日志框架(Log4J、SLF4J、Logback)--日志规范与实践
文章目录
部分内容原文地址:
博客园:鸡员外:五年Java经验,面试还是说不出日志该怎么写更好?——日志规范与最佳实践篇
- 运维人员 整个系统大部分时间都是运维人员来维护,日志可以帮助运维人员来了解系统状态(很多运维系统接入的也是日志),运维人员发现日志有异常信息也可以及时通知开发来排查
- 运营人员 运营人员,比如电商的转化率、视频网站的完播率、普通PV数据等都可以通过日志进行统计,随着大数据技术的普及,这部分日志占比也越来越高
日志有几种?
- 调试日志 用于开发人员开发或者线上回溯问题。
- 诊断日志 一般用于运维人员监控系统与安全人员分析预警。
- 埋点日志 一般用于运营决策分析,也有用作微服务调用链路追踪的(运维、调试)。
- 审计日志 与诊断日志类似,诊断日志偏向运维,审计日志偏向安全。
日志都需要输出什么?
- 调试日志
- DEBUG 或者 TRACE 级别,比如方法调用参数,网络连接具体信息,一般是开发者调试程序使用,线上非特殊情况关闭这些日志
- INFO 级别,一般是比较重要却没有风险的信息,如初始化环境、参数,清理环境,定时任务执行,远程调用第一次连接成功
- WARN 级别,有可能有风险又不影响系统继续执行的错误,比如系统参数配置不正确,用户请求的参数不正确(要输出具体参数方便排查),或者某些耗性能的场景,比如一次请求执行太久、一条sql执行超过两秒,某些第三方调用失败,不太可能被运行的if分支等
- ERROR 级别,用于程序出错打印堆栈信息,不应该用于输出程序问题之外的其他信息,需要注意打印了日志异常(Exception)就不应该抛(throw)了
- 诊断日志 一般输出 INFO 级别,请求响应时间,内存占用等等,线上接入监控系统时打开,建议输出到独立的文件,可以考虑 JSON 格式方便外部工具分析
- 埋点日志 业务按需定制,比如上文提到的转化率可以在用户付款时输出日志,完播率可以在用户播放完成后请求一次后台输出日志,一般可输出 INFO 级别,建议输出到独立的文件,可以考虑JSON格式方便外部工具分析
- 审计日志 大多 WARN 级别或者 INFO 级别,一般是敏感操作即可输出,登陆、转账付款、授权消权、删除等等,建议输出到独立的文件,可以考虑JSON格式方便外部工具分析
一般调试日志由开发者自定义输出,其他三种应该根据实际业务需求来定制。
日志的其他注意点
- 线上日志应尽量谨慎,要思考:这个位置输出日志能帮助排除问题吗?输出的信息与排查问题相关吗?输出的信息足够排除问题吗?做到不少输出必要信息,不多输出无用信息(拖慢系统,淹没有用信息)
- 超级 SessionId 与 RequestId,无论是单体应用还是微服务架构,应该为每个用户每次登陆生成一个超级SessionId,方便跟踪区分一个用户;RequestId,每次请求生成一个RequestId,用于跟踪一次请求,微服务也可以用于链路追踪
- 日志要尽量单行输出,一条日志输出一行,否则不方便阅读以及其他第三方系统或者工具分析
- 公司内部应该制定一套通用的日志规范,包括日志的格式,变量名(驼峰、下划线),分隔符(“=”或“:”等),何时输出(比如规定调用第三方前后输出INFO日志),公司的日志规范应该不断优化、调整,找到适合公司业务的最佳规范
一、Log4j
1.1新建一个Java工程,导入Log4j包,pom文件中对应的配置代码如下:
<!-- log4j support -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
1.2resources目录下创建log4j.properties文件。
### 设置###
log4j.rootLogger = debug,stdout,D,E
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
### 输出DEBUG 级别以上的日志到=/home/duqi/logs/debug.log ###
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = /home/duqi/logs/debug.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
### 输出ERROR 级别以上的日志到=/home/admin/logs/error.log ###
log4j.appender.E = org.apache.log4j.DailyRollingFileAppender
log4j.appender.E.File =/home/admin/logs/error.log
log4j.appender.E.Append = true
log4j.appender.E.Threshold = ERROR
