storm入门教程 第一章 前言[转]
1.1 实时流计算
互联网从诞生的第一时间起,对世界的最大的改变就是让信息能够实时交互,从而大大加速了各个环节的效率。正因为大家对信息实时响应、实时交互的需求,软件行业除了个人操作系统之外,数据库(更精确的说是关系型数据库)应该是软件行业发展最快、收益最为丰厚的产品了。记得十年前,很多银行别说实时转账,连实时查询都做不到,但是数据库和高速网络改变了这个情况。
随着互联网的更进一步发展,从Portal信息浏览型到Search信息搜索型到SNS关系交互传递型,以及电子商务、互联网旅游生活产品等将生活中的流通环节在线化。对效率的要求让大家对于实时性的要求进一步提升,而信息的交互和沟通正在从点对点往信息链甚至信息网的方向发展,这样必然带来数据在各个维度的交叉关联,数据爆炸已不可避免。因此流式处理加NoSQL产品应运而生,分别解决实时框架和数据大规模存储计算的问题。
早在7、8年前诸如UC伯克利、斯坦福等大学就开始了对流式数据处理的研究,但是由于更多的关注于金融行业的业务场景或者互联网流量监控的业务场景,以及当时互联网数据场景的限制,造成了研究多是基于对传统数据库处理的流式化,对流式框架本身的研究偏少。目前这样的研究逐渐没有了声音,工业界更多的精力转向了实时数据库。
2010年Yahoo!对S4的开源,2011年twitter对Storm的开源,改变了这个情况。以前互联网的开发人员在做一个实时应用的时候,除了要关注应用逻辑计算处理本身,还要为了数据的实时流转、交互、分布大伤脑筋。但是现在情况却大为不同,以Storm为例,开发人员可以快速的搭建一套健壮、易用的实时流处理框架,配合SQL产品或者NoSQL产品或者MapReduce计算平台,就可以低成本的做出很多以前很难想象的实时产品:比如一淘数据部的量子恒道品牌旗下的多个产品就是构建在实时流处理平台上的。
本教程是一本对storm的基础介绍手册,但是我们也希望它不仅仅是一本storm的使用手册,我们会在其中加入更多我们在实际数据生产过程的经验和应用的架构,最后的目的是帮助所有愿意使用实时流处理框架的技术同仁,同时也默默的改变这个世界。
1.2 Storm特点
Storm是一个开源的分布式实时计算系统,可以简单、可靠的处理大量的数据流。Storm有很多使用场景:如实时分析,在线机器学习,持续计算,分布式RPC,ETL等等。Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理,而且处理速度很快(在一个小集群中,每个结点每秒可以处理数以百万计的消息)。Storm的部署和运维都很便捷,而且更为重要的是可以使用任意编程语言来开发应用。
Storm有如下特点:
- 编程模型简单
在大数据处理方面相信大家对hadoop已经耳熟能详,基于Google Map/Reduce来实现的Hadoop为开发者提供了map、reduce原语,使并行批处理程序变得非常地简单和优美。同样,Storm也为大数据的实时计算提供了一些简单优美的原语,这大大降低了开发并行实时处理的任务的复杂性,帮助你快速、高效的开发应用。
- 可扩展
在Storm集群中真正运行topology(topology[英][tə'pɒlədʒɪ][美][tə'pɑ:lədʒɪ]n.拓扑结构; 地质学; 局部解剖学)的主要有三个实体:工作进程、线程和任务。Storm集群中的每台机器上都可以运行多个工作进程,每个工作进程又可创建多个线程,每个线程可以执行多个任务,任务是真正进行数据处理的实体,我们开发的spout(spout[英][spaʊt][美][spaʊt]n.喷口,喷嘴; 水柱,喷流; (鲸类的)喷水孔; [气]龙卷; )、bolt(bolt[英][bəʊlt][美][boʊlt]n.螺栓,螺钉; 闪电,雷电; 门闩; 弩箭; vt.筛选; 囫囵吞下; (把门、窗等)闩上; 突然说出,脱口说出; )就是作为一个或者多个任务的方式执行的。因此,计算任务在多个线程、进程和服务器之间并行进行,支持灵活的水平扩展。
