决办法) 在进行CTE训练时(同时也要理解下窗口函数的应用),发现不能继续 ...
- 获取ul下面最后一个li或ul中有多少个li
获取ul下面最后一个li或ul中有多少个li 先获取ul的对象,再通过这个对象获取li的list用for循环取值text之类的 def set_city(self, base_info): quali ...
- CSS基础之简单介绍
网页诞生初期,没有描述样式的语言,创建了很多用于描述样式的标签.但这些标签破坏了html作为一门结构语言的表现. 于是,W3C在1995年开始起草CSS,提出将结构和样式分离的解决方案. 元素 元素是 ...
- Dubbo——服务引用
文章目录 引言 正文 服务订阅 Invoker的创建 单注册中心的Invoker创建 Dubbo直连的Invoker创建 创建代理类 引言 上一篇我们分析了服务发布的原理,可以看到默认是创建了一个Ne ...
- webpack简单笔记
本文简单记录学习webpack3.0的笔记,已备日后查阅.节省查阅文档时间 安装 可以使用npm安装 //全局安装 npm install -g webpack //安装到项目目录 npm insta ...
- Spring中基于xml的AOP
1.Aop 全程是Aspect Oriented Programming 即面向切面编程,通过预编译方式和运行期动态代理实现程序功能的同一维护的一种技术.Aop是oop的延续,是软件开发中的 一个热点 ...
- java scoket aIO 通信
AsynchronousServerSocketChannel assc.accept(this, new ServerCompletionHandler()); 第一个参数是服务器的处理类,第二个参 ...
- Spark学习笔记(三)-Spark Streaming
Spark Streaming支持实时数据流的可扩展(scalable).高吞吐(high-throughput).容错(fault-tolerant)的流处理(stream processing). ...
- base64格式的图片上传阿里云
base64格式的图片上传阿里云 上传图片的时候,除了普通的图片上传,还有一张图片信息是以base64格式发送到后台的. 后台接受base64格式的图片,上传至阿里云代码:(主要是将base64转化成 ...
- JavaScript基础对象创建模式之命名空间(Namespace)模式(022)
JavaScript中的创建对象的基本方法有字面声明(Object Literal)和构造函数两种,但JavaScript并没有特别的语法来表示如命名空间.模块.包.私有属性.静态属性等等面向对象程序 ...