Prometheus时序数据库-数据的查询
Prometheus时序数据库-数据的查询
前言
在之前的博客里,笔者详细阐述了Prometheus数据的插入过程。但我们最常见的打交道的是数据的查询。Prometheus提供了强大的Promql来满足我们千变万化的查询需求。在这篇文章里面,笔者就以一个简单的Promql为例,讲述下Prometheus查询的过程。
Promql
一个Promql表达式可以计算为下面四种类型:
瞬时向量(Instant Vector) - 一组同样时间戳的时间序列(取自不同的时间序列,例如不同机器同一时间的CPU idle)
区间向量(Range vector) - 一组在一段时间范围内的时间序列
标量(Scalar) - 一个浮点型的数据值
字符串(String) - 一个简单的字符串
我们还可以在Promql中使用svm/avg等集合表达式,不过只能用在瞬时向量(Instant Vector)上面。为了阐述Prometheus的聚合计算以及篇幅原因,笔者在本篇文章只详细分析瞬时向量(Instant Vector)的执行过程。
瞬时向量(Instant Vector)
前面说到,瞬时向量是一组拥有同样时间戳的时间序列。但是实际过程中,我们对不同Endpoint采样的时间是不可能精确一致的。所以,Prometheus采取了距离指定时间戳之前最近的数据(Sample)。如下图所示:
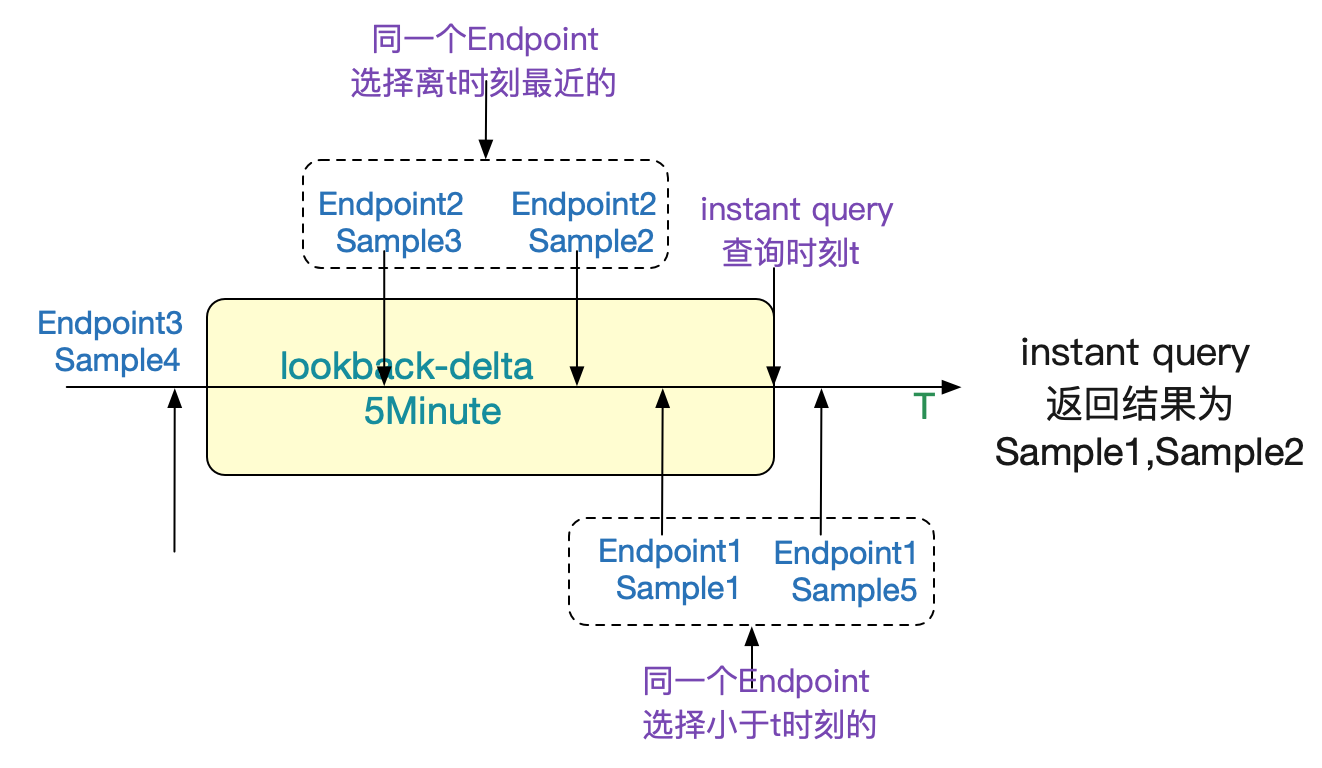
当然,如果是距离当前时间戳1个小时的数据直观看来肯定不能纳入到我们的返回结果里面。
所以Prometheus通过一个指定的时间窗口来过滤数据(通过启动参数--query.lookback-delta指定,默认5min)。
对一条简单的Promql进行分析
