Logistic回归之有序logistic回归分析
Logistic回归分析(logit回归)一般可分为3类,分别是二元logistic回归分析、多分类Logistic回归分析和有序Logistic回归分析。logistic回归分析类型如下所示。
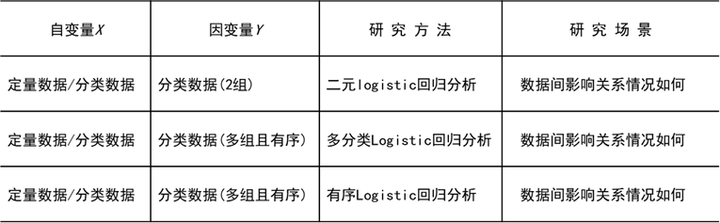
Logistic回归分析用于研究X对Y的影响,并且对X的数据类型没有要求,X可以为定类数据,也可以为定量数据,但要求Y必须为定类数据,并且根据Y的选项数,使用相应的数据分析方法。
- 如果Y有两个选项,如愿意和不愿意、是和否,那么应该使用有序logistic回归分析(SPSSAU进阶方法->二元logit);
- 如果Y有多个选项,并且各个选项之间可以对比大小,例如,1代表“不愿意”,2代表“无所谓”,3代表“愿意”,这3个选项具有对比意义,数值越高,代表样本的愿意程度越高,那么应该使用多元有序Logistic回归分析(SPSSAU进阶方法->有序logit);
- 如果Y有多个选项,并且各个选项之间不具有对比意义,例如,1代表“淘宝”,2代表“天猫”,3代表“京东”,4代表“亚马逊中国”,数值仅代表不同类别,数值大小不具有对比意义,那么应该使用多元无序Logistic回归分析(SPSSAU进阶方法->多分类logit)。
1、有序logistic回归分析基本说明
进行有序logistic回归时,通常需要有以下步骤,分别是连接函数选择,平行性检验,模型似然比检验,参数估计分析,模型预测准确效果共5个步骤。
1) 连接函数选择
SPSSAU共提供五类连接函数,分别如下:
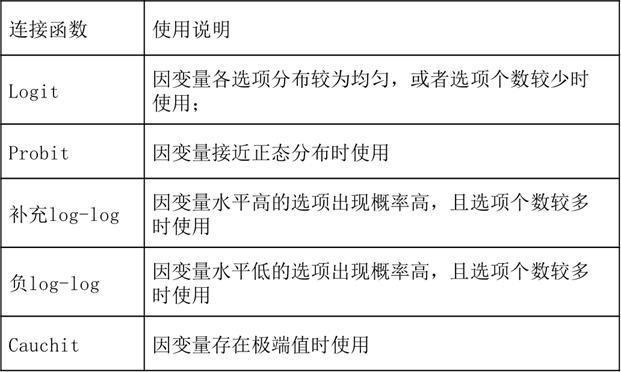
SPSSAU默认使用logit连接函数,如果模型没有特别的要求,应该首选使用logit连接函数,尤其是因变量的选项数量很少的时候。连接函数可能会对平行性检验起到影响,如果平行性检验无法通过时,可考虑选择更准确的连接函数进行尝试。正常情况下使用默认的logit连接函数即可。
2) 平行性检验
一般来说,模型最好通过平行性检验,但在研究中很可能出现无法通过的现象。此时有以下建议,如下:
- 改用多分类logistic回归;换个方法,因为一般可使用有序logistic回归的数据也可以使用多分类logistic回归分析;
- 改用线性回归;可考虑换成线性回归分析尝试;
- 改变连接函数;选择更适合的连接函数;
- 将因变量的类别选项进行一些合并处理等,使用SPSSAU数据处理->数据编码功能。
一般来说,有序logistic回归有一定的稳健性,即平行性检验对应的P值接近于0.05时,可考虑直接接受有序logistic回归分析的结果。
3) 模型似然比检验
模型似然比检验用于对整个模型的有效性进行分析,一般对应的P值小于0.05即可。同时SPSSAU还提供AIC和BIC这两个指标值,如果模型有多个,而且希望进行模型之间的优劣比较,可使用此两个指标,此两个指标是越小越好。具体可直接查看SPSSAU的智能分析和分析建议即可。
