[python爬虫]Requests-BeautifulSoup-Re库方案--Requests库介绍
【根据北京理工大学嵩天老师“Python网络爬虫与信息提取”慕课课程编写 文章中部分图片来自老师PPT
慕课链接:https://www.icourse163.org/learn/BIT-1001870001?tid=1002236011#/learn/announce】
一、python爬虫的思路
爬虫是指根据一定规则(如页面HTML结构)可以在网络页面上获取大量数据的代码或程序。python语言提供了很多适合编写爬虫的库。
python爬虫有很多种思路,这里使用3个python库搭建:Requests、BeautifulSoup、Re。
Requests库提供了方法获取HTML页面,相当于把网页抓取到了一个变量中,再使用这个变量进行后续处理。更多信息请查看官方文档:http://www.python-requests.org/en/master/。
BeautifulSoup库提供了方法解析抓取下来的HTML页面。它根据HTML页面的DOM(Document Object Model)结构,解析我们真正感兴趣的内容。BeautifulSopu(美味汤),就像是Requests库提供了丰富但是杂乱的食材,而BeautifulSoup库知道哪些食材可以用,并用这些食材做成了一锅美味的汤。更多信息请查看官方文档:https://www.crummy.com/software/BeautifulSoup/。
Re库提供了使用正则表达式(Regular Expression)的方法。正则表达式是多个字符串的概括表示,有点像模糊匹配。使用正则表达式,可以更好地匹配HTML的DOM结构。更多信息请查看官方文档:https://docs.python.org/3/library/re.html。
使用Requests、BeautifulSoup、Re库搭建python爬虫的思路是:Requests库获取页面内容,BeautifulSoup库解析页面内容,Re库辅助匹配字符串。这3个库都比较简洁,语法也不是很复杂,适合构建中小型的爬虫。
二、Requests库基本使用
