随机森林——Random Forests
[基础算法] Random Forests
2011 年 8 月 9 日
Random Forest(s),随机森林,又叫Random Trees[2][3],是一种由多棵决策树组合而成的联合预测模型,天然可以作为快速且有效的多类分类模型。如下图所示,RF中的每一棵决策树由众多split和node组成:split通过输入的test取值指引输出的走向(左或右);node为叶节点,决定单棵决策树的最终输出,在分类问题中为类属的概率分布或最大概率类属,在回归问题中为函数取值。整个RT的输出由众多决策树共同决定,argmax或者avg。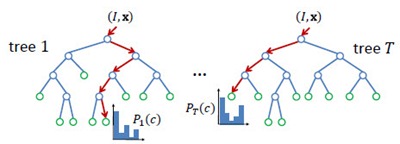
Node Test
node test通常很简单,但很多简单的拧在一起就变得无比强大,联合预测模型就是这样的东西。node test是因应用而异的。比如[1]的应用是基于深度图的人体部位识别,使用的node test是基于像素x的深度比较测试: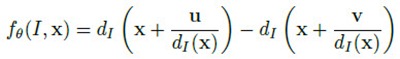
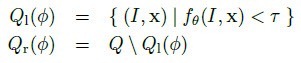
简单的说,就是比较像素x在u和v位移上的像素点的深度差是否大于某一阈值。u和v位移除以x深度值是为了让深度差与x本身的深度无关,与人体离相机的距离无关。这种node test乍一看是没有意义的,事实上也是没多少意义的,单个test的分类结果可能也只是比随机分类好那么一丁点。但就像Haar特征这种极弱的特征一样,起作用的关键在于后续的Boosting或Bagging——有效的联合可以联合的力量。
Training
RF属于Bagging类模型,因此大体训练过程和Bagging类似,关键在于样本的随机选取避免模型的overfitting问题。RF中的每棵决策树是分开训练的,彼此之间并无关联。对于每棵决策树,训练之前形成一个样本子集,在这个子集中有些样本可能出现多次,而另一些可能一次都没出现。接下去,就是循序决策树训练算法的,针对这个样本子集的单棵决策树训练。
单棵决策树的生成大致遵循以下过程:
1)随机生成样本子集;
2)分裂当前节点为左右节点,比较所有可选分裂,选取最优者;
3)重复2)直至达到最大节点深度,或当前节点分类精度达到要求。
这一过程是贪婪的。
当然对于不同的应用场合,训练过程中,会有细节上的差别,比如样本子集的生成过程、以及最优分割的定义。
在[1]中,决策树的真实样本其实是图片中的像素x,变量值则是上文提到的node test。但是,对于一张固定大小的图片而言可取的像素x是可数大量的,可取的位移(u,v)和深度差阈值几乎是不可数无限的。因此,[1]在训练单棵决策树前,要做的样本子集随机其实涉及到像素x集合的随机生成、位移(u,v)和深度差阈值组合的随机生成,最后还有训练深度图集合本身的随机生成。
最优分裂通常定义为使信息增量最大的分类,如[1]中的定义: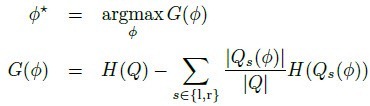
H指熵,通过分裂子集的部位标签分布计算。
Reference:
[1] J. Shotton, A. Fitzgibbon, M. Cook, T. Sharp, M. Finocchio, R. Moore, A. Kipman, and A. Blake. Real-Time Human Pose Recognition in Parts from a Single Depth Image. In CVPR 2011.
[2] L. Breiman. Random forests. Mach. Learning, 45(1):5–32, 2001.
[3] T. Hastie, R. Tibshirani, J. H. Friedman. The Elements of Statistical Learning. ISBN-13 978-0387952840, 2003, Springer.
[4] V. Lepetit, P. Lagger, and P. Fua. Randomized trees for real-time keypoint recognition. In Proc. CVPR, pages 2:775–781, 2005
from: http://blog.csdn.net/yangtrees/article/details/7488937
随机森林——Random Forests的更多相关文章
- sklearn_随机森林random forest原理_乳腺癌分类器建模(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 机器学习方法(六):随机森林Random Forest,bagging
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 前面机器学习方法(四)决策树讲了经典 ...
