Data Block Compression
The database can use table compression to eliminate duplicate values in a data block. This section describes the format of data blocks that use compression.
The format of a data block that uses basic and advanced row compression is essentially the same as an uncompressed block. The difference is that a symbol table at
the beginning of the block stores duplicate values for the rows and columns. The database replaces occurrences of these values with a short reference to the symbol
table.
数据库可以使用表压缩参数来去除数据块中的重复值,这一节描述使用压缩模式的数据块的结构。
使用基本以及高级行压缩功能的数据块基本上跟非压缩的数据块是一样的。不同之处在于一个符号表会在数据块的开头存储行和列的重复值。数据库会用出现率来替代这些数值,简短参引到该表。
Assume that the rows in Example 12–2 are stored in a data block for the seven-column sales table.
Example 12–2 Rows in sales Table
2190,13770,25-NOV-00,S,9999,23,161
2225,15720,28-NOV-00,S,9999,25,1450
34005,120760,29-NOV-00,P,9999,44,2376
9425,4750,29-NOV-00,I,9999,11,979
1675,46750,29-NOV-00,S,9999,19,1121
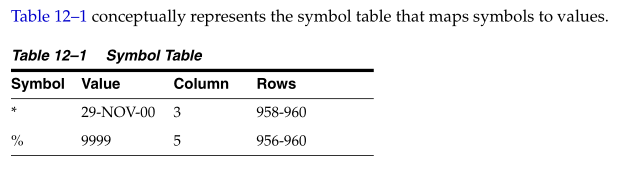
When basic or advanced row compression is applied to this table, the database replaces duplicate values with a symbol reference. Example 12–3 is a conceptual representation of the compression in which the symbol * replaces 29-NOV-00 and % replaces 9999 .
当基本或者高级行压缩功能开启了,那么数据库会把重复数值替换为一个关联的符号。例如例子12-2中重复的数据29-NOV-00被替换为*号,而9999被替换为%。
Example 12–3 OLTP Compressed Rows in sales Table
2190,13770,25-NOV-00,S,%,23,161
2225,15720,28-NOV-00,S,%,25,1450
34005,120760,*,P,%,44,2376
9425,4750,*,I,%,11,979
1675,46750,*,S,%,19,1121
如下表,概念上一个符号表会这么去将符号和值对应上。
Space Management in Data Blocks
As the database fills a data block from the bottom up, the amount of free space between the row data and the block header decreases. This free space can also shrink during updates, as when changing a trailing null to a nonnull value. The database manages free space in the data block to optimize performance and avoid wasted space.
因为数据库往数据块里填数据是从下往上的,在块头部和行数据中间的空间空间会慢慢减少。该空闲空间也可以随着更新而收缩,比如当把一个结尾的空值改为非空值。数据库通过管理这些空闲空间来优化表现以及避免空间浪费。
Percentage of Free Space in Data Blocks
The PCTFREE storage parameter is essential to how the database manages free space. This SQL parameter sets the minimum percentage of a data block reserved as free space for updates to existing rows. Thus, PCTFREE is important for preventing row migration and avoiding wasted space.
For example, assume that you create a table that will require only occasional updates, most of which will not increase the size of the existing data. You specify the PCTFREE
parameter within a CREATE TABLE statement as follows:
CREATE TABLE test_table (n NUMBER) PCTFREE 20;
PCTFREE是数据库管理空闲空间的重要参数。这个SQL参数设置数据块最小保留的空间所占总的的百分比,以供更新已存在行的操作。所以,PCTFREE对于防止行迁移和避免空间浪费是很重要的。
比如,假设你要创建一个只是偶尔会更新数据,并且大多数不会增长已存在的数据的表,你可以通过以下SQL指定PCTFREE参数:
CREATE TABLE test_table(n number) PCTFREE 20;
Figure 12–9 shows how a PCTFREE setting of 20 affects space management. The database adds rows to the block over time, causing the row data to grow upwards toward the block header, which is itself expanding downward toward the row data.