1.Requests库的安装
①python的正确安装
在python官网下载python3.x版本,python官网:https://www.python.org/。
python语言有两个版本同步更新:2.x系列和3.x系列。当前最新版本是2.7和3.7。2.x版本是之前的版本,各种库比较丰富。3.x版本是2009年开始开发的,相比较于2.x版本语法有很大的变化。两个版本是不兼容的。发展到现在,3.x系列已经有很多成熟的第三方库了,官方也在支持3.x系列版本的开发。除此之外,BeautifulSoup库对3.x版本也有优化。
下载并安装python后,需要配置计算机环境变量,为了在使用CMD命令窗口时可以正确找到所需工具的位置。(pip工具)
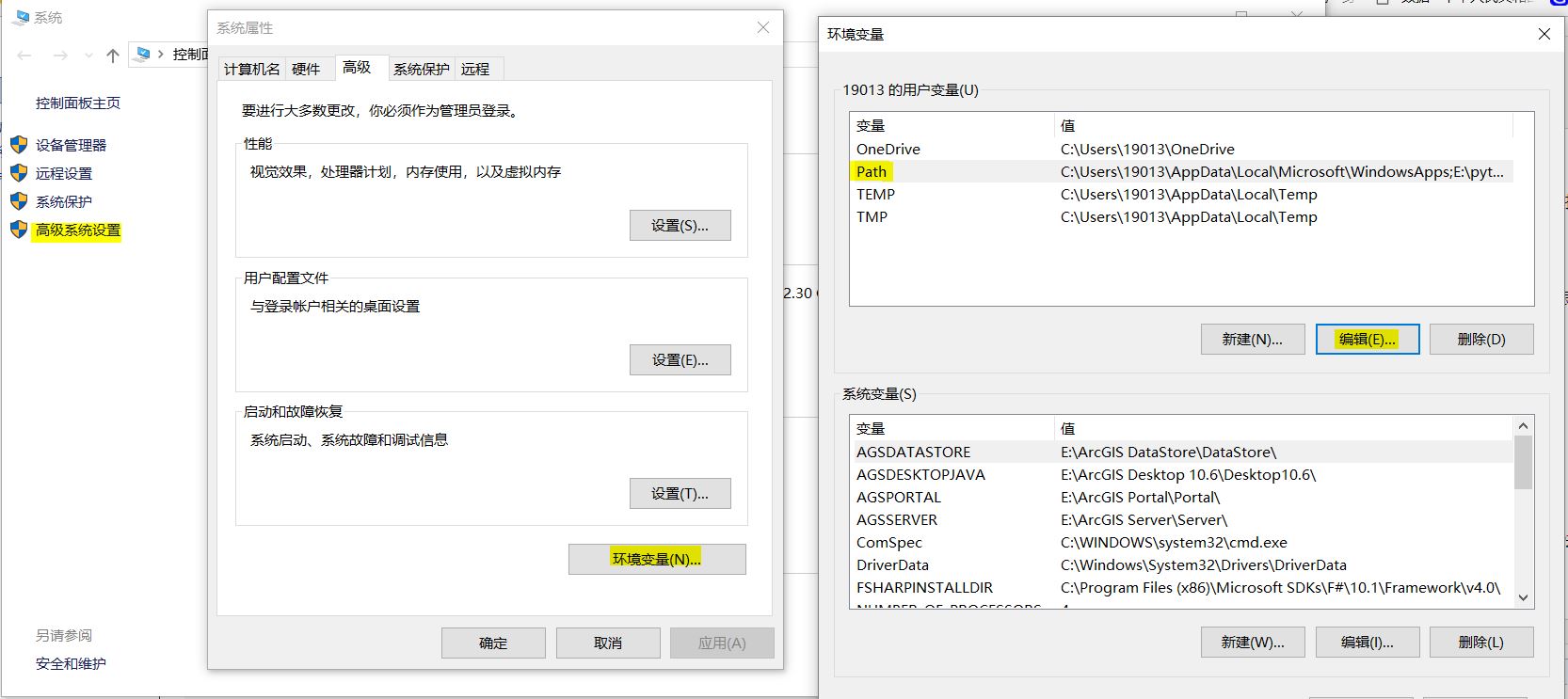
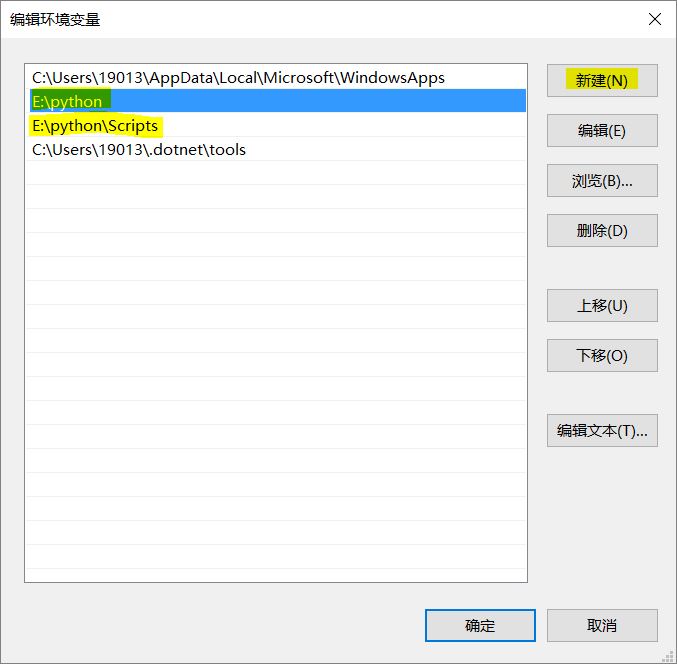
右键计算机属性-高级系统设置-环境变量。在用户变量列表中,找到Path变量,点击编辑。新建两个变量,目录是python安装目录下python.exe和pip.exe所在位置。
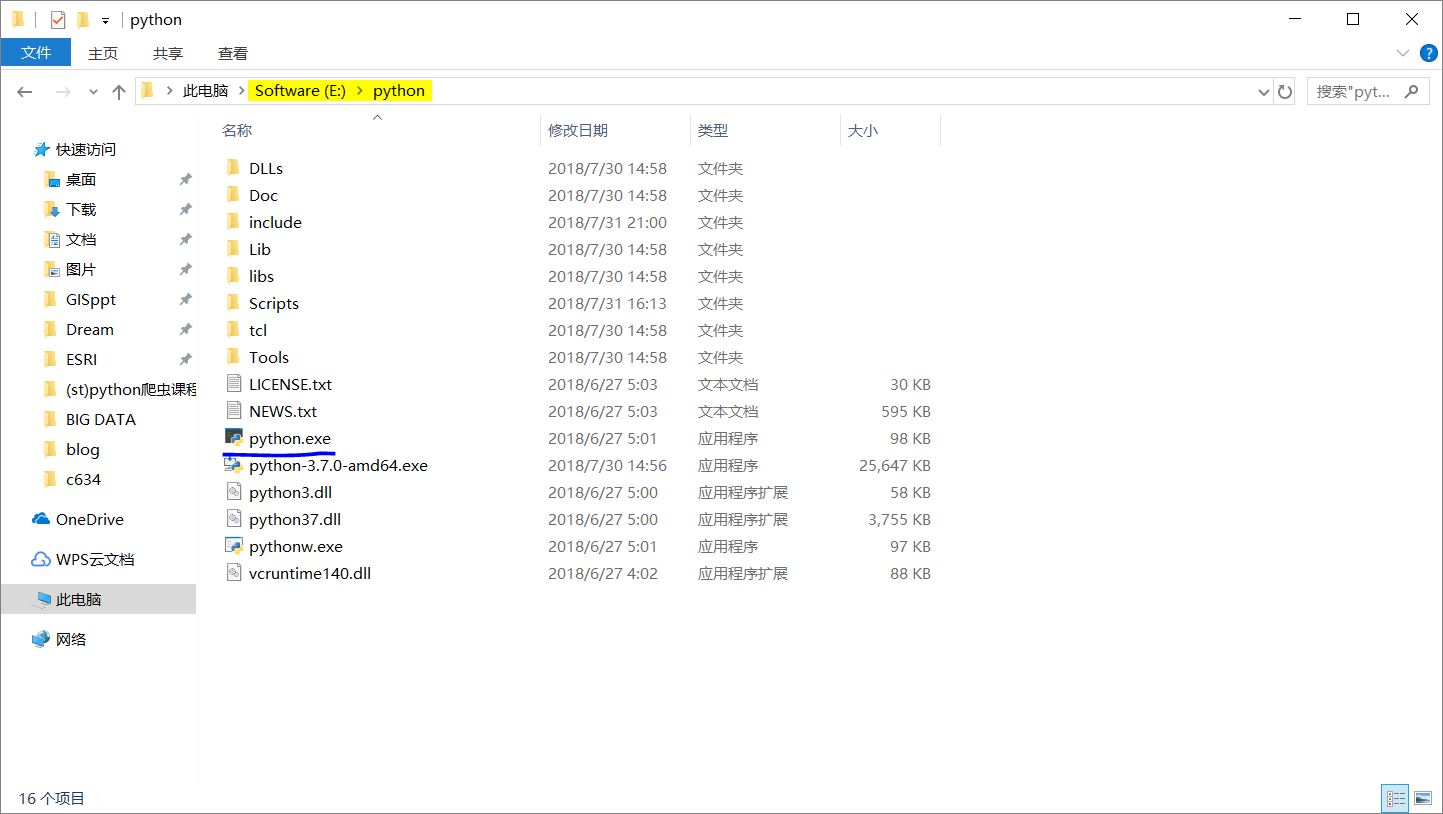
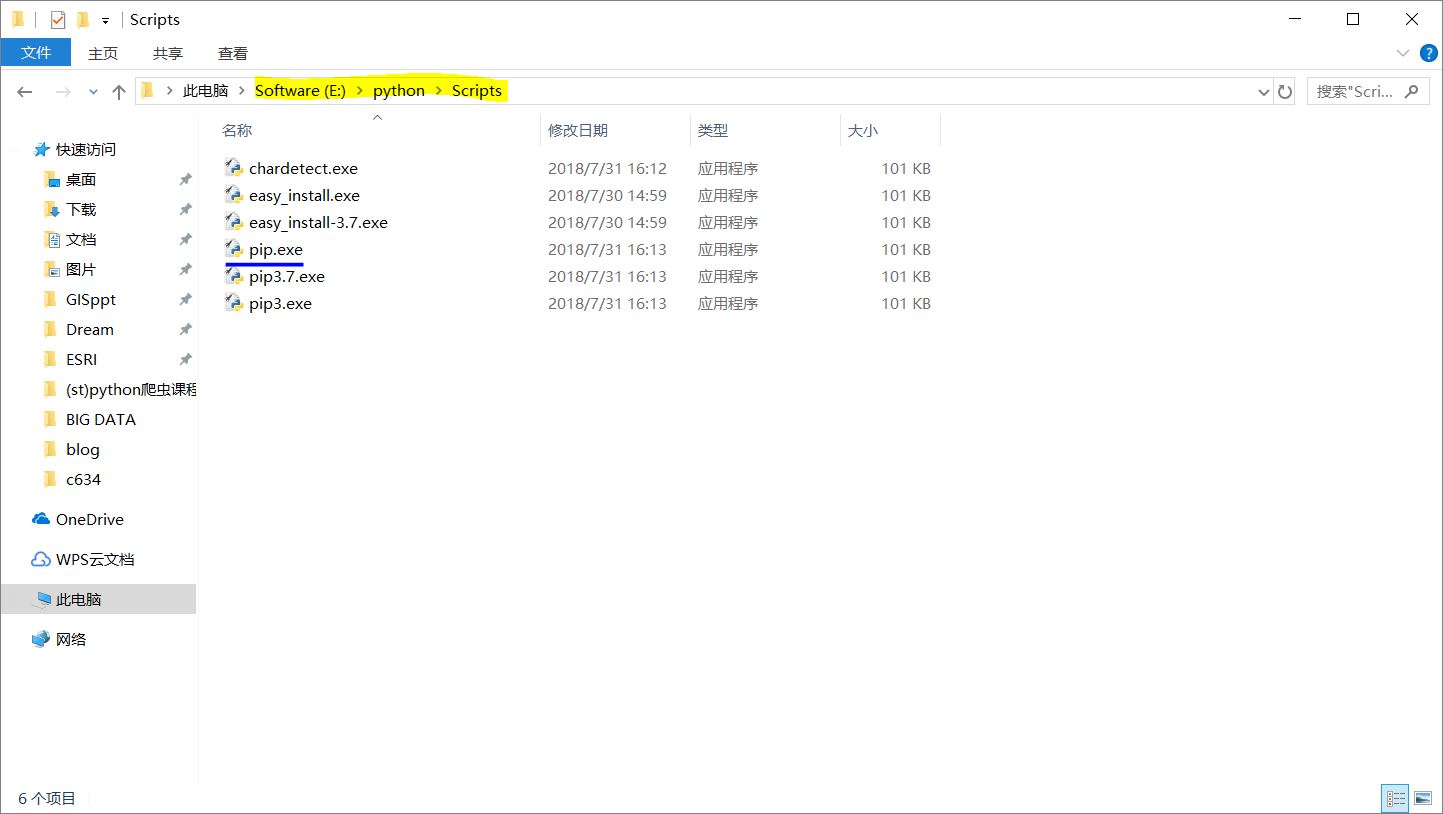
打开CMD(command,命令提示符),输入python以测试环境变量是否配置成功。若输出python版本信息,则说明配置成功。
②Requests库的安装
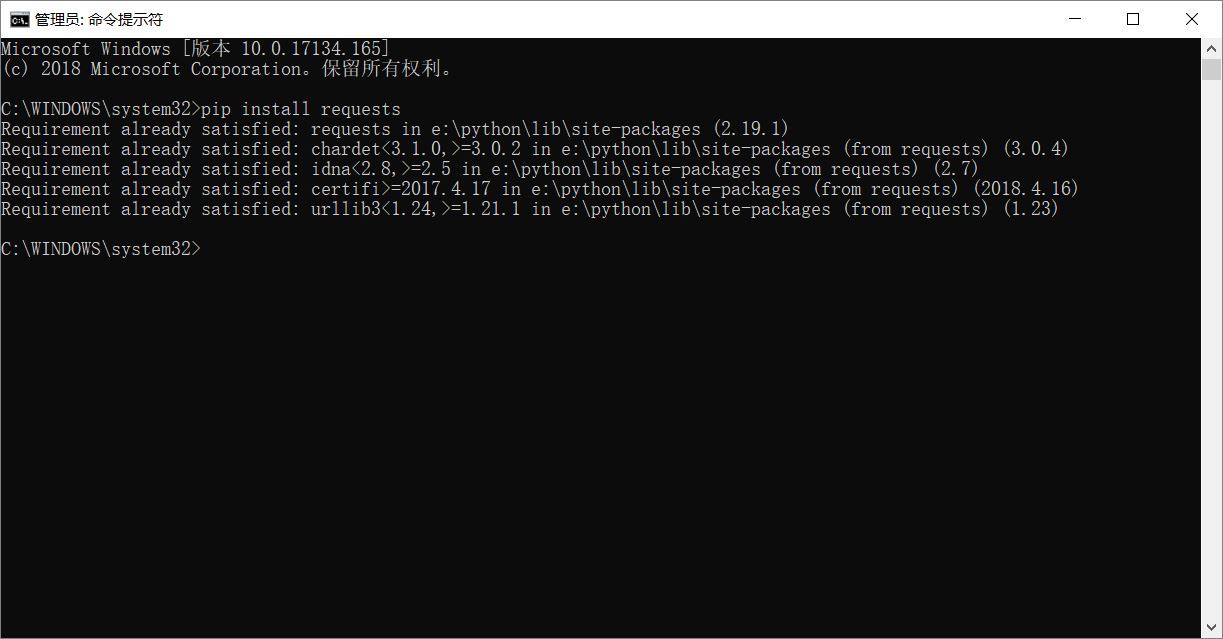
以管理员身份启动CMD(右键CMD即可,这里不确定直接运行CMD是否可以安装成功),输入pip install requests即可从网络上下载并安装requests库。pip是python库的管理工具,可以对大部分库进行下载、安装、更新、卸载等。但是也有部分库是使用pip工具安装不了的。如果提示要先更新pip工具,按照指导更新即可。
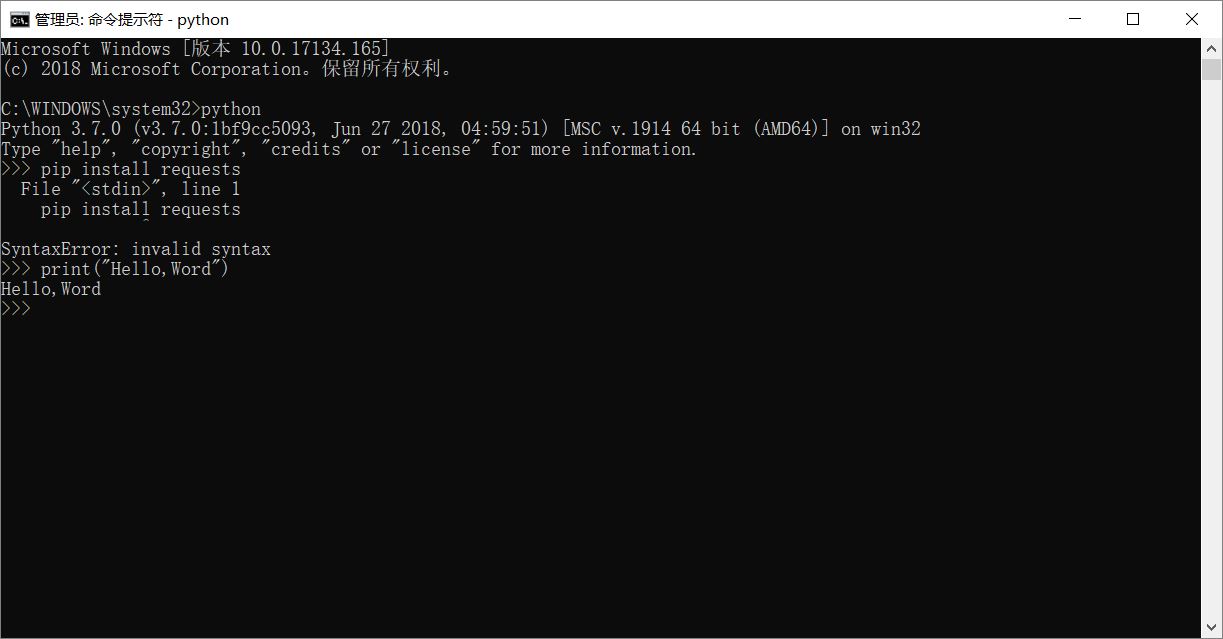