4) 参数估计分析
参数估计分析其实就已经开始进入实质性的分析了。首先可分析R方,即模型的拟合水平情况,SPSSAU提供3个R方值指标,分别是McFadden R 方、Cox & Snell R 方和Nagelkerke R 方。此3个R 方均为伪R 方值,其值越大越好,但其无法非常有效的表达模型的拟合程度,意义相对交小,而且多数情况此3个指标值均会特别小,研究人员不用过分关注于此3个指标值。一般报告其中任意一个R方值指标即可。
5) 模型预测效果分析
有序logistic回归建模时,还可以对模型的预测效果进行分析,SPSSAU也会默认输出结果,当然一般情况下我们关注于影响关系,因而对于预测效果等不那么看重。即模型预测质量的关注乎相对较低,多数时候直接忽略它。
2、如何使用SPSSAU进行有序logistic回归操作
关于有序logistic回归的操作上,SPSSAU操作如下:
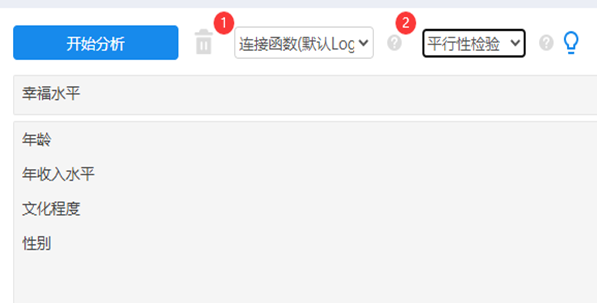
至于分析结果如下:
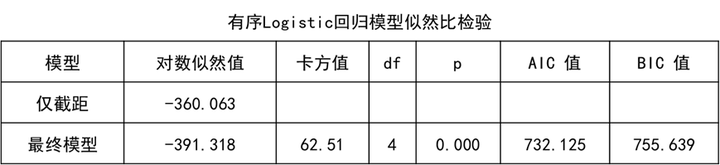
首先对模型整体有效性进行分析(模型似然比检验),从上表可知:此处模型检验的原定假设为:是否放入自变量(性别_女, 年龄, 年收入水平, 文化程度)两种情况时模型质量均一样;分析显示拒绝原假设(chi=62.510,p=0.000<0.05),即说明本次构建模型时,放入的自变量具有有效性,本次模型构建有意义。
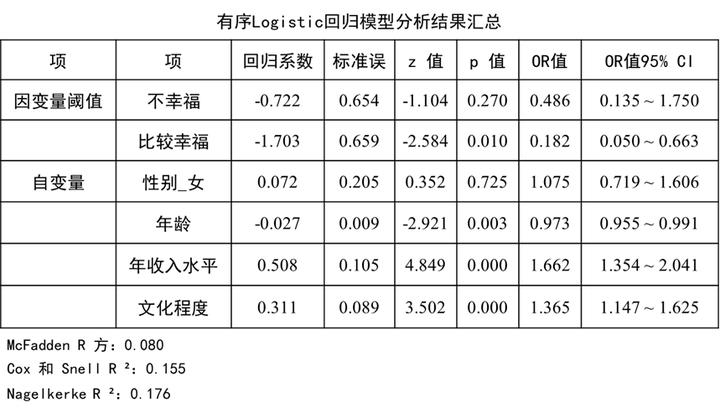
首先可针对任意一个R方值进行描述,一般是McFadden R 方为0.08,意味着自变量仅解释幸福度8%的原因,logistic回归时R方值一般都比较小,一般不用过多理会。
具体分析影响关系时,可直接参考SPSSAU的智能分析即可,而上表格还列出因变量阈值对应的信息,该数据对数据分析并无过多意义,仅为数学上的指标值而已。
性别_女的回归系数值为0.072,但是并没有呈现出显著性(z=0.352,p=0.725>0.05),意味着性别并不会对幸福水平产生影响关系。
年龄的回归系数值为-0.027,并且呈现出0.01水平的显著性(z=-2.921,p=0.003<0.01),意味着年龄会对幸福水平产生显著的负向影响关系。年龄越大的人幸福水平反而越低。
年收入水平的回归系数值为0.508,并且呈现出0.01水平的显著性(z=4.849,p=0.000<0.01),意味着年收入水平会对幸福水平产生显著的正向影响关系。收入水平越高的群体,幸福度会越高。
文化程度的回归系数值为0.311,并且呈现出0.01水平的显著性(z=3.502,p=0.000<0.01),意味着文化程度会对幸福水平产生显著的正向影响关系。文化水平越高的群体,他们的幸福度会越高。
3、有序logistic相关问题
