Scrapyd 改进第一步: Web Interface 添加 charset=UTF-8, 避免查看 log 出现中文乱码
0.问题现象和原因
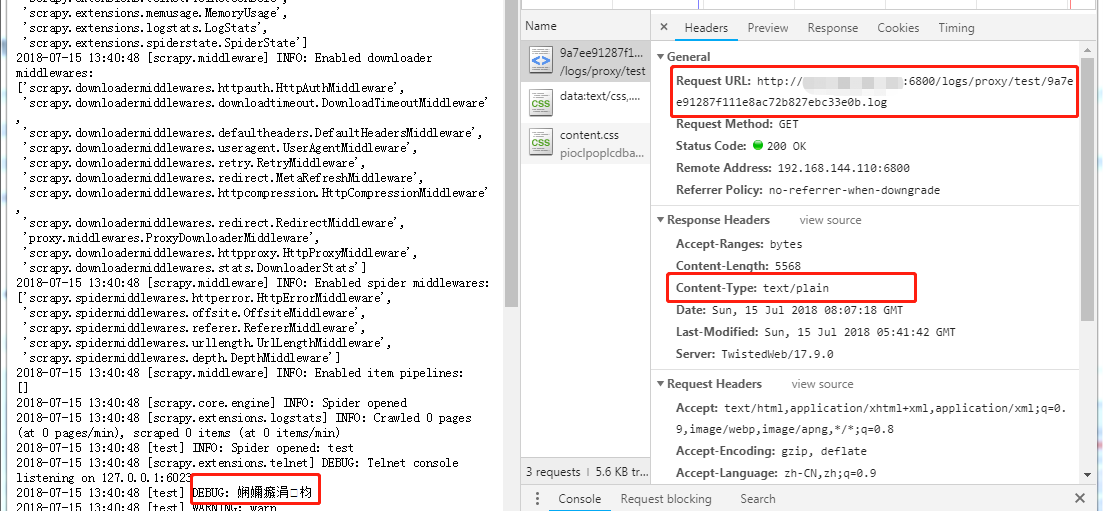
如下图所示,由于 Scrapyd 的 Web Interface 的 log 链接直接指向 log 文件,Response Headers 的 Content-Type 又没有声明字符集 charset=UTF-8,因此通过浏览器查看 log 会出现非 ASCII 乱码。
1.解决思路
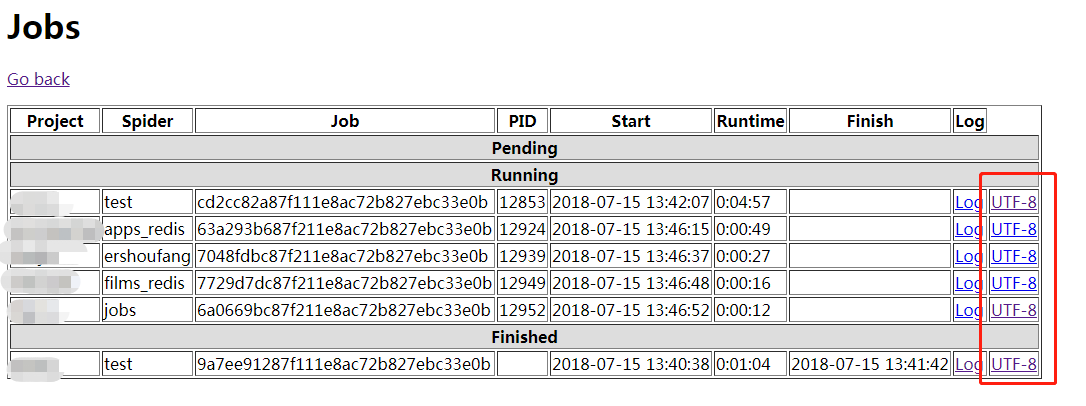
(1) 如下图所示,在 Jobs 页面添加带有项目信息的 UTF-8 超链接,如 http://127.0.0.1:6800/logs/UTF-8.html?project=proxy&spider=test&job=cd2cc82a87f111e8ac72b827ebc33e0b
(2) 在 Scrapyd 的 logs 目录新建 UTF-8.html,通过 <meta charset="UTF-8"> 声明编码
(3) 新页面打开超链接后,通过 JS 获取 url 查询对,然后更新 UTF-8.html 页面的 iframe 的 src 属性,如 <iframe src="/logs/proxy/test/9a7ee91287f111e8ac72b827ebc33e0b.log" width="100%" height="100%"></iframe>
(4) 浏览器自动加载 iframe 获取 log 文件
2.修改 Scrapyd 代码
/site-packages/scrapyd/website.py
改动位置:
(1) table 添加最后一列,见红色代码
def render(self, txrequest):
cols = 9 ######## 8
s = "<html><head><meta charset='UTF-8'><title>Scrapyd</title></head>"
s += "<body>"
s += "<h1>Jobs</h1>"
s += "<p><a href='..'>Go back</a></p>"
s += "<table border='1'>"
s += "<tr><th>Project</th><th>Spider</th><th>Job</th><th>PID</th><th>Start</th><th>Runtime</th><th>Finish</th><th>Log</th>"
if self.local_items:
s += "<th>Items</th>"
#cols = 9 ########
cols += 1 ########
(2) 有两处需要添加 UTF-8 超链接,分别对应 Running 和 Finished,见红色代码
s += "<td><a href='/logs/%s/%s/%s.log'>Log</a></td>" % (p.project, p.spider, p.job)
s += "<td><a href='/logs/UTF-8.html?project=%s&spider=%s&job=%s' target='_blank'>UTF-8</a></td>" % (p.project, p.spider, p.job) ########
(3) 完整代码:
from datetime import datetime import socket from twisted.web import resource, static
from twisted.application.service import IServiceCollection from scrapy.utils.misc import load_object from .interfaces import IPoller, IEggStorage, ISpiderScheduler from six.moves.urllib.parse import urlparse class Root(resource.Resource): def __init__(self, config, app):
resource.Resource.__init__(self)
self.debug = config.getboolean('debug', False)
self.runner = config.get('runner')