注意这里有一个容易犯错的地方,也是很多人不会注意到的。启动CMD后输入完python测试配置环境变量成功后,要把CMD退出去,再启动,输入pip install requests。因为在CMD中输入完python后,CMD就变成了python交互器了。
2.Requests库的7个主要方法
Requests库比较简洁,主要的方法只有7个,分别对应HTTP的功能,这里可以先跳过,不用理解。
这些方法是:
requests.get():获取HTML网页的主要方法,对应HTTP的GET
requests.head():获取HTML网页的头信息,对应HTTP的HEAD
requests.post():向HTML网页提交POST请求,对应HTTP的POST
requests.put():向HTML网页提交PUT请求,对应HTTP的PUT
requests.patch():向HTML网页提交局部修改请求,对应HTTP的PATCH
requests.delete():向HTML网页提交删除请求,对应HTTP的DELETE
requests.request():构造一个请求,是支撑以上各种方法的基础方法
其中,最重要的,也是用的最多的是requests.get()。
3.Requests库的requests.get()
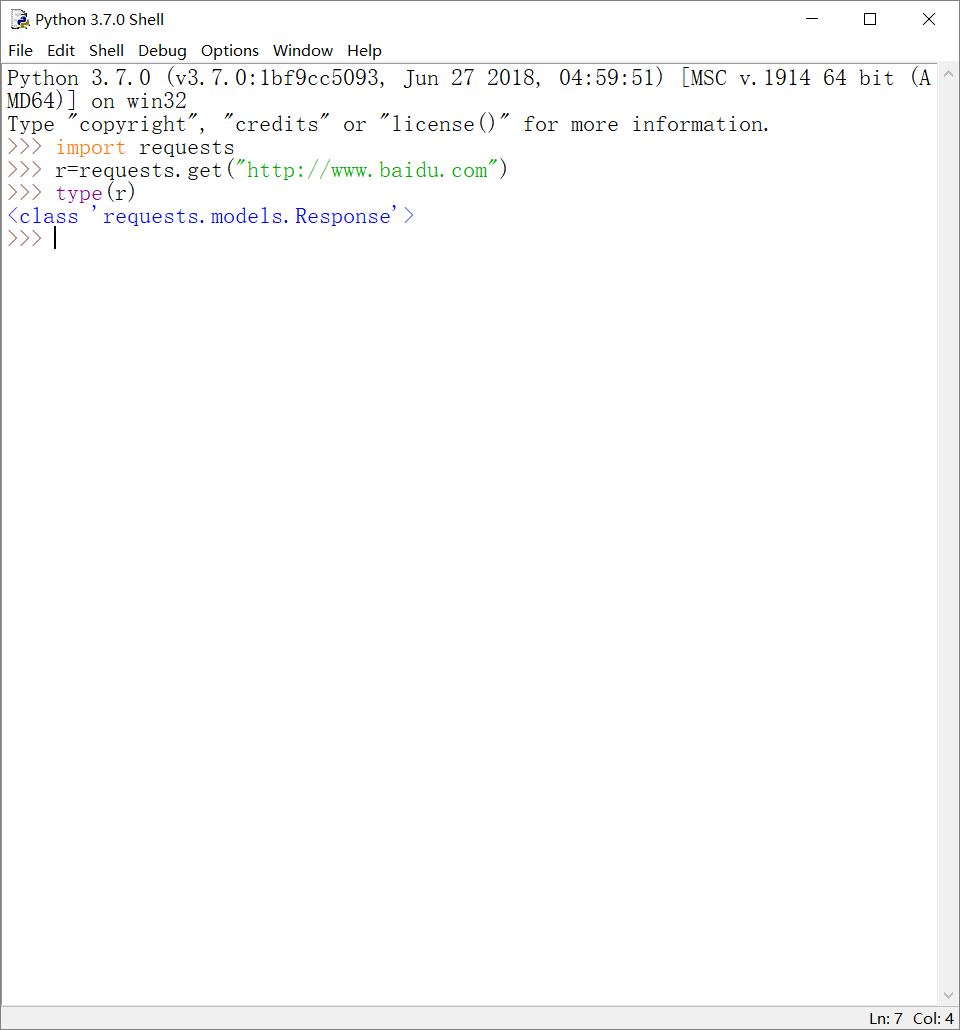
r.requests.get(url)这样一行代码,做的事情其实有很多。requests.get(url)通过get()方法和url构造了一个向网页请求资源的Request对象(注意Request对象的'R'是大写)。而get()方法返回一个Response对象,其中包含了网页所有相关资源(即爬虫返回的全部内容),也包括我们向网页请求访问的Request对象中的相关信息。
这里,Request和Response是两个重要的对象。
①Response对象的重要属性
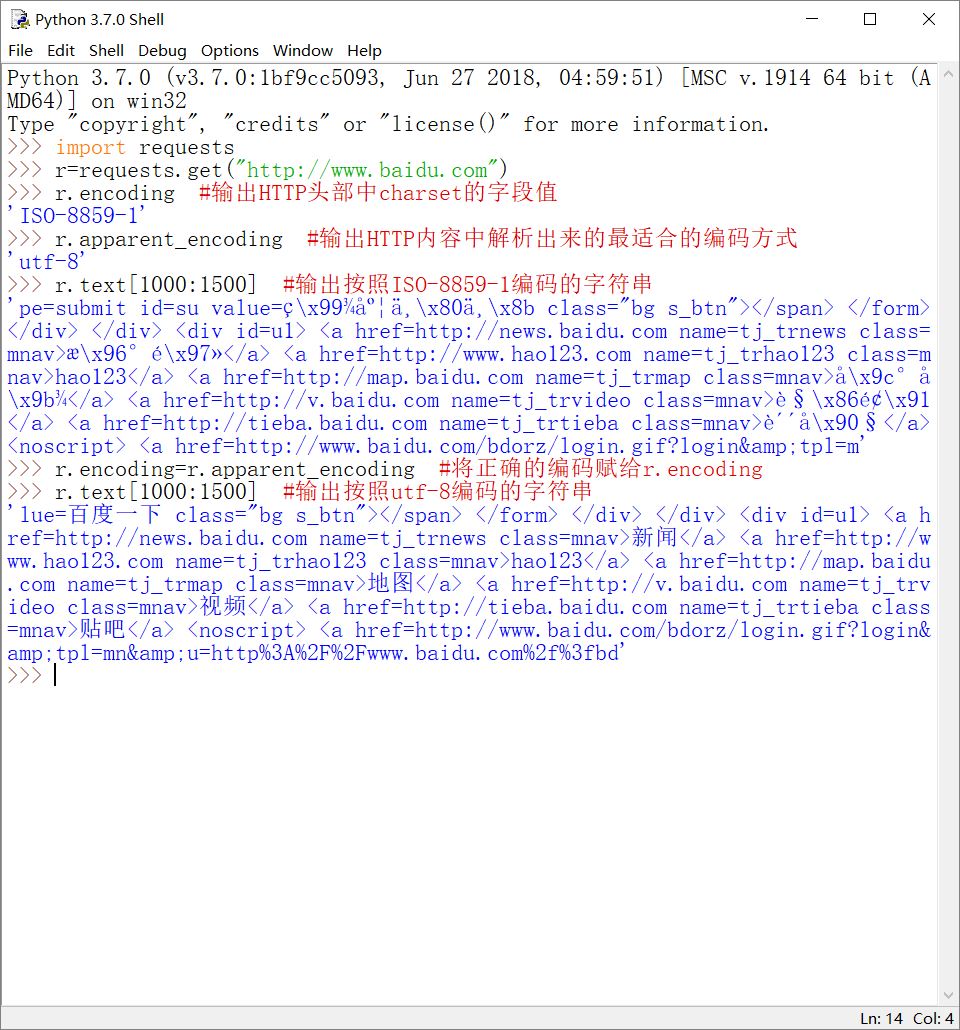
r.status_code:HTTP请求的返回状态,200表示连接成功,不是200表示连接失败
r.encoding:HTTP头部中猜测的内容字符编码方式
r.apparent_encoding:从HTTP内容中解析出的最适合该内容的编码方式(与r.encoding的区别会在后面解释)
