Canalv1.1.4版本搭建HA集群
前提
Canal上一个正式版是于2019-9-2发布的v1.1.4,笔者几个月前把这个版本的Canal推上了生产环境,部署了HA集群。过程中虽然遇到不少的坑,但是在不出问题的前提下,Canal的作用还是非常明显的。上周的一次改造上线之后,去掉了原来对业务系统订单数据通过RabbitMQ实时推送的依赖,下游的统计服务完全通过上游业务主库的binlog事件进行聚合,从而实现了核心业务和实时统计两个不同的模块解耦。
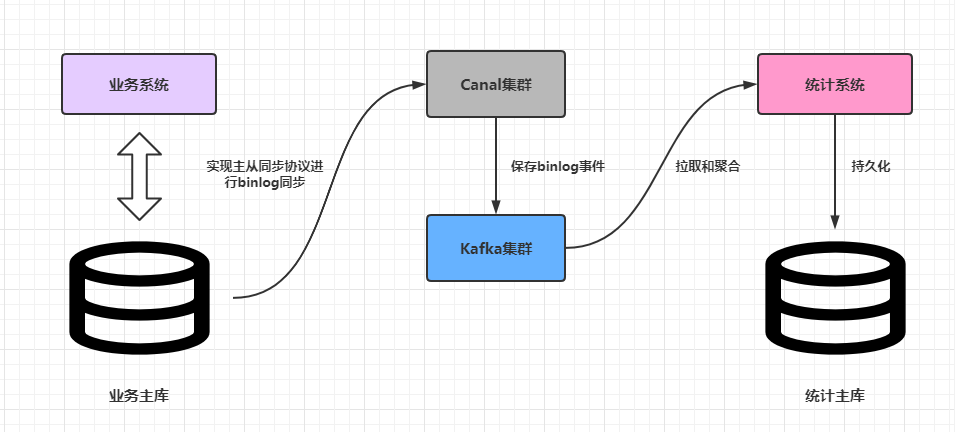
这篇文章简单分析一下如何搭建生产环境下可靠的Canal高可用集群。
Canal高可用集群架构
Canal的HA其实包含了服务端HA和客户端的HA,两者的实现原理差不多,都是通过Zookeeper实例标识某个特定路径下抢占EPHEMERAL(临时)节点的方式进行控制,抢占成功的一者会作为运行节点(状态为running),而抢占失败的一方会作为备用节点(状态是standby)。下文只分析服务端HA集群搭建,因为一般情况下使用内建的数据管道例如Kafka,基本屏蔽了客户端的细节。假设客户端使用了Kafka,也就是Canal从主库同步到的binlog事件最终会投放到Kafka,那么Canal服务端HA集群架构大致如下:
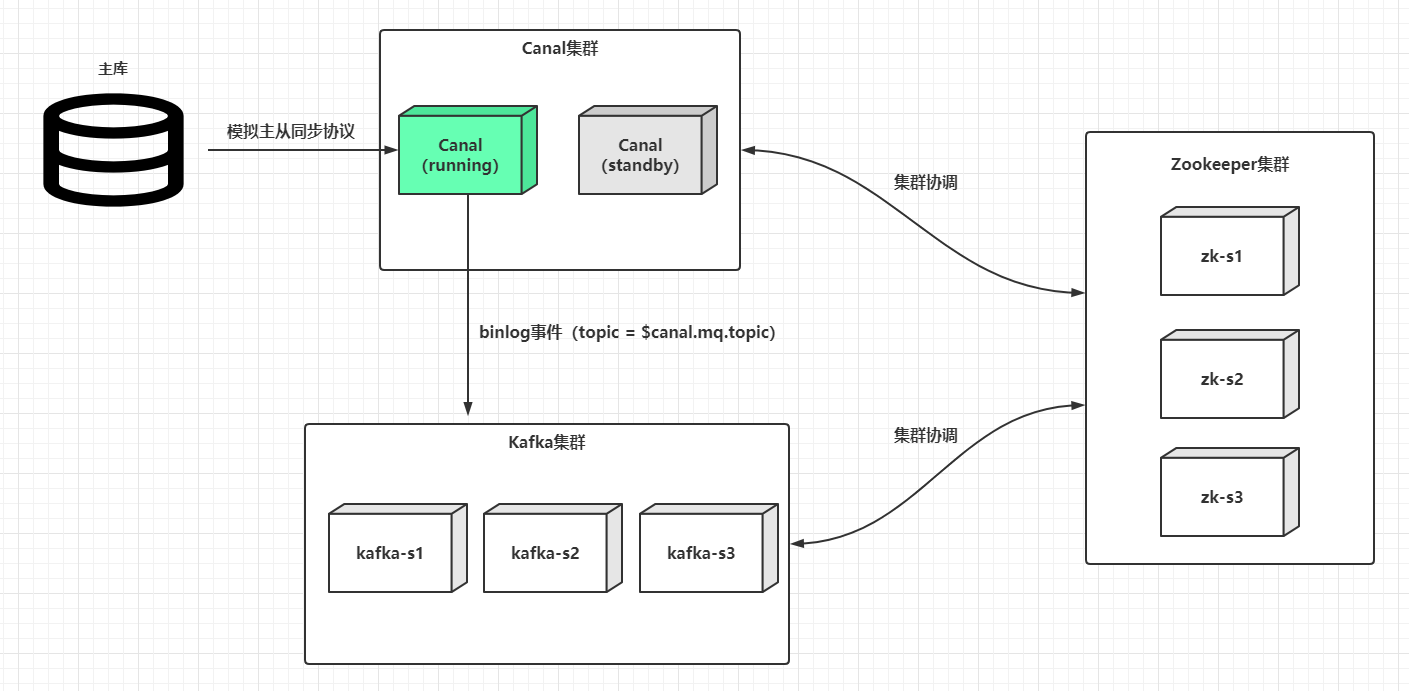
这是全局来看,而一个运行的Canal服务端,可以同时支持监听多个上游数据库的binlog,某个主库解析配置的抽象在Canal中的术语叫做Instance(实例):
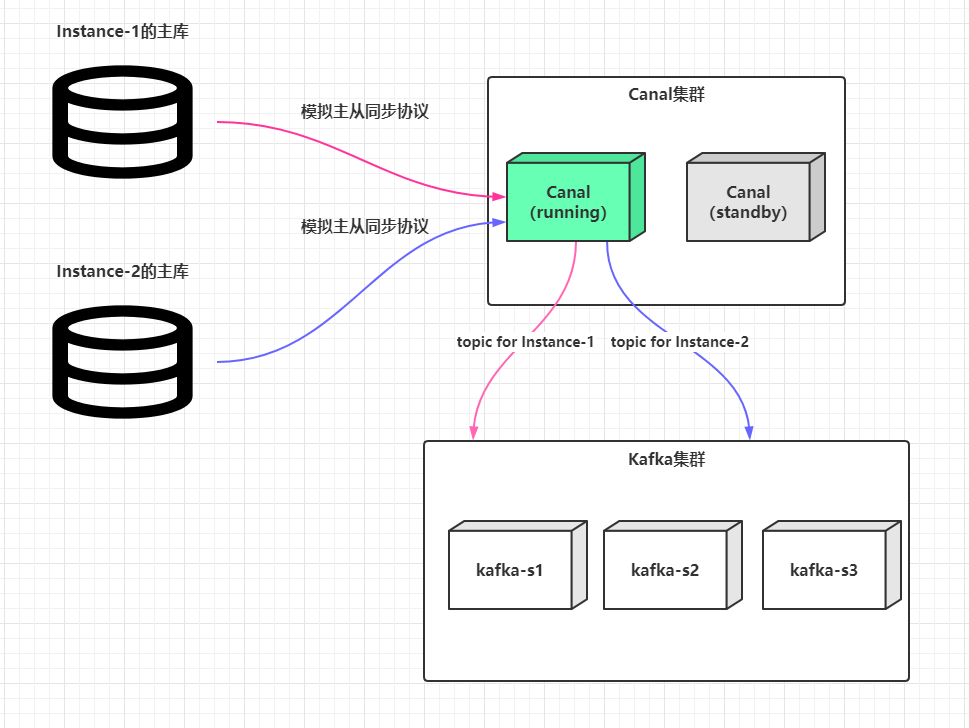
定义多个Instance的操作很简单,主配置文件$CANAL_HOME/conf/canal.properties中的canal.destinations配置项通过英文逗号分隔多个标识如:
# canal.destinations=[Instance标识1,Instance标识2...,Instance标识n]
canal.destinations=customer-service,payment-service
然后在$CANAL_HOME/conf目录下添加customer-service和payment-service文件夹,把原来的$CANAL_HOME/conf/example文件夹中的instance.properties拷贝过去,按需修改里面的配置即可:
$CANAL_HOME
- conf
- customer-service
- instance.properties # 这里主要配置customer-service主库的连接信息、过滤规则和目标topic的配置等等
配置 【canal.mq.topic = customer-service】
- payment-service
- instance.properties # 这里主要配置payment-service主库的连接信息和过滤规则和目标topic的配置等等
配置 【canal.mq.topic = payment-service】
而Canal最终解析好的binlog事件会分别以topic为customer-service或payment-service发送到Kafka集群中,这样就能确保不同数据源解析出来的binlog不会混乱。
Canal会实时监听每个Instance的配置文件instance.properties的变动,一旦发现配置文件有属性项变更,会进行一次热加载,原则是变更Instance的配置文件是不用重启Canal服务的。
搭建Canal高可用集群
为了简单起见,Zookeeper和Kafka使用单节点作为示例,实际上生产环境中建议Zookeeper或Kafka都使用奇数个(>=3)节点的集群。
笔者本地一台CentOS7.x的虚拟机192.168.56.200上安装了Zookeeper和Kafka,本地开发机192.168.56.1是Windows10操作系统。虚拟机安装了一个MySQL8.x的服务端(Canal要求MySQL服务开启binlog支持特性,并且要求binlog类型为ROW,这两点MySQL8.x是默认开启的),现在详细讲解在这两台机器上搭建一个Canal服务端HA集群。
生产上搭建Canal服务端HA集群的机器最好在同一个内网中,并且建议服务器由Canal独占,不要部署其他中间件或者应用,机器的配置建议4核心8GB内存起步。
下载当前(2020-08-22)最新版本的canal.deployer-1.1.4.tar.gz:
拷贝和解压canal.deployer-1.1.4.tar.gz到虚拟机的/data/canal目录下,同时解压一份在本地开发机的磁盘中。演示直接使用example标识的Instance。修改虚拟机/data/canal/conf/example/instance.properties:
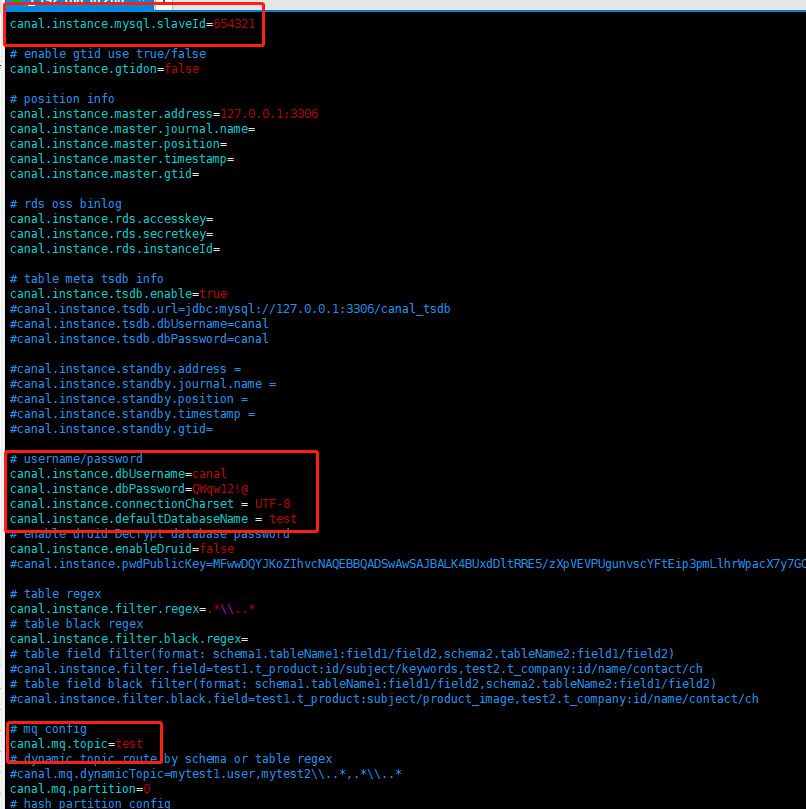
注意这里笔者把topic设置为和数据库的schema一致。其他细节项就不再进行展开,有兴趣可以看笔者之前写过的一篇文章《基于Canal和Kafka实现MySQL的Binlog近实时同步》,里面很详细地介绍了怎么部署一个可用的Canal单机服务,包括了MySQL、Zookeeper和Kafka的安装和使用。
同理,在开发机中的对应的配置文件中添加一模一样的配置项,但是canal.instance.mysql.slaveId配置项需要每个实例唯一,并且不能和主库的serverId冲突,例如:
# 虚拟机中的配置
canal.instance.mysql.slaveId=654321
# 开发机中的配置
canal.instance.mysql.slaveId=654322
然后修改虚拟机/data/canal/conf/canal.properties配置,修改项主要包括:
| Key | Value |