好了,解释完Instant Vector概念之后,我们可以着手进行分析了。直接上一条带有聚合函数的Promql把。
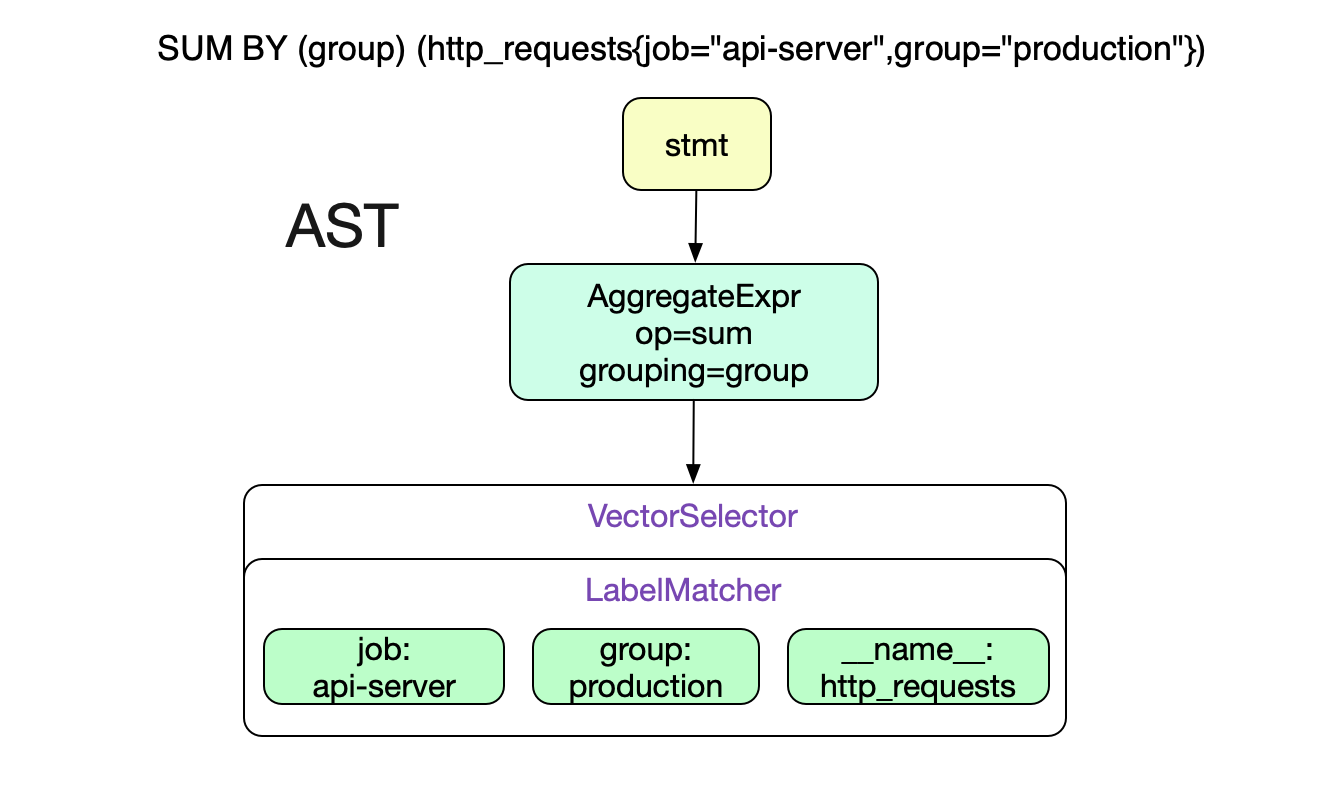
SUM BY (group) (http_requests{job="api-server",group="production"})
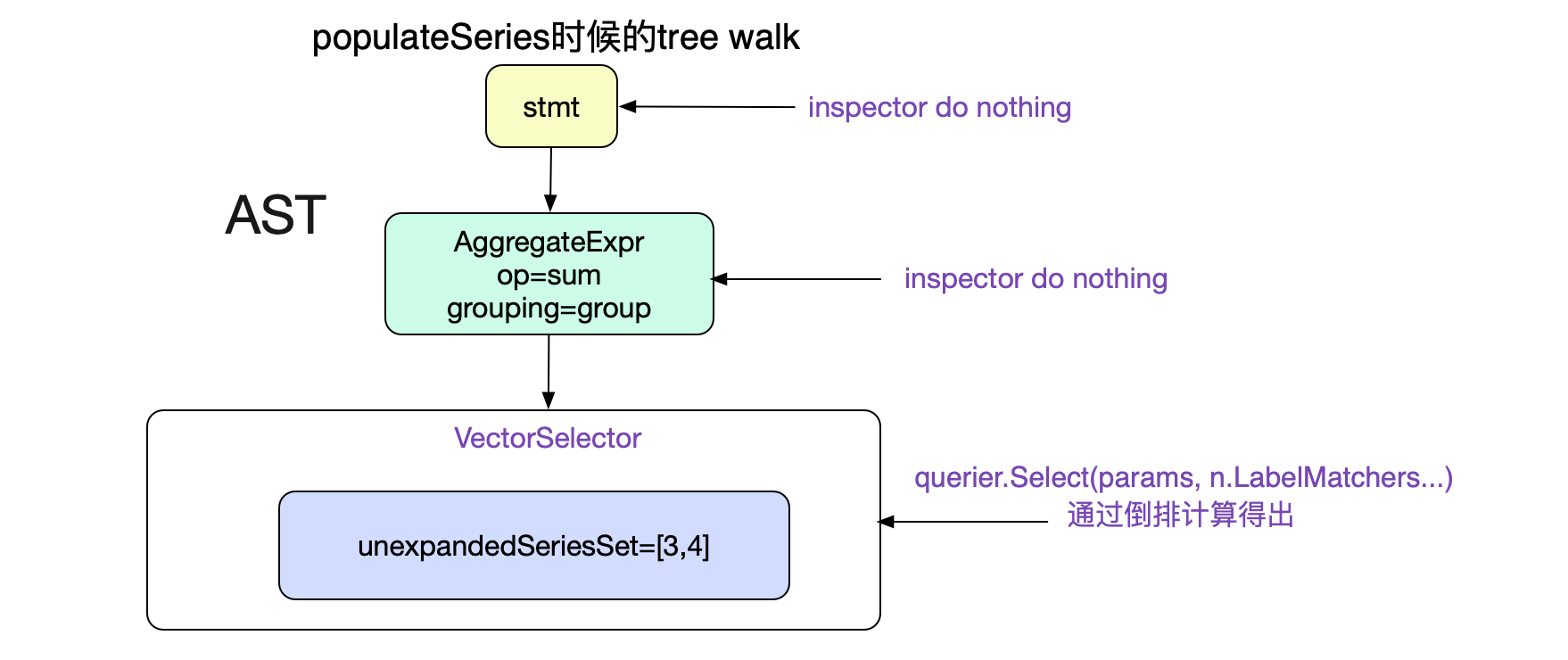
首先,对于这种有语法结构的语句肯定是将其Parse一把,构造成AST树了。调用
promql.ParseExpr
由于Promql较为简单,所以Prometheus直接采用了LL语法分析。在这里直接给出上述Promql的AST树结构。
Prometheus对于语法树的遍历过程都是通过vistor模式,具体到代码为:
ast.go vistor设计模式
func Walk(v Visitor, node Node, path []Node) error {
var err error
if v, err = v.Visit(node, path); v == nil || err != nil {
return err
}
path = append(path, node)
for _, e := range Children(node) {
if err := Walk(v, e, path); err != nil {
return err
}
}
_, err = v.Visit(nil, nil)
return err
}
func (f inspector) Visit(node Node, path []Node) (Visitor, error) {
if err := f(node, path); err != nil {
return nil, err
}
return f, nil
}
通过golang里非常方便的函数式功能,直接传递求值函数inspector进行不同情况下的求值。
type inspector func(Node, []Node) error
求值过程
具体的求值过程核心函数为:
func (ng *Engine) execEvalStmt(ctx context.Context, query *query, s *EvalStmt) (Value, storage.Warnings, error) {
......
querier, warnings, err := ng.populateSeries(ctxPrepare, query.queryable, s) // 这边拿到对应序列的数据
......
val, err := evaluator.Eval(s.Expr) // here 聚合计算
......
}
populateSeries
首先通过populateSeries的计算出VectorSelector Node所对应的series(时间序列)。这里直接给出求值函数
func(node Node, path []Node) error {
......
querier, err := q.Querier(ctx, timestamp.FromTime(mint), timestamp.FromTime(s.End))
......
case *VectorSelector:
.......
set, wrn, err = querier.Select(params, n.LabelMatchers...)
......
n.unexpandedSeriesSet = set
......
case *MatrixSelector:
......
