Python3爬取百度百科(配合PHP)
用PHP写了一个网页,可以获取百度百科词条。

那么通过Python来爬取,只需要不断向这个网页POST数据,获取返回值就可以了。由于是我自己的网页,保存返回值我也让PHP在服务器端来完成了,所以Python的任务只需要不断向服务器POST数据。
那么POST什么数据呢?暂时找到了一个名词大全的网页。http://cidian.911cha.com/cixing_mingci.html

足足20页的名词,足够作为名词POST数据的来源了。
下面是获取各种名词的python代码:
zd = []
for i in range(20):
url = 'http://cidian.911cha.com/cixing_mingci_p'+str(i+1)+'.html'
webpage = urllib.request.urlopen(url)
data = webpage.read()
data = data.decode('utf-8')
'''
file = open('d:/Pythoncode/simplecodes/0.html','w',encoding='utf-8')
file.write(data)
file.close()
'''
k = re.findall(r'target="_blank">.+?</a>',data)
cou = 0
cx=[]
for i in k :
if cou%2==0:
cx.append(i)
cou= cou+1
for it in cx:
m = re.search(r'target="_blank">(.*?)</a>',it)
iturl = m.group(1)
zd.append(iturl)
现在字典里已经保存了足足20页的名词,下一步就是要向服务器POST数据,保存词条内容了。
for i in zd :
s=i
print(i)
s=urllib.parse.quote(s)
url = "http://www.selflink.cn/xiaobaike/?name=%s"%(s)
try:
urllib.request.urlopen(url,timeout=5)
except Exception as e:
pass
python开始运行了……
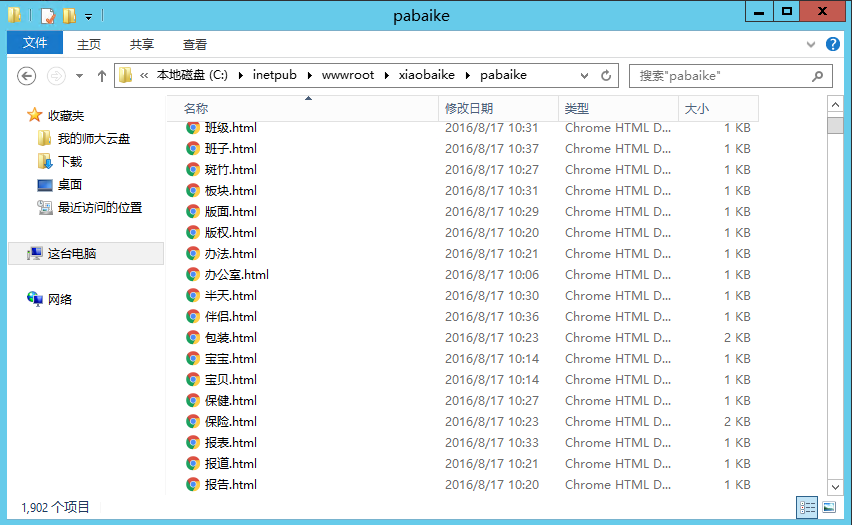
最后爬到了1902个词条内容0.0
获取了这么多词条有什么用呢?……我也不知道,不过,获取知识也许是人工智能的开始吧^_^
Python3爬取百度百科(配合PHP)的更多相关文章
- Python开发简单爬虫(二)---爬取百度百科页面数据
一.开发爬虫的步骤 1.确定目标抓取策略: 打开目标页面,通过右键审查元素确定网页的url格式.数据格式.和网页编码形式. ①先看url的格式, F12观察一下链接的形式;② 再看目标文本信息的标签格 ...
- Python——爬取百度百科关键词1000个相关网页
Python简单爬虫——爬取百度百科关键词1000个相关网页——标题和简介 网站爬虫由浅入深:慢慢来 分析: 链接的URL分析: 数据格式: 爬虫基本架构模型: 本爬虫架构: 源代码: # codin ...