- 高可靠性
Storm可以保证spout发出的每条消息都能被“完全处理”,这也是直接区别于其他实时系统的地方,如S4。
请注意,spout发出的消息后续可能会触发产生成千上万条消息,可以形象的理解为一棵消息树,其中spout发出的消息为树根,Storm会跟踪这棵消息树的处理情况,只有当这棵消息树中的所有消息都被处理了,Storm才会认为spout发出的这个消息已经被“完全处理”。如果这棵消息树中的任何一个消息处理失败了,或者整棵消息树在限定的时间内没有“完全处理”,那么spout发出的消息就会重发。
考虑到尽可能减少对内存的消耗,Storm并不会跟踪消息树中的每个消息,而是采用了一些特殊的策略,它把消息树当作一个整体来跟踪,对消息树中所有消息的唯一id进行异或计算,通过是否为零来判定spout发出的消息是否被“完全处理”,这极大的节约了内存和简化了判定逻辑,后面会对这种机制进行详细介绍。
这种模式,每发送一个消息,都会同步发送一个ack/fail,对于网络的带宽会有一定的消耗,如果对于可靠性要求不高,可通过使用不同的emit接口关闭该模式。
上面所说的,Storm保证了每个消息至少被处理一次,但是对于有些计算场合,会严格要求每个消息只被处理一次,幸而Storm的0.7.0引入了事务性拓扑,解决了这个问题,后面会有详述。
- 高容错性
如果在消息处理过程中出了一些异常,Storm会重新安排这个出问题的处理单元。Storm保证一个处理单元永远运行(除非你显式杀掉这个处理单元)。
当然,如果处理单元中存储了中间状态,那么当处理单元重新被Storm启动的时候,需要应用自己处理中间状态的恢复。
- 支持多种编程语言
除了用java实现spout和bolt,你还可以使用任何你熟悉的编程语言来完成这项工作,这一切得益于Storm所谓的多语言协议。多语言协议是Storm内部的一种特殊协议,允许spout或者bolt使用标准输入和标准输出来进行消息传递,传递的消息为单行文本或者是json编码的多行。
Storm支持多语言编程主要是通过ShellBolt, ShellSpout和ShellProcess这些类来实现的,这些类都实现了IBolt 和 ISpout接口,以及让shell通过java的ProcessBuilder类来执行脚本或者程序的协议。
可以看到,采用这种方式,每个tuple(tuple[英][tʌpl][美][tʌpl]n.元组,数组; )在处理的时候都需要进行json的编解码,因此在吞吐量上会有较大影响。
- 支持本地模式
Storm有一种“本地模式”,也就是在进程中模拟一个Storm集群的所有功能,以本地模式运行topology跟在集群上运行topology类似,这对于我们开发和测试来说非常有用。
- 高效
用ZeroMQ作为底层消息队列, 保证消息能快速被处理。
对比Hadoop的批处理,Storm是个实时的、分布式以及具备高容错的计算系统。同Hadoop一样Storm也可以处理大批量的数据,然而Storm在保证高可靠性的前提下还可以让处理进行的更加实时;也就是说,所有的信息都会被处理。Storm同样还具备容错和分布计算这些特性,这就让Storm可以扩展到不同的机器上进行大批量的数据处理。他同样还有以下的这些特性:
- 易于扩展。对于扩展,你只需要添加机器和改变对应的topology(拓扑)设置。Storm使用Hadoop Zookeeper进行集群协调,这样可以充分的保证大型集群的良好运行。
- 每条信息的处理都可以得到保证。
- Storm集群管理简易。
- Storm的容错机能:一旦topology递交,Storm会一直运行它直到topology被废除或者被关闭。而在执行中出现错误时,也会由Storm重新分配任务。
- 尽管通常使用Java,Storm中的topology可以用任何语言设计。
为什么 Storm 比 Hadoop 快?
