【原】Spark中Job如何划分为Stage
版权声明:本文为原创文章,未经允许不得转载。
复习内容:
Spark中Job的提交 http://www.cnblogs.com/yourarebest/p/5342404.html
1.Spark中Job如何划分为Stage
我们在复习内容中介绍了Spark中Job的提交,下面我们看如何将Job划分为Stage。
对于JobSubmitted事件类型,通过 dagScheduler的handleJobSubmitted方法处理,方法源码如下:
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
//根据jobId生成新的Stage,详见1
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
...
Stage的提交及TaskSet(tasks)的提交
...
}
1.newResultStage方法如下, 根据jobId生成一个ResultStage
private def newResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
//根据jobid和rdd得到父Stages和StageId,详见2
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, jobId)
//根据父Stages和StageId生成ResultStage,详见4
val stage = new ResultStage(id, rdd, func, partitions, parentStages, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
2.getParentStagesAndId方法如下所示:
private def getParentStagesAndId(rdd: RDD[_], firstJobId: Int): (List[Stage], Int) = {
val parentStages = getParentStages(rdd, firstJobId),详见3
val id = nextStageId.getAndIncrement()
(parentStages, id)
}
3.getParentStages方法如下所示:
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
val parents = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
//将要遍历的RDD放到栈Stack中
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
dep match {
//判断rdd的依赖关系,如果是ShuffleDependency说明是宽依赖,详见4
case shufDep: ShuffleDependency[, , _] =>
parents += getShuffleMapStage(shufDep, firstJobId)
//是窄依赖
case _ =>
//遍历rdd的父RDD是否有父Stage存在
waitingForVisit.push(dep.rdd)
} } } }
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
//调用visit方法访问出栈的RDD
visit(waitingForVisit.pop())
}
parents.toList
}
4.getShuffleMapStage方法如下所示:
private def getShuffleMapStage(
shuffleDep: ShuffleDependency[, , _],
firstJobId: Int): ShuffleMapStage = {
shuffleToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) => stage
case None =>
// We are going to register ancestor shuffle dependencies,详见5
getAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
//根据firstJobId生成ShuffleMapStage,详见6
shuffleToMapStage(dep.shuffleId) = newOrUsedShuffleStage(dep, firstJobId)
}
// Then register current shuffleDep
val stage = newOrUsedShuffleStage(shuffleDep, firstJobId)
shuffleToMapStage(shuffleDep.shuffleId) = stage
stage
}
}
5.getAncestorShuffleDependencies方法如下:
private def getAncestorShuffleDependencies(rdd: RDD[_]): Stack[ShuffleDependency[, , _]] = {
val parents = new Stack[ShuffleDependency[, , _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
dep match {
case shufDep: ShuffleDependency[, , _] =>
if (!shuffleToMapStage.contains(shufDep.shuffleId)) {
parents.push(shufDep)
}
case _ =>
}
waitingForVisit.push(dep.rdd)
}
}
}
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents
}
6.newOrUsedShuffleStage方法如下所示,根据给定的RDD生成ShuffleMapStage,如果shuffleId对应的Stage已经存在与MapOutputTracker,那么number和位置输出的位置信息都可以从MapOutputTracker找到
private def newOrUsedShuffleStage(
shuffleDep: ShuffleDependency[, , _],
firstJobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
val numTasks = rdd.partitions.length
val stage = newShuffleMapStage(rdd, numTasks, shuffleDep, firstJobId, rdd.creationSite)
if (mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
val serLocs = mapOutputTracker.getSerializedMapOutputStatuses(shuffleDep.shuffleId)
val locs = MapOutputTracker.deserializeMapStatuses(serLocs)
for (i <- 0 until locs.length) {
stage.outputLocs(i) = Option(locs(i)).toList // locs(i) will be null if missing
}
stage.numAvailableOutputs = locs.count(_ != null)
} else {
// Kind of ugly: need to register RDDs with the cache and map output tracker here
// since we can't do it in the RDD constructor because # of partitions is unknown
logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}
2.Stage描述
一个Stage是一组并行的tasks;一个Stage可以被多个Job共享;一些Stage可能没有运行所有的RDD的分区,比如first 和 lookup;Stage的划分是通过是否存在Shuffle为边界来划分的,Stage的子类有两个:ResultStage和ShuffleMapStage
对于窄依赖生成的是ResultStage,对于宽依赖生成的是ShuffleMapStage。当ShuffleMapStages执行完后,产生输出文件,等待reduce task去获取,同时,ShffleMapStages也可以通过DAGScheduler的submitMapStage方法独立作为job被提交
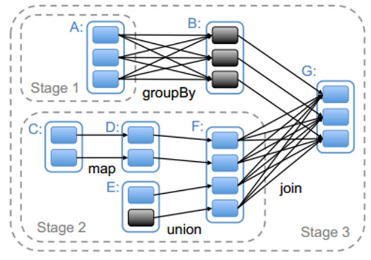
stage划分示意图
下一篇我们看Stage如何提交的。
【原】Spark中Job如何划分为Stage的更多相关文章
- 【Spark篇】--Spark中的宽窄依赖和Stage的划分
一.前述 RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖. Spark中的Stage其实就是一组并行的任务,任务是一个个的task . 二.具体细节 窄依赖 父RDD和子RDD parti ...