}
return nil
可以看到这个求值函数,只对VectorSelector/MatrixSelector进行操作,针对我们的Promql也就是只对叶子节点VectorSelector有效。
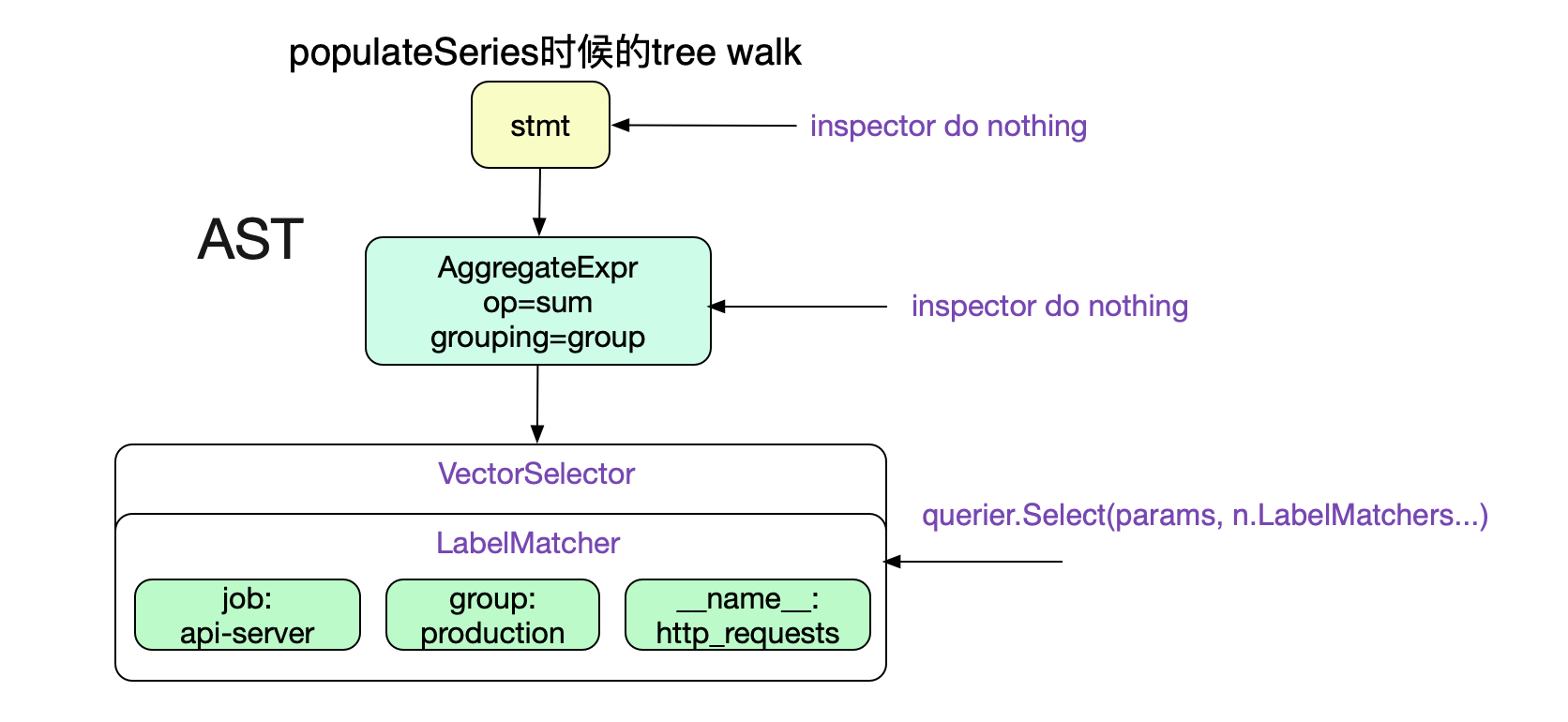
select
获取对应数据的核心函数就在querier.Select。我们先来看下qurier是如何得到的.
querier, err := q.Querier(ctx, timestamp.FromTime(mint), timestamp.FromTime(s.End))
根据时间戳范围去生成querier,里面最重要的就是计算出哪些block在这个时间范围内,并将他们附着到querier里面。具体见函数
func (db *DB) Querier(mint, maxt int64) (Querier, error) {
for _, b := range db.blocks {
......
// 遍历blocks挑选block
}
// 如果maxt>head.mint(即内存中的block),那么也加入到里面querier里面。
if maxt >= db.head.MinTime() {
blocks = append(blocks, &rangeHead{
head: db.head,
mint: mint,
maxt: maxt,
})
}
......