log4j.appender.E.layout = org.apache.log4j.PatternLayout
log4j.appender.E.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
1.3输出日志
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Log4JTest {
private static final Logger logger = LoggerFactory.getLogger(Log4JTest.class);
public static void main(String[] args) {
// 记录debug级别的信息
logger.debug("This is debug message.");
// 记录info级别的信息
logger.info("This is info message.");
// 记录error级别的信息
logger.error("This is error message.");
}
}
1.4控制台查看输出结果。
然后可以再/Users/duqi/logs目录下的debug.log和error.log文件中查看信息。
二、Log4J基本使用方法
Log4j由三个重要的组件构成:日志信息的优先级,日志信息的输出目的地,日志信息的输出格式。日志信息的优先级从高到低有ERROR、WARN、 INFO、DEBUG,分别用来指定这条日志信息的重要程度;日志信息的输出目的地指定了日志将打印到控制台还是文件中;而输出格式则控制了日志信息的显 示内容。
2.1 定义配置文件
也可以完全不使用配置文件,而是在代码中配置Log4j环境。但是,使用配置文件将使您的应用程序更加灵活。Log4j支持两种配置文件格式,一种是XML格式的文件,一种是Java特性文件(键=值)。下面我们介绍使用Java特性文件做为配置文件的方法:
1:配置根Logger,其语法为:
log4j.rootLogger = [ level ] , appenderName, appenderName, …
其中,level 是日志记录的优先级,分为OFF、FATAL、ERROR、WARN、INFO、DEBUG、ALL或者您定义的级别。Log4j建议只使用四个级别,优 先级从高到低分别是ERROR、WARN、INFO、DEBUG。通过在这里定义的级别,您可以控制到应用程序中相应级别的日志信息的开关。比如在这里定 义了INFO级别,则应用程序中所有DEBUG级别的日志信息将不被打印出来。 appenderName就是指把日志信息输出到哪个地方。您可以同时指定多个输出目的地,例如上述例子我们制定了stdout、D和E这三个地方。
2:配置文件的输出目的地Appender,一般,配置代码的格式如下。
log4j.appender.appenderName = fully.qualified.name.of.appender.class
log4j.appender.appenderName.option1 = value1
…
log4j.appender.appenderName.option = valueN
其中,Log4j提供的appender有以下几种:
- org.apache.log4j.ConsoleAppender(控制台),
- org.apache.log4j.FileAppender(文件),
- org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件),
- org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件),
- org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
3:配置日志信息的格式(布局),其语法为:
log4j.appender.appenderName.layout = fully.qualified.name.of.layout.class
log4j.appender.appenderName.layout.option1 = value1
…
log4j.appender.appenderName.layout.option = valueN
其中,Log4j提供的layout有以下几种:
- org.apache.log4j.HTMLLayout(以HTML表格形式布局),
- org.apache.log4j.PatternLayout(可以灵活地指定布局模式),
- rg.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
