Flask 模型操作
ORM
简称 ORM, O/RM, O/R Mapping
持久化模型
特征
- 数据表和编程类的映射
- 数据类型映射
- 字段属性映射类的属性和数据类型
- 关系映射
- 表于表之间的关系对应到 编程类的关系上
优点
数据操作和业务逻辑区分
封装了数据库操作, 提升效率
省略了庞大的数据访问层
链接数据库
flask中是不自带ORM的,如果在flask里面连接数据库有两种方式
- pymysql
- SQLAlchemy
是python 操作数据库的一个库。能够进行 orm 映射官方文档 sqlchemy
SQLAlchemy“采用简单的Python语言,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型”。
SQLAlchemy的理念是,SQL数据库的量级和性能重要于对象集合;而对象集合的抽象又重要于表和行。
SQLAlchemy 方式
链接数据库
链接语法
app.config['SQLALCHEMY_DATABASE_URL'] = "mysql://用户名:密码@数据库服务器地址:端口号/数据库名称"
实例
from flask import Flask
from flask_sqlalchemy import SQLAlchemy # 导入pymysql , 并且将其伪装成 ,MySQLdb
# import pymysql
# pymysql.install_as_MySQLdb() app = Flask(__name__) # 通过 app 配置数据库信息
# app.config['SQLALCHEMY_DATABASE_URI'] = "mysql://root:123456@127.0.0.1:3306/flask"
app.config['SQLALCHEMY_DATABASE_URI'] = "mysql+pymysql://root:123456@127.0.0.1:3306/flask" # 创建数据库实例
db = SQLAlchemy(app)
print(db) @app.route('/')
def hello_world():
return 'Hello World!' if __name__ == '__main__':
app.run()
定义模型( 重点 )
模型
根据数据库表结构而创建出来的类 ( 模型类, 实体类 )
1. 先创建实体类, 通过实体类自动生成表
2. 先创建表, 根据表借口编写实体类
语法
class MODELNAME(db.Model):
__tablename__ = "TABLENAME"
COLUMN_NAME = db.Column(db.TYPE, OPTIONS)
参数
"""
MODELNAME : 定义的模型类名称, 根据表名而设定
比如:
表名: USERS
MODELNAME : Users
TABLENAME : 要映射到数据库中表的名称
COLUMN_NAME : 属性名, 映射到数据库中的列名
TYPE : 映射到列的数据类型
类型 python类型 说明
Integer int 32 位整数
SmallInteger int 16 位整数
BiglInteger int 不限精度整数
Float float 浮点数
String str 字符串
Text str 字符串
Boolean bool 布尔值
Date datatime.date 日期类型
Time datatime.time 时间类型
DateTime datatime.datatime 时间和日期类型
OPTIONS : 列选项, 多个列选项用逗号隔开
选项名 说明
autoincrement 如果设置为 True, 表示该列自增, 列类型是整数且是主键, 默认自增
primary_key 如果设置为 Ture, 表示该列为主键
unique 如果设置为 Ture, 表示该列的值唯一
index 如果设置为 Ture, 表示该列的值要加索引
nullable 如果设置为 Ture, 表示该列的值可以为空
default 指定该列的默认值
"""
实例
"""
创建实体类 Users , 映射数据库中的 users 表
id 自增 主键
username 长度为 80 的字符串, 非空, 唯一, 加索引
age 整数 允许为空
email 长度 120 字符串 唯一
""" class Users(db.Model):
__tablename__ = 'users' # 如果表名为 users 的话可以省略
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), nullable=False, unique=True, index=True)
age = db.Column(db.Integer, nullable=True)
email = db.Column(db.String(120), unique=True)
应用模型
创建
db.create_all()
# 将所有的类创建到数据库上
# 只有类对应的表不存在才会创建, 否则无反应, 因此想更改表结构就必须删掉重建
# 由此可见此方法及其愚蠢
# 临时性的, 此方法一般都不会用, 不对, 是绝对不要用
删除
db.drop_all()
# 将所有的数据表全部删除
数据库迁移
实体类的改动映射回数据库
此操作需要依赖第三方库
如果不使用第三方库也想重写表结构
就只能全部删掉在全部创建, 极其智障.