}

知道数据在哪些block里面,我们就可以着手进行计算VectorSelector的数据了。
// labelMatchers {job:api-server} {__name__:http_requests} {group:production}
querier.Select(params, n.LabelMatchers...)
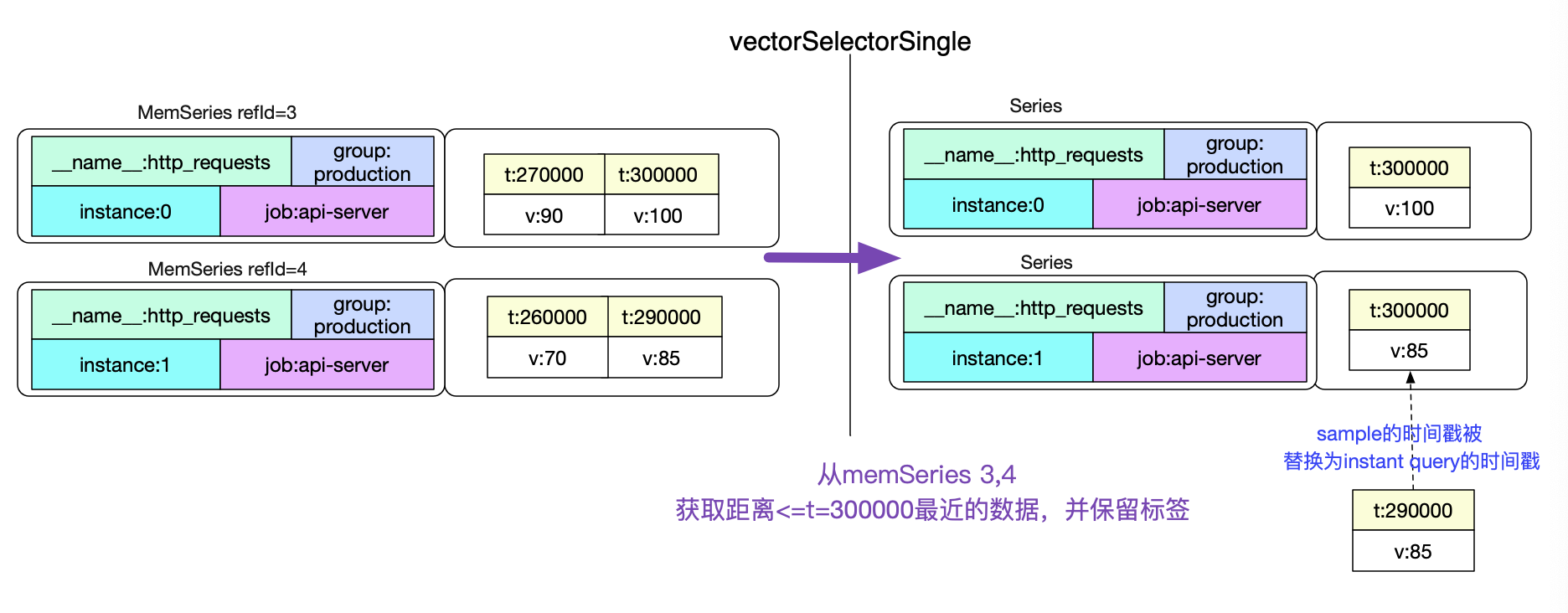
有了matchers我们很容易的就能够通过倒排索引取到对应的series。为了篇幅起见,我们假设数据都在headBlock(也就是内存里面)。那么我们对于倒排的计算就如下图所示:
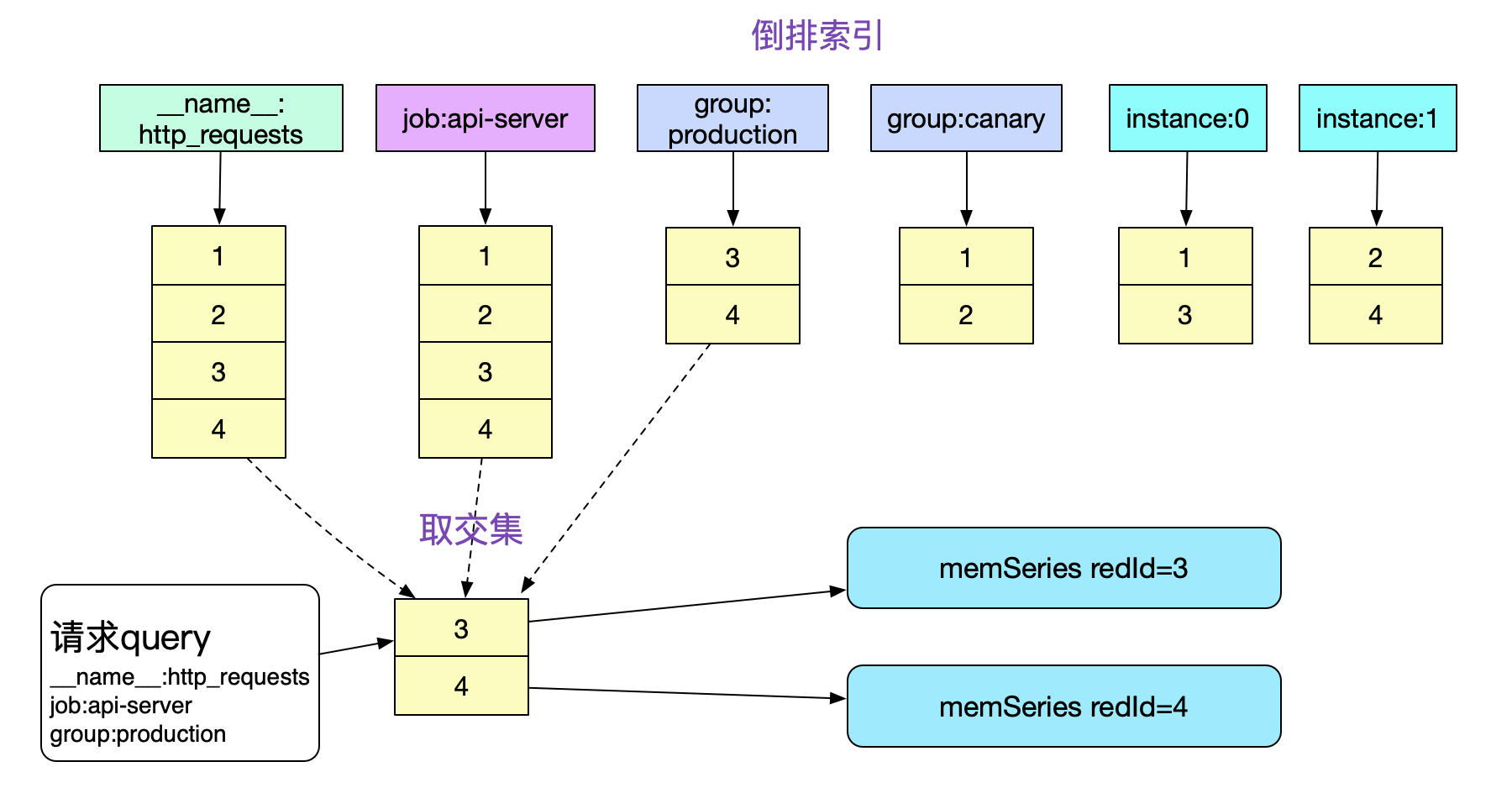
这样,我们的VectorSelector节点就已经有了最终的数据存储地址信息了,例如图中的memSeries refId=3和4。
如果想了解在磁盘中的数据寻址,可以详见笔者之前的博客
<<Prometheus时序数据库-磁盘中的存储结构>>
evaluator.Eval
通过populateSeries找到对应的数据,那么我们就可以通过evaluator.Eval获取最终的结果了。计算采用后序遍历,等下层节点返回数据后才开始上层节点的计算。那么很自然的,我们先计算VectorSelector。
func (ev *evaluator) eval(expr Expr) Value {
......
case *VectorSelector:
// 通过refId拿到对应的Series
checkForSeriesSetExpansion(ev.ctx, e)
// 遍历所有的series
for i, s := range e.series {
// 由于我们这边考虑的是instant query,所以只循环一次
for ts := ev.startTimestamp; ts <= ev.endTimestamp; ts += ev.interval {
// 获取距离ts最近且小于ts的最近的sample
_, v, ok := ev.vectorSelectorSingle(it, e, ts)
if ok {
if ev.currentSamples < ev.maxSamples {
// 注意,这边的v对应的原始t被替换成了ts,也就是instant query timeStamp
ss.Points = append(ss.Points, Point{V: v, T: ts})
ev.currentSamples++
} else {
ev.error(ErrTooManySamples(env))
}
}
......
}
}
}
如代码注释中看到,当我们找到一个距离ts最近切小于ts的sample时候,只用这个sample的value,其时间戳则用ts(Instant Query指定的时间戳)代替。
其中vectorSelectorSingle值得我们观察一下:
func (ev *evaluator) vectorSelectorSingle(it *storage.BufferedSeriesIterator, node *VectorSelector, ts int64) (int64, float64, bool){
......