全量数据处理使用的大多是鼎鼎大名的hadoop或者hive,作为一个批处理系统,hadoop以其吞吐量大、自动容错等优点,在海量数据处理上得到了广泛的使用。但是,hadoop不擅长实时计算,因为它天然就是为批处理而生的,这也是业界一致的共识。否则最近这两年也不会有s4,storm,puma这些实时计算系统冒出来啦。
storm的网络直传、内存计算,其时延必然比hadoop的通过hdfs传输低得多;当计算模型比较适合流式时,storm的流式处理,省去了批处理的收集数据的时间;因为storm是服务型的作业,也省去了作业调度的时延。所以从时延上来看,storm要快于hadoop。
按照storm作者的说法,storm对于实时计算的意义类似于hadoop对于批处理的意义。我们都知道,根据google mapreduce来实现的hadoop为我们提供了map, reduce原语,使我们的批处理程序变得非常地简单和优美。我们可以看一下storm和hadoop的对比概念:
| Hadoop | Storm | |
| 系统角色 | JobTracker | Nimbus |
| TaskTracker | Supervisor | |
| Child | Worker | |
| 应用名称 | Job | Topology |
| 组件接口 | Mapper/Reducer | Spout/Bolt |
认 识
Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要 求。Storm经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域。Storm的部署管理非常简单,而且,在同类的流式计算工 具,Storm的性能也是非常出众的。
Storm主要分为两种组件Nimbus和Supervisor。这两种组件都是快速失败的,没有状态。任务状态和心跳信息等都保存在Zookeeper上的,提交的代码资源都在本地机器的硬盘上。
- Nimbus负责在集群里面发送代码,分配工作给机器,并且监控状态。全局只有一个。
- Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程Worker。每一个要运行Storm的机器上都要部署一个,并且,按照机器的配置设定上面分配的槽位数。
- Zookeeper是Storm重点依赖的外部资源。Nimbus和Supervisor甚至实际运行的Worker都是把心跳保存在Zookeeper上的。Nimbus也是根据Zookeerper上的心跳和任务运行状况,进行调度和任务分配的。
- Storm提交运行的程序称为Topology。
- Topology处理的最小的消息单位是一个Tuple,也就是一个任意对象的数组。
- Topology由Spout和Bolt构成。Spout是发出Tuple的结点。Bolt可以随意订阅某个Spout或者Bolt发出的Tuple。Spout和Bolt都统称为component。
下图是一个Topology设计的逻辑图的例子。
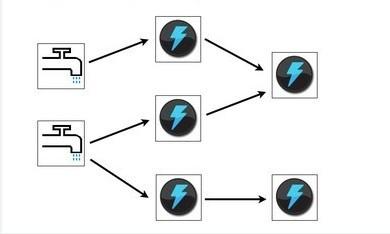
下图是Topology的提交流程图。
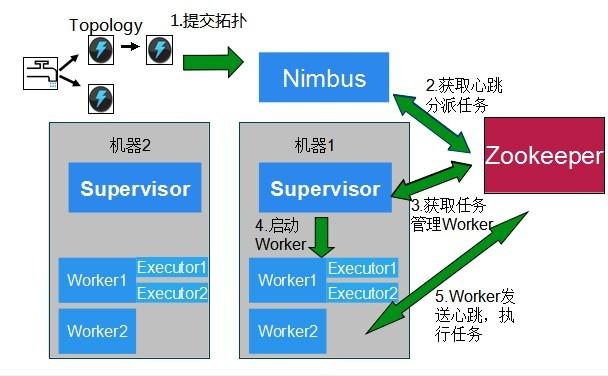
下图是Storm的数据交互图。可以看出两个模块Nimbus和Supervisor之间没有直接交互。状态都是保存在Zookeeper上。Worker之间通过ZeroMQ传送数据。

虽然,有些地方做得还是不太好,例如,底层使用的ZeroMQ不能控制内存使用(下个release版本,引入了新的消息机制使用netty代替 ZeroMQ),多语言支持更多是噱头,Nimbus还不支持HA。但是,就像当年的Hadoop那样,很多公司选择它是因为它是唯一的选择。而这些先期 使用者,反过来促进了Storm的发展。
发 展
Storm已经发展到0.8.2版本了,看一下两年多来,它取得的成就:
- 有50个大大小小的公司在使用Storm,相信更多的不留名的公司也在使用。这些公司中不乏淘宝,百度,Twitter,Groupon,雅虎等重量级公司。
从开源时候的0.5.0版本,到现在的0.8.0+,和即将到来的0.9.0+。先后添加了以下重大的新特性:
- 使用kryo作为Tuple序列化的框架(0.6.0)
- 添加了Transactional topologies(事务性拓扑)的支持(0.7.0)
- 添加了Trident的支持(0.8.0)
- 引入netty作为底层消息机制(0.9.0)
Transactional topologies和Trident都是针对实际应用中遇到的重复计数问题和应用性问题的解决方案。可以看出,实际的商用给予了Storm很多良好的反馈。