The PCTFREE setting ensures that at least 20% of the data block is free. For example, the database prevents an INSERT statement from filling the block so that the row data and header occupy a combined 90% of the total block space, leaving only 10% free.
表12-9显示了设置为20的PCTFREE是怎么影响空间管理的。比如,当一个插入语句要插入的行数据和块头占用了总空间的90%的时候,因为空闲空间会只剩下10%,数据库就会阻止这个语句往这个数据块里插数据。

Optimization of Free Space in Data Blocks
While the percentage of free space cannot be less than PCTFREE , the amount of free space can be greater. For example, a PCTFREE setting of 20% prevents the total amount of free space from dropping to 5% of the block, but permits 50% of the block to be freespace. The following SQL statements can increase free space:
■ DELETE statements
■ UPDATE statements that either update existing values to smaller values or increase existing values and force a row to migrate
■ INSERT statements on a table that uses OLTP compression . If inserts fill a block with data, then the database invokes block compression, which may result in the block having more free space.
数据块空闲空间的优化:
当空闲空间所占的百分比不能少于PCTFREE参数的同时,空闲空间的总数可以更大,比如,PCTFREE是20的时候,会阻止空闲空间跌到5%,但允许50%的空闲空间,以下SQL可以增加空闲空间:
■DELETE语句
■UPDATE语句(把已有数据更新为更小的数据,或者增长数据强制使行迁移)
■插入语句,对一个OLTP压缩模式的表,假如往块中插入数据,数据库会对块进行压缩,这样子就有可能会让块有更多的空闲空间。
The space released is available for INSERT statements under the following conditions:
■ If the INSERT statement is in the same transaction and after the statement that frees space, then the statement can use the space.
■ If the INSERT statement is in a separate transaction from the statement that frees space (perhaps run by another user), then the statement can use the space made
available only after the other transaction commits and only if the space is needed.
对于INSERT语句,释放的空间在以下情况是可用的:
如果INSERT语句是在同一个事务之中,在会释放空间的语句过后,那么该INSERT语句可以使用这一部分空间
如果INSERT语句是在不同的事务之中,那么只有当那个释放空间的语句所在的事务提交之后(可能由其他用户发起的),该insert语句才会在需要的时候使用到这一部分空间
Coalescing Fragmented Space
Released space may or may not be contiguous with the main area of free space in a data block, as shown in Figure 12–10. Noncontiguous free space is called fragmented space.
聚合碎片空间
已释放的空间可能是也可能不是和数据块中主要的空闲空间是连续的。比如在12-10中显示的。非连续的空闲空间称为碎片空间。

Oracle Database automatically and transparently coalesces the free space of a data block only when the following conditions are true:
■ An INSERT or UPDATE statement attempts to use a block that contains sufficient free
space to contain a new row piece.
■ The free space is fragmented so that the row piece cannot be inserted in a contiguous section of the block.
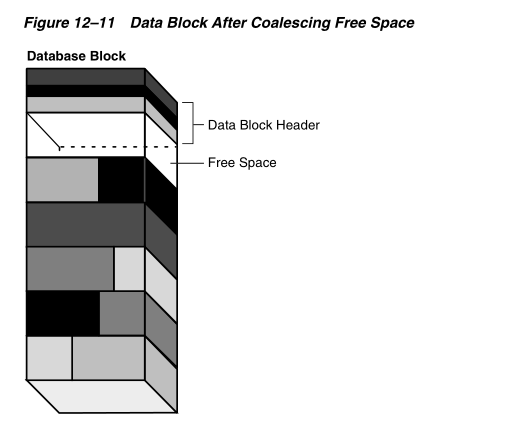
After coalescing, the amount of free space is identical to the amount before the operation, but the space is now contiguous.
Figure 12–11 shows a data block after space has been coalesced.
