HDFS概述
HDFS概述
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.HDFS产出背景及定义
1>.HDFS产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理磁盘中,但是不方便维护和管理,迫切需求一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
2>.HDFS定义
HDFS全称为:Hadoop Distributed File System,它是一个文件系统,用于存储文件,通过目录树来定位;其次,他是分布式的,由很多服务联合起来实现其功能,集群中的服务器有各自的角色。
3>.HDFS的使用场景
适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
二.HDFS优缺点
1>.优点
一.高容错性
>.数据自动保存多个副本,它通过增加副本的形式,提高容错性;
>.某一个副本丢失以后,它可以自动恢复; 二.适合处理大数据
>.数据规模:能够处理数据规模达到GB,TB,甚至PB级别的数据;
>.文件规模:能够处理百万规模以上的文件数量,数量相当之大; 三.可构建在廉价机器上,通过多副本机智,提高可靠性。
2>.缺点
一.不适合低延迟数据访问,比如毫秒级的存储数据,是做不到的; 二.无法高效的对大量小文件进行存储
>.存储大量小文件的话,他会占用NameNode大量的内存来存储文件目录块信息。这样是不可取的,因为NameNode的内存总是有限的;
>.小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标; 三.不支持并发写入,文件随机修改
>.一个文件只能有一个写,不允许多个线程同时写;
>.仅支持数据append(追加),不支持文件的随机修改。
三.HDFS组成架构
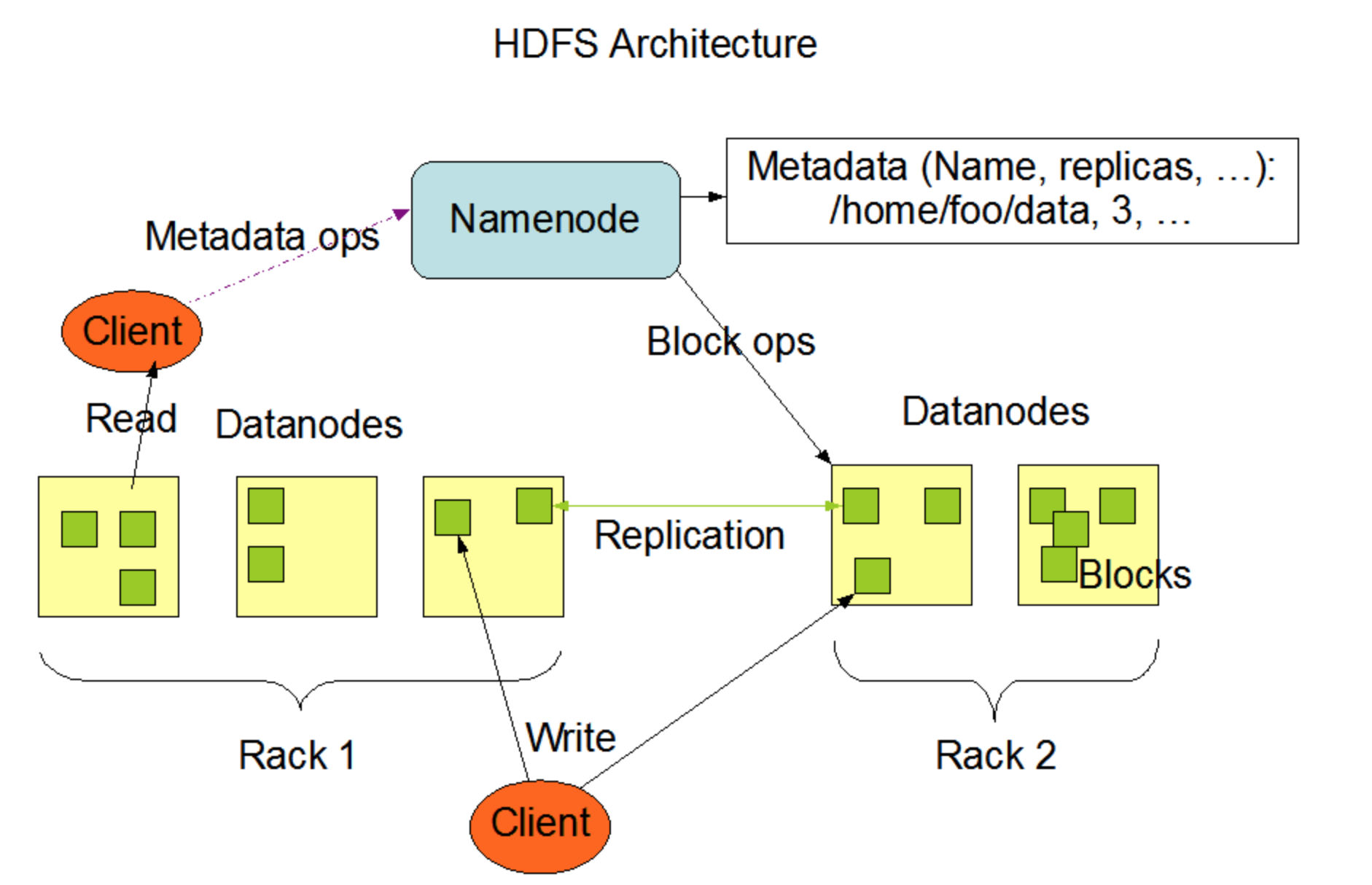
一.NameNode
就是Master,他是一个主管,管理者。
>.管理HDFS的名称空间;
>.配置副本策略;
>.管理数据块(Block)映射信息;
>.处理客户端读写请求; 二.DataNode
就是Slave。NameNode下达命令,DataNode执行实际的操作。
>.存储实际的数据块;
>.执行数据块的读/写操作; 三.Client
就是客户端。
>.文件切分,文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;
>.与NameNode交互,获取文件的位置信息;
>.与Datanode交互,读取或者写入数据;
>.Client提供一些命令来管理HDFS,比如NameNode格式化;