1. flask-script
对于项目进行管理, 启动项目, 添加 shell 命令
包 flask-script
类 Manager
# 将 app 交给 Manager 管理
manager = Manager(app) if __name__ == '__main__':
# app.run(debug=True)
manager.run() """
命令行启动
python app.py runserver --port 5555
python app.py runserver --host 0.0.0.0
python app.py runserver --host 0.0.0.0 --port 5555
"""
2. flask_migrate
包 flask_migrate
类
Migrate 管理 app 和 db 中间的关系, 提供数据库迁移
MigrateCommand 允许终端中执行迁移命令
# 创建 Migrate 对象
migrate = Migrate(app, db) # 为 manager 增加子命令, 添加做数据库迁移的子命令manager.add_command('db', MigrateCommand) """
命令行执行
python app.py db init 初始化 一个项目中的 init 只执行一次即可, 生成 migrations 文件夹
python app.py db migrate 将编辑好的实体类生成中间文件, 只有在实体类有更改的时候才会生成
python app.py db upgrade 将中间文件映射回数据库
其他的命令可以通过 python app.py db 会进行查阅
"""
数据库修改
# 修改操作
# 创建实体类对象并赋值
user = Users()
user.username = 'yangtuo'
user.age = 18
user.email = '7452@qq.com'
# 将实体对象保存回数据库
db.session.add(user)
# 针对非查询操作, 必须手动操作提交
db.session.commit()
自动视图提交修改
每次进行修改都需要执行 add 以及 commit 略显繁琐
设置 SQLALCHEMY_COMMIT_ON_TEARDOWN 即可不需要手动更新, 但是仅局限于在 视图函数 中可以简化操作
# 配置数据库操作自动提交
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True @app.route('/add_user')
def add_view():
user = Users()
user.username = 'yangtuo'
user.age = 18
user.email = '7452@qq.com'
# 如果设置了 SQLALCHEMY_COMMIT_ON_TEARDOWN = True 则不需要进行 add 和 commit 操作
# db.session.add(user)
# db.session.commit()
return '增加数据成功'
数据库单表查询
语法
db.session.query(查询域).过滤方法(过滤条件).执行方法()
返回值
# 条件必须要由 实体类.属性 构成
db.session.query(Users).filter(age>18).all() # 错误
db.session.query(Users).filter(Users.age>18).all() # 正确
# 此命令支持跨表多个查询, 因此必须要带实体来进行查询
query = db.session.query(Users.id, Teacher.tanme)
query = db.session.query(Users, Teacher) # 查询 Users,Teacher 的所有的列 # 无执行方法的时候 返回值为一个 query 对象, 类型为 BaseQuery
print(query) # sql 语句
print(type(query)) # <class 'flask_sqlalchemy.BaseQuery'> # 有执行方法的时候 返回值为 列表
query = db.session.query(Users.id, Teacher.tanme).all()
print(query) # 列表
执行函数
# 执行函数
all() # 列表形式返回所有数据
first() # 返回实体对象第一条数据, 没有数据返回 None
fist_or_404() # 效果同上, 没有数据返回 404
count() # 返回查询结果数量
过滤函数
# 过滤器
filter() # 指定查询条件 ( 所有条件都可以 )
filter_by() # 等值条件中使用( 只能做 = 操作, > < 都不行, 注意不是 == )
limit() # 限制访问条数
order_by() # 排序
group_by() # 分组
与查询
# 多条件查询
# 链式操作或者逗号隔开表示并列条件
db.session.query(Users).filter(Users.age>17).filter(Users.id>10).all()
db.session.query(Users).filter(Users.age>17,Users.id>10).all()
或查询
# 或关系查询, 首选需要引入
from sqlalchemy import or_ # 语法
db.session.query(Users).filter(or_(条件1,条件2))
与, 或并列查询
# 语法 .and_(), .or_()
db.session.query(Users).filter(
or_(
Users.id < 2,
and_(Users.name == 'eric', Users.id > 3),
Users.extra != ""
)).all() # 可以嵌套
非查询
任何的查询是在 类字段前加 ~ 表示非查询
db.session.query(Users).filter(~Users.email.like('%yangtuo%')).all() # not like
模糊查询
# 模糊查询
# 语法 .like('%xxxx%')
db.session.query(Users).filter(Users.email.like('%yangtuo%')).all() # like
db.session.query(Users).filter(Users.email.like('%%%s%%' % 'yangtuo')).all()