- 爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释 我的第一个想法是做一个数据库,把常用的词语和词语的解释放到数据库里面,当用户查询时直接读取数据库结果 但是自己又没有心思做这样一个数 ...
- python简单爬虫 用beautifulsoup爬取百度百科词条
目标:爬取“湖南大学”百科词条并处理数据 需要获取的数据: 源代码: <div class="basic-info cmn-clearfix"> <dl clas ...
- java 如何爬取百度百科词条内容(java如何使用webmagic爬取百度词条)
这是老师所布置的作业 说一下我这里的爬去并非能把百度词条上的内容一字不漏的取下来(而是它分享链接的一个主要内容概括...)(他的主要内容我爬不到 也不想去研究大家有好办法可以call me) 例如 互 ...
- python爬虫—爬取百度百科数据
爬虫框架:开发平台 centos6.7 根据慕课网爬虫教程编写代码 片区百度百科url,标题,内容 分为4个模块:html_downloader.py 下载器 html_outputer.py 爬取数 ...
- python3爬取百度图片(2018年11月3日有效)
最终目的:能通过输入关键字进行搜索,爬取相应的图片存储到本地或者数据库 首先打开百度图片的网站,搜索任意一个关键字,比如说:水果,得到如下的界面 分析: 1.百度图片搜索结果的页面源代码不包含需要提取 ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- R语言爬虫:爬取百度百科词条
抓取目标:抓取花儿与少年的百度百科中成员信息 url <- "http://baike.baidu.com/item/%E8%8A%B1%E5%84%BF%E4%B8%8E%E5%B0 ...
随机推荐
- I.MX6 Power off register hacking
/*********************************************************************** * I.MX6 Power off register ...
- VS2008+ffmpeg SDK3.2调试tutorial01
最近研究ffmpeg,在ubuntu下感觉不太好调试,老是找不到函数的声明.所以我就把他移到windows下用vs2008分析 关于环境的搭建,我参考了 http://hi.baidu.com/for ...
- Nosql释义
NoSQL不是产品,是一项运动 ---->NoSQL(NoSQL = Not Only SQL ),意即反SQL运动,是一项全新的数据库革命性运动,早期就有人提出,发展至2009年 ...
- Asp.Net MVC4 系列-- 进阶篇之路由(1)【转】
http://blog.csdn.net/lan_liang/article/details/22993839?utm_source=tuicool
- jdbc:oracle:thin:@192.168.3.98:1521:orcl(详解)
整理自互联网 一. jdbc:oracle:thin:@192.168.3.98:1521:orcljdbc:表示采用jdbc方式连接数据库oracle:表示连接的是oracle数据库thin:表示连 ...
- 同行评审 Peer Review
周五的课上,章老师给我们上了一节关于同行评审(Peer Review)的课程,让我了解了以前并不熟悉的这一过程.课上我们就姚思丹同学项目组做的项目,分组进行了审查. 首先介绍一下同行评审(Peer R ...
- STM32的JTAG、SWD和串口下载的问题
最近有一个项目用到STM32,为了使PCB布线方便一些所以改了一些引脚,占用了JTAG接口的PA15和PB3,所以要禁用一下JTAG,下载采用SWD模式.这样在实际操作中做出一些总结(方法网上都有.这 ...
- 关于webpack最好的文档
这几天研究webpack打包工具,在网上搜了无数的资料,鱼龙混杂.看了几十份资料,依然没有一个可以完整的描述的. 折腾了那么久,还是放弃治疗了.回到官网,一字一句的阅读,一个小时就彻底明白了. 学习新 ...
- 数据库(class0507)
局部变量_先声明再赋值 声明局部变量 DECLARE @变量名 数据类型 DECLARE @name varchar(20) DECLARE @id int 赋值 SET @变量名 =值 --set用 ...
- wuzhicms水印的设置