算法-搜索(6)B树
B树是平衡的m路搜索树。
根结点至少两个子女,根结点以外的非失败结点至少⌈m/2⌉个子女,所有失败结点都在h+1层。
第h层至少2⌈m/2⌉h-1个结点,因此失败结点数n+1≥2⌈m/2⌉h-1个。
每个结点包含一组指针recptr[m],指向实际记录的存放地址。recptr[i]与key[i]形成了一个索引项
注:key[0]~key[n]和ptr[0]~ptr[n](n<m)
1.B树的插入
每个非失败结点都有⌈m/2⌉-1~m-1个关键码,插入后超过范围的话需要分裂结点。
前⌈m/2⌉-1个关键码形成结点p,后m-⌈m/2⌉个结点形成结点q,第⌈m/2⌉个关键码和指向q的指针插入到p的父结点。
最差情况下,自顶向下搜索叶结点需要h次读盘,自底向上分裂路径上每一个结点。分裂非根结点时插入两个结点,分裂根结点时插入三个结点。需要读写磁盘次数=3h+1(不考虑读入的结点再向上插入时需要重新从磁盘读入)
当m较大时,访问磁盘的平均次数接近h+1。
2.B树的删除
如果被删关键码不在叶结点,在删去后就找其后一个指针指向的子树里最小的关键码x替代,再删去叶结点的关键码x。
在叶结点中删去关键码:
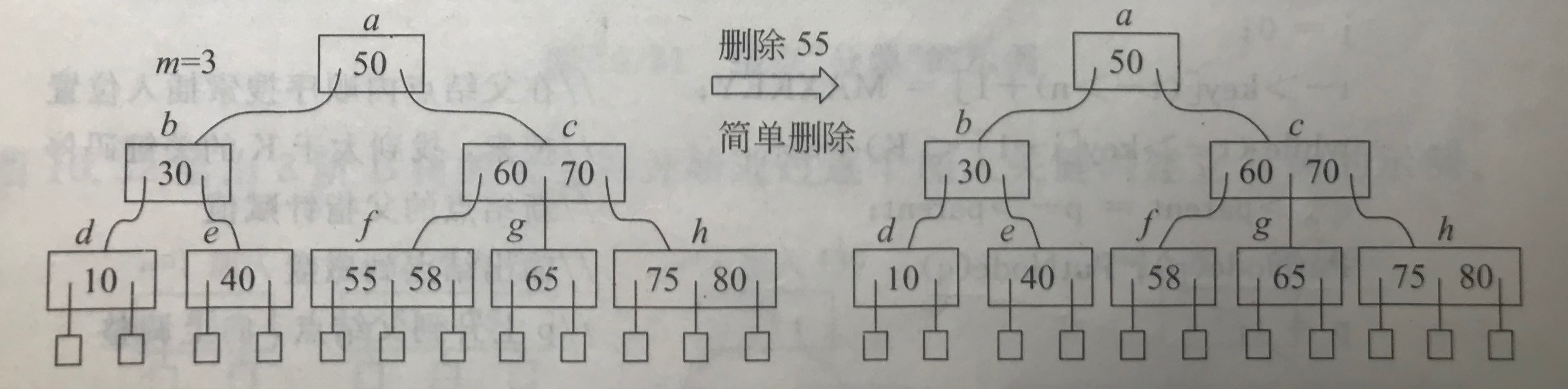
(1)被删关键码所在结点是根结点、结点关键码个数n≥2,直接删除关键码并将结点写回磁盘。
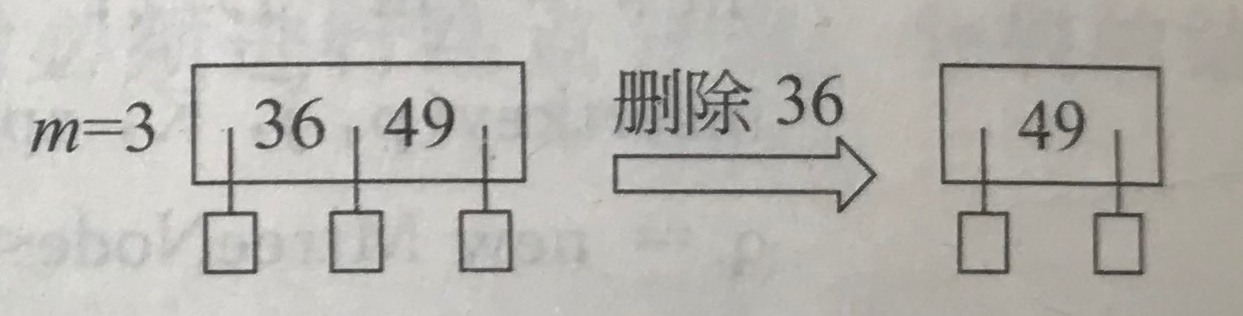
(2)被删关键码所在结点不是根结点、结点关键码个数n≥⌈m/2⌉,,直接删除关键码并将结点写回磁盘。
(3)被删关键码在叶结点、结点关键码个数n=⌈m/2⌉-1、相邻右兄弟/左兄弟结点关键码个数n≥⌈m/2⌉
①将父结点刚刚好大于/小于待删关键码的关键码下移到待删关键码的位置。
②将右兄弟/左兄弟结点中的最小/最大关键码上移到父结点的该位置。
③将右兄弟/左兄弟结点的最左/右子树指针平移到被删关键码所在结点的最后/最前子树指针位置。
④右/左兄弟结点被移走了一个关键码和一个指针,需要要剩下的填补调整,结点的关键码个数n也要减1。

(4)被删关键码在叶结点、结点关键码个数n=⌈m/2⌉-1、相邻右兄弟/左兄弟结点关键码个数n=⌈m/2⌉-1,则需要合并结点。
①将父结点p刚刚好大于待删关键码的关键码下移到待删关键码的位置。
②将若要合并p中子树指针pi和所pi+1指向的结点,并保留pi指向的结点,则将Ki+1关键码下移。
③把要指向pi结点全部关键码和指针都移到pi+1指向结点,并将其删除。
④p结点被移走了一个关键码和一个指针,需要要剩下的填补调整,结点的关键码个数n也要减1。
⑤如果p结点是根结点且关键码个数减少到了0,则将其删去,合并后结点作为新根;如果p结点不是根结点且关键码个数减少到了⌈m/2⌉-1,它要和自己的兄弟结点合并并重复该过程;
- template <class T>
- class Btree:public Mtree<T>{ //B树类继承自m树
- public:
- Btree();
- bool Insert(const T& x);
- bool Remove(T& x);
- void LeftAdjust(MtreeNode<T> *p,MtreeNode<T> *q,int d,int j);
- void RightAdjust(MtreeNode<T> *p,MtreeNode<T> *q,int d,int j);
- void compress(MtreeNode<T> *p,int j);
- void merge(MtreeNode<T> *p,MtreeNode<T>* q,MtreeNode<T> *pl,int j);