# 格式化字符串形式要 两个 %% 来表示一个 % 因此就出现这么多% 很麻烦...
区间查询
# 区间查询
# 语法 .between(条件1,条件2)
db.session.query(Users).filter(Users.id.between(30,40)) # 30~40 包括 30 40
db.session.query(Users).filter(~Users.id.between(30,40)) # <30, >40 不包括 30 40
区间判断
# 区间判断
# 语法 .in_(列表/元组)
db.session.query(Users).filter(Users.id.in_([1,3,4])).all() # in
截取查询
# 截取查询
# .limit(n)
db.session.query(Users).limit(3).all()
跳过查询
limit 和 offset 可以配合实现分页操作
# 跳过查询
# .offset(n)
db.session.query(Users).offset(3).all()
db.session.query(Users).offset(3).limit(3).all()
排序查询
# 排序查询
# 语法 .order_by('列 规则,列 规则')
# 规则 desc 降序 asc 升序(默认, 不写就表示升序)
db.session.query(Users).order_by('Users.id desc').all() # 先按xxx排序,xxx排序不出来的部分 再用 yyy 来排序
db.session.query(Users).order_by('Users.id desc, Users.name').all()
聚合查询
需要配合聚合函数
from sqlalchemy import func
func.sum() # 求和
func.count() # 求数量
func.max() # 求最大值
func.min() # 求最小值
func.avg() # 求平均数
# 语法
db.session.query(func.聚合函数(实体类.属性),func.聚合函数(实体类.属性)..).all() # 返回值 列表里面又套了个元组, 因为聚合出来的数据是固定的不可修改,因此用元组修饰
[((),(),()...)]
分组查询
# 分组查询
# 语法
db.session.query(查询列, 聚合列).group_by(分组列).all()
ret = db.session.query(Users.is_active, func.avg(Users.age)).group_by('is_active').all()
print(ret) # [(None, Decimal('22.5000')), (True, Decimal('24.0000'))]
带条件的分组聚合
条件必须放在 group_by 后面, 关键字不在使用 filter 使用 having 和 mysql 类似 (不能再使用where)
ret = db.session.query(Users.is_active, func.avg(Users.age)).group_by(Users.age).having(func.avg(Users.age) > 23).all()
print(ret) # [(True, Decimal('24.0000'))]
综合查询
# 查询所有年龄 18 以上按找 active 分组后, 组内大于两人的信息
ret = db.session.query(Users.is_active, func.count(Users.is_active))\
.filter(Users.age > 18)\
.group_by(Users.is_active)\
.having(func.count(Users.is_active) > 2).all()
print(ret)
查询优先级
执行顺序和 mysql 的 一样 , mysql 的优先顺序点击 这里
但是 mysql 中没有 offset , 但是 mysql 的 limit 可以提供两个参数来获取类似 offset 的功能
因此结合 对 mysql 的分析 SQLAlchemy 的查询优先顺序如下
query > filter > group > having > order >limit = offset
# 查询所有人的年龄
ret = db.session.query(func.sum(Users.age)).all() # 查询多少人
ret = db.session.query(func.count(Users.id)).all() # 查询所有 大于 19 岁的人的平均年龄
ret = db.session.query(func.avg(Users.age)).filter(Users.age > 19).all() # 查询 按找active 分组后 组内成员大于2 的组信息
ret = db.session.query(Users.is_active, func.count(Users.is_active))\