r.text:HTTP响应内容的字符串形式,即URL对应的页面内容
r.content:HTTP响应内容的二进制形式。如在HTTP中获取的图片、视频等多媒体资源就是用二进制形式存储的
页面中显示的字符都是有一定要求的。有些页面会在HTTP头部中写入charset字段,来标识该页面中文本字符串的编码方式,但是有些页面的头部中没有charset字段。r.encoding的作用就是查看HTTP头部,以返回charset字段的值;如果没有charset字段,则返回的编码方式是'iso-8859-1'。r.apparent_encoding是实实在在地解析页面的内容,分析其中的字符串的最适合的编码方式,并返回这个编码。所以一般情况下,r.apparent_encoding比r.encoding更合理。一般用get()方法成功获取HTTP相关内容后,将r.apparent_encoding的值赋给r.encoding(即r.encoding=r.apparent_encoding),来根据正确的编码方式显示字符。
②关于get()方法的定义

从图中可以看到,get()方法实际上返回的是一个request()方法构造的对象,即get()方法是request()方法的封装。不光是get()方法,Requests库提供的其他几个方法也都是request()方法的封装。从这个层面上理解,Requests库只有request()这样一个基础的方法。
③get()方法使用的示例
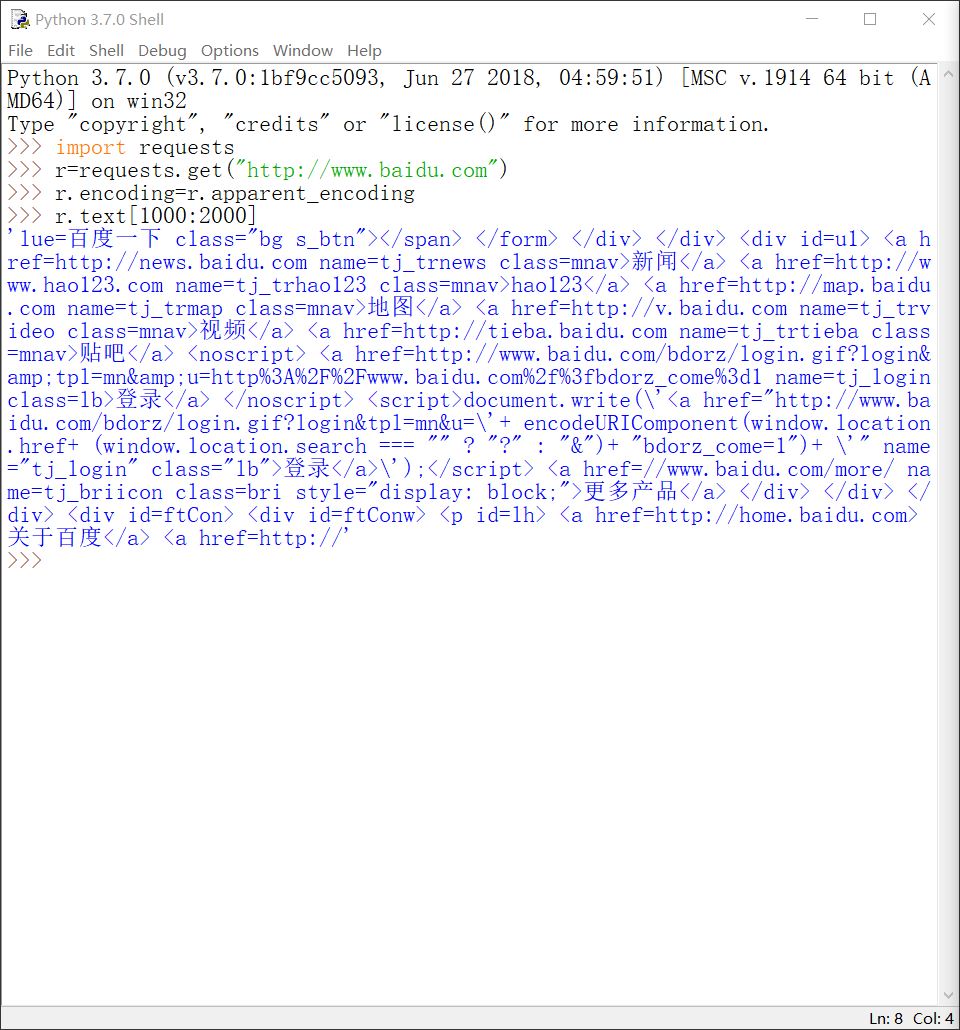
下面输出Response对象的相关属性信息,并展示错误的编码方式:
展示get()方法返回的Response对象:
4.Requests库的异常及通用代码框架
①Requests库使用过程中可能会产生的异常
r=requests.get(url)这样一行代码是和指定的服务器进行连接,但是在这个过程中可能会产生很多异常。
requests.ConnectionError:网络连接错误,如DNS查询失败、服务器防火墙拒绝连接等
requests.HTTPError:在HTTP协议层面出现的异常
