Hadoop学习------Hadoop安装方式之(二):伪分布部署
要想发挥Hadoop分布式、并行处理的优势,还须以分布式模式来部署运行Hadoop。单机模式是指Hadoop在单个节点上以单个进程的方式运行,伪分布模式是指在单个节点上运行NameNode、DataNode、JobTracker、TaskTracker、SeconderyNameNode5个进程,而分布式模式是指在不同节点上分别运行上述5个进程中的某几个,比如在某个节点上运行DataNode和TaskTracker。
前面几步和单机部署一样,可以参照Hadoop学习------Hadoop安装方式之(一):单机部署
这里重点讲述几个配置文件的修改和部署完成后的测试。
1、修改core-site.xml 文件
cd /usr/local/hadoop/etc/hadoop/
vi core-site.xml
在其中的<configuration>中添加以下内容
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
其中fs.defaultFS:代表配置NN节点地址和端口号 fs.defaultFS - 这是一个描述集群中NameNode结点的URI(包括协议、主机名称、端口号),集群里面的每一台机器都需要知道NameNode的地址。DataNode结点会先在NameNode上注册,这样它们的数据才可以被使用。独立的客户端程序通过这个URI跟DataNode交互,以取得文件的块列表。
hdfs://localhost:9000:其中localhost替换为ip或则映射主机名
hadoop.tmp.dir是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site-xml中不配置namenode 和datanode的存放位置,默认就放在这个路径下
2、修改配置文件 hdfs-site.xml
cd /usr/local/hadoop/etc/hadoop/
vi hdfs-site.xml
其中的<configuration>中添加以下内容
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
dfs.replication,它决定着系统里面的文件块的数据备份个数。对于一个实际的应用,它应该被设为3(这个数字并没有上限,但更多的备份可能并没有作用,而且会占用更多的空间)。少于三个的备份,可能会影响到数据的可靠性(系统故障时,也许会造成数据丢失)
dfs.data.dir这是DataNode结点被指定存储数据的本地文件系统路径。DataNode结点上的这个路径没必要完全相同。因为每台机器的环境很可能是不一样的。但如果每台机器上的这个路径都是统一配置的话,工作会变得简单一些。默认情况下,它的值是Hadoop.temp.dir,这个路径只能用于测试的目的,因为,他很可能会丢失掉一些数据,所以,这个值最好还是被覆盖。
dfs.name.dir 这是NameNode结点存储Hadoop文件信息的本地系统路径。这个值只对NameNode有效,DataNode并不需要使用它。上面对于/tmp的警告同样使用于这里。在实际应用中,它最好被覆盖掉。
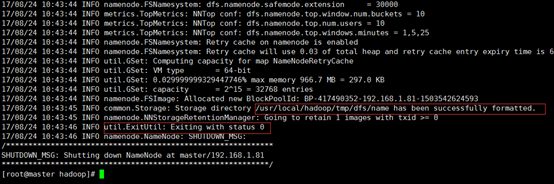
3、配置完成后,执行NameNode 的格式化
cd /usr/local/hadoop
./bin/hdfs namenode –format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错
4、开启 NameNode 和 DataNode 守护进程
./sbin/start-dfs.sh
若出现如下SSH提示,输入yes即可。
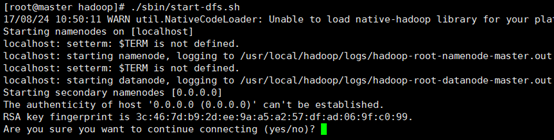
启动时可能会出现如下 WARN 提示:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable。该 WARN 提示可以忽略,并不会影响正常使用(该 WARN 可以通过编译 Hadoop 源码解决)。

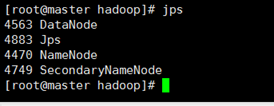
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
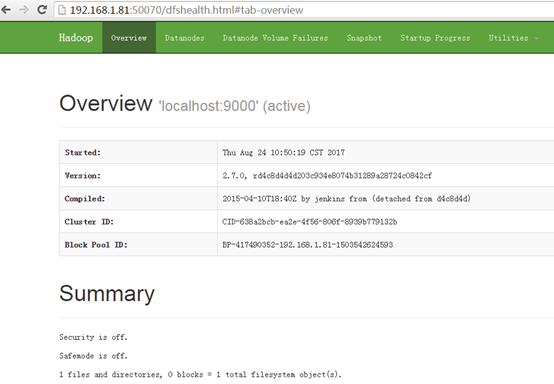
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
(Linux系统 无法直接查看,可通过windows系统访问)
5、运行Hadoop伪分布式实例
伪分布需要我们读取HDFS上的数据,要使用HDFS,我们需要在HDFS中创建用户目录,并放入几个文件。
./bin/hdfs dfs -mkdir -p /user/hadoop
接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/hadoop/input:
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
如果报没有路径错误,说明当前登录的用户和dfs里建的用户目录不对应(比如root),可以切换成hadoop用户,也可以在把路径改为全路径 /user/hadoop/input

复制完成后,可以通过如下命令查看文件列表
./bin/hdfs dfs -ls input
