The Google File System(论文阅读笔记)
概述
GFS:一个可扩展的分布式文件系统,用于大型分布式数据相关应用,TB级的数据,成千上万的并发请求。
设计概览
假设
- 组件的失效比异常更加常见
- 多数的文件修改操作是追加数据而不是重写原来的数据/随机读写
- GB及更大的单个文件是很常见的,对于小文件提供支持,但是无需专门考虑影响。
- 系统主要负荷由大型顺序读写、小型随机读写构成。客户端应该对随机读写进行排序以提高性能。
- 持续的高带宽比低延迟更重要
架构

- GFS集群由一个master和多个chunk server组成,被多个客户端访问。
- 文件被分割成64M的多个chunk,每个chunk 用唯一的块句柄来标识,句柄由master在创建块的时候进行分配。块服务器存储块,按照块句柄和块内偏移来读写块数据。
- 每个文件块有多个备份(replicas),默认是3个
- master维护GFS的元数据,包括名字空间(文件名、块句柄)、访问控制信息(权限管理),文件与块的链接(map<文件名,list of 块>,map<块,list of location>),管理块租借(primary chunk, version number),块的垃圾回收、块迁移等
- master会定期与块服务器进行通信(ping),来收集、检查chunk server的状态
- 客户端和块服务器都不会缓存文件数据
- 中心化架构
单Master
- 简化了设计,但是必须使得master在读写方面的占用最小化(防止成为热点,导致性能瓶颈)
- 客户端本地缓存块句柄和块位置
- Chunk Size 大小设置为64M
Chunk Size
- 64MB的大小比一般的linux文件大
- 降低了块的数量
- 减小了master响应请求的压力
- 减小了网络压力
- 小文件(不足64MB),可能成为“热点”。
元数据
- master将元数据保存在内存中
- 操作速度块
- 通过操作日志来保证元数据安全性
- 通过远程备份操作日志来保证操作日志安全性
- 实践中不用担心OutOfMemory,因为元数据都很小(64Bit)
- 更换更大的内存相比整个系统的代价而言微不足道
- master不持久化块的位置,唯一持久化的信息是操作日志
- 在每次重启的时候,结合操作日志,向chunk server发出对于块信息的请求。返回块位置、版本号等信息。
- 操作日志包含关键元数据的变动记录,是GFS的核心
- 操作日志定义了并发操作顺序的逻辑线。
- 操作日志持久化了元数据
- 使用checkpoint来减小日志规模
- 通过多线程来减小创建checkpoint时的影响
一致性模型
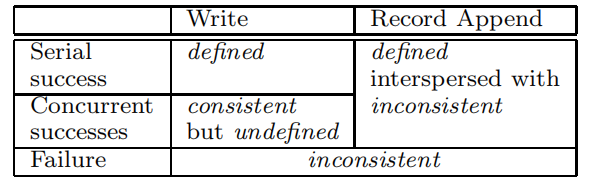
- 轻量(弱一致性)
- 简洁而容易实现
- 成功的操作一定是一致的,但是不一定是已定义的
- 通过填入冗余字符,来使得可能产生未定义范围的操作,最终结果为已定义。
- 通过写入校验和来检查写入记录的有效性(保证已定义)
- 在 一系列成功变动后,变动的文件范围保证是已定义的
- 将块的变动在所有的复本上按 相同的顺序进行记录
- 使用块版本号来检测是否因为块服务器死机造成错过了某些变动,从而复本变成失效
- 失效的复本将不再会涉及后续的变动,Master向客户端响应块的位置时也不会返回此复本的信息
- 不保证一定会返回正确的数据
- 但是一般不是无效的数据,更常见的是“过期”的数据
系统交互
块租约
- 在一个chunk和它的副本中选出一个 primary chunk
- 主块为块的所有变动选择一个序列顺序。所有的复本在应用变动时都遵从这个顺序。
- 全局的变动顺序首先被Master选择 的租约签署顺序所定义,在一个租约中,则由主块赋予的序列号决定