requests.URLRequired:URL缺失造成的异常
requests.TooManyRedirects:用户访问URL进行的重定向次数超过了Requests库要求的最大重定向次数产生的异常,如对复杂URL进行访问时引发
requests.ConnectTimeout:连接远程服务器超时异常
requests.Timeout:连接至服务器及到获取内容整个过程中产生的超时异常
当发生异常时,Response对象的status_code属性不是200。根据这一点,Requests库提供了r.raise_for_status()方法。如果status_code不是200,则引发HTTPError异常。可以根据这一点使用python语言的try-except异常捕捉机制,编写连接至服务器并获取页面内容的通用代码框架。
②通用代码框架
import requests #引入Requests库 def getHTMLText(url):
try:
r=requests.get(url)
r.raise_for_status() #如果状态不是200,则产生HTTPError异常
r.encoding=r.apparent_encoding
return r.text
except:
return "产生错误" def main():
url="http://www.baidu.com"
print(getHTMLText(url)) if __name__=="__main__":
main()
关于python语言的异常处理机制,请查看:http://www.runoob.com/python3/python3-errors-execptions.html。
5.关于HTTP协议
HTTP(Hypertext Transfer Protocol,超文本传输协议),是一个基于“请求与响应”模式的、无状态的应用层协议。其中,“请求与响应”模式指的是用户发出请求、服务器作出响应;“无状态”指前一次请求与后一次请求之间没有关联,不会相互影响;“应用层协议”指HTTP协议工作在TCP协议之上。