logsdir = config.get('logs_dir')
itemsdir = config.get('items_dir')
local_items = itemsdir and (urlparse(itemsdir).scheme.lower() in ['', 'file'])
self.app = app
self.nodename = config.get('node_name', socket.gethostname())
self.putChild(b'', Home(self, local_items))
if logsdir:
self.putChild(b'logs', static.File(logsdir.encode('ascii', 'ignore'), 'text/plain'))
if local_items:
self.putChild(b'items', static.File(itemsdir, 'text/plain'))
self.putChild(b'jobs', Jobs(self, local_items))
services = config.items('services', ())
for servName, servClsName in services:
servCls = load_object(servClsName)
self.putChild(servName.encode('utf-8'), servCls(self))
self.update_projects() def update_projects(self):
self.poller.update_projects()
self.scheduler.update_projects() @property
def launcher(self):
app = IServiceCollection(self.app, self.app)
return app.getServiceNamed('launcher') @property
def scheduler(self):
return self.app.getComponent(ISpiderScheduler) @property
def eggstorage(self):
return self.app.getComponent(IEggStorage) @property
def poller(self):
return self.app.getComponent(IPoller) class Home(resource.Resource): def __init__(self, root, local_items):
resource.Resource.__init__(self)
self.root = root
self.local_items = local_items def render_GET(self, txrequest):
vars = {
'projects': ', '.join(self.root.scheduler.list_projects())
}
s = """
<html>
<head><meta charset='UTF-8'><title>Scrapyd</title></head>
<body>
<h1>Scrapyd</h1>
<p>Available projects: <b>%(projects)s</b></p>
<ul>
<li><a href="/jobs">Jobs</a></li>
""" % vars
if self.local_items:
s += '<li><a href="/items/">Items</a></li>'
s += """
<li><a href="/logs/">Logs</a></li>
<li><a href="http://scrapyd.readthedocs.org/en/latest/">Documentation</a></li>
</ul> <h2>How to schedule a spider?</h2> <p>To schedule a spider you need to use the API (this web UI is only for
monitoring)</p> <p>Example using <a href="http://curl.haxx.se/">curl</a>:</p>