伪分布式运行 MapReduce 作业的方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件(可以将单机步骤中创建的本地 input 文件夹,输出结果 output 文件夹都删掉来验证这一点)。
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
查看运行结果
./bin/hdfs dfs -cat output/*
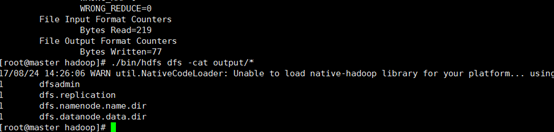
我们也可以将运行结果取回到本地:
rm -r ./output # 先删除本地的 output 文件夹(如果存在)
./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/*
若要关闭 Hadoop 需要运行
./sbin/stop-dfs.sh
注意:下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行 ./sbin/start-dfs.sh 就行
6、启动YARN
伪分布式不启动 YARN 也可以,一般不会影响程序执行
大家可能会有疑惑,启动 Hadoop 后,见不到书上所说的 JobTracker 和 TaskTracker。这是因为新版的 Hadoop 使用了新的 MapReduce 框架(MapReduce V2,也称为 YARN,Yet Another Resource Negotiator)
YARN 是从 MapReduce 中分离出来的,负责资源管理与任务调度。YARN 运行于 MapReduce 之上,提供了高可用性、高扩展性,上述通过 ./sbin/start-dfs.sh 启动 Hadoop,仅仅是启动了 MapReduce 环境,我们可以启动 YARN ,让 YARN 来负责资源管理与任务调度。
6.1 修改配置文件 mapred-site.xml
cd /usr/local/hadoop/etc/hadoop/
需要将mapred-site.xml.template 文件改名或者复制一份
mv mapred-site.xml.template mapred-site.xml
或 cp mapred-site.xml.template mapred-site.xml
然后在进行编辑 vi mapred-site.xml
在<configuration> 中添加
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
6.2修改配置文件 yarn-site.xml
cd /usr/local/hadoop/etc/hadoop/
vi yarn-site.xml
在<configuration>中添加
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
6.3 启动YARN 以及检验
完成前面两步就可以启动 YARN 了(需要先执行过 ./sbin/start-dfs.sh)
切换到hadoop主目录 cd /usr/local/hadoop
./sbin/start-yarn.sh # 启动YARN
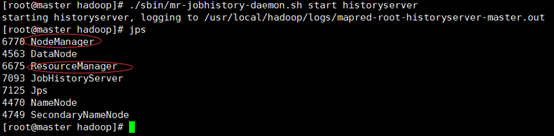
./sbin/mr-jobhistory-daemon.sh start historyserver # 开启历史服务器,才能在Web中查看任务运行情况
开启后通过 jps 查看,可以看到多了 NodeManager 和 ResourceManager 两个后台进程
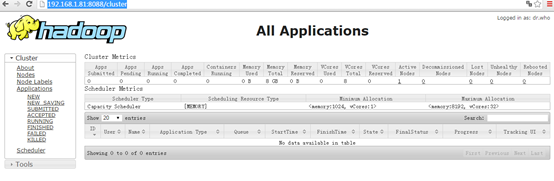
启动 YARN 之后,运行实例的方法还是一样的,仅仅是资源管理方式、任务调度不同。观察日志信息可以发现,不启用 YARN 时,是 “mapred.LocalJobRunner” 在跑任务,启用 YARN 之后,是 “mapred.YARNRunner” 在跑任务。启动 YARN 有个好处是可以通过 Web 界面查看任务的运行情况:http://localhost:8088/cluster
访问Job History Server的web页面 http://localhost:19888/

但 YARN 主要是为集群提供更好的资源管理与任务调度,然而这在单机上体现不出价值,反而会使程序跑得稍慢些。因此在单机上是否开启 YARN 就看实际情况了。
6.4 关闭YARN
如果不想启动 YARN,务必把配置文件 mapred-site.xml 重命名,改成 mapred-site.xml.template,需要用时改回来就行。否则在该配置文件存在,而未开启 YARN 的情况下,运行程序会提示 “Retrying connect to server: 0.0.0.0/0.0.0.0:8032” 的错误,这也是为何该配置文件初始文件名为 mapred-site.xml.template。 关闭命令如下
./sbin/stop-yarn.sh
./sbin/mr-jobhistory-daemon.sh stop historyserver
也可以用下面的启动/停止命令,等同于start/stop-dfs.sh + start/stop-yarn.sh
sbin/start-all.sh
sbin/stop-all.sh
Hadoop学习------Hadoop安装方式之(二):伪分布部署的更多相关文章
- (一)Hadoop1.2.1安装——单节点方式和单机伪分布方式
Hadoop1.2.1安装——单节点方式和单机伪分布方式 一. 需求部分 在Linux上安装Hadoop之前,需要先安装两个程序: 1)JDK 1.6(或更高版本).Hadoop是用Java编写的 ...
