SQL Server 脚本语句
一、语法结构

select select_list
[ into new_table ]
from table_source
[ where search_condition ]
[ group by broup_by_expression ]
[ having search_condition ]
[order by order_by_expression [ asc | desc ]
select查询语句中的主要参数说明如下
select_list:查询的列或者表达式的列表,用逗号进行分隔。 new_table:新的表名。 table_source:要查询的表。如果是多个表,用逗号进行分隔。 search_condition:查询条件。 group_by_expression:分组表达式。 order_by_expression:排序表达式。 asc:升序排序。 desc:降序排序。
select查询语句字句的功能列表
| 子句 | 主要功能 | 是否必需 |
| select | 指定由查询返回的列 | 是 |
| from | 指定要查询的表 | 是 |
| into | 创建新表并将结果行插入新表中 | 否 |
| where | 查询条件 | 否 |
| group by | 对查询结果进行分组 | 否 |
| order by | 对查询结果进行排序 | 否 |
| having | 对查询结果进行筛选 |
否 |
二、选择列表
选择列表用于定义select语句的结果集中的列
1、* 查询所有列:
select * from person
*就是结果集合,表示查询person表中的所有列。
2、distinct 去除重复数据:
distinct是对所有列作用,也就是说,所有列都相同才算重复数据。
select distinct name from person
3、包含函数的查询:
例如:
select count(*) from person
三、from子句
from子句实际上就是用逗号分隔的表名、视图名和join字句的列表。使用from子句可以实现如下功能:
1、列出选择列表和where子句引用的列所在的表和视图。可以使用as子句为表和视图指定别名。
2、联接类型。这些类型由on子句中指定的联接条件限定。
分配表名时可以使用如下形式
- table_name as table alias
- table_name as table_alias
需要特别说明的是,如果为表分配了别名,那么T-SQL语句中对该表的所有显示引用都必须使用别名,而不能使用别名。
四、where子句
where子句可以筛选结果集的源表中的行。带有where子句的select语句的结构如下:
select <字段列表>
from <表名>
where<条件表达式>
其中,条件表达式是由各种字段、常量、表达式、关系运算符、逻辑运算符和特殊的运算符组合起来的。
where子句中的运算符:
1、关系运算符
关系运算符用来表示两个表达式之间的比较关系。
| 关系运算符 | 含义 |
| = | 等于 |
| < | 小于 |
| > | 大于 |
| !=(或<>) | 不等于 |
| >= | 大于等于 |
| <= | 小于等于 |
| !> | 不大于 |
| !< | 不小于 |
2、逻辑运算符
逻辑运算符用于表示两个表达式之间的逻辑关系:
| 逻辑运算符 | 含义 |
| not | 非(否) |
| and | 与 |
| or | 或 |
3、特殊运算符
| 特殊运算符 | 含义 |
| % | 通配符,通常与like配合使用 |
| _ | 通配符,代表严格的一个字符。where name like '_xxx'将查找以xxx结尾的所有4个字母的名字(sxxx,dxxx等) |
| [] | 指定范围([a-f])或集合([abcdefg])中的任何单个字符。where name like '[a-f]xxxx',将超找以abcdef开头,xxxx结尾的字符。 |
| [^] | 不属于指定范围的([a-f])或集合([abcdefg])的任何单个字符。 |
| between | 定义一个取值范围区间,使用and分开。between开始值与and结束值。 |
| like | 字符串匹配 |
| in | 一个字段的值是否在一组定义的值之中 |
| exists | 子查询有结果集返回(则子查询返回True) |
| not exists | 子查询没有结果集返回(则子查询返回True) |
| is null | 字段是否为null |
| is not null | 字段是否不为null |
在WHERE子句中使用EXISTS(如果使用得当的话)可以大大提高性能。因为使用EXISTS时,只要找到和条件匹配的记录,SQL Server就立即停止。假设有一个包含一百万条记录的表,并且在第三个记录中找到了匹配的记录,那么使用EXISTS选项将避免读取999997条记录!NOT EXISTS以同样的方式工作。
五、group by子句
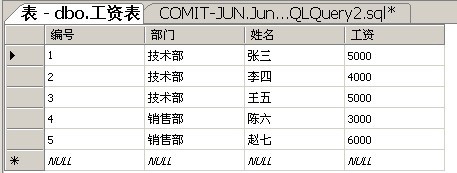
为了最简单地说明问题,我特地设计了一张这样的表。
一、GROUP BY单值规则
规则1:单值规则,跟在SELECT后面的列表,对于每个分组来说,必须返回且仅仅返回一个值。
典型的表现就是跟在SELECT后面的列,如果没有使用聚合函数,必须出现在GROUP BY子句后面。
如下面这个查询报错:
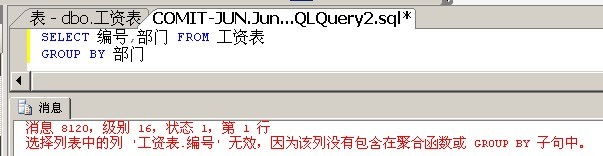
因为对于按照部门分组之后,技术部分组有3个编号,销售部分组有2个编号,你让数据库显示哪个呢?
