关于Python文档读取UTF-8编码文件问题
近来接到一个小项目,读取目标文件中每一行url,并逐个请求url,拿到想要的数据。
#-*- coding:utf-8 -*-
class IpUrlManager(object):
def __init__(self):
self.newipurls = set()
#self.oldipurls = set() def Is_has_ipurl(self):
return len(self.newipurls)!=0 def get_ipurl(self):
if len(self.newipurls)!=0:
new_ipurl = self.newipurls.pop()
#self.oldipurls.add(new_ipurl)
return new_ipurl
else:
return None def download_ipurl(self,destpath):
try:
f = open(destpath,'r')
iter_f = iter(f)
lines = 0
for ipurl in iter_f:
lines = lines + 1
self.newipurls.add((ipurl.rstrip('\r\n'))
#log记录读取了多少行IP url
#print lines
finally:
if f:
f.close()
咋一眼看code写的没问题,每一个url 增加进newipurls set集合中。但是请求的过程中,requests.get后,会出现如下错误:
raise InvalidSchema("No connection adapters were found for '%s'" % url)

后来发现每次都是第一行的url请求失败。然后打印print 请求的url。也没发现异常。然后从根源上去找,好吧,print打印newipurls set集合看看。
果然,问题就在这里。

奇怪,为什么这个URL前面为默认加上了\xef\xbb\xbf 这几个字符呢?
上网看了一些资料,原来在python的file对象的readline以及readlines程序中,针对一些UTF-8编码的文件,开头会加入BOM来表明编码方式。
何为BOM?
所谓BOM,全称是Byte Order Mark,它是一个Unicode字符,通常出现在文本的开头,用来标识字节序(Big/Little Endian),除此以外还可以标识编码(UTF-8/16/32)。
其实如果大家有UltraEdit tool可以发现,在另存为文件的时候,可以保存为UTF-8 和UTF-8 无BOM的文件。
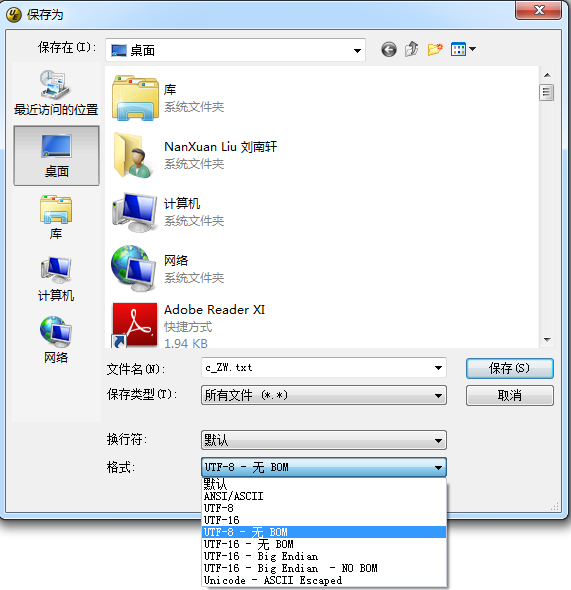
如果将文件另存在UTF-8的格式,则文件的开头默认会增加三个字节\xef\xbb\xbf。
怎么检测该文件是否为UTF-8 带BOM的呢?
import codecs
def download_ipurl(self,destpath):
try:
f = open(destpath,'r')
iter_f = iter(f)
lines = 0
for ipurl in iter_f:
lines = lines + 1
if ipurl[0:3] == codecs.BOM_UTF8:
self.newipurls.add((ipurl.rstrip('\r\n')).lstrip('\xef\xbb\xbf'))
#print self.newipurls
#log记录读取了多少行IP url
#print lines
finally:
if f:
f.close()
引用codecs模块,来判断前三个字节是否为BOM_UTF8。如果是,则剔除\xef\xbb\xbf字节。
其实大家可以通过其他方式剔除BOM字节,我写的比较粗糙。
关于Python文档读取UTF-8编码文件问题的更多相关文章
- 吴裕雄--天生自然python学习笔记:python文档操作批量替换 Word 文件中的文字
我们经常会遇到在不同的 Word 文件中的需要做相同的文字替换,若是一个一个 文件操作,会花费大量时间 . 本节案例可以找出指定目录中的所有 Word 文件(包含 子目录),并对每一个文件进行指定的文 ...