// 这一步是获取>=refTime的数据,也就是我们instant query传入的
ok := it.Seek(refTime)
......
if !ok || t > refTime {
// 由于我们需要的是<=refTime的数据,所以这边回退一格,由于同一memSeries同一时间的数据只有一条,所以回退的数据肯定是<=refTime的
t, v, ok = it.PeekBack(1)
if !ok || t < refTime-durationMilliseconds(LookbackDelta) {
return 0, 0, false
}
}
}
就这样,我们找到了series 3和4距离Instant Query时间最近且小于这个时间的两条记录,并保留了记录的标签。这样,我们就可以在上层进行聚合。
SUM by聚合
叶子节点VectorSelector得到了对应的数据后,我们就可以对上层节点AggregateExpr进行聚合计算了。代码栈为:
evaluator.rangeEval
|->evaluate.eval.func2
|->evelator.aggregation grouping key为group
具体的函数如下图所示:
func (ev *evaluator) aggregation(op ItemType, grouping []string, without bool, param interface{}, vec Vector, enh *EvalNodeHelper) Vector {
......
// 对所有的sample
for _, s := range vec {
metric := s.Metric
......
group, ok := result[groupingKey]
// 如果此group不存在,则新加一个group
if !ok {
......
result[groupingKey] = &groupedAggregation{
labels: m, // 在这里我们的m=[group:production]
value: s.V,
mean: s.V,
groupCount: 1,
}
......
}
switch op {
// 这边就是对SUM的最终处理
case SUM:
group.value += s.V
.....
}
}
.....
for _, aggr := range result {
enh.out = append(enh.out, Sample{
Metric: aggr.labels,
Point: Point{V: aggr.value},
})
}
......
return enh.out
}
好了,有了上面的处理,我们聚合的结果就变为:
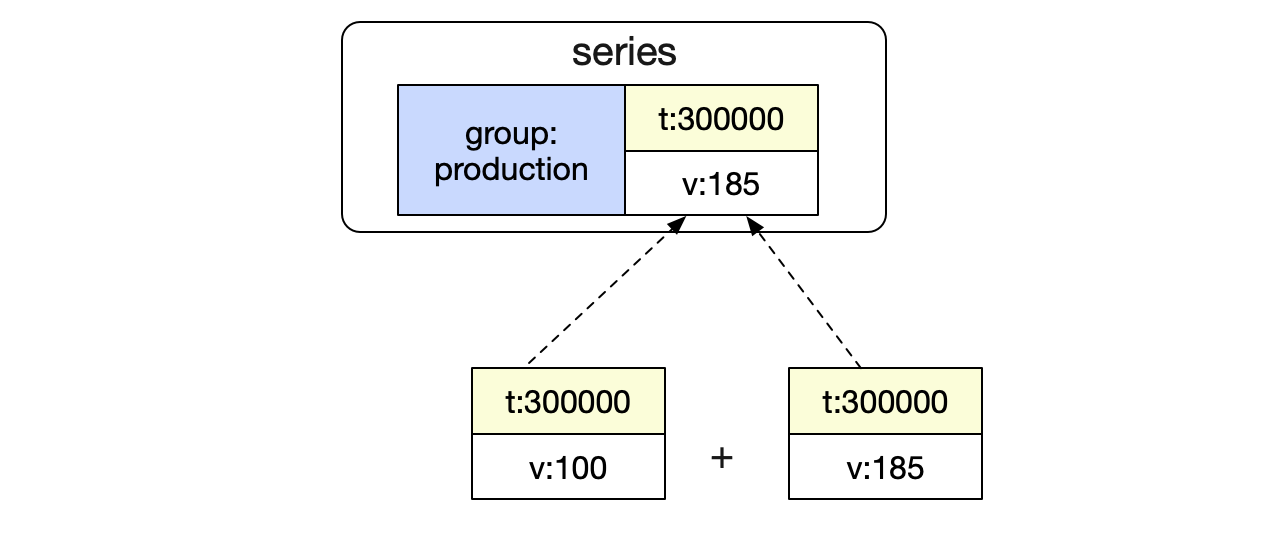
这个和我们的预期结果一致,一次查询的过程就到此结束了。
总结
Promql是非常强大的,可以满足我们的各种需求。其运行原理自然也激起了笔者的好奇心,本篇文章虽然只分析了一条简单的Promql,但万变不离其宗,任何Promql都是类似的运行逻辑。希望本文对读者能有所帮助。

Prometheus时序数据库-数据的查询的更多相关文章
- Prometheus时序数据库-数据的插入
Prometheus时序数据库-数据的插入 前言 在之前的文章里,笔者详细的阐述了Prometheus时序数据库在内存和磁盘中的存储结构.有了前面的铺垫,笔者就可以在本篇文章阐述下数据的插入过程. 监 ...