数据库只有在以下情况的时候会自动且透明地聚合数据块中的空闲空间:
■一个插入或者更新语句试图使用数据块中的有效空闲空间来容纳一个新的行片段
■空闲空间是碎片化的因此行片段无法被插入到数据块中的连续部分
在聚合之后,空闲空间的大小是和操作之前完全一致的,只不过空间现在变成了连续的而已。
图12-11显示了一个聚合过后的数据块
Oracle Database performs coalescing only in the preceding situations because otherwise performance would decrease because of the continuous coalescing of the free space in data blocks.
数据库只有在上述的情况下才会执行聚合操作。否则性能会因为持续的空闲空间聚合操作而下降。
Reuse of Index Space
The database can reuse space within an index block. For example, if you insert a value into a column and delete it, and if an index exists on this column, then the database can reuse the index slot when a row requires it.
The database can reuse an index block itself. Unlike a table block, an index block only becomes free when it is empty. The database places the empty block on the free list of the index structure and makes it eligible for reuse. However, Oracle Database does not automatically compact the index: an ALTER INDEX REBUILD or COALESCE statement is required.
Figure 12–12 represents an index of the employees.department_id column before the index is coalesced. The first three leaf blocks are only partially full, as indicated by the gray fill lines.
索引空间的重用
数据库可以重用索引块中的空间。比如,当你往里面插入一列然后删除它,并且假如这一列存在一个索引,那么数据库可以重用这个索引的插槽假如某一行数据请求它。
数据库可以重用一个索引块本身,不像表的块,一个索引块只有当它为空的时候它才是空闲的。数据库把这些空块放到索引结构的空闲列表中,并且让它变为可重用。不过,数据库不会自动去收缩索引,必须通过alter index rebuild 或者 coalesce语句。
表12-12表示employees表的department_id列的索引聚合前的结构,前面的三个叶块只是部分填满,被分配给灰色的填充行。
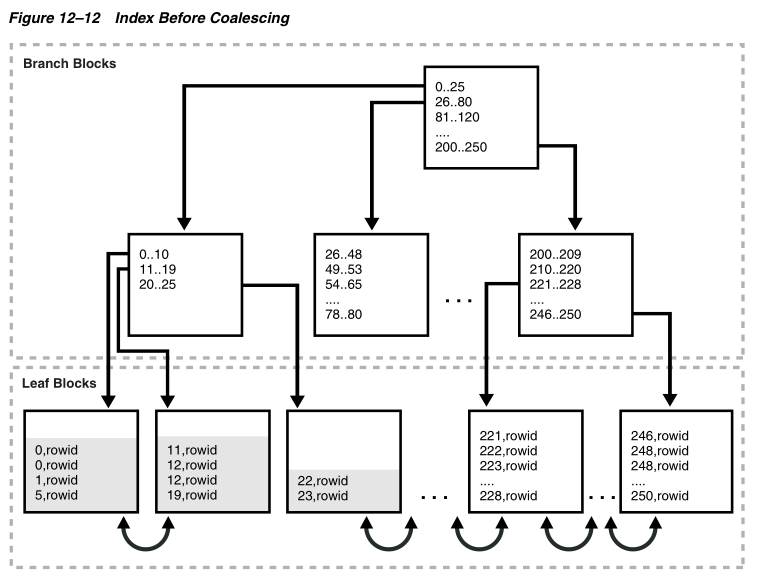
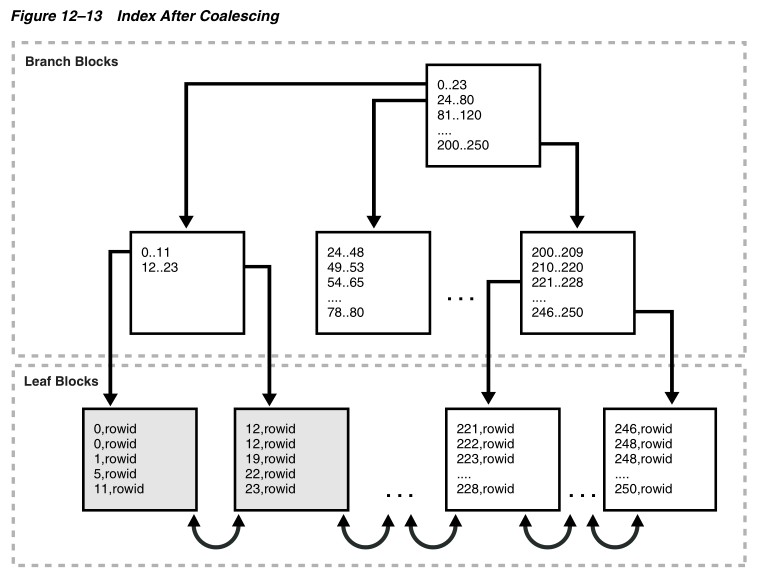
Figure 12–13 shows the index in Figure 12–12 after the index has been coalesced. The first two leaf blocks are now full, as indicated by the gray fill lines, and the third leaf
block has been freed.