HTTP协议采用URL(Uniform Resource Locator,统一资源定位符)作为定位网络资源的标识。网络上的每个文件都有一个唯一的URL,它包含文件的位置信息以及浏览器对它的处理信息。URL的格式为http://host[:port][path]。其中host是指合法的Internet主机或本地IP地址。post是端口号,默认为80。80是http的端口号,443是https的端口号。path是所请求资源的路径。
HTTP协议对资源的操作与Requests库提供的方法是相对应的。这些操作包括:
GET:请求获取URL位置的资源;HEAD:请求获取位置资源的头部信息;POST:请求向位置资源后附加新的数据;PUT:请求向URL位置存储一个资源,并覆盖原URL位置的资源;PATCH:请求局部更新URL位置资源;DELETE:请求删除URL位置存储的资源。
HTTP协议通过URL对资源作定位,通过这6个方法对资源进行管理。
6.Requests库的方法
①requests.request(method,url,**kwargs)
Requests库的基础方法,其他方法(如get()方法)都是这个方法的封装。
method是请求的方式,对应get、head、post、put、patch、delete、options这7种方法。其中options是指与服务器交互时产生的一些参数,和URL的位置资源不直接相关。method参数的含义,以get()方法举例。r=requests.request('get',url),r=requests.request('GET',url),r=requests.get(url)。这3种方法是等价的。注意requests.request()中get是字符串,要加引号。
url是拟获取资源的链接。
kwargs是可选参数,这里有13个。分别是:
params:字典或字节序列,增加到URL中。程序不仅链接到指定的URL,还代入一些参数。服务器根据这些参数筛选部分内容资源返回
data:字典、字节序列或文件对象,作为Request的内容,增加到URL对应资源的主体内容中
json:JSON格式的数据,作为Request的内容
headers:字典,用于定制访问服务器的信息头,可将程序爬取行为模拟成浏览器的访问行为