- Prometheus时序数据库-报警的计算
Prometheus时序数据库-报警的计算 在前面的文章中,笔者详细的阐述了Prometheus的数据插入存储查询等过程.但作为一个监控神器,报警计算功能是必不可少的.自然的Prometheus也提供 ...
- Prometheus时序数据库-内存中的存储结构
Prometheus时序数据库-内存中的存储结构 前言 笔者最近担起了公司监控的重任,而当前监控最流行的数据库即是Prometheus.按照笔者打破砂锅问到底的精神,自然要把这个开源组件源码搞明白才行 ...
- Prometheus时序数据库-磁盘中的存储结构
Prometheus时序数据库-磁盘中的存储结构 前言 之前的文章里,笔者详细描述了监控数据在Prometheus内存中的结构.而其在磁盘中的存储结构,也是非常有意思的,关于这部分内容,将在本篇文章进 ...
- MySQL数据库 | 数据表-查询命令详细记录
本篇专门记录数据库增删改查中最常用.花招最多的 查. [文章结构] 一.数据的准备 二.基本的查询功能 三.条件查询 四.查询排序 五.聚合函数 六.分组查询 七.分页查询 八.连接查询 九.子查询 ...
- webform中实现SQL Sever2008数据库数据分页查询
1 分页 1.1 数据库中存储过程 已知 当前页 pageIndex 页容量 pageSize 求 总页数 pageCou ...
- 时序数据库技术体系 – 初识InfluxDB(原理)
原贴地址:http://hbasefly.com/2017/12/08/influxdb-1/?qytefg=c4ft23 在上篇文章<时序数据库体系技术 – 时序数据存储模型设计>中笔者 ...
- [转帖]时序数据库技术体系(二):初识InfluxDB
时序数据库技术体系(二):初识InfluxDB https://sq.163yun.com/blog/article/169866295296581632 把生命浪费在美好事物上2018-06-26 ...
- 时序数据库连载系列:指标届的独角兽Prometheus
简介 Prometheus是SoundCloud公司开发的一站式监控告警平台,依赖少,功能齐全.于2016年加入CNCF,广泛用于 Kubernetes集群的监控系统中,2018.8月成为继K8S之后 ...
随机推荐
- 数据分析常用库(numpy,pandas,matplotlib,scipy)
概述 numpy numpy(numeric python)是 python 的一个开源数值计算库,主要用于数组和矩阵计算.底层是 C 语言,运行效率远高于纯 python 代码.numpy主要包含2 ...
- 关于TCP和UDP的通俗理解
TCP和UDP是网络基础,很多公司面试也都会问到,今天我在这里,根据大神们的讲解,自己总结借鉴一下. 首先,先提一个问题:英雄联盟是TCP还是UDP? 这个问题对于游戏玩家,可能大多数人都没有想过.一 ...
- matplotlib 单figure多图
method 1 import numpy as np import matplotlib.pyplot as plt fg, axes = plt.subplots(1, 2, figsize=(1 ...
- CDN 工作原理剖析
CDN 工作原理剖析 CDN / Content Delivery Network / 内容分发网络 https://www.cloudflare.com/zh-cn/learning/cdn/wha ...
- 经济学,金融学:资产证券化 ABS
经济学,金融学:资产证券化 ABS ABS 资产支持证券 蚂蚁金服如何把30亿变成3000亿?资产证券化 前几天,花呗借呗的东家蚂蚁集团在上市前夕被监管部门叫停,因为这则新闻广大网民都听说了一个概念: ...
- how to publish a UMD module
how to publish a UMD module 如何发布UMD模块 npm https://github.com/xgqfrms/umd-npm-package https://www.npm ...
- css 设置多行文本的行间距
css 设置多行文本的行间距 block element span .ticket-card-info{ line-height:16px; display: inline-block; } .tic ...
- Python 股票市场分析实战
目标: 1.股票数据获取 2.历史趋势分析及可视化 3.风险分析 实验数据:来源于Yahoo Finance / Stooq,该网站提供了很多API接口,本文用的工具是pandas-datareade ...
- bluestein算法
我们熟知的FFT算法实际上是将一个多项式在2n个单位根处展开,将其点值对应相乘,并进行逆变换.然而,由于单位根具有"旋转"的特征(即$w_{m}^{j}=w_{m}^{j+m}$) ...
- list.add(int index, E element)和list.addAll(list1)
List.add(int index, E element): 在列表的指定位置插入指定元素(可选操作).将当前处于该位置的元素(如果有的话)和所有后续元素向右移动(在其索引中加 1). 参数:ind ...