Context Encoder论文及代码解读
经过秋招和毕业论文的折磨,提交完论文終稿的那一刻总算觉得有多余的时间来搞自己的事情。
研究论文做的是图像修复相关,这里对基于深度学习的图像修复方面的论文和代码进行整理,也算是研究生方向有一个比较好的结束。好啦,下面开始进入正题~
所有的image inpainting的介绍在这里: 基于深度学习的Image Inpainting(论文+代码)
Context encoders for image generation
1. Encoder-decoder pipeline
网络结构是一个简单的编码器-解码器结构,中间采用Channel-wise fully-connected layer来连接编码器和解码器,网络结构如图。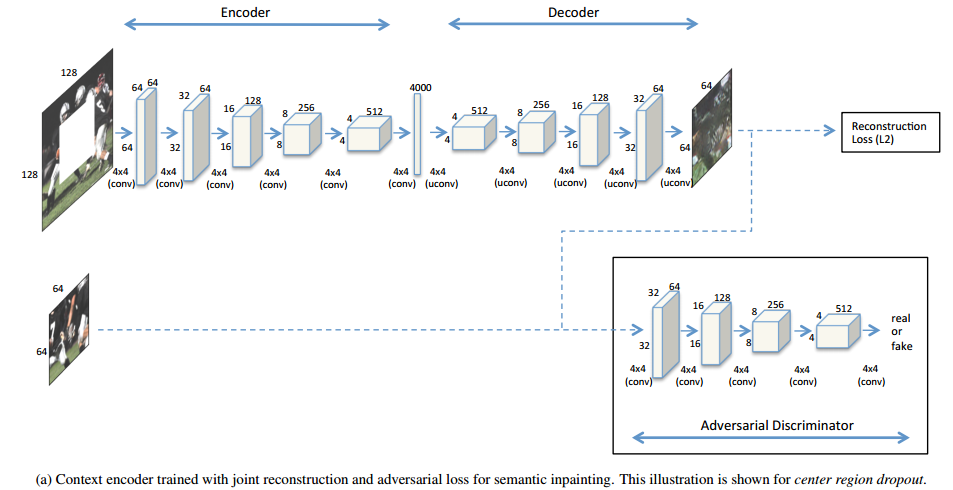
1.1 编码器:采用AlexNet网络作为baseline,五个卷积加上池化pool5,若输入图像为227x227,可以得到一个6x6x256的特征图。
1.2 Channel-wise fully-connected layer:减少网络参数,若使用全连接层,输入特征图为mxnxn,输出也为mxnxn,则需要m2n4的参数,而使用channel-wise仅需要mn4的参数,使用步长为1的卷积来将信息在通道之间传递。
1.3 解码器:就是一系列的五个上卷积的操作,使其恢复到与原图一样的大小。
2. Loss function
包含reconstruction(l2) loss和adversarial loss。
2.1 重建L2 loss主要是捕获缺失区域的整体结构,但是容易在预测输出中平均多种模式;

M作为二值化的掩码,没看懂最外面的M是干啥用。。
2.2 而adv loss则从多种可能的输出模式中选择一种,也可以说是进行特定模式选择,使得预测结果看起来更真实。
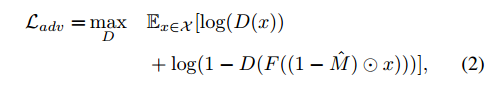
2.3 两种loss结合到一起,既具备结构性,也具备真实语义性。
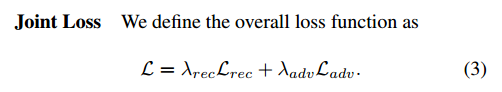
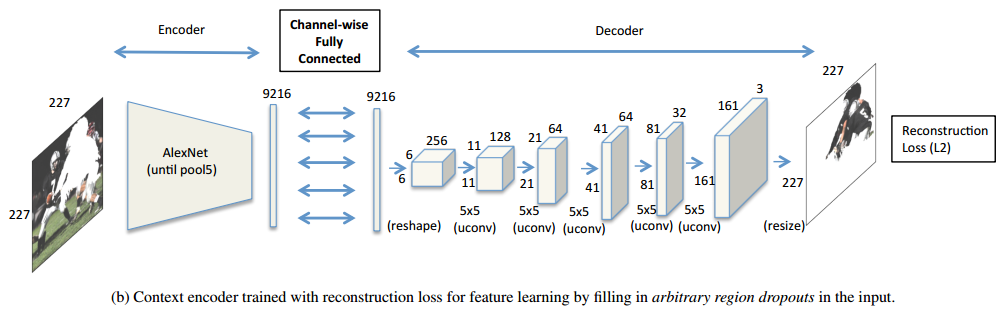
对于任意区域的图像修复网络结构图如下。
我觉得这篇论文的创新点有以下两点:
1. 使用编码-解码器结构来完成图像修复的任务,并改用channel-wise的方式连接,节省了一定的参数。
2. 使用联合损失函数,结合重建l2 loss和对抗式adv loss,使得修复图像更加真实。
代码解读:train.lua
---------------------------------------------------------------------------
-- Adversarial discriminator net
---------------------------------------------------------------------------
local netD = nn.Sequential()
if opt.conditionAdv then
local netD_ctx = nn.Sequential()
-- input Context: (nc) x 128 x 128, going into a convolution
netD_ctx:add(SpatialConvolution(nc, ndf, 5, 5, 2, 2, 2, 2))
-- state size: (ndf) x 64 x 64 local netD_pred = nn.Sequential()
-- input pred: (nc) x 64 x 64, going into a convolution
netD_pred:add(SpatialConvolution(nc, ndf, 5, 5, 2, 2, 2+32, 2+32)) -- 32: to keep scaling of features same as context
-- state size: (ndf) x 64 x 64 local netD_pl = nn.ParallelTable();
netD_pl:add(netD_ctx)
netD_pl:add(netD_pred) netD:add(netD_pl)
netD:add(nn.JoinTable(2))
netD:add(nn.LeakyReLU(0.2, true))
-- state size: (ndf * 2) x 64 x 64 netD:add(SpatialConvolution(ndf*2, ndf, 4, 4, 2, 2, 1, 1))
netD:add(SpatialBatchNormalization(ndf)):add(nn.LeakyReLU(0.2, true))
-- state size: (ndf) x 32 x 32
else
-- input is (nc) x 64 x 64, going into a convolution
netD:add(SpatialConvolution(nc, ndf, 4, 4, 2, 2, 1, 1))
netD:add(nn.LeakyReLU(0.2, true))
-- state size: (ndf) x 32 x 32
end
