【原创】Hadoop机架感知对性能调优的理解
Hadoop作为大数据处理的典型平台,在海量数据处理过程中,其主要限制因素是节点之间的数据传输速率。因为集群的带宽有限,而有限的带宽资源却承担着大量的刚性带宽需求,例如Shuffle阶段的数据传输不可避免,所以如何优化带宽资源的占用是一个值得思考的问题。仔细思考下,Hadoop数据传输的需求主要表现在几个方面:
- Map阶段的数据传输:Map阶段的非本地化任务需要远程拷贝数据块,然而这种带宽消耗在一定程度上不是必要的,如果数据能做到很高程度的本地化可以减少这个阶段的数据传输带来的带宽消耗。
- Shuffle阶段的数据传输:Map阶段的中间数据集需要传输到Reduce端需要大量的带宽资源。
- Reduce阶段的计算结果保存:Reduce端最终的计算结果需要保存到HDFS上,这种带宽的消耗也是不可避免的。
不过还好,Hadoop的设计者们在最初就考虑到了这个问题,所以在Map阶段的任务调度过程中做了一定程度的优化。当一个有空闲资源的TT(TaskTracker)向JT(JobTracker)申请任务的时候,JT会选择一个最靠近TT的任务给它,选择的原则是:
- TT本地是否有未处理的任务,有则调度之;
- TT本地没有未处理的任务,则调度一个和TT同一个机架上的任务给它;
- 否则,调度一个本数据中心的任务给他。
然而,我们会思考JT使如何知道这种结构关系的呢?为啥就知道另一个节点就是和这个TT是同一个机架或者数据中心的呢?这就要追溯到Hadoop的机架感知功能了。
- 什么是机架感知
机架感知是一种计算不同计算节点(TT)的距离的技术,用以在任务调度过程中尽量减少网络带宽资源的消耗,这里用尽量,想表达的是当一个TT申请不到本地化任务时,JT会尽量调度一个机架的任务给他,因为不同机架的网络带宽资源比同一个机架的网络带宽资源更可贵。当然,机架感知不仅仅用在MR中,同样还用在HDFS数据块备份过程中(第一个replica选择本节点【如果上传是DataNode】或者随机的一个DN(系统会尽量避免存储太满和太忙的节点),第二个节点选择于第一个节点不同机架的DN,第三个选择放在第二个DN同一个机架的另一个DN上)
- 机架感知实战
首先,看下面这个图的一个集群结构,D1和D2是两个数据中心,下面各有两个机架,然后叶子节点是DN。
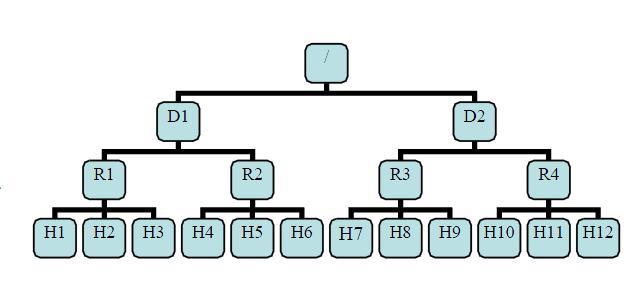
此时H1和H2是同一个Rack的,H1和H4是同一个数据中心的。而H1和H7是不同数据中心的。
然而,上面这种树结构不是Hadoop自己就自动建立的,需要用户的手动设置协助。在小型的集群中和单机测试中,一般是用不着配置的,所以机架感知功能默认是关闭的。
要设置机架感知,用户需要自己编写脚本来定义节点的映射关系和配置conf/core-site.xml文件的属性来启动机架感知。
一个脚本实例程序如下面的例子所示,定义了一个rack字典,里面有每个hostname对应的rack信息,后面也给出了每个IP对应的rack信息。将这段脚本程序放在每个节点的hadoop/bin/目录下,包括主节点。
#!/usr/bin/python
#-*-coding:utf-8 -*-
import sys
rack = {
"brix-01":"rack1",
"brix-02":"rack1",
"brix-03":"rack1",
"brix-04":"rack1",
"brix-05":"rack1",
"brix-06":"rack1",
"brix-07":"rack1",
"brix-08":"rack1",
"brix-09":"rack1",
"192.168.1.231":"rack1",
"192.168.1.232":"rack1",
"192.168.1.233":"rack1",
"192.168.1.234":"rack1",
"192.168.1.235":"rack1",
"192.168.1.236":"rack1",
"192.168.1.237":"rack1",
"192.168.1.238":"rack1",
"192.168.1.239":"rack1"
} if __name__=="__main__":
print "/"+rack.get(sys.argv[1],"rack0")
写好脚本程序后,然后配置core-site.xml文件,添加如下属性:
<property>
<name>topology.script.file.name</name>
<value>/home/hadoop/hadoop/bin/RackAware.py</value>
</property>
<property>
<name>topology.script.number.args</name>
<value>18</value>
</property>
在第一次,故意将脚本程序写错,发现启动集群后观察日志发现接收到heartbeat信息后会报错,这说明,JT在得知启动机架感知后,在收到TT的心跳信息后会将其地址作为参数传入脚本,找到其对应的rack,然后将这些信息保存到内存中。
2014-11-17 21:15:24,658 INFO org.apache.hadoop.mapred.JobTracker: Lost tracker 'tracker_brix-03:localhost/127.0.0.1:39733'
2014-11-17 21:15:24,658 INFO org.apache.hadoop.ipc.Server: IPC Server handler 4 on 19001, call heartbeat(org.apache.hadoop.mapred.TaskTrackerStatus@47d2a09d, true, true, true, -1) from 192.168.1.236:53534:
error: java.io.IOException: java.lang.NullPointerException
java.io.IOException: java.lang.NullPointerException
at org.apache.hadoop.mapred.JobTracker.resolveAndAddToTopology(JobTracker.java:2385)
at org.apache.hadoop.mapred.JobTracker.addNewTracker(JobTracker.java:2377)
at org.apache.hadoop.mapred.JobTracker.processHeartbeat(JobTracker.java:2756)
at org.apache.hadoop.mapred.JobTracker.heartbeat(JobTracker.java:2556)
at sun.reflect.GeneratedMethodAccessor6.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:483)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:508)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:959)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:955)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:954)
2014-11-17 21:15:24,677 WARN org.apache.hadoop.net.ScriptBasedMapping: org.apache.hadoop.util.Shell$ExitCodeException: File "/home/hadoop/hadoop/bin/RackAware.py", line 6
"brix-02":"rack1"
^
SyntaxError: invalid syntax
2014-11-17 21:20:05,848 INFO org.apache.hadoop.mapred.JobTracker: Starting RUNNING
2014-11-17 21:20:05,858 INFO org.apache.hadoop.ipc.Server: IPC Server handler 9 on 19001: starting
2014-11-17 21:20:05,985 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/brix-02
2014-11-17 21:20:06,012 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/brix-03
2014-11-17 21:20:06,037 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/brix-01
2014-11-17 21:20:06,078 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/brix-04
2014-11-17 21:20:06,099 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/brix-07
2014-11-17 21:20:06,127 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/brix-08
2014-11-17 21:20:06,151 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/brix-09
2014-11-17 21:20:06,173 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/brix-05
2014-11-17 21:20:06,193 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/brix-06
配置正确后,启动集群观察JT的日志发现建立了机架的拓扑关系了。
【原创】Hadoop机架感知对性能调优的理解的更多相关文章
- 性能调优:理解Set Statistics Time输出
在性能调优:理解Set Statistics IO输出我们讨论了Set Statistics IO,还有如何帮助我们进行性能调优.这篇文章会讨论下Set Statistics Time,它会告诉我们执 ...
- 性能调优:理解Set Statistics IO输出
性能调优是DBA的重要工作之一.很多人会带着各种性能上的问题来问我们.我们需要通过SQL Server知识来处理这些问题.经常被问到的一个问题是:早上这个存储过程运行时间还是可以的,但到了晚上就很慢很 ...
- [大牛翻译系列]Hadoop(9)MapReduce 性能调优:理解性能瓶颈,诊断map性能瓶颈
6.2 诊断性能瓶颈 有的时候作业的执行时间会长得惊人.想靠猜也是很难猜对问题在哪.这一章中将介绍如何界定问题,找到根源.涉及的工具中有的是Hadoop自带的,有的是本书提供的. 系统监控和Hadoo ...