cookies:字典或CookieJar,Request中的cookie
auth:元祖类型,支持HTTP认证功能
files:字典类型,向服务器传送文件时使用的字段
timout:设定超时时间,以秒为单位
proxies:字典类型,设定访问代理服务器,以指定的IP地址访问网络
allow_redirects:True/False,默认是True,是否可以进行重定向
stream:True/False,默认是True,是否立即下载获取的内容
verify:True/False,默认是True,是否认证SSL证书
cert:保存本体SSL证书路径的相关设置
Requests库提供的其他几个方法的参数都是上面13种,只是对有些方法来说,对比较常用的参数进行了显式定义,而没有把它们放在可选参数中。
②requests.get(url,params=None,**kwargs)
③requests.head(url,**kwargs)
④requests.post(url,data=None,json=None,**kwargs)
⑤requests.put(url,data=None,**kwargs)
⑥requests.patch(url,data=None,**kwargs)
⑦requests.delete(url,**kwargs)
[python爬虫]Requests-BeautifulSoup-Re库方案--Requests库介绍的更多相关文章
- Python爬虫入门(二)之Requests库
Python爬虫入门(二)之Requests库 我是照着小白教程做的,所以该篇是更小白教程hhhhhhhh 一.Requests库的简介 Requests 唯一的一个非转基因的 Python HTTP ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- python爬虫知识点总结(四)Requests库的基本使用
官方文档:http://docs.python-requests.org/en/master 安装方法 命令行下输入:pip3 install requests.详见:https://www.cnbl ...