.group_by(Users.is_active)\
.having(func.count(Users.is_active) > 2).all() # 查询所有年龄 18 以上按找 active 分组后, 组内大于两人的信息
ret = db.session.query(Users.is_active, func.count(Users.is_active))\
.filter(Users.age > 18)\
.group_by(Users.is_active)\
.having(func.count(Users.is_active) > 2).all()
数据库删除
db.session.delete(记录对象)
ps
以上都是基于 db.session 的方式查询
还可以基于实体类进行查询 , 和 db 方式没有效率性能上的区别
两种方式没什么大区别, 貌似也没有说法哪种更好哪种在某场合下必须要用的情况
Users.query.all()
db.session.query(Users).all()
db.session.query(Users.id).all()
db.session.query('users.id'').all() User.query.filter(Users.is_active==True).all() # 实体类方式查询中的等于必须是双等于号
以及 所有的 实体类.列名, 都可以用 "表名.属性" 或者 "实体类.列名" 来表示 , 不会影响显示
但是如果使用 实体类.列名 的方式 会存在互相引用的时候因为未加载到的问题 因此这个要稍微注意到
数据库关联
一对多
什么是一对多
A表中的一条数据可以关联到B表中的多条数据
B表中的一条数据只能关联到A表中的一条数据
示例
Teacher(老师) 与 Course(课程)之间的关系
一名老师(Teacher)只能教授一门课程(Course)
一门课程(Course)可以被多名老师(Teacher)所教授
在数据库中体现
"主外键关系" 完成实现一对多
在 "一" 表中创建主键
在 "多" 表中创建外键来对 "一" 表进行关联
在 SQLAlchemy 中的实现
1. 在 "多" 的实体类中增加对 "一" 的实体类的引用( 外键 )
语法
外键列名 = db.Column(
db.type,
db.ForeignKey(主键表.主键列)
)
实例
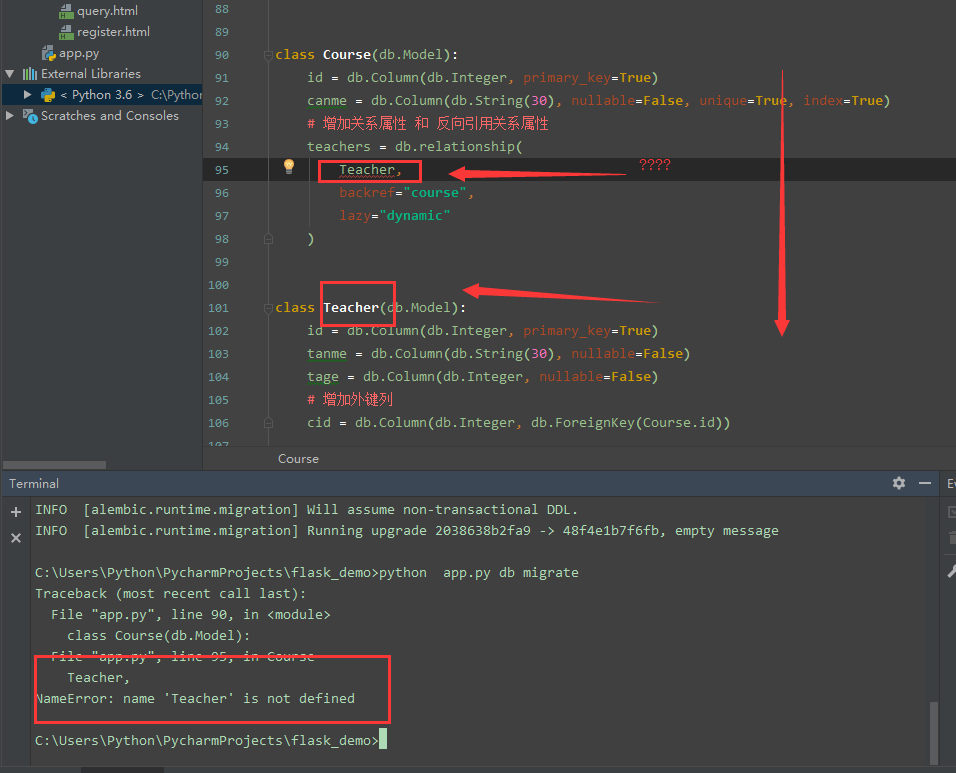
class Course(db.Model):
id = db.Column(db.Integer, primary_key=True)
canme = db.Column(db.String(30), nullable=False, unique=True, index=True) class Teacher(db.Model):
id = db.Column(db.Integer, primary_key=True)
tanme = db.Column(db.String(30), nullable=False)
tage = db.Column(db.Integer, nullable=False)
# 增加外键列
cid = db.Column(db.Integer, db.ForeignKey(Course.id))
2. 在 "一" 的实体类中增加对 "关联属性" 以及 "反向引用关系属性"
目的 在编程语言中创建类(对象) 与类(对象) 之间的关系, 不会对数据库有所操作, 仅仅是为了代码逻辑方便
关联属性
在 "一" 的实体中, 通过哪个 <<属性>> 来获取对应到 "多" 的实体对象们
反向引用关系属性
在 "多" 的实体中, 通过哪个 <<属性>> 来获取对应到 "一" 的实体对象
语法
属性名 = db.relationship(
关联到的实体类,
backref="自定义一个反向关系属性名",
lazy="dynamic",
) """
lazy 参数: 指定如何加载相关记录
1.select
首次访问源对象时加载关联数据
2.immediate
源对象加载后立马加载相关数据(使用连接)
3.subquery
效果同上(使用子查询)
4.noload
永不加载
5.dynamic
不加载记录但提供加载记录的查询
"""
实例
class Course(db.Model):
id = db.Column(db.Integer, primary_key=True)
canme = db.Column(db.String(30), nullable=False, unique=True, index=True)
# 增加关系属性 和 反向引用关系属性
teachers = db.relationship(
'Teacher',
backref="course",
lazy="dynamic"
) class Teacher(db.Model):
id = db.Column(db.Integer, primary_key=True)