- 一个租约有60s的时间,可以主动解约与续约
- 可以避免由于网络导致的“多个主块”
- 副本间强一致性——在某一个副本上的操作失效,则需要在所有块上重新执行该操作
数据流
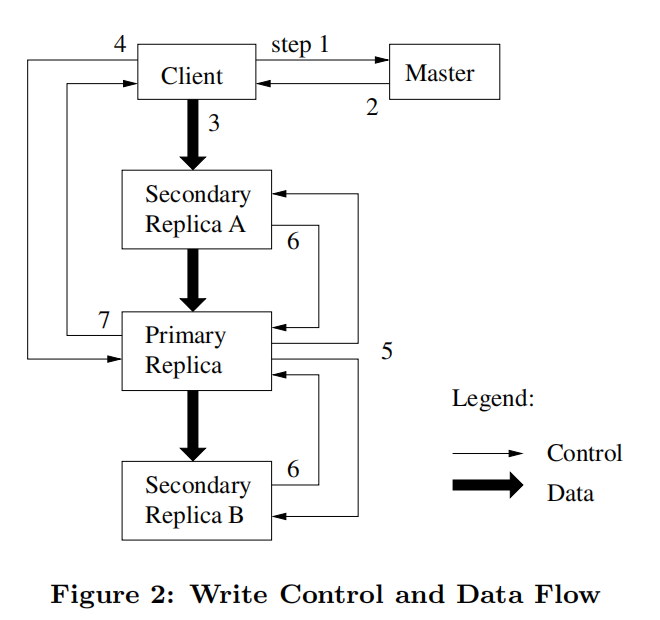
- 推送到网络拓扑中最近的结点
- 原子性的记录追加
- 数据流与控制流解耦
Master 操作
- 加锁来支持在master上并行执行多个操作
- 块创建、重新复制、重新负载均衡
- 将新的复本放在磁盘空间使用率低于平均水平的块服务器 上。
- 限制每台块服务器上的“最近”创建的数量。
- 在机架之间分布块的复本。一旦可用的块的复本数量低于用户指定的指标,Master就将重新创建块的副本
- 使磁盘空间利用率平均化
- 在一个文件被删除之后,GFS不能立刻回收可用的物理存储。回收在对文件和块进行例行垃圾回收时进行
- 当一个文件被应用系统删除,文件会被重命名为一个隐藏的名字,包含删除的时间戳。如果这些文件已经存在了三天(间隔可以配置),Master会将其进行移除。(软删除以防止误删除)
- 通过块版本号来区分当前副本与过期副本
- 当 Master为一个块签署一个租约时,将会递增块的版本号,然后通知当前的复本。Master和这些复本都在它们的持久化状态中记录新的版本号。
- 发生在客户端被通知之前 也就是 data flow 的第1步与第2步之间
容错
- chunk 与master 复制
- 保留多个块的副本
- 操作日志和检查点在多个机器上复制
- shadow master
- Data Integrity
- 由于磁盘可能会损坏,所以必须要有能够检查数据正确性的手段(对于chunk server而言)
- 通过校验和来检查(上文也提到过)
- 每个服务器独立维护CheckSum
- 由于磁盘可能会损坏,所以必须要有能够检查数据正确性的手段(对于chunk server而言)
读了好几次这篇论文,可以说越读问题越多,越读收获越多。虽然有许多细节论文没有交代清楚,但是总的框架是十分清晰的。
简洁、高效,贴近实际场景。GFS的设计正如论文开篇的假定一样:朴实却又只能如此。
单个PC->性能->集群->容错->一致性->中心化、冗余->性能->去中心化
The Google File System(论文阅读笔记)的更多相关文章
- Google File System 论文阅读笔记
核心目标:Google File System是一个面向密集应用的,可伸缩的大规模分布式文件系统.GFS运行在廉价的设备上,提供给了灾难冗余的能力,为大量客户机提供了高性能的服务. 1.一系列前提 G ...
- The Google File System论文拜读
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google∗ 摘要 我们设计并实现了谷歌文件系统 ...
- The Google File System——论文详解(转)
“Google文件存储系统(GFS)是构建在廉价服务器之上的大型分布式系统.它将服务器故障视为正常现象,通过软件方式自动容错,在保证系统可用性和可靠性同时,大大降低系统成本. GFS是Google整个 ...
- Google file system
读完了Google file system论文的中文版,记录一下总结,懒得打字,直接上草图:
- 《The Google File System》论文阅读笔记——GFS设计原理
一.设计预期 设计预期往往针对系统的应用场景,是系统在不同选择间做balance的重要依据,对于理解GFS在系统设计时为何做出现有的决策至关重要.所以我们应重点关注: 失效是常态 主要针对大文件 读操 ...