- org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
Log4J采用类似C语言中的printf函数的打印格式格式化日志信息,打印参数如下:
- %m 输出代码中指定的消息
- %p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL
- %r 输出自应用启动到输出该log信息耗费的毫秒数
- %c 输出所属的类目,通常就是所在类的全名
- %t 输出产生该日志事件的线程名
- %n 输出一个回车换行符,Windows平台为“rn”,Unix平台为“n”
- %d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
- %l 输出日志事件的发生位置,包括类目名、发生的线程,以及在代码中的行数。举例:Testlog4.main(TestLog4.java:10)
2.2 在代码中使用Log4j
1:获取记录器。
使用Log4j,第一步就是获取日志记录器,这个记录器将负责控制日志信息。其语法为:public static Logger getLogger( String name);通过指定的名字获得记录器,如果必要的话,则为这个名字创建一个新的记录器。Name一般取本类的名字,比如:static Logger logger = Logger.getLogger ( ServerWithLog4j.class.getName () )。
2:读取配置文件
当获得了日志记录器之后,第二步将配置Log4j环境,其语法为:
BasicConfigurator.configure (): 自动快速地使用缺省Log4j环境。
PropertyConfigurator.configure ( String configFilename) :读取使用Java的特性文件编写的配置文件。
DOMConfigurator.configure ( String filename ) :读取XML形式的配置文件。
3:插入记录信息(格式化日志信息)
当上两个必要步骤执行完毕,您就可以轻松地使用不同优先级别的日志记录语句插入到您想记录日志的任何地方,其语法如下:
Logger.debug ( Object message ) ;
Logger.info ( Object message ) ;
Logger.warn ( Object message ) ;
Logger.error ( Object message ) ;
2.3 日志级别
每个Logger都被了一个日志级别(log level),用来控制日志信息的输出。日志级别从高到低分为:
- A:off 最高等级,用于关闭所有日志记录。
- B:fatal 指出每个严重的错误事件将会导致应用程序的退出。
- C:error 指出虽然发生错误事件,但仍然不影响系统的继续运行。
- D:warm 表明会出现潜在的错误情形。
- E:info 一般和在粗粒度级别上,强调应用程序的运行全程。
- F:debug 一般用于细粒度级别上,对调试应用程序非常有帮助。
- G:all 最低等级,用于打开所有日志记录。
上面这些级别是定义在org.apache.log4j.Level类中。Log4j只建议使用4个级别,优先级从高到低分别是error,warn,info和debug。通过使用日志级别,可以控制应用程序中相应级别日志信息的输出。例如,如果使用b了info级别,则应用程序中所有低于info级别的日志信息(如debug)将不会被打印出来。
三、Spring中使用Log4j
一般是在web.xml配置文件中配置Log4j监听器和log4j.properties文件,代码如下:
<context-param>
<param-name>log4jConfigLocation</param-name>
<param-value>classpath:/config/log4j.properties</param-value>
</context-param>
<context-param>
<param-name>log4jRefreshInterval</param-name>
<param-value>60000</param-value>
</context-param>
<listener>
<listener-class>org.springframework.web.util.Log4jConfigListener</listener-class>
</listener>
四、Commons Logging
common-logging是apache提供的一个通用的日志接口,
在common-logging中,有一个Simple logger的简单实现,但是它功能很弱,所以使用common-logging,通常都是配合着log4j来使用;
