[数据结构]字典树(Tire树)
概述:
Trie是个简单但实用的数据结构,是一种树形结构,是一种哈希树的变种,相邻节点间的边代表一个字符,这样树的每条分支代表一则子串,而树的叶节点则代表完整的字符串。和普通树不同的地方是,相同的字符串前缀共享同一条分支。
例如:pool,prize,preview,prepare,produce,progress这些关键词的Tire树
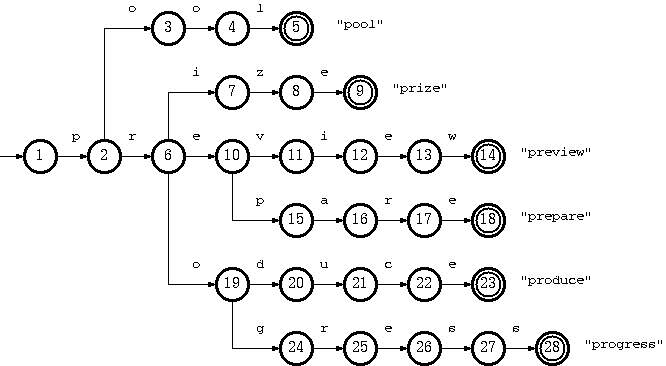
典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符;
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
- 每个节点的所有子节点包含的字符都不相同。
应用场景:
字典数查找效率很高,时间复杂度是O(m),m是要查找的单词中包含的字母的个数,但是会浪费大量存放空指针的存储空间,属于以空间换时间的算法。
1、串快速检索
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。
2、单词自动完成
编辑代码时,输入字符,自动提示可能的关键字、变量或函数等信息。
3、最长公共前缀
对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为最近公共祖先问题。
4、串排序方面的应用
给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典序从小到大输出用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。对这棵树进行先序遍历即可。
程序代码:
#include <gtest/gtest.h>
#include <list>
using namespace std; class TrieTree
{
public: const static int MAX_CHILD_KEY_COUNT = 30;
const static char STRING_END_TAG = '\xFF';
struct TrieNode
{
char nodeValue;
int nodeFreq;
list<TrieNode*> childNodes[MAX_CHILD_KEY_COUNT]; //为了避免这里数组太大,采用数组+链表方式 TrieNode()
{
nodeValue = 0;
nodeFreq = 0;
}
}; TrieTree();
~TrieTree(); public:
void Insert(const string& strVal);
void Delete(const string& strVal);
int Search(const string& strVal);
int CommonPrefix(const string& strVal); private:
void Clean(TrieNode* rootNode);
bool DeleteNode(TrieNode* rootNode, const string& strVal, int nOffset); TrieNode m_RootNode;
}; TrieTree::TrieTree()
{
}; TrieTree::~TrieTree()
{
Clean(&m_RootNode);
}; void TrieTree::Insert(const string& strVal)
{
if (strVal.empty())
{
return;
} // 在字符串末尾添加一个特殊字符,以区分是前缀还是完整字符串
string strValue(strVal);
strValue += STRING_END_TAG; TrieNode* pCurrentNode = &m_RootNode;
unsigned int nIndex = 0;
unsigned int nLength = strValue.length(); do
{
bool bExistVal = false;
char cValue = strValue[nIndex];
list<TrieNode*>& refListNode = pCurrentNode->childNodes[(unsigned char)cValue % MAX_CHILD_KEY_COUNT];
if (refListNode.size())
{
list<TrieNode*>::iterator it = refListNode.begin();
list<TrieNode*>::iterator itEnd = refListNode.end();
for (; it != itEnd; ++it)
{
if (cValue == (*it)->nodeValue)
{
(*it)->nodeFreq++;
bExistVal = true;
pCurrentNode = *it; break;
}
}
} // 当前不存在对应的字符,则新建一个
if (!bExistVal)
{
TrieNode* pNewNode = new TrieNode();
pNewNode->nodeFreq = 1;
pNewNode->nodeValue = cValue; refListNode.push_back(pNewNode);
pCurrentNode = pNewNode;
} ++nIndex;
}
while(nIndex < nLength);
} void TrieTree::Delete(const string& strVal)
{
if (strVal.empty())
{
return;
} string strValue(strVal);
strValue += STRING_END_TAG; DeleteNode(&m_RootNode, strValue, 0);
} int TrieTree::Search(const string& strVal)
{
if (strVal.empty())
{
return 0;