在GitHub上超过4000个项目负责人。Storm集成了许多库,支持包括Kestrel、Kafka、JMS、Cassandra、Memcached以及更多系统。随着支持的库越来越多,Storm更容易与现有的系统协作。
Storm的拥有一个活跃的社区和一群热心的贡献者。过去两年,Storm的发展是成功的。
当 前
Storm被广泛应用于实时分析,在线机器学习,持续计算、分布式远程调用等领域。来看一些实际的应用:
- 一淘-实时分析系统pora:实时分析用户的属性,并反馈给搜索引擎。最初,用户属性分析是通过每天在云梯上定时运行的MR job来完成的。为了满足实时性的要求,希望能够实时分析用户的行为日志,将最新的用户属性反馈给搜索引擎,能够为用户展现最贴近其当前需求的结果。
携程-网站性能监控:实时分析系统监控携程网的网站性能。利用HTML5提供的performance标准获得可用的指标,并记录日志。Storm集群实时分析日志和入库。使用DRPC聚合成报表,通过历史数据对比等判断规则,触发预警事件。
如果,业务场景中需要低延迟的响应,希望在秒级或者毫秒级完成分析、并得到响应,而且希望能够随着数据量的增大而拓展。那就可以考虑下,使用Storm了。
试想下,如果,一个游戏新版本上线,有一个实时分析系统,收集游戏中的数据,运营或者开发者可以在上线后几秒钟得到持续不断更新的游戏监控 报告和分析结果,然后马上针对游戏的参数和平衡性进行调整。这样就能够大大缩短游戏迭代周期,加强游戏的生命力(实际上,zynga就是这么干的!虽然使 用的不是 Storm……Zynga研发之道探秘:用数据说话)。
除了低延迟,Storm的Topology灵活的编程方式和分布式协调也 会给我们带来方便。用户属性分析的项目,需要处理大量的数据。使用传统的MapReduce处理是个不错的选择。但是,处理过程中有个步骤需要根据分析结 果,采集网页上的数据进行下一步的处理。这对于MapReduce来说就不太适用了。但是,Storm的Topology就能完美解决这个问题。基于这个 问题,我们可以画出这样一个Storm的Topology的处理图。
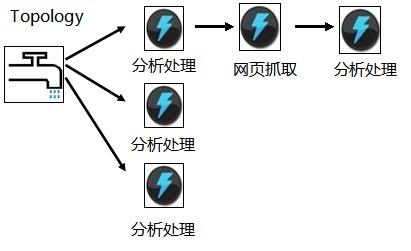
我们只需要实现每个分析的过程,而Storm帮我们把消息的传送和接受都完成了。更加激动人心的是,你只需要增加某个Bolt的并行度就能够解决掉某个结点上的性能瓶颈。
未 来
在流式处理领域里,Storm的直接对手是S4。不过,S4冷淡的社区、半成品的代码,在实际商用方面输给Storm不止一条街。
如果把范围扩大到实时处理,Storm就一点都不寂寞了。
- Puma:Facebook使用puma和Hbase相结合来处理实时数据,使批处理 计算平台具备一定实时能力。 不过这不算是一个开源的产品。只是内部使用。
- HStreaming:尝试为Hadoop环境添加一个实时的组件HStreaming能让一个Hadoop平台在几天内转为一个实时系统。分商业版和免费版。也许HStreaming可以借Hadoop的东风,撼动Storm。
Spark Streaming:作为UC Berkeley云计算software stack的一部分,Spark Streaming是建立在Spark上的应用框架,利用Spark的底层框架作为其执行基础,并在其上构建了DStream的行为抽象。利用 DStream所提供的api,用户可以在数据流上实时进行count,join,aggregate等操作。
当然,Storm也有Yarn-Storm项目,能让Storm运行在Hadoop2.0的Yarn框架上,可以让Hadoop的MapReduce和Storm共享资源。
总 结
知乎上有一个挺好的问答: 问:实时处理系统(类似s4, storm)对比直接用MQ来做好处在哪里? 答:好处是它帮你做了: 1) 集群控制。2) 任务分配。3) 任务分发 4) 监控 等等。
需要知道Storm不是一个完整的解决方案。使用Storm你需要加入消息队列做数据入口,考虑如何在流中保存状态,考虑怎样将大问题用分布式去解 决。解决这些问题的成本可能比增加一个服务器的成本还高。但是,一旦下定决定使用了Storm并解决了那些恼人的细节,你就能享受到Storm给你带来的 简单,可拓展等优势了。
技术的发展日新月异,数据处理领域越来越多优秀的开源产品。Storm的过去是成功的,将来会如何发展,我们拭目以待吧。
storm入门教程 第一章 前言[转]的更多相关文章
- storm入门教程 第一章 前言
转自:http://blog.linezing.com/?p=1847 storm:http://www.cnblogs.com/panfeng412/tag/Storm/ http://blog.l ...