- hadoop 性能调优与运维
hadoop 性能调优与运维 . 硬件选择 . 操作系统调优与jvm调优 . hadoop运维 硬件选择 1) hadoop运行环境 2) 原则一: 主节点可靠性要好于从节点 原则二:多路多核,高频 ...
- [大牛翻译系列]Hadoop(16)MapReduce 性能调优:优化数据序列化
6.4.6 优化数据序列化 如何存储和传输数据对性能有很大的影响.在这部分将介绍数据序列化的最佳实践,从Hadoop中榨出最大的性能. 压缩压缩是Hadoop优化的重要部分.通过压缩可以减少作业输出数 ...
- [大牛翻译系列]Hadoop(8)MapReduce 性能调优:性能测量(Measuring)
6.1 测量MapReduce和环境的性能指标 性能调优的基础系统的性能指标和实验数据.依据这些指标和数据,才能找到系统的性能瓶颈.性能指标和实验数据要通过一系列的工具和过程才能得到. 这部分里,将介 ...
- 【原创】构建高性能ASP.NET站点 第五章—性能调优综述(后篇)
原文:[原创]构建高性能ASP.NET站点 第五章-性能调优综述(后篇) 构建高性能ASP.NET站点 第五章—性能调优综述(后篇) 前言:本篇主要讲述如何根据一些简单的工具和简单的现象来粗布的定位站 ...
- Hadoop作业性能指标及參数调优实例 (二)Hadoop作业性能调优7个建议
作者:Shu, Alison Hadoop作业性能调优的两种场景: 一.用户观察到作业性能差,主动寻求帮助. (一)eBayEagle作业性能分析器 1. Hadoop作业性能异常指标 2. Hado ...
- 【原创】SQL Server 性能调优读书笔记
CPU 100%: 有时可能是硬盘性能不足,或者内存容量不够,让CPU一直忙于I/O. 导致性能问题的一些因素: 用户习惯:在运行尖峰时刻做一些不必做但消耗资源的事情,如之行数据库完整备份,如在服务器 ...
随机推荐
- 6 款国外开源web oa办公系统(转)
国外的开源产品较多,而且大多提供免费的社区版本,oa办公系统也不例外. 1.eGroupware eGroupware是一个多用户,在以PHP为基础的API上的定制集为基础开发的,以WEB为基础的工作 ...
- 学习lamda表达式
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.L ...
- [转载]MongoDB的真正性能
最近开始研究MySQL和MongoDB,发现这方面资料不多.尤其是真正的说到点子上的文章,太少了. 有一些对比测试的文章基本上都是瞎测,测试方法都测到了马腿上,得出的结论基本上都是NoSQL毫无价值 ...
- 卡牌手游源码《暗黑世界V1.3》数据库表说明文档!!!
原地址:http://blog.csdn.net/uxqclm/article/details/11970761 欢迎来到9秒:www.9miao.com 由于看到论坛中有人询问需求<暗黑世界V ...
- U3D版本《暗黑世界V1.0》编译——图文教程!
原地址:http://blog.csdn.net/uxqclm/article/details/11970773 欢迎来到9秒:www.9miao.com 说明: A. 工具准备: ...
- 再硬写一个最简单的HTTPSERVER
参考同上一个贴: 纯于练手. #HTTPserver import socket HOST = '' PORT = 8088 text_content = '''HTTP/1.x 200 OK Con ...
- 禁用nginx的access日志
修改nginx.conf 找到access_log: access_log /dev/null; 或者access_log off
- UVA 10765 Doves and bombs
给定一个无向的连通图,要求每个点去掉后连通分量的数目,然后输出连通分量最多的m个点. 分析: 先求出双连通分量,然后统计所有双连通分量中割顶出现的次数,最后求出的就是割顶去掉后剩下的双连通的数目,对于 ...
- 李洪强漫谈iOS开发[C语言-019]-断点调试
- easyui源码翻译1.32--Dialog(对话框窗口)
前言 扩展自$.fn.window.defaults.使用$.fn.dialog.defaults重写默认值对象.下载该插件翻译源码 该对话框是一种特殊类型的窗口,它在顶部有一个工具栏,在底部有一个按 ...