- };
- template <class T>
- bool Btree<T>::Insert(const T& x){
- //将关键码x插入到一个驻留在磁盘的m阶B树中
- Triple<T> loc=Search(x);
- if(!loc.tag) return false; //已存在
- MtreeNode<T> *p=loc.r,*q; //p是关键码要插入的结点地址
- MtreeNode<T> *ap=NULL,*t; //ap是插入码x的右邻指针
- T k=x;int j=loc.i; //(k,ap)形成插入二元组
- while(){
- if(p->n<m-){ //结点关键码个数未超出
- insertkey(p,j,k,ap);
- PutNode(p);
- return true;
- }
- int s=(m+)/; //准备分裂结点
- insertkey(p,j,k,ap); //插入后p->n达到m
- q=new MtreeNode<T>;
- move(p,q,s,m); //将p的key[s+1..m]和ptr[s..m]移动到q的key[1..s-1]和ptr[0..s-1],p->n改为s-1,q->n改为m-s
- k=p->key[s]; ap=q; //(k,ap)形成向上插入二元组
- if(p->parent!=NULL){
- t=p->parent;GetNode(t);
- j=;
- t->key[(t->n)+]=MAXKEY;
- while(t->key[j+]<k) j++; //搜索,找到大于K的关键码停止
- q->parent=p->parent;
- PutNode(p);PutNode(q);
- p=t; //p上升到父结点,继续调整
- }
- else{ //原p为根,需要产生新根
- root=new MtreeNode<T>;
- root->n=;root->parent=NULL;
- root->key[]=k;
- root->ptr[]=p;
- root->ptr[]=ap;
- q->parent=p->parent=root;
- PutNode(p);PutNode(q);PutNode(root);
- return true;
- }
- }
- }
- template <class T>
- bool Btree<T>::Remove(const T& x){
- Triple<T> loc=Search(x);
- if(loc.tag) return false; //未找到
- MtreeNode<T> *p=loc.r,*q,*s;
- int j=loc.i; //p->key[j]==x
- if(p->ptr[j]!=NULL){ //非叶结点
- s=p->ptr[j];GetNode(s);q=p;
- while(s!=NULL){
- q=s;
- s=s->ptr[];
- }
- p->key[j]=q->key[];
- compress(q,); //把结点q中1以后的指针和关键码前移,删除key[1]
- p=q;
- }
- else compress(p,j); //叶结点,直接删除
- int d=(m+)/;
- while(){
- if(p->n<d-){ //小于最小限制
- j=;q=p->parent;
- GetNode(q);
- while(j<=q->n && q->ptr[j]!=p)
- j++;
- if(!j) LeftAdjust(p,q,d,j);