tanme = db.Column(db.String(30), nullable=False)
tage = db.Column(db.Integer, nullable=False)
# 增加外键列
cid = db.Column(db.Integer, db.ForeignKey(Course.id))
关联数据操作
方式一 操作外键字段
直接操作本表中有的字段 外键映射字段进行赋值, 即正向操作
tea = Teacher()
tea.cid = 1
方式二 操作反向引用属性
操作关联表的 relationship 关系字段的 bcakref 属性来进行赋值, 即反向操作
cou = Course()
tea = Teacher()
tea.course = cou
一对一
在一对多的基础上添加唯一约束 ( 即对 "多" 设置唯一约束 )
语法
设置外键字段和唯一索引
外键列名 = db.Column(
db.TYPE,
db.ForeignKey('主表.主键'),
unique = True
)
增加关联属性和反向引用关系属性
在另一个实体类中增加关联属性和反向引用关系属性
属性名 = db.relationship(
"关联的实体类名",
backref="反向引用关系属性名",
uselist = False
) # userlist:设置为False,表示关联属性是一个标量而非一个列表
实例
用户和用户老婆是一对一关系( 大概 )
class Wife(db.Model):
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(30))
#增加外键约束和唯一约束,引用自users表中的id列
uid = db.Column(
db.Integer,
db.ForeignKey('users.id'),
unique = True
)
class Users(db.Model):
id = db.Column(db.Integer,primary_key=True)
username = db.Column(db.String(80),nullable=False,unique=True,index=True)
age = db.Column(db.Integer,nullable=True)
email = db.Column(db.String(120),unique=True)
isActive = db.Column(db.Boolean,default=True) #增加关联属性和反向引用关系属性(Wife表一对一)
wife = db.relationship(
"Wife",
backref="user",
uselist = False
)
关联字段操作 ( 和一对多完全一样, 本质上就是一对多字段加了个唯一索引而已 )
方式一 操作外键字段
直接操作本表中有的字段 外键映射字段进行赋值, 即正向操作
wif = Wife()
wif.uid = 1
方式二 操作反向引用属性
操作关联表的 relationship 关系字段的 bcakref 属性来进行赋值, 即反向操作
wife = Wife()
user = User()
wife.Wife = user
多对多
双向的一对多, "多" 代表着是无法直接用字段来处理, 即不会再本表中添加关系字段, 只需要做反向引用属性即可
而且需要指定第三张表来映射( 第三张表需要手动创建 ), 设置语法在两个多对多表中的任意一个设置即可
因为此设置中同时对两个都设置了外向引用属性
设置语法
属性值 = db.relationship(
"关联实体类",
lazy="dynamic",
backref=db.backref(
"关联实体类中的外向引用属性",
lazy="dynamic"
)
secondary="第三张关联表名"
)
实例
# 编写StudentCourse类,表示的是Student与Course之间的关联类(表)
# 此表需要设定到两个关联表的外键索引
# 表名:student_course
class StudentCourse(db.Model):
__tablename__ = "student_course"
id = db.Column(db.Integer, primary_key=True)
# 外键:student_id,引用自student表的主键id
student_id = db.Column(db.Integer, db.ForeignKey('student.id'))
# 外键:course_id,引用自course表的主键id
course_id = db.Column(db.Integer, db.ForeignKey('course.id')) # 两个多对多关联表二选一进行配置即可
class Student(db.Model):
id = db.Column(db.Integer, primary_key=True)
sname = db.Column(db.String(30), nullable=False)