- 【Python爬虫】BeautifulSoup网页解析库
BeautifulSoup 网页解析库 阅读目录 初识Beautiful Soup Beautiful Soup库的4种解析器 Beautiful Soup类的基本元素 基本使用 标签选择器 节点操作 ...
- Python爬虫十六式 - 第三式:Requests的用法
Requests: 让 HTTP 服务人类 学习一时爽,一直学习一直爽 Hello,大家好,我是Connor,一个从无到有的技术小白.今天我们继续来说我们的 Python 爬虫,上一次我们说到了 ...
- Python爬虫系列(三):requests高级耍法
昨天,我们更多的讨论了request的基础API,让我们对它有了基础的认知.学会上一课程,我们已经能写点基本的爬虫了.但是还不够,因为,很多站点是需要登录的,在站点的各个请求之间,是需要保持回话状态的 ...
- Python爬虫系列(二):requests基础
1.发送请求: import requests # 获取数据#r是一个 response 对象.包含请求返回的内容r = requests.get('https://github.com/timeli ...
- Python爬虫之BeautifulSoup的用法
之前看静觅博客,关于BeautifulSoup的用法不太熟练,所以趁机在网上搜索相关的视频,其中一个讲的还是挺清楚的:python爬虫小白入门之BeautifulSoup库,有空做了一下笔记: 一.爬 ...
- 通过哪吒动漫豆瓣影评,带你分析python爬虫与BeautifulSoup快速入门【华为云技术分享】
久旱逢甘霖 西安连着几天温度排行全国三甲,也许是<哪吒之魔童降世>的剧组买通了老天,从踩着风火轮的小朋友首映开始,就全国性的持续高温,还好今天凌晨的一场暴雨,算是将大家从中暑边缘拯救回来了 ...
随机推荐
- React Native 0.50版本新功能简介
React Native在2017年经历了众多版本的迭代,从接触的0.29版本开始,到前不久发布的0.52版本,React Native作为目前最受欢迎的移动跨平台方案.虽然,目前存在着很多的功能和性 ...
- 基于Java的HashMap和HashSet实现
一.Map接口类: import java.util.Iterator; public interface IMap<K, V> { /* 清除所有键值对 */ void clear(); ...
- MyCat-schema.xml详解
一.概念与图示 schema.xml配置的几个术语与其关系图示: 二.schema 标签 schema 标签用于定义 MyCat 实例中的逻辑库,如: <schema name="US ...
- [Swift]LeetCode868. 二进制间距 | Binary Gap
Given a positive integer N, find and return the longest distance between two consecutive 1's in the ...
- [Swift]LeetCode877. 石子游戏 | Stone Game
Alex and Lee play a game with piles of stones. There are an even number of piles arranged in a row, ...
- postgresql 删除库的时候报错database "temp_test_yang" is being accessed by other users
删除库的时候报错 ERROR: database "temp_test_yang" is being accessed by other usersDETAIL: There ar ...
- Python Django(WEB电商项目构建)
(坚持每一天,就是成功) Python Django Web框架,Django是一个开放源代码的Web应用框架,由Python写成.采用了MTV的框架模式,即模型M,模板T和视图V组成. 安装Pyth ...
- CMake根据平台移植检查设置文件编译选项
#添加函数检查功能 include(CheckFunctionExists) //检查系统是否支持accpet4,将检查结果设置至HAVE_ACCEPT4 check_function_exists( ...
- Python内置函数(16)——dir
英文文档: dir([object]) Without arguments, return the list of names in the current local scope. With an ...
- pytorch: 准备、训练和测试自己的图片数据
大部分的pytorch入门教程,都是使用torchvision里面的数据进行训练和测试.如果我们是自己的图片数据,又该怎么做呢? 一.我的数据 我在学习的时候,使用的是fashion-mnist.这个 ...