- 经典论文翻译导读之《Google File System》(转)
[译者预读] GFS这三个字母无需过多修饰,<Google File System>的论文也早有译版.但是这不妨碍我们加点批注.重温经典,并结合上篇Haystack的文章,将GFS.TFS ...
- 《The Google File System》论文研读
GFS 论文总结 说明:本文为论文 <The Google File System> 的个人总结,难免有理解不到位之处,欢迎交流与指正 . 论文地址:GFS Paper 阅读此论文的过程中 ...
- 《The Google File System》 笔记
<The Google File System> 笔记 一.Introduction 错误是不可避免的,应当看做正常的部分而不是异常.因此需要设计持续监控,错误检查,容错,自动恢复的系统. ...
- 大数据理论篇HDFS的基石——Google File System
Google File System 但凡是要开始讲大数据的,都绕不开最初的Google三驾马车:Google File System(GFS), MapReduce,BigTable. 为这一切的基 ...
- 谷歌三大核心技术(一)The Google File System中文版
谷歌三大核心技术(一)The Google File System中文版 The Google File System中文版 译者:alex 摘要 我们设计并实现了Google GFS文件系统,一个 ...
随机推荐
- WIN10有线网络反复断开解决方法
最近家里台式机碰到一个奇怪的问题,开机之后有线网络就时断时续,右下角网络图标不停在小地球与小电脑之间切换.网上大概搜索了一下,貌似碰到这种问题的朋友不在少数,但大部分朋友碰到的都是无线网络居多.这里把 ...
- 聊聊Java
聊聊Java 笔记源于 视频教程Bilibili:狂神说Java 关注公众号:狂神说 能干嘛? 热度 TIOBE 狂神计划 三高:高可用.高性能.高并发 全球几千万的程序员都会Java,真正精通的不到 ...
- Navicat远程连接MySQL 提示1045 - Access denied for user 'root'@'223.74.158.192'(using password:YES)
问题: 今天在自己的阿里云服务器上(Window Server2012 R2)安装了一个MySQL5.7.26,在阿里云服务器中通过本地链接是正常的,但是当在自己的电脑上使用Navicat连接是提示: ...
- CD题解(药水的选择)
这道题显然是一个01背包加上记录路径的题目,要说这道题的原型就是N多年前的CD 本题主要考的就是对01背包的基础板子加上稍微一点点的码力,就可以A掉这个题了 废话不多说,上代码: #include&l ...
- 数学计算 LibreOJ - 2573
题目描述 小豆现在有一个数 x ,初始值为 1 . 小豆有 Q 次操作,操作有两种类型: 1 m: x=x×m ,输出 xmodM : 2 pos: x=x/ 第 pos 次操作所乘的数(保证第 po ...
- Windows下生成IOS证书并发布APP安装到IPhone
目录: 一:生成证书 二:安装到IPhone 准备环境: 1.Appuploader(需要安装Java环境) 2.爱思助手 一.生成证书 1.1.打开appuploader后登陆开发者账号 1.2.点 ...
- 正则表达式以及sed,awk用法 附带案例
则表达式 基本正则 ^ $ [ ] [^] . * \{n,m\} \{n,\} \(ro\)\{2\} \(\) 扩展正则 egrep grep - ...
- 安装visual stdio 2017后依然报错:Unable to find vcvarsall.bat
安装visual stdio 2017后依然报错:Unable to find vcvarsall.bat 解决办法:更新setuptools 原文章:https://blog.csdn.net/wl ...
- 数据可视化之DAX篇(十)在PowerBI中累计求和的两种方式
https://zhuanlan.zhihu.com/p/64418286 假设有一组数据, 已知每一个产品贡献的利润,如果要计算前几名产品的贡献利润总和,或者每一个产品和利润更高产品的累计贡献占总体 ...
- 数据可视化之DAX篇(九) 关于DAX中的VAR,你应该避免的一个常见错误
https://zhuanlan.zhihu.com/p/67803111 本文源于微博上一位朋友的问题,在计算同比增长率时,以下两种DAX代码有什么不同? -------------------- ...