|---|---|
canal.zkServers |
填写Zookeeper集群的host:port,这里填写192.168.56.200:2181 |
canal.serverMode |
kafka |
canal.instance.global.spring.xml |
classpath:spring/default-instance.xml(一定要修改为此配置,基于Zookeeper的集群管理依赖于此配置) |
canal.mq.servers |
填写Kafka集群的host:port,这里填写192.168.56.200:9092 |
其他配置项可以按需修改。对于canal.properties,Canal多个集群节点可以完全一致,写好一份然后拷贝使用即可。接着可以分别启动两个Canal服务,一般来说,先启动的节点会成为running节点:
- 对于
Linux系统,可以使用命令sh $CANAL_HOME/bin/startup.sh启动Canal。 - 对于
Windows系统,直接挂起命令界面执行$CANAL_HOME/bin/startup.bat脚本即可。
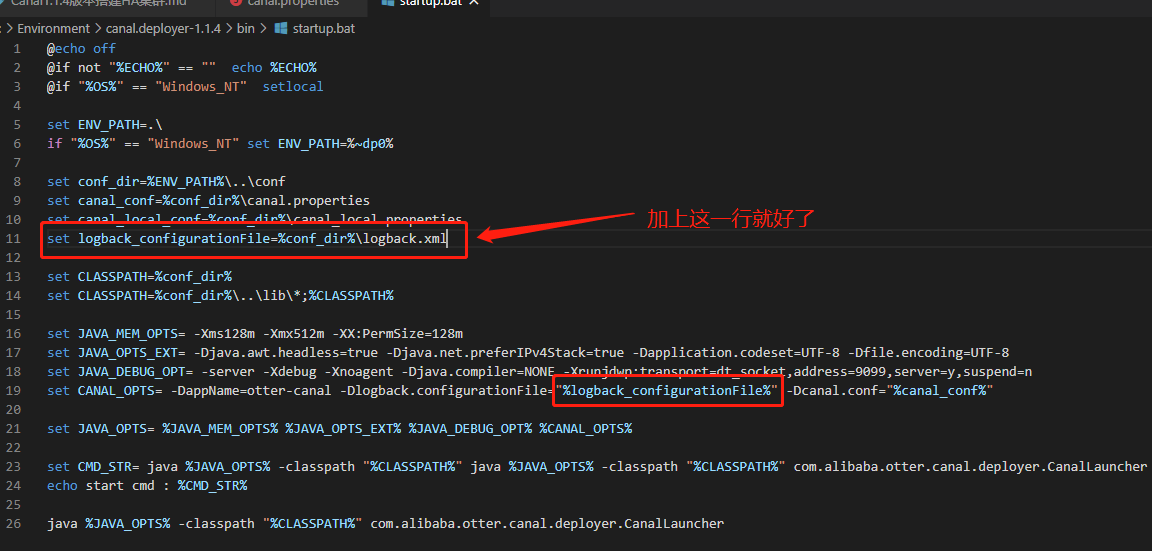
Windows启动如果控制台报错ch.qos.logback.core.LogbackException: Unexpected filename extension of file...,其实是因为脚本中的logback配置文件路径占位符的变量没有预先设置值,见下图:
Linux下的启动日志(example.log):

Windows下的启动日志(canal.log):

测试Canal高可用集群
先启动虚拟机中的Canal服务,再启动本地开发机中的Canal服务:
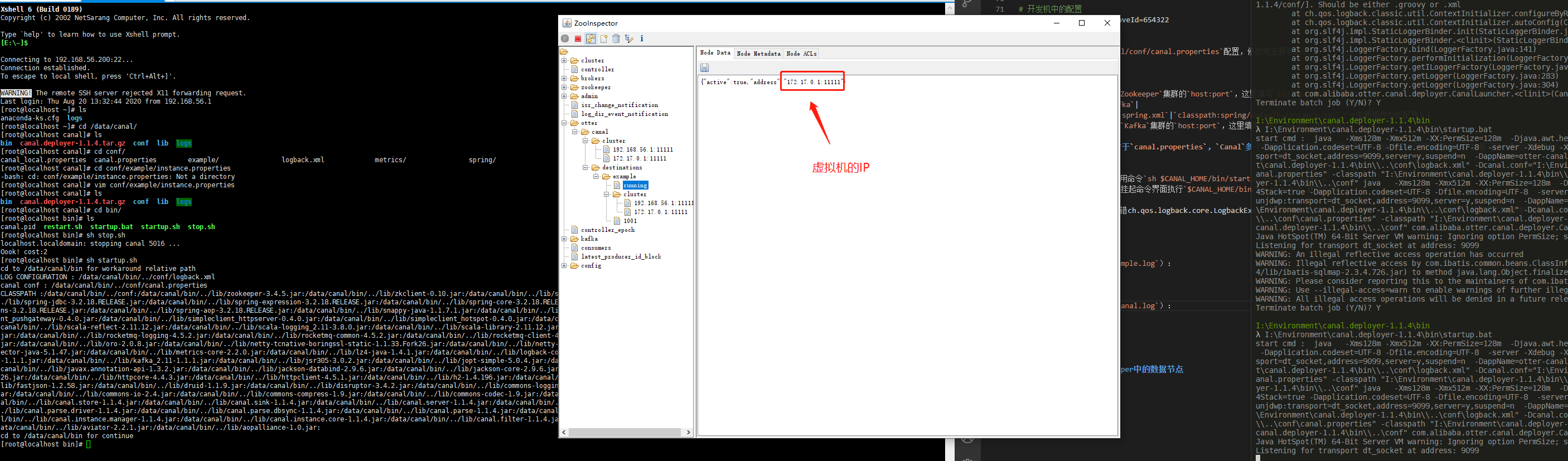