<p><code>curl http://localhost:6800/schedule.json -d project=default -d spider=somespider</code></p> <p>For more information about the API, see the <a href="http://scrapyd.readthedocs.org/en/latest/">Scrapyd documentation</a></p>
</body>
</html>
""" % vars
return s.encode('utf-8') class Jobs(resource.Resource): def __init__(self, root, local_items):
resource.Resource.__init__(self)
self.root = root
self.local_items = local_items def render(self, txrequest):
cols = 9 ######## 8
s = "<html><head><meta charset='UTF-8'><title>Scrapyd</title></head>"
s += "<body>"
s += "<h1>Jobs</h1>"
s += "<p><a href='..'>Go back</a></p>"
s += "<table border='1'>"
s += "<tr><th>Project</th><th>Spider</th><th>Job</th><th>PID</th><th>Start</th><th>Runtime</th><th>Finish</th><th>Log</th>"
if self.local_items:
s += "<th>Items</th>"
#cols = 9 ########
cols += 1 ########
s += "</tr>"
s += "<tr><th colspan='%s' style='background-color: #ddd'>Pending</th></tr>" % cols
for project, queue in self.root.poller.queues.items():
for m in queue.list():
s += "<tr>"
s += "<td>%s</td>" % project
s += "<td>%s</td>" % str(m['name'])
s += "<td>%s</td>" % str(m['_job'])
s += "</tr>"
s += "<tr><th colspan='%s' style='background-color: #ddd'>Running</th></tr>" % cols
for p in self.root.launcher.processes.values():
s += "<tr>"
for a in ['project', 'spider', 'job', 'pid']:
s += "<td>%s</td>" % getattr(p, a)
s += "<td>%s</td>" % p.start_time.replace(microsecond=0)
s += "<td>%s</td>" % (datetime.now().replace(microsecond=0) - p.start_time.replace(microsecond=0))
s += "<td></td>"
s += "<td><a href='/logs/%s/%s/%s.log'>Log</a></td>" % (p.project, p.spider, p.job)
s += "<td><a href='/logs/UTF-8.html?project=%s&spider=%s&job=%s' target='_blank'>UTF-8</a></td>" % (p.project, p.spider, p.job) ########
if self.local_items:
s += "<td><a href='/items/%s/%s/%s.jl'>Items</a></td>" % (p.project, p.spider, p.job)
s += "</tr>"
s += "<tr><th colspan='%s' style='background-color: #ddd'>Finished</th></tr>" % cols
for p in self.root.launcher.finished:
s += "<tr>"