表12-13表示经过聚合后的索引结构,前面的两个叶块已经被灰色填充行填满,第三个叶块变为空闲。
Chained and Migrated Rows
Oracle Database must manage rows that are too large to fit into a single block. The following situations are possible:
■ The row is too large to fit into one data block when it is first inserted.
In row chaining, Oracle Database stores the data for the row in a chain of one or more data blocks reserved for the segment. Row chaining most often occurs with large rows. Examples include rows that contain a column of data type LONG or LONG RAW , a VARCHAR2(4000) column in a 2 KB block, or a row with a huge number of columns. Row chaining in these cases is unavoidable.
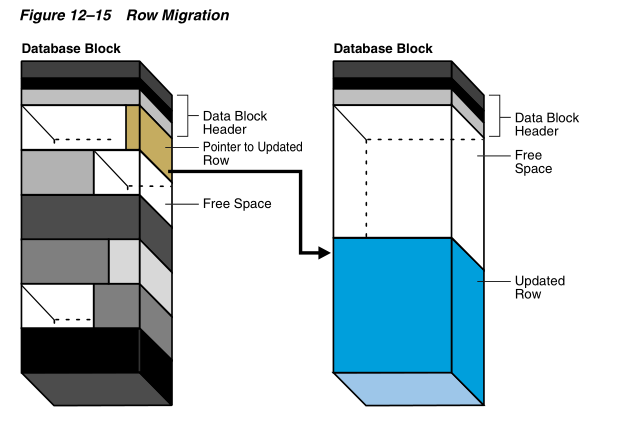
■ A row that originally fit into one data block is updated so that the overall row length increases, but insufficient free space exists to hold the updated row. In row migration, Oracle Database moves the entire row to a new data block, assuming the row can fit in a new block. The original row piece of a migrated row contains a pointer or "forwarding address" to the new block containing the migrated row. The rowid of a migrated row does not change.
■ A row has more than 255 columns.Oracle Database can only store 255 columns in a row piece. Thus, if you insert a row into a table that has 1000 columns, then the database creates 4 row pieces, typically chained over multiple blocks.