可见当前的cluster列表中包含了两个host:port,而running节点中的信息只包含虚拟机的host:port,意味着当前运行节点时虚拟机中的Canal服务,本地开发机中的Canal服务作为备用节点。此时可以尝试在虚拟机中执行sh stop.sh关闭Canal服务:
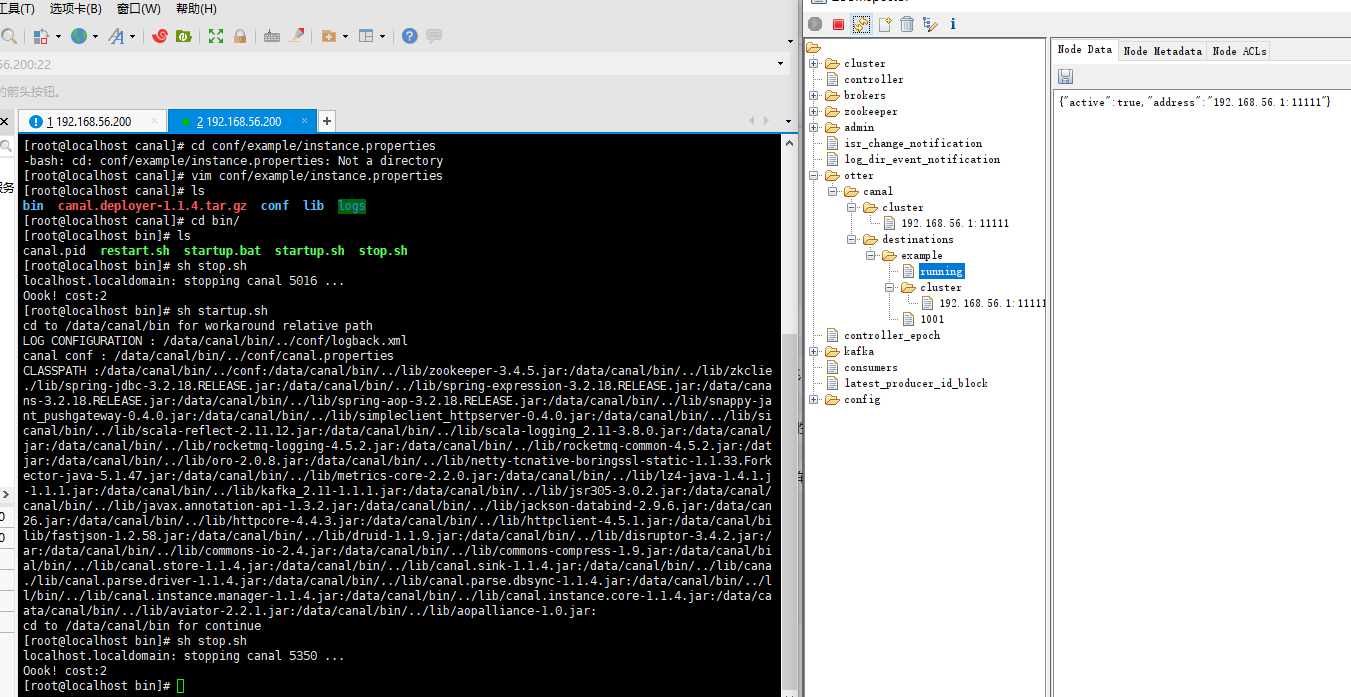
可见cluster列表只剩下本地开发机中的Canal服务的host:port,而running节点中的信息也是指向此服务信息。至此成功验证了Canal主备模式的切换。此时可以再验证一下开发机中的example.log:

说说Canal保存在Zookeeper中的数据节点
前文使用ZooInspector展示了Canal保存在Zookeeper中的节点信息,这里简单分析一下。节点树的结构如下:
| 节点路径 | 描述 |
|---|---|
/otter/canal |
根目录 |
/otter/canal/cluster |
Canal集群节点信息 |
/otter/canal/destinations |
Canal所有Instance的信息 |
/otter/canal/cluster路径的展开如下:
# 其实就是挂载了所有集群节点的host:port信息
/otter/canal/cluster
- 192.168.56.1:11111
- 172.17.0.1:11111
/otter/canal/destinations路径会相对复杂,展开的信息如下:
/otter/canal/destinations
- Instance标识
- running 记录当前为此Instance提供服务状态为running的Canal节点 [EPHEMERAL类型]
- cluster 记录当前为此Instance提供服务的Canal集群节点列表
- Client序号标识
- running 客户端当前正在读取的running节点 [EPHEMERAL类型]
- cluster 记录当前读取此Instance的客户端节点列表