sage = db.Column(db.Integer, nullable=False)
isActive = db.Column(db.Boolean, default=True) # 在此表中进行设置反向引用属性, 一次性设置两份
class Course(db.Model):
id = db.Column(db.Integer, primary_key=True)
canme = db.Column(db.String(30), nullable=False, unique=True, index=True) students = db.relationship(
"Student",
lazy="dynamic", # 针对 Course 类中的 students 属性的延迟加载
backref=db.backref(
"courses",
lazy="dynamic" # 针对 students 类中的 courses 属性的延迟加载
)
secondary="student_course" # 指定第三张关联表
)
关联数据操作
# 向第三张关联表中插入数据 # 取到 数据
courses = request.form.getlist('courses')
# 根据数据 查到所有对象
obj_list = Course.query.filter(Course.id.in_(courses)).all()
for cou in obj_list : # 方案1:通过 stu 关联 course 值
# stu.courses.append(cou) # 方案2:通过 course 关联 stu 值
cou.students.append(stu)
ps:
当然也可以直接操作第三张表, 毕竟是个实表. 但是不推荐. 就逻辑层面我们是尽力无视第三表的存在
还请无视到底
pymysql 方式
链接数据库
格式
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
配置文件中添加
SQLALCHEMY_DATABASE_URI = "mysql+pymysql://root:123456@127.0.0.1:3306/yangtuoDB?charset=utf8" SQLALCHEMY_POOL_SIZE = 10 SQLALCHEMY_MAX_OVERFLOW = 5
注册初始化数据库
函数级别
不推荐
from flask_sqlalchemy import SQLAlchemy
from flask import FLask
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] ="mysql://root:12345@localhost/test"
db = SQLAlchemy(app)
全局
from flask_sqlalchemy import SQLAlchemy
from flask import FLask
db = SQLAlchemy() def create_app():
app = Flask(__name__)
db.init_app(app)
return app
注意
必须在导入蓝图之前
from flask_sqlalchemy import SQLAlchemy
必须要在初始化之前导入模板,不然是没办法正确得到db
from .models import *
创建生成表
在离线脚本中操作数数据库创建 create_all drop_all
from chun import db,create_app app = create_app()
app_ctx = app.app_context() # app_ctx = app/g
with app_ctx: # __enter__,通过LocalStack放入Local中
db.create_all() # 调用LocalStack放入Local中获取app,再去app中获取配置
操作表
#方式一
db.session #会自动创建一个session
db.session.add()
db.session.query(models.User.id,models.User.name).all()
db.session.commit()
db.session.remove()
#方式二
导入models
models.User.query
目录结构
chun 项目名
chun 与项目名同名的文件夹
static 静态文件相关
templates 模板文件相关
view 视图函数
acctount.py 具体视图函数
user.py 具体视图函数
__init__.py 初始化文件
models.py 数据库相关
create_table.py 数据库创建离线脚本
settings.py 配置文件
chun.chun.__init__.py
用于初始化,创建DB对象,app对象
from flask import Flask