- Storm入门之第一章
Storm入门之第一章 1.名词 spout龙卷,读取原始数据为bolt提供数据 bolt雷电,从spout或者其他的bolt接收数据,并处理数据,处理结果可作为其他bolt的数据源或最终结果 nim ...
- 《进击吧!Blazor!》系列入门教程 第一章 8.部署
<进击吧!Blazor!>是本人与张善友老师合作的Blazor零基础入门教程视频,此教程能让一个从未接触过Blazor的程序员掌握开发Blazor应用的能力. 视频地址:https://s ...
- Storm入门教程 第二章 构建Topology[转]
2.1 Storm基本概念 在运行一个Storm任务之前,需要了解一些概念: Topologies Streams Spouts Bolts Stream groupings Reliability ...
- 《进击吧!Blazor!》系列入门教程 第一章 6.安全
<进击吧!Blazor!>是本人与张善友老师合作的Blazor零基础入门教程视频,此教程能让一个从未接触过Blazor的程序员掌握开发Blazor应用的能力. 视频地址:https://s ...
- 《进击吧!Blazor!》系列入门教程 第一章 7.图表
<进击吧!Blazor!>是本人与张善友老师合作的Blazor零基础入门教程视频,此教程能让一个从未接触过Blazor的程序员掌握开发Blazor应用的能力. 视频地址:https://s ...
- [ABP教程]第一章 创建服务端
Web应用程序开发教程 - 第一章: 创建服务端 关于本教程 在本系列教程中, 你将构建一个名为 Acme.BookStore 的用于管理书籍及其作者列表的基于ABP的应用程序. 它是使用以下技术开发 ...
- Nova PhoneGap框架 第一章 前言
Nova PhoneGap Framework诞生于2012年11月,从第一个版本的发布到现在,这个框架经历了多个项目的考验.一直以来我们也持续更新这个框架,使其不断完善.到现在,这个框架已比较稳定了 ...
- 村田噪声抑制基础教程-第一章 需要EMI静噪滤波器的原因
1-1. 简介 EMI静噪滤波器 (EMIFIL®) 是为电子设备提供电磁噪声抑制的电子元件,配合屏蔽罩和其他保护装置一起使用.这种滤波器仅从通过连线传导的电流中提取并移除引起电磁噪声的元件.第1章说 ...
随机推荐
- POJ1426Find The Multiple
http://poj.org/problem?id=1426 题意 : 输入一个数n,找n的倍数m,这个m所满足的条件是,每一位数只能由0或1组成,在题目的旁边用红色的注明了Special Judge ...
- EXPRESS.JS再出发
那个那个MEAN的书,看得七七八八,有了大概,现在就要一样一样的加深记忆啦.. EXPRSS.JS的东东,网上有现成入门书籍: 第一期代码测试: var express = require('expr ...
- linux入门教程(八) Linux磁盘管理
[查看磁盘或者目录的容量 df 和 du] df 查看已挂载磁盘的总容量.使用容量.剩余容量等,可以不加任何参数,默认是按k为单位显示的 df常用参数有 –i -h -k –m等 -i 使用inode ...
- ActiveMQ 学习笔记
http://somebody-hjh.iteye.com/blog/726050 一.概述 Message,即消息.人与人之间通过消息传递信息.言语.眼神.肢体动作都可被视为消息体.当然还有我们经常 ...
- s3cmd的安装与配置
安装包链接:http://files.cnblogs.com/files/litao0505/s3.rar 安装S3cmd1. tar -zxf s3cmd-1.0.0.tar.gz2. mv s3c ...
- Linux磁盘管理命令
1.磁盘分割: fdisk [root@linux ~]# fdisk [-l] 装置名称 参数: -l :输出后面接的装置所有的partition内容.若仅有fdisk -l时, 则系统将会把整个系 ...
- 解决不安装VC运行库(VC2005,VC2008),程序运行出错的方法
因为VS2005以后程序采用了manifest的生成方式,所以发布的时候要和运行库一起发布.但是我们平时开发和发布的时候如果都要客户安装运行库,那就不太方便了.你可以Microsoft下载:http: ...
- Android:控件AutoCompleteTextView 客户端保存搜索历史自动提示
<?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android=&quo ...
- Zookeeper核心机制
(如果感觉有帮助,请帮忙点推荐,添加关注,谢谢!你的支持是我不断更新文章的动力.本博客会逐步推出一系列的关于大型网站架构.分布式应用.设计模式.架构模式等方面的系列文章) Zookeeper是Hado ...
- linux 命令学习大全
转载 http://blog.csdn.net/xiaoguaihai/article/details/8705992/