- cursor 记录客户端读取的position信息
# 例如
/otter/canal/destinations
- example
- running -> {"active":true,"address":"192.168.56.1:11111"}
- cluster
- 192.168.56.1:11111
- 172.17.0.1:11111
- 1001
- running
- cluster
- cursor
理解各个路径存放的信息,有利于在Canal集群出现故障的时候结合日志进行故障排查。
小结
Canal集群已经在生产跑了一段时间,大部分的问题和坑都已经遇到过,有些问题通过了屏蔽某些开关解决,一些遗留无法解决的问题也想办法通过预警手段人工介入处理。Canal的HA其实是比较典型的主备模式,也就是同一个时刻,只有单个Canal服务对单个Instance(Destination)进行处理,想了下确实好像这样才能确保主备中继日志同步的基本有序,备用节点其实是完全划水不工作的(除了监听Zookeeper中的路径变更),一旦running节点出现故障或者宕机,备用节点就会提升为running节点,确保集群的可用性。
(本文完 c-3-d e-a-20200822)
Canalv1.1.4版本搭建HA集群的更多相关文章
- Hadoop集群搭建:用三台云服务器搭建HA集群(过程记录和分享)
该文主要记录了自己用云服务器搭建集群的过程,也分享一些自己遇到的问题和解决方法.里面可能提及一些自己的理解,可能不够准确,希望大家能够指正我,谢谢. 1.什么是HA集群 HA :High Availa ...
- hadoop搭建HA集群之后不能自动切换namenode
在搭好HA集群之后,想测试一下集群的高可用性,于是先把active的namenode给停掉: hadoop-daemon.sh stop namenode 或者直接kill掉该节点namenode的对 ...