>.Client可以通过一些命令来访问HDFS,比如对HDFS增删改查操作; 四.Secondary NameNode
并非NameNode的热备,当NameNode刮掉的时候,它并不能马上替换NameNode并提供服务。
>.辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
>.在紧急情况下,可辅助恢复NameNode;
四.HDFS文件块大小
HDFS中文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadoop2.x版本是128M,在Hadoop1.x版本中是64M。
一.为什么Hadoop2.x版本中是128M
>.如果寻址时间为10ms,即查找到目标的bolck的时间为10ms;
>.寻址时间为传输时间的1%时,则为最佳状态。因此,传输时间=寻址时间/0.01=10ms/0.01=1000ms=1s
>.而目前磁盘的传输速度普遍为100MB/s
>.因此block的大小为=1s*100MB/s=100M
>.这个100M在外国的程序员无法用二进制表示,于是开发人员为了方便好记就找了一个二进制和改制相似的数字设置为默认值,因此Hadoop默认的大小为128MB。当然,这是为脑补出来的答案,哈哈哈~ 二.为什么块的大小不能设置太小,也不能设置太大?
>.HDFS的块设置太小,会增加寻址时间,呈现一直在找块的开始位置;
>.如果块设置的太大,从磁盘传输数据的时间会明显大雨定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。 总结:HDFS块的大小设置,主要取决于磁盘传输速度。随着科技的发展,磁盘的速度在不久的将来也会有所提高的,而Hadoop的版本默认值也会在不断的变大,这是很合理的。
关于如何测试磁盘的读写速度,可参考我之前的笔记:https://www.cnblogs.com/yinzhengjie/p/9935478.html。
HDFS概述的更多相关文章
- HDFS概述(一)
HDFS概述(一) 1. HDFS产出的背景及定义 1.1 HDFS产生的背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需 ...
- HDFS概述和Shell操作
大数据技术之Hadoop(HDFS) 第一章 HDFS概述 HDFS组成架构 HDFS文件块大小 第二章 HDFS的Shell操作(开发重点) 1.基本语法 bin/hadoop fs 具体命令 ...
- HDFS概述(6)————用户手册
目的 本文档是使用Hadoop分布式文件系统(HDFS)作为Hadoop集群或独立通用分布式文件系统的一部分的用户的起点.虽然HDFS旨在在许多环境中"正常工作",但HDFS的工作 ...