for a in ['project', 'spider', 'job']:
s += "<td>%s</td>" % getattr(p, a)
s += "<td></td>"
s += "<td>%s</td>" % p.start_time.replace(microsecond=0)
s += "<td>%s</td>" % (p.end_time.replace(microsecond=0) - p.start_time.replace(microsecond=0))
s += "<td>%s</td>" % p.end_time.replace(microsecond=0)
s += "<td><a href='/logs/%s/%s/%s.log'>Log</a></td>" % (p.project, p.spider, p.job)
s += "<td><a href='/logs/UTF-8.html?project=%s&spider=%s&job=%s' target='_blank'>UTF-8</a></td>" % (p.project, p.spider, p.job) ########
if self.local_items:
s += "<td><a href='/items/%s/%s/%s.jl'>Items</a></td>" % (p.project, p.spider, p.job)
s += "</tr>"
s += "</table>"
s += "</body>"
s += "</html>" txrequest.setHeader('Content-Type', 'text/html; charset=utf-8')
txrequest.setHeader('Content-Length', len(s)) return s.encode('utf-8')
3.新建 UTF-8.html 页面
根据 http://scrapyd.readthedocs.io/en/stable/config.html 确定 Scrapyd 所使用的 logs_dir,在该目录下添加如下文件 UTF-8.html
<html>
<head><meta charset="UTF-8"></head>
<iframe src="" width="100%" height="100%"></iframe> <script>
function parseQueryString(url) {
var urlParams = {};
url.replace(
new RegExp("([^?=&]+)(=([^&]*))?", "g"),
function($0, $1, $2, $3) {
urlParams[$1] = $3;
}
);
return urlParams;
} var kwargs = parseQueryString(location.search);
document.querySelector('iframe').src = "/logs/" + kwargs.project + '/' + kwargs.spider + '/' + kwargs.job + '.log'
</script> <html>
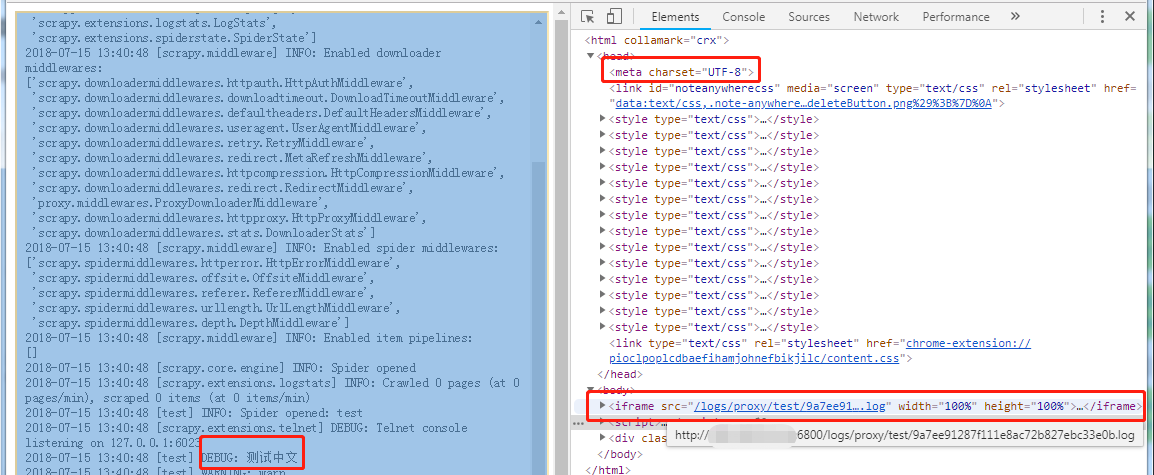
4.实现效果
Scrapyd 改进第一步: Web Interface 添加 charset=UTF-8, 避免查看 log 出现中文乱码的更多相关文章
- Scrapyd 改进第二步: Web Interface 添加 STOP 和 START 超链接, 一键调用 Scrapyd API
0.提出问题 Scrapyd 提供的开始和结束项目的API如下,参考 Scrapyd 改进第一步: Web Interface 添加 charset=UTF-8, 避免查看 log 出现中文乱码,准备 ...
- zabbix客户端的安装、zabbix主被动模式、添加主机模板等、处理页面的中文乱码
1.zabbix客户端的安装: 如下步骤: wget repo.zabbix.com/zabbix/3.2/rhel/7/x86_64/zabbix-release-3.2-1.el7.noarch. ...
- 关于web.xml中配置Spring字符编码过滤器以解决中文乱码的问题
当出现中文乱码问题,Spring中可以利用CharacterEncodingFilter过滤器解决,如下代码所示: <!-- Spring字符编码过滤器:解决中文乱码问题 --> < ...