- else RightAdjust(p,q,d,j);
- p=q;
- if(p==root) break;
- }
- else break;
- }
- if(root->n==){
- p=root->ptr[];
- delete root;
- root=p;
- root->parent=NULL;
- }
- return true;
- }
- template <class T>
- void LeftAdjust(MtreeNode<T> *p,MtreeNode<T> *q,int d,int j){
- MtreeNode<T> *pl=q->ptr[j+];
- if(pl->n>d-){ //右兄弟空间还够,仅做调整
- p->n++;
- p->key[p->n]=q->key[j+];
- q->key[j+]=pl->key[];
- p->ptr[p->n]=pl->ptr[];
- pl->ptr[]=pl->ptr[];
- compress(pl,);
- }
- else merge(p,q,pl,j+); //p与pl合并,保留p结点
- }
- template <class T>
- void RightAdjust(MtreeNode<T> *p,MtreeNode<T> *q,int d,int j){
- }
- void compress(MtreeNode<T> *p,int j){
- for(int i=j; i<p-n; i++){ //左移
- p->key[i]=p->key[i+];
- p->ptr[i]=p->ptr[i+];
- }
- p->n--; //结点中元素个数减1
- }
- void merge(MtreeNode<T> *p,MtreeNode<T>* q,MtreeNode<T> *pl,int j){
- p->key[(p->n)+]=q->key[j];
- p->ptr[(p->n)+]=pl->ptr[];
- for(int i=; i<=pl->n; i++){
- p->key[(p->n)+i+]=pl->key[i];
- p->ptr[(p->n)+i+]=pl->ptr[i];
- }
- compress(q,j);
- p->n=p->n+pl->n+;
- delete pl;
- }
算法-搜索(6)B树的更多相关文章
- 算法进阶面试题05——树形dp解决步骤、返回最大搜索二叉子树的大小、二叉树最远两节点的距离、晚会最大活跃度、手撕缓存结构LRU
接着第四课的内容,加入部分第五课的内容,主要介绍树形dp和LRU 第一题: 给定一棵二叉树的头节点head,请返回最大搜索二叉子树的大小 二叉树的套路 统一处理逻辑:假设以每个节点为头的这棵树,他的最 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- Java数据结构和算法 - 什么是2-3-4树
Q1: 什么是2-3-4树? A1: 在介绍2-3-4树之前,我们先说明二叉树和多叉树的概念. 二叉树:每个节点有一个数据项,最多有两个子节点. 多叉树:(multiway tree)允许每个节点有更 ...
- 【程序员的吃鸡大法】利用OCR文字识别+百度算法搜索,玩转冲顶大会、百万英雄、芝士超人等答题赢奖金游戏
[先上一张效果图]: 一.原理: 其实原理很简单: 1.手机投屏到电脑: 2.截取投屏画面的题目部分,进行识别,得到题目和三个答案: 3.将答案按照一定的算法,进行搜索,得出推荐答案: 4.添加了一些 ...