在使用SPSSSAU进行有序logistic回归时,可能会出现一些问题,比如提示奇异矩阵,质量异常,Y值只能为0或1等,接下来一一说明。
第1点:出现奇异矩阵或质量异常
如果做有序logsitic回归时提示奇异矩阵,通常有两个原因,一是虚拟哑变量设置后,本应该少放1项作为参考项但是并没有,而是把所有的哑变量项都放入框中,这会导致绝对的共线性问题即会出现奇异矩阵矩阵。二是X之间有着太强的共线性(可使用通用方法的线性回归查看下VIF值),此时也可能导致模型无法拟合等。先找出原因,然后把有问题的项移出模型中即可。
同时,如果因变量Y的分布极其不均匀,SPSSAU建议可先对类别进行组合,可使用数据处理里面的数据编码完成。
第2点:无法通过平行性检验?
有序Logit回归的分析要求数据满足平行性检验,如果不满足,SPSSAU建议使用多分类Logti回归分析即可,当然也可以改用线性回归,改变连接函数,对因变量Y的选项进行组合等多种方式,尝试并在最终选择出最优方案即可。
第3点:OR值的意义
OR值=exp(b)值,即回归系数的指数次方,该值在医学研究里面使用较多,实际意义是X增加1个单位时,Y的增加幅度。如果仅仅是研究影响关系,该值意义较小。
第4点: wald值或z值
z 值=回归系数/标准误,该值为中间过程值无意义,只需要看p 值即可。有的软件会提供wald值(但不提供z 值,该值也无实际意义),wald值= z 值的平方。
第5点: McFadden R 方、Cox & Snell R 方和Nagelkerke R 方相关问题?
Logit回归时会提供此3个R 方值(分别是McFadden R 方、Cox & Snell R 方和Nagelkerke R 方),此3个R 方均为伪R 方值,其值越大越好,但其无法非常有效的表达模型的拟合程度,意义相对交小,而且多数情况此3个指标值均会特别小,研究人员不用过分关注于此3个指标值。一般报告其中任意一个R方值指标即可。
以上就是本次分享的内容,登录SPSSAU官网了解更多。
Logistic回归之有序logistic回归分析的更多相关文章
- SPSS数据分析—多分类Logistic回归模型
前面我们说过二分类Logistic回归模型,但分类变量并不只是二分类一种,还有多分类,本次我们介绍当因变量为多分类时的Logistic回归模型. 多分类Logistic回归模型又分为有序多分类Logi ...
- 机器学习之三:logistic回归(最优化)
一般来说,回归不用在分类问题上,因为回归是连续型模型,而且受噪声影响比较大.如果非要应用进入,可以使用logistic回归. logistic回归本质上是线性回归,只是在特征到结果的映射中加入了一层函 ...
- 5 Logistic回归(二)
5.2.4 训练算法:随机梯度上升 梯度上升算法:在每次更新回归系数时都需要遍历整个数据集,在数十亿样本上该算法复杂度太高. 改进方法:随机梯度上升算法:一次仅用一个样本点更新回归系数. 由于可以在新 ...