行链接和行迁移
oracle数据库必须管理那些太大的行数据(没办法插入到一个单一的数据块中),以下几种可能的情况:
■行数据太大以至于一开始就无法插入到数据块中。在行链接中,oracle会把行数据存储在一个分布在段中一个或多个数据块中的链接(想象一条锁链)中。行链接一般发生在行数据太大的情况下。比如说行数据里面包含了LONG或者LONG RAW类型的列,在一个2KB的块中存储4000字符长度的列,或者一行有非常多列的数据。行链接在这种情况下是不可避免的。(除非你的块很大)
■一行本身已经存储在数据块中,但更新后行长度增长了,但没有足够的空闲空间来存储更新后的行。这种会导致行迁移,数据库会把行记录移动到一个新的数据块中(假设一个数据块能够装下更新后的行数据的情况下)。原本的行片段会包含一个前滚的指针指向新的数据块,但rowid并没有改变。
■一行数据包含超过255个列。Oracle数据库只可以在一个行片段中存储255列。所以,如果你插入的行数据包含1000列数据,那么数据库会创建4个行片段,链接到多个数据块中。
Figure 12–14 depicts shows the insertion of a large row in a data block. The row is too large for the left block, so the database chains the row by placing the first row piece in the left block and the second row piece in the right block
图12-14描绘了在一个数据块中插入一个大的行的情况。对于左边的数据块来说,这一行数据太大,所以数据库通过行链接在左边的数据块中放置第一个行片段,然后在第二个数据块中放置第二个行片段。然后会有一个行片段指针指向第二个行片段。
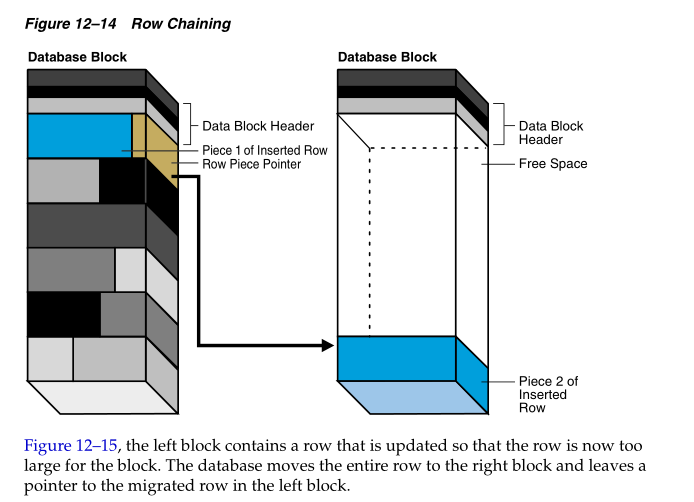
图12-15中,左边的数据块原本容纳的行数据更新后对于数据库来说变得太大。数据库将这条行记录移动到右边的数据块,然后在左边的数据块留下一个指针指向更新后的行片段。
When a row is chained or migrated, the I/O needed to retrieve the data increases. This situation results because Oracle Database must scan multiple blocks to retrieve the information for the row. For example, if the database performs one I/O to read an index and one I/O to read a nonmigrated table row, then an additional I/O is required
to obtain the data for a migrated row.
The Segment Advisor, which can be run both manually and automatically, is an Oracle Database component that identifies segments that have space available for reclamation. The advisor can offer advice about objects that have significant free space or too many chained rows.
当某一行数据做了链接或者迁移,I/O需要抓取的数据就增加了。这是因为数据库必须扫描多个数据块来获取行数据的信息。比如,如果数据库要通过一次I/O来读一个索引然后一次I/O来读没有迁移的行,那么对于迁移过后的行,数据库就需要多做一次I/O来找到拥有实际数据的迁移过后的行。
段优化器能够辨别段中有多少可以用于回收的空间,可以手动或者自动自行。它可以给那些有太多空闲空间或者有太多行链接的对象提供建议。
--根据11g官方文档翻译,若有翻译不当或错误,请不吝指正。
Data Block Compression的更多相关文章
- Populating Tabular Data Block Manually Using Cursor in Oracle Forms
Suppose you want to populate a non-database data block with records manually in Oracle forms. This t ...
- ORA-01578 data block corrupted 数据文件损坏 与 修复 (多为借鉴 linux)
好吧,先说说造成崩溃的原因: 使用redhat 5.9 Linux 作为数据库服务器, 周五数据库正在使用中,硬关机造成数据库文件部分损坏(周一上班时,应用程序启动不起来,查看日志文件时,发现一个数据 ...
- Data Block -- Uncompressed
Overview of Data Blocks Oracle Database manages the logical storage space in the data files of a dat ...