- 算法导轮之B树的学习
最近学习了算法导轮里B树相关的知识,在此写一篇博客作为总结. 1.引言 B树是为磁盘或其他直接存取的辅助存储设备而设计的一种平衡搜索树.B树类似于红黑树,但它与红黑树最大不同之处在于B树的节点可以拥有 ...
- Java数据结构和算法(一)树
Java数据结构和算法(一)树 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 前面讲到的链表.栈和队列都是一对一的线性结构, ...
- 利用OCR文字识别+百度算法搜索,玩转冲顶大会、百万英雄、芝士超人等答题赢奖金游戏
[先上一张效果图]: 一.原理: 其实原理很简单: 1.手机投屏到电脑: 2.截取投屏画面的题目部分,进行识别,得到题目和三个答案: 3.将答案按照一定的算法,进行搜索,得出推荐答案: 4.添加了一些 ...
- bs4--官文--搜索文档树
搜索文档树 Beautiful Soup定义了很多搜索方法,这里着重介绍2个: find() 和 find_all() .其它方法的参数和用法类似,请读者举一反三. 再以“爱丽丝”文档作为例子: ht ...
- 0算法基础学算法 搜索篇第二讲 BFS广度优先搜索的思想
dfs前置知识: 递归链接:0基础算法基础学算法 第六弹 递归 - 球君 - 博客园 (cnblogs.com) dfs深度优先搜索:0基础学算法 搜索篇第一讲 深度优先搜索 - 球君 - 博客园 ( ...
- loj#6072 苹果树(折半搜索,矩阵树定理,容斥)
loj#6072 苹果树(折半搜索,矩阵树定理,容斥) loj 题解时间 $ n \le 40 $ . 无比精确的数字. 很明显只要一个方案不超过 $ limits $ ,之后的计算就跟选哪个没关系了 ...
随机推荐
- Zookeeper集群部署及报错分析
安装 下载压缩包 解压 修改zoo.cfg文件 创建myid文件 启动 自启动配置 有时间再补hhh 报错处理 很荣幸的遇到了大部分报错,日志再zookeeper目录的bin下的zookeeper.o ...
- 算法数据结构 | 只要30行代码,实现快速匹配字符串的KMP算法
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是算法数据结构专题的第29篇文章,我们来聊一个新的字符串匹配算法--KMP. KMP这个名字不是视频播放器,更不是看毛片,它其实是由Kn ...
- PHP key() 函数
------------恢复内容开始------------ 实例 从当前内部指针位置返回元素键名: <?php$people=array("Peter","Joe ...
- PHP vprintf() 函数
实例 输出格式化的字符串: <?php高佣联盟 www.cgewang.com$number = 9;$str = "Beijing";vprintf("There ...
- luogu P4725 多项式对数函数(多项式 ln)
LINK:多项式对数函数 多项式 ln 如题 是一个模板题.刚学会导数 几个知识点 \([f(x)\cdot g(x)]'=f(x)'g(x)+f(x)g(x)',f(g(x))'=f'(g(x))g ...
- 死磕abstractqueuedsynchronizer源码
第一次写博客,先练练手. 1.AQS是什么? 在Lock中,用到了一个同步队列AQS,全称为AbstractQueuedSynchronizer,它是一个同步工具也是lock用来实现线程同步的核心组件 ...
- Dynamics365 Field Service Work Order Theory
Come from :https://neilparkhurst.com/2016/08/20/field-service-work-order-theory/ In this post I aim ...
- time模块 random模块
time模块 time.sys等模块是C语言实现的,内置到了python解释器的.而不是py文件. 导入模块的时候,优先到python解释器,然后才会找py文件. #时间戳 #计算 # print(t ...
- “随手记”开发记录day12
就我们团队昨天的讨论,今天进行更改. 今天我们先简单的更改了之前的粉色背景图,因为用户反应总览界面的“总览”二字,是深粉色背景不太美观.进过多次更改之后使颜色变得更舒适.
- 手敲代码太繁琐?“拖拉拽”式Python编程惊艳到我了
Python到底有多火,从后端开发到前端开发:从金融量化分析到大数据:从物联网到人工智能,都有Python的踪迹. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后, ...