from flask_session import Session from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy() from .views.account import ac
from .views.user import us from .models import * def create_app():
app = Flask(__name__)
app.config.from_object('settings.ProConfig')
app.register_blueprint(ac)
app.register_blueprint(us) db.init_app(app) # return app
chun.settings.py
配置文件相关存放,数据库的链接之类的
from redis import Redis
class BaseConfig(object):
#
SQLALCHEMY_DATABASE_URI = "mysql+pymysql://root:123456@127.0.0.1:3306/s9day122?charset=utf8"
SQLALCHEMY_POOL_SIZE = 10
SQLALCHEMY_MAX_OVERFLOW = 5
SQLALCHEMY_TRACK_MODIFICATIONS = False
#
pass
chun.chun.models.py
数据库表文件
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column
from sqlalchemy import Integer,String,Text,Date,DateTime
from sqlalchemy import create_engine
from chun import db class Users(db.Model):
__tablename__ = 'users' id = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=False)
chun.create_table.py
数据库离线操作脚本文件,用于 操作 app,g,db 的相关脚本
from chun import db,create_app app = create_app()
app_ctx = app.app_context()
with app_ctx:
db.create_all() class ProConfig(BaseConfig):
pass
chun.chun.views.user.py
视图请求回应相关的文件
from flask import Blueprint
from chun import db
from chun import models
us = Blueprint('us',__name__) @us.route('/index')
def index():
# 使用SQLAlchemy在数据库中插入一条数据
# db.session.add(models.Users(name='yangtuo',depart_id=1))
# db.session.commit()
# db.session.remove()
result = db.session.query(models.Users).all()
print(result)
db.session.remove() return 'Index'
Flask 模型操作的更多相关文章
- 03 flask数据库操作、flask-session、蓝图
ORM ORM 全拼Object-Relation Mapping,中文意为 对象-关系映射.主要实现模型对象到关系数据库数据的映射. 1.优点 : 只需要面向对象编程, 不需要面向数据库编写代码. ...
- .NET使用DAO.NET实体类模型操作数据库
一.新建项目 打开vs2017,新建一个项目,命名为orm1 二.新建数据库 打开 SqlServer数据库,新建数据库 orm1,并新建表 student . 三.新建 ADO.NET 实体数据模型 ...
- xBIM 基本的模型操作
目录 xBIM 应用与学习 (一) xBIM 应用与学习 (二) xBIM 基本的模型操作 xBIM 日志操作 XBIM 3D 墙壁案例 xBIM 格式之间转换 xBIM 使用Linq 来优化查询 x ...
- django创建ORM模型、通过ORM模型操作单个表、ORM模型常用字段
一.ORM简介 ORM ,全称Object Relational Mapping,中文叫做对象关系映射,通过ORM我们可以通过类的方式去操作数据库,而不用再写原生的SQL语句.通过把表映射成类,把行作 ...
- Laravel 5.2 四、.env 文件与模型操作
一..env文件 .env 文件是应用的环境配置文件,在配置应用参数.数据库连接.缓存处理时都会使用这个文件. // 应用相关参数 APP_ENV=local APP_DEBUG=true //应用调 ...