- 基于Hadoop不同版本搭建hive集群(附配置文件)
本教程采用了两种方案 一种是hive-1.21版本,hadoop版本为hadoop2.6.5 还有一种是主要讲基于hadoop3.x hive的搭建 先来第一种 一.本地方式(内嵌derby) 步骤 ...
- ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群
Hadoop HA 原理概述 为什么会有 hadoop HA 机制呢? HA:High Available,高可用 在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SP ...
- 二进制搭建Kubernetes集群(最新v1.16.0版本)
目录 1.生产环境k8s平台架构 2.官方提供三种部署方式 3.服务器规划 4.系统初始化 5.Etcd集群部署 5.1.安装cfssl工具 5.2.生成etcd证书 5.2.1 创建用来生成 CA ...
- linux系统centOS7下搭建redis集群中ruby版本过低问题的解决方法
问题描述: 在Centos7中,通过yum安装ruby的版本是2.0.0,但是如果有些应用需要高版本的ruby环境,比如2.2,2.3,2.4... 那就有点麻烦了,譬如:我准备使用redis官方给的 ...
- hadoop HA集群搭建步骤
NameNode DataNode Zookeeper ZKFC JournalNode ResourceManager NodeManager node1 √ √ √ √ node2 ...
- 大数据-HBase HA集群搭建
1.下载对应版本的Hbase,在我们搭建的集群环境中选用的是hbase-1.4.6 将下载完成的hbase压缩包放到对应的目录下,此处我们的目录为/opt/workspace/ 2.对已经有的压缩包进 ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
随机推荐
- 洛谷3月月赛div2 题解(模拟+数学+贪心+数学)
由于本人太蒻了,div1的没有参加,胡乱写了写div2的代码就赶过来了. T1 苏联人 题目背景 题目名称是吸引你点进来的. 这是一道正常的题,和苏联没有任何关系. 题目描述 你在打 EE Round ...
- python3.4嵌套循环项目:买房分期付款(1)
#案例:买房分期付款24万(10年期限) i=1#定义年份sum1=0while i<=10: print("第",i,"年到了......") j=1# ...
- 通过java程序(JSch)运行远程linux主机上的shell脚本
如果您看完文章之后,觉得对您有帮助,请帮我点个赞,您的支持是我不竭的创作动力! 如果您看完文章之后,觉得对您有帮助,请帮我点个赞,您的支持是我不竭的创作动力! 如果您看完文章之后,觉得对您有帮助,请帮 ...
- 痞子衡嵌入式:一种i.MXRT下从App中进入ROM串行下载模式的方法
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是i.MXRT下在App中利用ROM API进ISP/SDP模式的方法. 我们知道i.MXRT系列分为两大阵营:CM33内核的i.MXRT ...
- Nginx定时日志切割
Nginx定时日志切割 现有的日志都会存在access.log文件中,但是随着时间的推移,这个文件的内容会越来越多,体积会越来越大,不便于运维 人员查看,所以我们可以通过把这个大的日志文件切割为多份不 ...
- C#LeetCode刷题之#62-不同路径(Unique Paths)
目录 问题 示例 分析 问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3680 访问. 一个机器人位于一个 m x ...
- 设计模式:原型模式介绍 && 原型模式的深拷贝问题
0.背景 克隆羊问题:有一个羊,是一个类,有对应的属性,要求创建完全一样的10只羊出来. 那么实现起来很简单,我们先写出羊的类: public class Sheep { private String ...
- Mybatis-06-Lombok
偷懒神器Lombok 1. 什么是Lombok? java library plugs build tools 2.使用步骤: 在IDEA中安装Lombok插件 在项目中导入lombok的jar包 ...
- SVN的基本使用
2020年7月6日 为什么需要版本控制? 需要清晰地保存某些文件的不同修订版本 控制文件的发屐过程,找出导致 BUG 的原因 轻松将项目或文件恢复到指定版本 极大方便团队之间协同开发,防止出现混乱 在 ...
- 【期外】 (一)关于LSH :局部敏感哈希算法
LSH是我同学的名字,平时我会亲切的称呼他为离骚,老师好,左移(leftshift),小骚骚之类的,最近他又多了一个新的外号:局部敏感哈希(Locally sensitive hashing). 好了 ...