- HDFS概述(5)————HDFS HA
HA With QJM 目标 本指南概述了HDFS高可用性(HA)功能以及如何使用Quorum Journal Manager(QJM)功能配置和管理HA HDFS集群. 本文档假设读者对HDFS集群 ...
- HDFS概述(4)————HDFS权限
概述 Hadoop分布式文件系统(HDFS)的权限模型与POSIX模型的文件和目录权限模型一致.每个文件和目录与所有者和组相关联.该文件或目录将权限划分为所有者的权限,作为该组成员的其他用户的权限.以 ...
- HDFS概述(3)————HDFS Federation
本指南概述了HDFS Federation功能以及如何配置和管理联合集群. 当前HDFS背景 HDFS主要有两层: 1.Namespace (1)包含目录,文件和块. (2)它支持所有命名空间相关的文 ...
- HDFS概述(1)————HDFS架构
概述 Hadoop分布式文件系统(HDFS)是一种分布式文件系统,用于在普通商用硬件上运行.它与现有的分布式文件系统有许多相似之处.然而,与其他分布式文件系统的区别很大.HDFS具有高度的容错能力,旨 ...
- HDFS概述(2)————Block块大小设置
以下内容转自:http://blog.csdn.net/samhacker/article/details/23089157?utm_source=tuicool&utm_medium=ref ...
- Hadoop之HDFS概述
一.HDFS产生背景及定义 1.HDFS产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文 ...
随机推荐
- Android-蓝牙自动配对与隐藏对话框
一.概述 本次分析是基于Android7.0的源码. 二.自动配对分析过程 首先,我们分析一下源码的自动配对过程,packages/apps/Settings/src/com/android/sett ...
- google zxing android扫描优化&解析
这里先给出zxing包的源码地址 zip包:https://codeload.github.com/zxing/zxing/zip/master Github:https://github.com/z ...
- axis根据wsdl生成java客户端代码
根据wsdl生成java客户端代码有多个方法,其中使用axis生成的代码比较友好,也是经常用的一种方法.首先下载axis jar包:axis-bin-1_4.zip 官方地址:http://ws.Ap ...
- Express NodeJs Web框架 入门笔记
Express 是一个简洁而灵活的 node.js Web应用框架, 提供了一系列强大特性帮助你创建各种 Web 应用,和丰富的 HTTP 工具. 使用 Express 可以快速地搭建一个完整功能的网 ...
- asp.net core 自定义认证方式--请求头认证
asp.net core 自定义认证方式--请求头认证 Intro 最近开始真正的实践了一些网关的东西,最近写几篇文章分享一下我的实践以及遇到的问题. 本文主要介绍网关后面的服务如何进行认证. 解决思 ...
- Tableau环图可视化
1.选择"记录数",拖拽两个记录数放入列中,求总和,选择饼图: 2.选择"大小",调整两个饼图的大小: 3.点击第二个总和(行上的),选择“双轴”: 4.点击坐 ...
- Docker-Dockerfile及基本语法
Dockerfile的作用是通过它可以生成自定镜像,先介绍几个基本的docker命令. [docker镜像相关的命令]docker search 镜像名: 搜索镜像docker pull 镜像名: 镜 ...
- VS2017的MVC和Angular联合开发的配置文件作用
在通过MVC和Angular联合开发项目时,项目里有几个重要的配置文件,下面列出这几个配置文件的分析和比较: 主要配置文件有appsettings.json,tsconfig.json,package ...
- eclipse 更改默认主题,重写默认滚动条样式(安装DevStyle主题插件)
1.点击Help->Eclipse Marktplace 2.弹出窗口输入: DevStyle 3.点击安装,重启eclipse 4.可以设置黑色和浅色主题,个人比较喜欢浅色,重点式滚动条样式变 ...
- 光盘安装win7系统教程
光盘安装系统是最传统的安装系统的方法,虽然现在U盘安装和硬盘安装已经很方便,但仍有很多用户习惯光盘安装的方式,下面小编教大家如何利用光盘安装系统. 来源:https://www.haoxitongx. ...