Commons Logging定义了一个自己的接口 org.apache.commons.logging.Log,以屏蔽不同日志框架的API差异,这里用到了Adapter Pattern(适配器模式)。
五、SLF4J
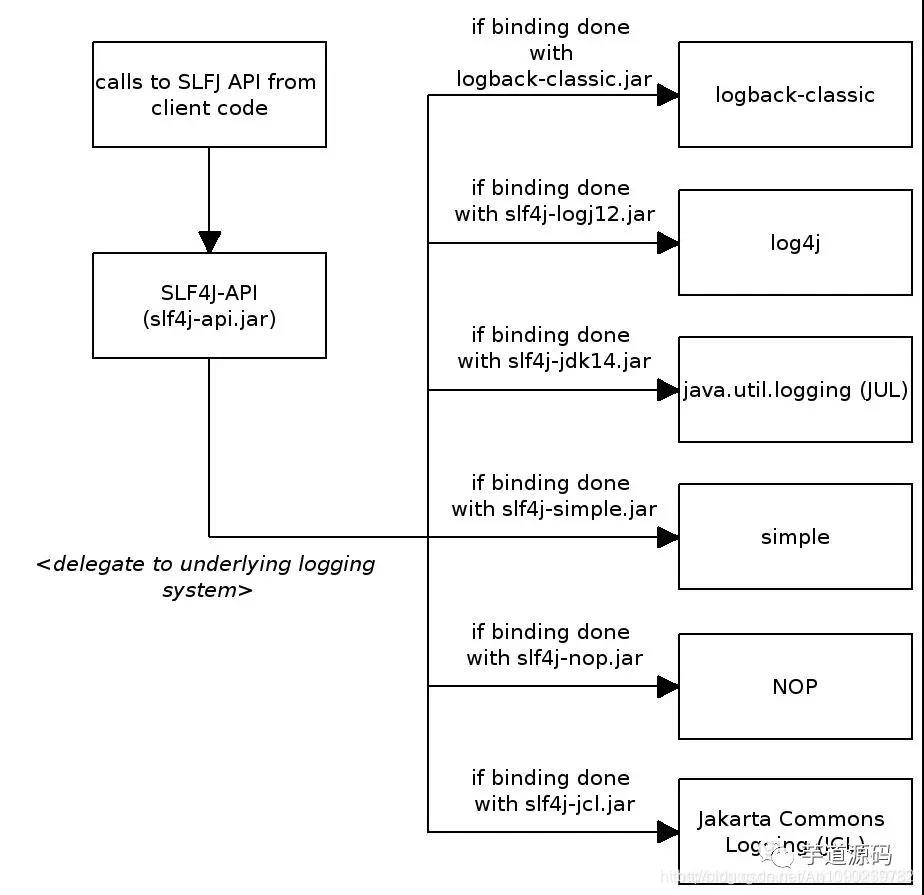
Simple Logging Facade for Java(SLF4J)用作各种日志框架(例如java.util.logging,logback,log4j)的简单外观或抽象,允许最终用户在部署时插入所需的日志框架。
要切换日志框架,只需替换类路径上的slf4j绑定。 例如,要从java.util.logging切换到log4j,只需将slf4j-jdk14-1.8.0-beta2.jar替换为slf4j-log4j12-1.8.0-beta2.jar
SLF4J不依赖于任何特殊的类装载机制。 实际上,每个SLF4J绑定在编译时都是硬连线的,以使用一个且只有一个特定的日志记录框架。 例如,slf4j-log4j12-1.8.0-beta2.jar绑定在编译时绑定以使用log4j。 在您的代码中,除了slf4j-api-1.8.0-beta2.jar之外,您只需将您选择的一个且只有一个绑定放到相应的类路径位置。 不要在类路径上放置多个绑定。
以下是slf4j 绑定其它日志组件的图解说明。

因此,slf4j 就是众多日志接口的集合,他不负责具体的日志实现,只在编译时负责寻找合适的日志系统进行绑定。具体有哪些接口,全部都定义在slf4j-api中。查看slf4j-api源码就可以发现,里面除了public final class LoggerFactory类之外,都是接口定义。因此,slf4j-api本质就是一个接口定义。
总之,Slf4j更好的兼容了各种具体日志实现的框架,如图:
六、Log4j2
Apache Log4j 2是对Log4j的升级,它比其前身Log4j 1.x提供了重大改进,并提供了Logback中可用的许多改进,同时修复了Logback架构中的一些固有问题。
与Logback一样,Log4j2提供对SLF4J的支持,自动重新加载日志配置,并支持高级过滤选项。 除了这些功能外,它还允许基于lambda表达式对日志语句进行延迟评估,为低延迟系统提供异步记录器,并提供无垃圾模式以避免由垃圾收集器操作引起的任何延迟。
所有这些功能使Log4j2成为这三个日志框架中最先进和最快的。
七、Logback
logback是由log4j创始人设计的又一个开源日志组件,作为流行的log4j项目的后续版本,从而替代log4j。
Logback的体系结构足够通用,以便在不同情况下应用。 目前,logback分为三个模块:logback-core,logback-classic和logback-access。
logback-core:模块为其他两个模块的基础。
logback-classic:模块可以被看做是log4j的改进版本。此外,logback-classic本身实现了SLF4J
API,因此可以在logback和其他日志框架(如log4j或java.util.logging(JUL))之间来回切换。logback-access:模块与Servlet容器(如Tomcat和Jetty)集成,以提供HTTP访问日志功能。
日志框架(Log4J、SLF4J、Logback)--日志规范与实践的更多相关文章
- java的几个日志框架log4j、logback、common-logging
开发工作中每个系统都需要记录日志,常见的日志工具有log4j(用的最多),slf4j,commons-loging,以及最近比较流行的logback 以前只是在项目中用log4j,更多的是参考下配置文 ...
- 在android中使用logback-android日志框架配置 slf4j + logback
为什么使用 slf4j + logback logbak定位于log4j的替代者,logback同样支持slf4j,方便被替换.在Android平台上,我在使用log4中遇到tag混乱的问题.相比lo ...
- SLF4J其实只是一个门面服务而已,他并不是真正的日志框架,真正的日志的输出相关的实现还是要依赖Log4j、logback等日志框架的。
小结: 1.加层: 每一种日志框架都有自己单独的API,要使用对应的框架就要使用其对应的API,这就大大的增加应用程序代码对于日志框架的耦合性. 为了解决这个问题,就是在日志框架和应用程序之间架设一个 ...
- log4j、logback日志框架与统一接口slf4j说明
log4j 传入日志框架,老项目中使用较多. 日志级别 根日志级别 log4j.rootLogger=info 默认日志级别,设置后对于没有设置子级别的日志输出都走这个默认值. 子类日志级别 log4 ...