- 【原】Spark中Stage的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Job如何划分为Stage http://www.cnblogs.com/yourarebest/p/5342424.html 1 ...
- spark 中划分stage的思路
窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用,表现为 一个父RDD的分区对应于一个子RDD的分区 两个父RDD的分区对应于一个子RDD 的分区. 宽依赖指子RDD的每个分区都要依赖于父RD ...
- 【原】 Spark中Task的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Stage的提交 http://www.cnblogs.com/yourarebest/p/5356769.html Spark中 ...
- 【原】Spark中Job的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. Spark程序程序job的运行是通过actions算子触发的,每一个action算子其实是一个runJob方法的运行,详见文章 SparkContex源码 ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- 【原】 Spark中Worker源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Worker源码分析(一)http://www.cnblogs.com/yourarebest/p/5300202.html 4.receive方法, r ...
- Spark中Task,Partition,RDD、节点数、Executor数、core数目的关系和Application,Driver,Job,Task,Stage理解
梳理一下Spark中关于并发度涉及的几个概念File,Block,Split,Task,Partition,RDD以及节点数.Executor数.core数目的关系. 输入可能以多个文件的形式存储在H ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
随机推荐
- python 中函数的参数
一.python中的函数参数形式 python中函数一般有四种表现形式: 1.def function(arg1, arg2, arg3...) 这种是python中最常见的一中函数参数定义形式,函数 ...
- c++ union学习
看到公司前辈的代码中用到了union,不管是大学还是工作用到union机会比较少,还是挺新奇的.所以特意找些资料学习学习 前辈的代码: #include<iostream> using n ...
- 17款code review工具
本文是码农网原创翻译,转载请看清文末的转载要求,谢谢合作! 好的代码审查器可以大大地帮助程序员提高代码质量,减少错误几率. 虽然现在市场上有许多可用的代码审查工具,但如何挑选也是一个艰巨的任务.在咨询 ...
- SVN服务器使用(二)
上篇主要介绍的VisualSVN Server 安装,这篇主要介绍VisualSVN Server 的使用. 首先打开VisualSVN Server Manager,如图: 可以在窗口的右边看到版本 ...
- 【弱省胡策】Round #7 Rectangle 解题报告
orz PoPoQQQ 的神题. 我的想法是:给每一个高度都维护一个 $01$ 序列,大概就是维护一个 $Map[i][j]$ 的矩阵,然后 $Map[i][j]$ 表示第 $i$ 根柱子的高度是否 ...
- sjtu1590 强迫症
Description BS96发布了一套有\(m\)个band柄绘的新badge,kuma先生想要拿到04的badge于是进行了抽抽抽. kuma先生一共抽了\(n\)个badge.他把所有的bad ...
- 把硬盘格式化成ext格式的cpu占用率就下来了
把硬盘格式化成ext格式的cpu占用率就下来了我是使用ext4格式 @Paulz 还有这种事情? 现在是什么格式?- - ,你自己用top命令看一下啊就知道什么东西在占用cpu了下载软件一半cpu都用 ...
- 二维图形的矩阵变换(二)——WPF中的矩阵变换基础
原文:二维图形的矩阵变换(二)--WPF中的矩阵变换基础 在前文二维图形的矩阵变换(一)——基本概念中已经介绍过二维图像矩阵变换的一些基础知识,本文中主要介绍一下如何在WPF中进行矩阵变换. Matr ...
- Android TextView自动实现省略号
TextView自带的可以通过 android:ellipsize="end" android:singleLine="true"实现单行省略, 但是当我们需 ...
- Context 之我见
Context这个单词在程序开发中屡见不鲜,我记得以前在博客中写过一些关于这个词语的自我解释,但是我这个人有一个毛病就是健忘,如果不将自己的想法写下,不出十分钟,就被我抛到九霄云外. 真我现在还有点想 ...