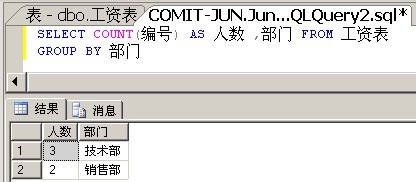
如果假设你使用聚合函数COUNT(编号)之后,对于每个部门分组,就只有一个值 - 该部门下的人数:
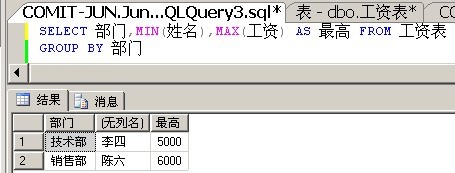
下面来实战下,我们希望查询出每个部门,最高工资的那个人的姓名,部门,工资。
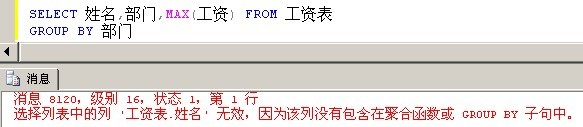
Shit,出师不利。第一次实战就错误了,我们来分析下。
很明显,上面的姓名列是不符合单值规则的。我们的一厢情愿想法是,MAX(工资)之后,SQL Server就能自动帮我们返回不符合单值规则的'姓名'。但是很遗憾,SQL Server并没有这么做。理由如下:
- 如果两个人的工资相同,那么应该将哪个人的姓名返回?
- 如果我们使用的不是MAX()聚合函数,而是SUM、AVG等聚合函数(没有与之匹配的工资),那么姓名返回哪个?
- 如果在查询语句中使用了两个聚合函数,如MAX(),MIN()。那么应该返回的是MAX工资的姓名,还是MIN工资的姓名呢?