- Log4j2日志框架集成Slf4j日志门面
1.说明 本文介绍使用日志门面Slf4j打印日志, 底层日志实现使用Log4j2框架, 方便以后切换底层日志实现, Log4j2可以替换成Logback等. 2.依赖管理 在pom.xml依赖管理中导 ...
- springboot日志框架学习------slf4j和log4j2
springboot日志框架学习------slf4j和log4j2 日志框架的作用,日志框架就是用来记录系统的一些行为的,可以通过日志发现一些问题,在出现问题之后日志是好的一个帮手. 市面上的日志框 ...
- SpringBoot(三) - Slf4j+logback 日志,异步请求,定时任务
1.Slf4j+logback 日志 SpringBoot框架的默认日志实现:slf4j + logback: 默认日志级别:info,对应了实际生产环境日志级别: 1.1 日志级别 # 常见的日志框 ...
- Java日志框架:SLF4J,Common-Logging,Log4J,Logback说明
Log4j Apache的一个开放源代码项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台.文件.GUI组件.甚至是套接口服务 器.NT的事件记录器.UNIX Syslog守护进程等 ...
- Java日志框架 (commons-logging,log4j,slf4j,logback)
转自:http://blog.csdn.net/kobejayandy/article/details/17335407 如果对于commons-loging.log4j.slf4j.LogBack等 ...
- 拨云见日,彻底弄清楚Java日志框架 log4j, logback, slf4j的区别与联系
log4j 以及 logback, slf4j 官网 日志框架的困惑 作为一个正常的项目,是必须有日志框架的存在的,没有日志,很难追踪一些奇奇怪怪的系统问题. 但是,我们经常在项目的依赖中,见到奇奇怪 ...
随机推荐
- Hadoop之WordCount
求平均数是MapReduce比较常见的算法,求平均数的算法也比较简单,一种思路是Map端读取数据,在数据输入到Reduce之前先经过shuffle,将map函数输出的key值相同的所有的value值形 ...
- 解决首页中Better-scroll可滚动区域的问题
在首页时候,使用BetterScroll插件的时候,滚动的时候经常会卡顿.Better-scroll在决定有多少区域可以滚动时,是根据ScrollerHeight属性决定的.ScrollerHeigh ...
- 多线程那点事—Parallel.for
先看段代码: 1 for (int i = 0; i < 10; i++) 2 { 3 Task.Factory.StartNew(()=>Console.WriteLine($" ...
- Linux系统下qt程序运行找不到IGL
linux下使用QT5运行时出现两个问题: cannot find -lGL collect2:error:ld returned 1 exit status 这是因为系统缺少链接库,执行两条命令即可 ...
- 数据库的查询(结合YGGL.sql)
(如有错误,欢迎指正!) 1.select 语句查询 (1)查询employees表员工部门号和性别,要求消除重复行. mysql> select distinct 员工部门号,性别 from ...
- 腾讯消息队列CMQ部署与验证
环境 IP 备注 192.168.1.66 node1 前置机 192.168.1.110 node2 192.168.1.202 node3 架构图 组件介绍 组件 监听端口 access 1200 ...
- 2018年第九届蓝桥杯B组(201806-----递增三元组)
给定三个整数数组 A = [A1, A2, - AN], B = [B1, B2, - BN], C = [C1, C2, - CN], 请你统计有多少个三元组(i, j, k) 满足: 1 < ...
- P3714 [BJOI2017]树的难题 点分治+线段树合并
题目描述 题目传送门 分析 路径问题考虑点分治 对于一个分治中心,我们可以很容易地得到从它开始的一条路径的价值和长度 问题就是如何将不同的路径合并 很显然,对于同一个子树中的所有路径,它们起始的颜色是 ...
- go跳出多层循环的几种方式
前言 比如这样的需求, 遍历一个 切片, 切片内容是切片1, 需求是判断切片1中某个是否有相应数据, 有就返回 正文 我们需要考虑的是在写两层遍历时如何在获取结果后结束这两层遍历 变量法 设置一个变量 ...
- 【MyBatis】MyBatis 延迟加载策略
MyBatis 延迟加载策略 文章源码 什么是延迟加载 延迟加载,就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据,也被成为懒加载. 好处:先从单表查询,需要时再从关联表去关联查询,大大提 ...