- Hadoop EC 踩坑 :data block 缺失导致的 HDFS 传输速率下降
环境:hadoop-3.0.2 + 11 机集群 + RS-6-3-1024K 的EC策略 状况:某天,往 HDFS 上日常 put 业务数据时,发现传输速率严重下降 分析: 检查集群发现,在之前的传 ...
- ORA-01578 ORACLE data block corrupted (file # 29, block # 2889087)
BW数据库后台报错如下:F:\oracle\SBP\saptrace\diag\rdbms\sbp\sbp\trace ORA-01578: ORACLE data block corrupted ( ...
- 模拟ORA-26040: Data block was loaded using the NOLOGGING option
我们知道通过设置nologging选项.能够加快oracle的某些操作的运行速度,这在运行某些维护任务时是非常实用的,可是该选项也非常危急,假设使用不当,就可能导致数据库发生ORA-26040错误. ...
- block(data block,directory block)、inode、块位图、inode位图和super block概念详解【转】
本文转载自:https://blog.csdn.net/jhndiuowehu/article/details/50788287 一.基本概念: 1.block:文件系统中存储数据的最小单元 ...
- oracle --(一)数据块(data Block)
基本关系:数据库---表空间---数据段---分区---数据块 数据块(data Block)一.数据块Block是Oracle存储数据信息的最小单位.这里说的是Oracle环境下的最小单位.Orac ...
- Copy Records From One Data Block To Another Data Block In Oracle Forms
In this tutorial you will learn to copy the records from one data block to another data block on sam ...
随机推荐
- spring IOC 分析及实现
什么是IOC Inversion of Control,控制反转,也成依赖倒置. 反转: 依赖对象的创建被反转,使用IOC之前,对象由自己创建,反转后,由IOC容器获取 IOC容器的工作: 负责创建, ...
- Sublime 个人配置
Sublime 个人配置 用的faltland主题,之后还加了一些自己喜欢的东西. 效果图如下: { "always_show_minimap_viewport": true, & ...
- dubbo搭建
1.安装java : yum install java 2.下载Tomcat: wget http://mirrors.shu.edu.cn/apache/tomcat/tomcat-9/v9.0.1 ...
- Go 初体验 - 闭包,数组,切片,锁
我们先假设一个需求,创建一个数组,里面存放 0 - 99 的整数. 上代码: 输出: 然而并不是我们想要的结果,很多重复数值. 释义: 12行这个闭包函数对 i 的传递并非深拷贝,而是传递了变量指针, ...
- cycle标签和random两种方式美化表格
一:cycle标签实现给表格变色 1. <style>标签里写好需要的颜色 2. 在要变色的地方(行/列)加固定的语句,按照顺序依次执行 代码: <!DOCTYPE html> ...
- No module named 'pip._internal'
报错: Traceback (most recent call last):File "/home/myuser/.local/bin/pip", line 7, in <m ...
- python函数部分----函数初识
0.来源http://www.cnblogs.com/jin-xin/articles/8241942.html 1.return 返回0个返回值,返回一个返回值.返回多个返回值 None.如果一个变 ...
- UWP中MarkupExtension的使用
Xaml作为一种描述语言,在编程中极大地简化了页面开发的繁琐及时间消耗,这得益于它的多种特性:数据绑定.动画.资源文件等等.标记扩展作为其一个特性,在xaml中有不可替代的作用,今天分析下自定义标记扩 ...
- Linux学习方法和心态
如果单纯是为了架站,那我就可以毕业了. 成就感+兴趣=学习的动力. 不同的环境下,解决问题的办法有很多种,只要行得通,都是好方法. Distribution 安装 熟悉Shell环境 Shell脚本 ...
- Exp6 信息搜集与漏洞扫描 20164303
一.实践目标 掌握信息搜集的最基础技能与常用工具的使用方法. 二.实践内容. (1)各种搜索技巧的应用 (2)DNS IP注册信息的查询 (3)基本的扫描技术:主机发现.端口扫描.OS及服务版本探测. ...