- Qt 学习之路 2(56):使用模型操作数据库
Qt 学习之路 2(56):使用模型操作数据库 (okgogo: skip) 豆子 2013年6月20日 Qt 学习之路 2 13条评论 前一章我们使用 SQL 语句完成了对数据库的常规操作,包括简单 ...
- 第一百六十七节,jQuery,DOM 节点操作,DOM 节点模型操作
jQuery,DOM 节点操作,DOM 节点模型操作 学习要点: 1.创建节点 2.插入节点 3.包裹节点 4.节点操作 DOM 中有一个非常重要的功能,就是节点模型,也就是 DOM 中的“M”.页面 ...
- 笔记-flask基础操作
笔记-flask基础操作 1. 前言 本文为flask基础学习及操作笔记,主要内容为flask基础操作及相关代码. 2. 开发环境配置 2.1. 编译环境准备 安装相关Lib ...
- legend3---lavarel多对多模型操作实例
legend3---lavarel多对多模型操作实例 一.总结 一句话总结: 在多对多模型中,增加关系表的数据 需要 弄一个和关系表一对多的模型关系 1.在lavarel关系模型中,课程和标签表是多对 ...
随机推荐
- SAP MM 根据采购订单反查采购申请?
SAP MM 根据采购订单反查采购申请? 前日微信上某同行发来一个message,说是想知道如何通过采购订单号查询到其前端的采购申请号. 笔者首先想到去检查采购订单相关的常用报表ME2L/ME2M/M ...
- Parcelable encountered IOException writing serializable object
异常: java.lang.RuntimeException: Parcelable encountered IOException writing serializable object 这是在in ...
- WPF开发为按钮提供添加,删除和重新排列ListBox内容的功能
介绍 我有一种情况,我希望能够将项目添加到列表中,并在列表中移动项目,这似乎是使用a的最简单方法ListBox.我立刻想到了如何以通用的方式做到这一点,然后,也许,可以使用行为来做到这一点.这似乎是一 ...
- 访问vsts私有nuget
访问vsts私有nuget Intro 有时候我们可能要自己搭建一个 nuget,如果不对外公开,即包浏览也是需要权限的,那我们应该怎么做才可以支持在哪里都可以正常的还原包呢? 我是在 VSTS(Vi ...
- Actor模型浅析 一致性和隔离性
一.Actor模型介绍 在单核 CPU 发展已经达到一个瓶颈的今天,要增加硬件的速度更多的是增加 CPU 核的数目.而针对这种情况,要使我们的程序运行效率提高,那么也应该从并发方面入手.传统的多线程方 ...
- Delphi中打开网页连接的几种方法
https://blog.csdn.net/zisongjia/article/details/69398143 正好要用,做个记录.Mark下. 使用了第一种 uses shellapi proce ...
- SQL Server 2008初次启动
一.关于安装 SQL Server 数据库的安装,经过自己的安装,总体还是比较容易,没有太多难度,安装包在网上也有很多,在此,就跳过安装的这一步. 二.初次启动SQL Server 安装完成数据库后, ...
- Linux学习历程——Centos 7 mkdir命令
一.命令介绍 mkdir 命令用于创建空白目录格式为“mkdir [选项] 目录”, 除了能够创建单个空白目录,还能结合 -p 参数来递归创建具有嵌套层叠关系的文件目录. -------------- ...
- SQLServer之修改触发器
修改触发器规则 修改CREATE TRIGGER语句以前创建的 DML.DDL 或登录触发器的定义.触发器是通过使用CREATE TRIGGER创建的.这些触发器可以由Transact-SQL语句直接 ...
- 周末班:Python基础之函数进阶
迭代器和生成器 迭代和可迭代 什么是迭代(iteration)? 如果给定一个list或tuple,我们要想访问其中的某个元素,我们可以通过下标来,如果我们想要访问所有的元素,那我们可以用for循环来 ...