- python文档自动翻译
关键方法 提取文档内容 读取TXT文档 txt文档的读取很简单,直接用python自带的open()方法就好,代码如下所示: # 读取TXT文档 def read_txt(path): '''实现TX ...
- 基于 Python 官方 GitHub 构建 Python 文档
最近在学 Python,所以总是在看 Python 的官方文档, https://docs.python.org/2/ 因为祖传基因的影响,我总是喜欢把这些文档保存到本地,不过 Python 的文档实 ...
- python 文档
python 文档 https://docs.python.org/2/library/index.html
- Apache PDFbox开发指南之PDF文档读取
转载请注明来源:http://blog.csdn.net/loongshawn/article/details/51542309 相关文章: <Apache PDFbox开发指南之PDF文本内容 ...
- 9.9 Python 文档字符串
9.9 Python 文档字符串. 进入 Python 标准库所在的目录. 检查每个 .py 文件看是否有__doc__ 字符串, 如果有, 对其格式进行适当的整理归类. 你的程序执行完毕后, 应该会 ...
- 第8.19节 使用__doc__访问Python文档字符串(DocStrings )
__doc__特殊变量用于查看类.函数.模块的帮助信息,这些帮助信息存放在文档字符串中. 一. 关于文档字符串 关于文档字符串前面很多章节提到过,DocStrings 文档字符串用于程序的文档说明,并 ...
- 小讲堂:Mobox文档管理软件中的文件外链是什么?
今天我们来讨论Mobox文档管理软件中的文件外链是什么?熟悉MOBOX的朋友们应该知道,如果有文件需要分享给其他同事,直接可以进行文件共享.对方会在AM的即时通讯客户端有消息提醒,点击消息提醒可以看到 ...
- SharePoint 2010遍历文档库中所有的文件,文件夹
转:http://hi.baidu.com/sygwin/item/f99600849d51a12b110ef3eb 创建一个可视WebPart,并拖放一个label控件到ascx文件上,用于显示结果 ...
随机推荐
- Spring与SpringMVC的容器关系分析
Spring和SpringMVC作为Bean管理容器和MVC层的默认框架,已被众多WEB应用采用,而实际使用时,由于有了强大的注解功能,很多基于XML的配置方式已经被替代,但是在实际项目中,同时配置S ...
- 6种GET和POST请求发送方法
我试过了畅言和多说两种社会化评论框,后来还是抛弃了畅言,不安全. 无论是畅言还是多说,我都需要从远程抓取文章的评论数,然后存入本地数据库.对于多说,请求的格式如下: // 获取评论次数,参数是文章ID ...
- iOS状态栏颜色
下面截图给出修改 iOS 状态栏颜色的 4 种方式 Target.png Info.plist.png Storyboard.png code.png 其中第四张图中的代码,直接写在你的任何一个 Vi ...
- Web日程管理FullCalendar
fullcalendar是一款jQuery日程管理控件,提供了丰富的属性设置和方法调用,官网下载地址http://fullcalendar.io/download,眼下最新版本号是2.3.2. 仅仅要 ...
- Java数学表示式解析工具- jeval
这个包能够为我们提高高效的数学表达式计算. 举个样例:这个是我们策划给出的游戏命中率的一部份计算公式 是否命中=a命中率 – (b等级 – a等级) * (命中系数(6)* b闪避率 / 100)+3 ...
- [置顶] UNIX常用命令
scp命令用于两个机器之前文件的拷贝 scp 被拷贝文件 远程机器用户名@远程机器IP:拷贝目的目录或者拷贝目录下的目的文件 dos2unix 在执行编译文件时,本来应该生成可执行文件a,但是执行完后 ...
- hdu1258 Sum It Up (DFS)
Problem Description Given a specified total t and a list of n integers, find all distinct sums using ...
- Meth | phpstorm invalid descendent file name
Failed to collect files: Invalid descendent file name "codelog_ddz.\"(]))\",\').txt& ...
- 如何写好一个UITableView
本文是直播分享的简单文字整理,直播共分为上.下两部分. 第一部分: 优酷 :http://v.youku.com/v_show/id_XMTUzNzQzMDU0NA%3Cmark%3E.html Or ...
- navicat导入mysql数据库sql时报错或数据不完全问题
错误详情:[Err] [Imp] 2006 - MySQL server has gone away 或无提示错误,但是导入数据明显缺少字段和数据 找到服务器上的MYSQL安装目录下的my.ini文件 ...