- Hadoop学习------Hadoop安装方式之(三):分布式部署
这里为了方便直接将单机部署过的虚拟机直接克隆,当然也可以不这样做,一个个手工部署. 创建完整克隆——>下一步——>安装位置.等待一段时间即可. 我这边用了三台虚拟机,分别起名master, ...
- Hadoop学习------Hadoop安装方式之(一):单机部署
Hadoop 默认模式为单机(非分布式模式),无需进行其他配置即可运行.非分布式即单 Java 进程,方便进行调试. 1.创建用户 1.1创建hadoop用户组和用户 一般我们不会经常使用root用户 ...
- Hadoop学习笔记——安装Hadoop
sudo mv /home/common/下载/hadoop-2.7.2.tar.gz /usr/local sudo tar -xzvf hadoop-2.7.2.tar.gz sudo mv ha ...
- Hadoop 2.2.0单节点的伪分布集成环境搭建
Hadoop版本发展历史 第一代Hadoop被称为Hadoop 1.0 1)0.20.x 2)0.21.x 3)0.22.x 第二代Hadoop被称为Hadoop 2.0(HDFS Federatio ...
- Hadoop学习---Hadoop的深入学习
Hadoop生态圈 存储数据HDFS(Hadoop Distributed File System),运行在通用硬件上的分布式文件系统.具有高度容错性.高吞吐量的的特点. 处理数据MapReduce, ...
- Hadoop学习之路(十二)分布式集群中HDFS系统的各种角色
NameNode 学习目标 理解 namenode 的工作机制尤其是元数据管理机制,以增强对 HDFS 工作原理的 理解,及培养 hadoop 集群运营中“性能调优”.“namenode”故障问题的分 ...
- hadoop学习;安装jdk,workstation虚拟机v2v迁移;虚拟机之间和跨物理机之间ping网络通信;virtualbox的centos中关闭防火墙和检查服务启动
JDK 在Ubuntu下的安装 与 环境变量的配置 前期准备工作: 找到 JDK 和 配置TXT文件 并拷贝到桌面下 不是目录 而是文件拷贝到桌面下 以下的命令部分就直接复制粘贴就能够了 1.配 ...
- Hadoop学习-hdfs安装及其一些操作
hdfs:分布式文件系统 有目录结构,顶层目录是: /,存的是文件,把文件存入hdfs后,会把这个文件进行切块并且进行备份,切块大小和备份的数量有客户决定. 存文件的叫datanode,记录文件的切 ...
随机推荐
- android ----- 分享的连接在手机上打开App
首先做成HTML的页面,页面内容格式如下: <a href="[scheme]://[host]/[path]?[query]">启动应用程序</a> 这一 ...
- 撸一个小型PHP框架
项目地址:https://packagist.org/packages/cshaptx4869/frame # 开发中... ## 20190410 注解路由 ## 20190411 依赖注入 容器I ...
- IDEA常用操作
ctrl+tab:切换不同的tab Ctrl+D:比较两个目录或文件(先选中) Alt+斜杠 :智能感知提示单词 Ctrl+K :版本修改记录 Alt+Enter:正则检查 Ctrl+Alt+B:查找 ...
- 控制dom 加载成功后事件
- F7+vue 物理返回键监听使用
以前使用的是纯F7,这个项目加了Vue进去,但碰到了一个问题,就是这样监听不到安卓物理键的返回,它是点击返回,直接推出程序,这个坑有点深,查了不少资料也问了不少人,最后在网上看到了别人的写的,自己也改 ...
- Oracle中 “ORA-14551: 无法在查询中执行 DML 操作” 如何解决
在编写一个数据库函数时,方法实现需要查询后进行修改,出现ora-14551的错误 create or replace function fun_DxcBillSn(tabType integer,ta ...
- 棋牌平台开发教程之扎金花大小比较算法在php中的实现
PHP中扎金花比大小如何实现 在棋牌游戏中,不管是现实的还是线上的,扎金花无疑是最热门棋牌游戏之一,鄙人从小就酷爱扎金花,机缘巧合后面从事了IT行业,话不多说,直接进去正题吧. 扎金花两副牌的比较规则 ...
- python之路-----MySql操作
一.概述 1.什么是数据库 数据库就是按照数据结构来组织.存储和管理数据的仓库.如我们创建的文件夹,就是一个数据库. 2.什么是mysql,oracle,access,sqlit等? 他们都是一款软件 ...
- Python_Mix*OS模块,序列化模块种的json,pickle
os.path.basename(path)返回path最后的文件名,如何path以/或\结尾,那么就会返回空值,即os.path.split(path)的第一个元素 ret = os.path.ba ...
- sqlserver常用存储过程基本语法
一.定义变量--简单赋值 declare @a intset @a=5 print @a --使用select语句赋值 declare @user1 nvarchar(50) select @user ...