- 机器学习 —— 基础整理(五)线性回归;二项Logistic回归;Softmax回归及其梯度推导;广义线性模型
本文简单整理了以下内容: (一)线性回归 (二)二分类:二项Logistic回归 (三)多分类:Softmax回归 (四)广义线性模型 闲话:二项Logistic回归是我去年入门机器学习时学的第一个模 ...
- 机器学习之Logistic 回归算法
1 Logistic 回归算法的原理 1.1 需要的数学基础 我在看机器学习实战时对其中的代码非常费解,说好的利用偏导数求最值怎么代码中没有体现啊,就一个简单的式子:θ= θ - α Σ [( hθ( ...
- Logistic回归(逻辑回归)和softmax回归
一.Logistic回归 Logistic回归(Logistic Regression,简称LR)是一种常用的处理二类分类问题的模型. 在二类分类问题中,把因变量y可能属于的两个类分别称为负类和正类, ...
- 机器学习笔记(四)Logistic回归模型实现
一.Logistic回归实现 (一)特征值较少的情况 1. 实验数据 吴恩达<机器学习>第二课时作业提供数据1.判断一个学生能否被一个大学录取,给出的数据集为学生两门课的成绩和是否被录取 ...
- 机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归
机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归 关键字:Logistic回归.python.源码解析.测试作者:米仓山下时间:2018- ...
- 『科学计算』通过代码理解线性回归&Logistic回归模型
sklearn线性回归模型 import numpy as np import matplotlib.pyplot as plt from sklearn import linear_model de ...
随机推荐
- 每日一道 LeetCode (2):整数反转
题目:整数反转 题目来源:https://leetcode-cn.com/problems/reverse-integer 给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转. 示 ...
- HTML5 Canvas小游戏基础:用户交互
交互是游戏的根本.缺少了用户交互,游戏就不能称之为游戏,只能说是动画或电影.事件是浏览器响应用户交互操作的一种机制. 1.事件和事件执行 事件定义了用户与页面交互时产生的各种操作(主要通过鼠标或热键的 ...
- 什么是PHP 面向对象
PHP 面向对象 在面向对象的程序设计(英语:Object-oriented programming,缩写:OOP)中,对象是一个由信息及对信息进行处理的描述所组成的整体,是对现实世界的抽象. 在现实 ...
- Python os.fsync() 方法
概述 os.fsync() 方法强制将文件描述符为fd的文件写入硬盘.在Unix, 将调用fsync()函数;在Windows, 调用 _commit()函数.高佣联盟 www.cgewang.com ...
- PHP localeconv() 函数
实例 查找美国本地的数字格式化信息: <?php setlocale(LC_ALL,"US"); $locale_info = localeconv(); print_r($ ...
- PDO::commit
PDO::commit提交一个事务(PHP 5 >= 5.1.0, PECL pdo >= 0.1.0) 说明 语法 bool PDO::commit ( void )高佣联盟 www.c ...
- 6.15 省选模拟赛 老魔杖 博弈论 SG函数
这道题确实没有一个很好的解决办法 唯一的正解可能就是打表找规律 或者 直接猜结论了吧. 尽管如此 在此也给最终结论一个完整的证明. 对于70分 容易发现状态数量不大 可以进行暴力dp求SG函数. 原本 ...
- jsp应用-实现用户登陆功能
项目结构 1.login.jsp 这个没什么好说的,把表单提交到校验页面进行校验 2.首先获取request域中user,password,然后进行校验,校验成功把信息存入session域,然后转发到 ...
- 利用WxJava实现PC网站集成微信登录功能
原文地址:https://mp.weixin.qq.com/s/rT0xL9uAdHdZck_F8nyncg 来源:微信公众号:java碎碎念 1. 微信开放平台操作步骤 微信开放平台地址:https ...
- 还分不清 Cookie、Session、Token、JWT?一篇文章讲清楚
还分不清 Cookie.Session.Token.JWT?一篇文章讲清楚 转载来源 公众号:前端加加 作者:秋天不落叶 什么是认证(Authentication) 通俗地讲就是验证当前用户的身份,证 ...