} string strValue(strVal);
strValue += STRING_END_TAG; return CommonPrefix(strValue);
} int TrieTree::CommonPrefix(const string& strVal)
{
if (strVal.empty())
{
return 0;
} TrieNode* pCurrentNode = &m_RootNode;
unsigned int nIndex = 0;
unsigned int nLength = strVal.length();
int nFreq = 0; do
{
bool bExistVal = false;
char cValue = strVal[nIndex];
list<TrieNode*>& refListNode = pCurrentNode->childNodes[(unsigned char)cValue % MAX_CHILD_KEY_COUNT];
if (refListNode.size())
{
list<TrieNode*>::iterator it = refListNode.begin();
list<TrieNode*>::iterator itEnd = refListNode.end();
for (; it != itEnd; ++it)
{
if (cValue == (*it)->nodeValue)
{
nFreq = (*it)->nodeFreq;
bExistVal = true;
pCurrentNode = *it;
break;
}
}
} // 当前不存在对应的字符,则没有找到
if (!bExistVal)
{
nFreq = 0;
break;
} ++nIndex;
}
while(nIndex < nLength); return nFreq;
} void TrieTree::Clean(TrieNode* rootNode)
{
if (!rootNode)
{
return;
} for (int i=0; i<MAX_CHILD_KEY_COUNT; ++i)
{
list<TrieNode*>& refListNode = rootNode->childNodes[i];
if (refListNode.size())
{
list<TrieNode*>::iterator it = refListNode.begin();
list<TrieNode*>::iterator itEnd = refListNode.end();
for (; it != itEnd; ++it)
{
Clean(*it);
delete *it;
} refListNode.clear();
}
}
} bool TrieTree::DeleteNode(TrieNode* rootNode, const string& strVal, int nOffset)
{
if (!rootNode)
{
return false;
} bool bDelChild = false;
char cValue = strVal[nOffset];
list<TrieNode*>& refListNode = rootNode->childNodes[(unsigned char)cValue % MAX_CHILD_KEY_COUNT];
if (refListNode.size())
{
list<TrieNode*>::iterator it = refListNode.begin();
list<TrieNode*>::iterator itEnd = refListNode.end();
for (; it != itEnd; ++it)
{
if ((*it)->nodeValue == cValue)
{
bDelChild = true;
// 字符串没有结束,删除下一个节点
if (++nOffset < (int)strVal.length())
{
bDelChild = DeleteNode(*it, strVal, nOffset);
} // 该节点次数为0,说明已经没有子节点了,移除该节点
if (bDelChild &&
(0 == (--(*it)->nodeFreq)))
{
delete *it;
refListNode.erase(it);
} break;
}
}
} return bDelChild;
} TEST(Structure, tTireTree)
{
// "abc","ab","bd","dda"
TrieTree tree;
tree.Insert("abc");
tree.Insert("ab");
tree.Insert("bd");
tree.Insert("dda"); ASSERT_EQ(tree.Search("ab"), 1);
ASSERT_EQ(tree.CommonPrefix("ab"), 2);
tree.Delete("ab");
ASSERT_EQ(tree.Search("ab"), 0);
ASSERT_EQ(tree.CommonPrefix("ab"), 1);
tree.Delete("abcd");
ASSERT_EQ(tree.Search("ab"), 0);
ASSERT_EQ(tree.Search("d"), 0);
ASSERT_EQ(tree.CommonPrefix("d"), 1);
ASSERT_EQ(tree.Search("fg"), 0);
tree.Delete("fg");
}
参考引用:
百度百科“字典树”
http://www.cnblogs.com/huangxincheng/archive/2012/11/25/2788268.html
看书、学习、写代码
[数据结构]字典树(Tire树)的更多相关文章
- 字典(Tire树)
4189 字典 时间限制: 1 s 空间限制: 256000 KB 题目等级 : 大师 Master 题目描述 Description 最经,skyzhong得到了一本好厉害的字典,这个 ...