综上所述,数据库是不可能能够根据我们输入的一个聚合函数,就帮助我们判断并显示出不符合单值规则的列的。
对于MYSQL来说,当有这种不符合单值规则的列时,默认是返回这一组结果的第一条记录。而SQLite是返回最后一条。
因此,对于以上查询,我们要另寻解决方案。
解决方案1:关联子查询
SELECT 姓名,部门,工资 FROM 工资表 AS T1
WHERE NOT EXISTS (SELECT NULL FROM 工资表 AS T2 WHERE T1.部门 = T2.部门 AND T2.工资 > T1.工资)
输出如下:
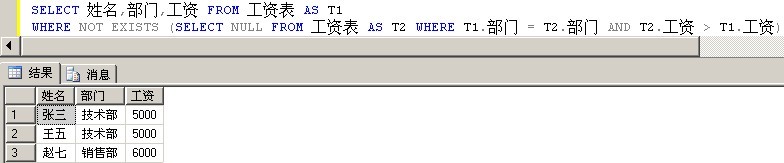
完全符合要求。对于上面的关联子查询,可以理解为:
遍历工资表的所有记录,查找不存在比当前记录部门相同且工资还大的记录。
虽然,关联子查询的语法非常简单,但是性能并不好。因为对于每一条记录,都要执行一次子查询。
解决方案2:衍生表
使用衍生表的思路是,先执行一个子查询,得到一个临时结果集,然后用临时结果集和原表进行INNER JOIN操作。就能得到最高工资的人的信息。
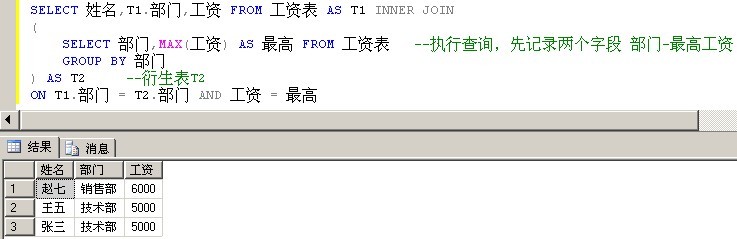
刚写出这个SQL语句时,觉得非常妙,理解了之后觉得非常妙。
SELECT 姓名,T1.部门,工资 FROM 工资表 AS T1 INNER JOIN
(
SELECT 部门,MAX(工资) AS 最高 FROM 工资表 --执行查询,先记录两个字段 部门-最高工资
GROUP BY 部门
) AS T2 --衍生表T2
ON T1.部门 = T2.部门 AND 工资 = 最高
衍生表的方式性能优于关联子查询,因为衍生表的方式只执行了一次子查询。但是它需要一张临时表来存储临时记录。因此,这个方案也并不是最佳的解决方案。
解决方案3:使用JOIN + IS NULL
这是一个更妙的解决方案,当我们用一个外联结去匹配记录时,当匹配的记录不存在,就会用NULL来代替相应的列。
我们先来看一条非常简答的SQL语句:

从中你看到了什么?当T2表中,不存在比T1表中工资高的记录时就返回NULL。
那么,那么,那么一个IS NULL是不是就解决问题了呢?
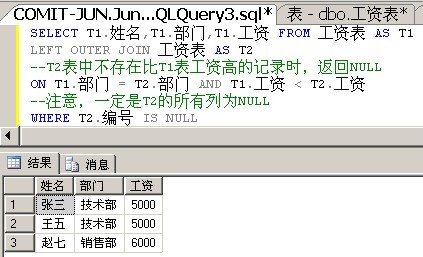
好妙,好妙的方法,让人拍案叫绝的使用了OUTER JOIN。
JOIN解决方案适用于针对大量数据查询并且可伸缩比较时。它总是能比基于子查询的解决方案更好地适应数据量的变量。
解决方案4:对额外的列使用聚合函数
我们知道,GROUP BY时,SELECT列表必须返回的是单值,那么我们可不可以通过使用聚合函数,让这个列返回单值呢?答案是可以的。
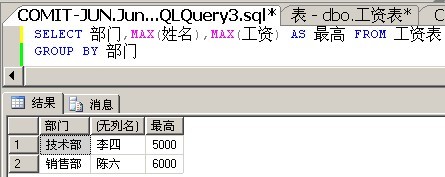
其实,返回的数据是有问题的,当工资相同时,它就返回按姓名从大到小排列的第一个姓名。也就是说,当工资相同时,它只能够返回一条记录。
我们将聚合函数换成MIN看看。
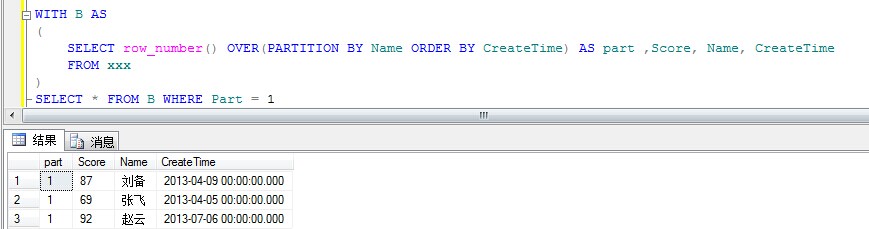
解决方案5:Row_Number() + OVER
WITH B AS
(
SELECT row_number() OVER(PARTITION BY Name ORDER BY CreateTime) AS part ,Score, Name, CreateTime
FROM xxx
)
SELECT * FROM B WHERE Part = 1
输出如下:
二、HAVING的理解
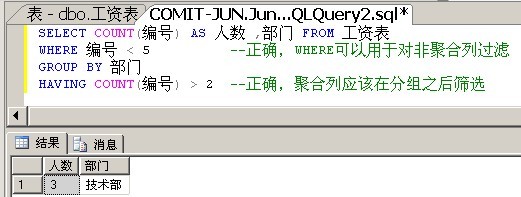
WHERE与HAVING的区别:
- WHERE(分组前过滤):WHERE不能对聚合函数列进行过滤,因为执行WHERE的时候,分组尚未执行,聚合函数也未执行。
- HAVING(分组后过滤):主要用于对聚合函数列进行过滤,因为HAVING实在分组之后执行的。HAVING子句只能配合GROUP BY子句使用。没有GROUP BY子句时不能使用HAVING。
错误使用WHERE的示例:

正确使用WHERE与HAVING的示例:
为了最简单地说明问题,我特地设计了一张这样的表。
一、GROUP BY单值规则
规则1:单值规则,跟在SELECT后面的列表,对于每个分组来说,必须返回且仅仅返回一个值。
典型的表现就是跟在SELECT后面的列,如果没有使用聚合函数,必须出现在GROUP BY子句后面。
如下面这个查询报错:
因为对于按照部门分组之后,技术部分组有3个编号,销售部分组有2个编号,你让数据库显示哪个呢?
如果假设你使用聚合函数COUNT(编号)之后,对于每个部门分组,就只有一个值 - 该部门下的人数:
下面来实战下,我们希望查询出每个部门,最高工资的那个人的姓名,部门,工资。
Shit,出师不利。第一次实战就错误了,我们来分析下。
很明显,上面的姓名列是不符合单值规则的。我们的一厢情愿想法是,MAX(工资)之后,SQL Server就能自动帮我们返回不符合单值规则的'姓名'。但是很遗憾,SQL Server并没有这么做。理由如下:
- 如果两个人的工资相同,那么应该将哪个人的姓名返回?
- 如果我们使用的不是MAX()聚合函数,而是SUM、AVG等聚合函数(没有与之匹配的工资),那么姓名返回哪个?
- 如果在查询语句中使用了两个聚合函数,如MAX(),MIN()。那么应该返回的是MAX工资的姓名,还是MIN工资的姓名呢?
综上所述,数据库是不可能能够根据我们输入的一个聚合函数,就帮助我们判断并显示出不符合单值规则的列的。
对于MYSQL来说,当有这种不符合单值规则的列时,默认是返回这一组结果的第一条记录。而SQLite是返回最后一条。
因此,对于以上查询,我们要另寻解决方案。
解决方案1:关联子查询
SELECT 姓名,部门,工资 FROM 工资表 AS T1
WHERE NOT EXISTS (SELECT NULL FROM 工资表 AS T2 WHERE T1.部门 = T2.部门 AND T2.工资 > T1.工资)
输出如下:
完全符合要求。对于上面的关联子查询,可以理解为:
遍历工资表的所有记录,查找不存在比当前记录部门相同且工资还大的记录。
虽然,关联子查询的语法非常简单,但是性能并不好。因为对于每一条记录,都要执行一次子查询。
解决方案2:衍生表
使用衍生表的思路是,先执行一个子查询,得到一个临时结果集,然后用临时结果集和原表进行INNER JOIN操作。就能得到最高工资的人的信息。
刚写出这个SQL语句时,觉得非常妙,理解了之后觉得非常妙。
SELECT 姓名,T1.部门,工资 FROM 工资表 AS T1 INNER JOIN
(
SELECT 部门,MAX(工资) AS 最高 FROM 工资表 --执行查询,先记录两个字段 部门-最高工资
GROUP BY 部门
) AS T2 --衍生表T2
ON T1.部门 = T2.部门 AND 工资 = 最高
衍生表的方式性能优于关联子查询,因为衍生表的方式只执行了一次子查询。但是它需要一张临时表来存储临时记录。因此,这个方案也并不是最佳的解决方案。
解决方案3:使用JOIN + IS NULL
这是一个更妙的解决方案,当我们用一个外联结去匹配记录时,当匹配的记录不存在,就会用NULL来代替相应的列。
我们先来看一条非常简答的SQL语句:
从中你看到了什么?当T2表中,不存在比T1表中工资高的记录时就返回NULL。
那么,那么,那么一个IS NULL是不是就解决问题了呢?