- 【机器学习】随机森林(Random Forest)
随机森林是一个最近比较火的算法 它有很多的优点: 在数据集上表现良好 在当前的很多数据集上,相对其他算法有着很大的优势 它能够处理很高维度(feature很多)的数据,并且不用做特征选择 在训练完后, ...
- 随机森林random forest及python实现
引言想通过随机森林来获取数据的主要特征 1.理论根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即个体学习器之间存在强依赖关系,必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系 ...
- 机器学习(六)—随机森林Random Forest
1.什么是随机采样? Bagging可以简单的理解为:放回抽样,多数表决(分类)或简单平均(回归): Bagging的弱学习器之间没有boosting那样的联系,不存在强依赖关系,基学习器之间属于并列 ...
- 第九篇:随机森林(Random Forest)
前言 随机森林非常像<机器学习实践>里面提到过的那个AdaBoost算法,但区别在于它没有迭代,还有就是森林里的树长度不限制. 因为它是没有迭代过程的,不像AdaBoost那样需要迭代,不 ...
- 【机器学习】随机森林 Random Forest 得到模型后,评估参数重要性
在得出random forest 模型后,评估参数重要性 importance() 示例如下 特征重要性评价标准 %IncMSE 是 increase in MSE.就是对每一个变量 比如 X1 随机 ...
- 随机森林(Random Forest)
决策树介绍:http://www.cnblogs.com/huangshiyu13/p/6126137.html 一些boosting的算法:http://www.cnblogs.com/huangs ...
- Bagging决策树:Random Forests
1. 前言 Random Forests (RF) 是由Breiman [1]提出的一类基于决策树CART的Bagging算法.论文 [5] 在121数据集上比较了179个分类器,效果最好的是RF,准 ...
随机推荐
- XAML 概述二
通过上一节我们已经对XAML有了一定的了解,这一节我们来系统的学习一下XAML. 一. 简单属性与类型转换器,属性元素: 我们已经知道 XAML是一种声明性的语言,并且XAML解析器会为每个标签创建一 ...
- hdu 5755 2016 Multi-University Training Contest 3 Gambler Bo 高斯消元模3同余方程
http://acm.hdu.edu.cn/showproblem.php?pid=5755 题意:一个N*M的矩阵,改变一个格子,本身+2,四周+1.同时mod 3;问操作多少次,矩阵变为全0.输出 ...
- mysql5.7.12安装过程中遇到的一些问题
在安装mysql-5.7.12-winx64中遇到的问题总结 1.该版本的mysql解压后的文件夹里没有data文件(切记自己添加data,自己添加的文件可能出现的问题是文件里的文件会缺失) 我在使用 ...
- Java中resourceBundle和Properties的区别
第一种办法InputStream is = Test.class.getResourceAsStream("DbConfig.properties");Properties p = ...
- tcp-client-c++
#include "stdafx.h" #include <Winsock2.h> #include <iostream> #pragma comment( ...
- android ble connect slowly
Hi I'm writing an Android app to connect to a BLE peripheral device. Android 4.4.2, Galaxy Nexus. I ...
- SharePoint 优化显示WebParts
在开发sharepoint中,经常遇到需要自定义显示列表中的一部分作为导航的内容, 如公告栏,新闻链接,最新动态等.... 我们通常需要显示一个列表的标题,并且限制字符长度, 外加一些条件,如按创建的 ...
- Objective-C传递数据小技巧
转自:http://www.guokr.com/blog/203413/ 比如说,如果你想向UIAlertView的delegate方法中传递一些信息,怎么办?继承UIAlertView么?使用Cat ...
- Hibernate各种主键生成策略与配置详解【附1--<generator class="foreign">】
1.assigned 主键由外部程序负责生成,在 save() 之前必须指定一个.Hibernate不负责维护主键生成.与Hibernate和底层数据库都无关,可以跨数据库.在存储对象前,必须要使用主 ...
- SQL SERVER 之 填充因子
填充因子依附索引而存在,但创建索引,就意味着要对表进行DML时,必须处理额外的工作量(也就是对索引结构的维护)以及存储方面的IO开销. 所以创建索引时,需要考虑创建索引所带来的查询性能方面的提高,与引 ...