- 基于Tire树和最大概率法的中文分词功能的Java实现
对于分词系统的实现来说,主要应集中在两方面的考虑上:一是对语料库的组织,二是分词策略的制订. 1. Tire树 Tire树,即字典树,是通过字串的公共前缀来对字串进行统计.排序及存储的一种树形结构 ...
- Tire树简介
又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种. 典型应用:用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计. 它的优点是:利用字符串的公共 ...
- Atitit 常见的树形结构 红黑树 二叉树 B树 B+树 Trie树 attilax理解与总结
Atitit 常见的树形结构 红黑树 二叉树 B树 B+树 Trie树 attilax理解与总结 1.1. 树形结构-- 一对多的关系1 1.2. 树的相关术语: 1 1.3. 常见的树形结构 ...
- 海量数据处理之Tire树(字典树)
参考博文:http://blog.csdn.net/v_july_v/article/details/6897097 第一部分.Trie树 1.1.什么是Trie树 Trie树,即字典树,又称单词查找 ...
- Tire树(字典树)
from:https://www.cnblogs.com/justinh/p/7716421.html Trie,又经常叫前缀树,字典树等等.它有很多变种,如后缀树,Radix Tree/Trie,P ...
- 9-11-Trie树/字典树/前缀树-查找-第9章-《数据结构》课本源码-严蔚敏吴伟民版
课本源码部分 第9章 查找 - Trie树/字典树/前缀树(键树) ——<数据结构>-严蔚敏.吴伟民版 源码使用说明 链接☛☛☛ <数据结构-C语言版>(严蔚 ...
- 【Todo】字符串相关的各种算法,以及用到的各种数据结构,包括前缀树后缀树等各种树
另开一文分析字符串相关的各种算法,以及用到的各种数据结构,包括前缀树后缀树等各种树. 先来一个汇总, 算法: 本文中提到的字符串匹配算法有:KMP, BM, Horspool, Sunday, BF, ...
- Tire树总结(模板+例题)
题目来自<算法竞赛设计指南> Tire树是一种可以快速查找字符串的数据结构 模板 #include<cstdio> #include<algorithm> #inc ...
随机推荐
- 为Eclipse/MyEclipse添加JDK API Document帮助文档
1.下载 Java SE Development Kit 8 Documentation . 2.启动Eclipse,Window-Preference-Java-Installed JREs: 3. ...
- Kafka架构设计:分布式发布订阅消息系统
[http://www.oschina.net/translate/kafka-design](较长:很详细的讲解) [我们为什么要搭建该系统]用作LinkedIn的活动流(activity stre ...
- 使用Office-Word的博客发布功能(测试博文)
本人打算在博客园开博,但平时收集和整理资料都在OneNote中,又不想在写博客时还要进行复制粘贴操作,于是就想到了Microsoft Office自带的博客发布功能.在此做了一下测试,发布了此博文. ...
- 转载:div和flash层级关系问题
转自:http://sin581.blog.163.com/blog/static/860578932012813112334404/ 问题: ie下默认好像div层级没有flash层级高,也 ...
- Oracle数据库定时任务配置和日志执行情况查询
基础配置: /***************************************************************** * * 移动抵扣券快到期推送提醒 * 首次执行 : 2 ...
- 4.接口隔离原则(Interface Segregation Principle)
1.定义 客户端不应该依赖它不需要的接口: 一个类对另一个类的依赖应该建立在最小的接口上. 2.定义解读 定义包含三层含义: 一个类对另一个类的依赖应该建立在最小的接口上: 一个接口代表一个角色,不应 ...
- 编写 Window 服务程序
编写 Window 服务程序 一.直观认识Windows服务. 打开Windows“控制面板/管理工具/服务”,系统显示Windows服务列表. ...
- 一个jQuery扩展工具包
带有详尽注释的源代码: var jQuery = jQuery || {}; // TODO // ###################################string操作相关函数### ...
- 【JavaScript】Registering JavaScript object methods as callbacks
The registration of callback functions is very common in JavaScript web programming, for example to ...
- Qt多线程学习:创建多线程
[为什么要用多线程?] 传统的图形用户界面应用程序都仅仅有一个运行线程,而且一次仅仅运行一个操作.假设用户从用户界面中调用一个比較耗时的操作,当该操作正在运行时,用户界面一般会冻结而不再响应.这个问题 ...