好妙,好妙的方法,让人拍案叫绝的使用了OUTER JOIN。
JOIN解决方案适用于针对大量数据查询并且可伸缩比较时。它总是能比基于子查询的解决方案更好地适应数据量的变量。
解决方案4:对额外的列使用聚合函数
我们知道,GROUP BY时,SELECT列表必须返回的是单值,那么我们可不可以通过使用聚合函数,让这个列返回单值呢?答案是可以的。
其实,返回的数据是有问题的,当工资相同时,它就返回按姓名从大到小排列的第一个姓名。也就是说,当工资相同时,它只能够返回一条记录。
我们将聚合函数换成MIN看看。
解决方案5:Row_Number() + OVER
WITH B AS
(
SELECT row_number() OVER(PARTITION BY Name ORDER BY CreateTime) AS part ,Score, Name, CreateTime
FROM xxx
)
SELECT * FROM B WHERE Part = 1
输出如下:
二、HAVING的理解
WHERE与HAVING的区别:
- WHERE(分组前过滤):WHERE不能对聚合函数列进行过滤,因为执行WHERE的时候,分组尚未执行,聚合函数也未执行。
- HAVING(分组后过滤):主要用于对聚合函数列进行过滤,因为HAVING实在分组之后执行的。HAVING子句只能配合GROUP BY子句使用。没有GROUP BY子句时不能使用HAVING。
错误使用WHERE的示例:
正确使用WHERE与HAVING的示例:
六、order by子句
order by子句用于指定结果集的排序
1、语法结构:
select <字段名列表>
from 数据库表名
[where <条件表达式>]
[order by[<字段名或者表达式> [asc|desc],...]]
order by子句可以搭配where子句,也可以和select、fromD搭配使用,而不需要where子句。
order by子句的语法如下:
[ order by { order_by_expression [ asc | desc] } [ ,...n ] ]
其中主要的参数说明如下:
order_by_espression:指定要排序的列、列的别名、表达式或者指定为代表选择列表内的名称、别名或表达式的位置的负整数。
asc:按递增顺序对指定列中的值进行排序。
desc:按递减顺序对指定列中的值进行排序。
七、having筛选查询
详见地址:http://www.cnblogs.com/kissdodog/p/3365789.html
八、into查询
into子句将查询结果生成新表,新表的结构由查询字段列表组成。也可以将查询的结果送入tempdb数据库的临时表中,这样关闭服务器之后临时表会自动删除。
into查询的语法结构:
SELECT <字段名列表>
[ into 新的数据表名 ]
FROM 数据库表名
[ where <条件表达式> ]
SQL Server 脚本语句的更多相关文章
- SQL server脚本语句积累
1:往现有的表中增加一个字段 IF NOT EXISTS ( SELECT 1 FROM sys.sysobjects so WITH ( NOLOCK ) INNER JOIN sys.syscol ...
- sql server 脚本创建数据库邮件
sql server 脚本创建数据库邮件代码: --脚本创建数据库邮件 --1.开启数据库邮件 RECONFIGURE WITH OVERRIDE GO RECONFIGURE WITH OVERRI ...