- form 表单添加 enctype ="multipart/form-data" 属性后后台接收中文乱码
解决办法: new String( request.getParameter("title").getBytes("ISO-8859-1"),"utf ...
- 第一讲 从头开始做一个web qq 机器人,第一步获取smart qq二维码
新手教程: 前言:最近在看了一下很久很久以前做的qq机器人失效了,最近也在换工作目前还在职,时间很挺宽裕的.就决定从新搞一个web qq机器人 PC的协议解析出来有点费时间以后再做. 准备工作: 编译 ...
- 零代码第一步,做个添加数据的服务先。node.js + mysql
node.js + mysql 实现数据添加的功能.万事基于服务! 增删改查之添加数据. 优点:只需要设置一个json文件,就可以实现基本的添加功能,可以视为是零代码. 添加数据的服务实现的功能: 1 ...
- Blazor client-side + webapi (.net core 3.1) 添加jwt验证流程(非host)第一步
第一步,设置并检查CROS跨域请求 因为我们并不打算将Blazor 由webapi来进行host,所以Blazor和api将是两个域名,这样操作即方便以后单独使用Blazor来写前端,但后端采用已有或 ...
- linux系统性能调优第一步——性能分析(vmstat)
linux系统性能调优第一步--性能分析(vmstat) 分类: LINUX 性能调优的第一步是性能分析,下面从性能分析着手进行一些介绍,尤其对linux性能分析工具vmstat的用法和实践进行详细介 ...
- [EntLib]微软企业库5.0 学习之路——第一步、基本入门
话说在大学的时候帮老师做项目的时候就已经接触过企业库了但是当初一直没明白为什么要用这个,只觉得好麻烦啊,竟然有那么多的乱七八糟的配置(原来我不知道有配置工具可以进行配置,请原谅我的小白). 直到去年在 ...
随机推荐
- java并发编程 | 线程详解
个人网站:https://chenmingyu.top/concurrent-thread/ 进程与线程 进程:操作系统在运行一个程序的时候就会为其创建一个进程(比如一个java程序),进程是资源分配 ...
- JS设置Cookie过期时间
//JS操作cookies方法! //写cookies function setCookie(name,value) { var Days = 30; var exp = new Date(); ex ...
- php禁止某ip或ip地址段访问的方法(转载)
<?php include("banIP.php");?> 禁用单个ip如下:<?php //禁用ip地址 $ip=$_SERVER["REMOTE_A ...
- NGINX+PHP配置
NGINX做为WEB服务器,运行PHP开发的程序和页面: server { listen 80; listen 443 ssl; ssl_certificate /usr/local/nginx/co ...
- (五) vivi代码分析
目录 vivi代码分析 初始化注册 使用open/read/ioctl 系统调用分析 ioctl流程一览 总结 title: vivi代码分析 date: 2019/4/23 19:30:00 toc ...
- Mongodb分片集群技术+用户验证
随着数据量持续增多,后续迟早会出现一台机器硬件瓶颈问题的.而mongodb主打的就是海量数据架构,“分片”就用这个来解决这个问题. 从图中可以看到有四个组件:mongos.config server. ...
- Node.js目录
[相关学习] npm入门教程 [基础] (1) 初识Node.js (2) 开发环境和调试工具 (3) commonJs 规范 (4) node 概念(global.process进程.调试) (5) ...
- python接收axios的post请求,并处理后返回数据
公司的python工程师不会js和python数据交互,所以我就去试了一下. 首先安装python,django框架和django-cors-headers. python官网下载,按提示操作,记住最 ...
- Laravel 5.7 使用 PHP artisan migrate 的问题
这是由于Laravel 默认使用 utf8mb4 字符, 包括支持在数据库存储「 表情」 . 如果你正在运行的 MySQL release 版本低于5.7.7 或 MariaDB release版本低 ...
- asp.netMVC4使用Bootstrap4
使用: 添加: <script src="../../Scripts/jquery-1.7.1.min.js" type="text/javascript" ...