- Sql Server脚本使用TFS版本控制
原文:Sql Server脚本使用TFS版本控制 1.安装TFS插件 Microsoft Visual Studio Team Foundation Server 2010 MSSCCI Provid ...
- 如何在SQL Server查询语句(Select)中检索存储过程(Store Procedure)的结果集?
如何在SQL Server查询语句(Select)中检索存储过程(Store Procedure)的结果集?(2006-12-14 09:25:36) 与这个问题具有相同性质的其他描述还包括:如何 ...
- SQL Server分页语句ROW_NUMBER,读取第4页数据,每页10条
SQL Server分页语句ROW_NUMBER,读取第4页数据,每页10条 SELECT Id,[Title],[Content],[Image] FROM ( SELECT ROW_NUMBER( ...
- SQL Server UPDATE语句的用法详解
SQL Server UPDATE语句用于更新数据,下面就为您详细介绍SQL Server UPDATE语句语法方面的知识,希望可以让您对SQL Server UPDATE语句有更多的了解. 现实应用 ...
- SQL Server中语句的自动参数化
原文:SQL Server中语句的自动参数化 use master go if exists(select * from sys.databases where name = 'test') drop ...
- 获取某月第一天,最后一天的sql server脚本 【转】http://blog.csdn.net/chaoowang/article/details/9167969
这是计算一个月第一天的SQL 脚本: SELECT DATEADD(mm, DATEDIFF(mm,0,getdate()), 0) --当月的第一天 SELECT DATEADD(mm, DA ...
- 获取某月第一天,最后一天的sql server脚本
本文来自:http://blog.csdn.net/chaoowang/article/details/9167969 这是计算一个月第一天的SQL 脚本: SELECT DATEADD(mm, ...
随机推荐
- HDU5673 Robot 默慈金数
分析: 注:然后学了一发线性筛逆元的姿势 链接:http://blog.miskcoo.com/2014/09/linear-find-all-invert #include<iostream& ...
- HDU-1240 Asteroids! (BFS)这里是一个三维空间,用一个6*3二维数组储存6个不同方向
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Submission ...
- PL/SQL连接查询数据报错时Dynamic Performance Tables not accessible
一.产生该提示原因plsql dev在用户运行过程中,要收集用户统计信息,但是由于你现在登录的用户没有访问v$session,v$sesstat and v$statname视图的权限,所以不能收集当 ...
- org.apache.hadoop.io.LongWritable cannot be cast to org.apache.hadoop.io.Text
代码缺少这一行:job.setInputFormatClass(KeyValueTextInputFormat.class);
- BestCoder Round #81 (div.2) B Matrix
B题...水题,记录当前行是由原矩阵哪行变来的. #include<cstdio> #include<cstring> #include<cstdlib> #inc ...
- 《Genesis-3D开源游戏引擎--横版格斗游戏制作教程04:技能的输入与检测》
4.技能的输入与检测 概述: 技能系统的用户体验,制约着玩家对整个游戏的体验.游戏角色的技能华丽度,连招的顺利过渡,以及逼真的打击感,都作为一款游戏的卖点吸引着玩家的注意.开发者在开发游戏初期,会根据 ...
- 关于Eclispse连接Mysql的Jdbc
1.在Eclipse中新建Java工程 2.引入JDBC库(在bulid path 的extenrnal里) 3. 1)导入sql包(import java.sql.*) 2)加载(注册)mysql ...
- HDOJ-ACM2035(JAVA) 人见人爱A^B
这道题的巧妙方法没有想出来,但是算是优化的暴力破解吧.Accepted import java.io.BufferedInputStream; import java.util.Scanner; pu ...
- algorithm@ dijkstra algorithm & prim algorithm
#include<iostream> #include<cstdio> #include<cstring> #include<limits> #incl ...
- 通过一张简单的图,让你彻底地搞懂JS的==运算
大家知道,JavaScript中的==是一种比较复杂运算,它的运算规则很奇怪,很容易让人犯错,从而成为JavaScript中“最糟糕的特性”之一. 在仔细阅读ECMAScript规范的基础上,我画了一 ...