train.lua中分别得到生成器和判别器的网络结构,然后准备数据,进行训练。这里选择判别器的网络结构代码分析。
网络结构中用到了nn.ParallelTable(),向介绍下torch中nn.Sequential,nn.Concat/ConcatTable,nn.Parallel/PararelTable之间的区别。
那么为什么生成器和判别器都需要用到nn.ParallelTable呢?即对每个成员模块应用与之对应的输入(第i个模块应用第i个输入)
我的理解:生成器需要将输入图像和noise输入到生成器中得到预测的图像;而判别器需要将真实的图像和预测的图像输入到判别器中。
Context Encoder论文及代码解读的更多相关文章
- sort论文和代码解读
流程:1.detections和trackers用匈牙利算法进行匹配 2.把匹配中iou < 0.3的过滤成没匹配上的(1.2步共同返回匹配上的,没匹配上的trackers,没匹配上的detec ...
- CVPR2018: Generative Image Inpainting with Contextual Attention 论文翻译、解读
注:博主是大四学生,翻译水平可能比不上研究人员的水平,博主会尽自己的力量为大家翻译这篇论文.翻译结果仅供参考,提供思路,翻译不足的地方博主会标注出来,请大家参照原文,请大家多多关照. 转载请务必注明出 ...
- Android MVP模式 谷歌官方代码解读
Google官方MVP Sample代码解读 关于Android程序的构架, 当前(2016.10)最流行的模式即为MVP模式, Google官方提供了Sample代码来展示这种模式的用法. Repo ...
- [ZZ]计算机视觉、机器学习相关领域论文和源代码大集合
原文地址:[ZZ]计算机视觉.机器学习相关领域论文和源代码大集合作者:计算机视觉与模式 注:下面有project网站的大部分都有paper和相应的code.Code一般是C/C++或者Matlab代码 ...
- weex官方demo weex-hackernews代码解读(上)
一.介绍 weex 是阿里出品的一个类似RN的框架,可以使用前端技术来开发移动应用,实现一份代码支持H5,IOS和Android.最新版本的weex已默认将vue.js作为前端框架,而weex-hac ...
- 代码解读 | VINS 视觉前端
本文作者是计算机视觉life公众号成员蔡量力,由于格式问题部分内容显示可能有问题,更好的阅读体验,请查看原文链接:代码解读 | VINS 视觉前端 vins前端概述 在搞清楚VINS前端之前,首先要搞 ...
- 《T-GCN: A Temporal Graph Convolutional Network for Traffic Prediction》 代码解读
论文链接:https://arxiv.org/abs/1811.05320 博客原作者Missouter,博客链接https://www.cnblogs.com/missouter/,欢迎交流. 解读 ...
- 优秀开源代码解读之JS与iOS Native Code互调的优雅实现方案
简介 本篇为大家介绍一个优秀的开源小项目:WebViewJavascriptBridge. 它优雅地实现了在使用UIWebView时JS与ios 的ObjC nativecode之间的互调,支持消息发 ...
- SoftmaxLayer and SoftmaxwithLossLayer 代码解读
SoftmaxLayer and SoftmaxwithLossLayer 代码解读 Wang Xiao 先来看看 SoftmaxWithLoss 在prototext文件中的定义: layer { ...
随机推荐
- bug日记之---------js中调用另一个js中的有ajax的方法, 返回值为undefind
今天做一个OCR授权的需求, 需要开发一个OCR弹框, 让用户选择是否授权给第三方识别公司(旷世科技)保存和识别用户个人信息, 照片等. 其中用到了在一个js的方法中调用另外一个js的方法, 其中有一 ...
- 用R语言做数据清理
数据的清理 如同列夫托尔斯泰所说的那样:“幸福的家庭都是相似的,不幸的家庭各有各的不幸”,糟糕的恶心的数据各有各的糟糕之处,好的数据集都是相似的.一份好的,干净而整洁的数据至少包括以下几个要素: 1. ...
- error CS1002: ; expected 错误解决
一般出现这种错误,大概原因是因为前端页面里的C#代码少个分号,或少个括号 导致编译器出错:仔细检查页面中的C#代码是否写的正确. 我之所以出现这个错误是因为前台页面中:@{ } 这里的代码少一个括号 ...
- 用 jupyter notebook 打开 oui.txt 文件出现的问题及解决方案
问题背景:下载了2018 IEEE 最新的 oui.txt 文件.里面包含了 设备 MAC 地址的前六位对应的厂商.要做的工作是,将海量设备的 MAC 地址与 oui.txt 文件的信息比对,统计出 ...
- Day 5内存管理,定义变量
昨日内容回顾 python的2种执行方式 交互式 写一句翻译一句 优点:能及时发现bug,及时调试 缺点:关即消失,不能保存 命令行式 优点:可以永久保存 缺点:无法及时看到结果 python3 c: ...
- 2 Class类
在程序运行期间,Java运行时系统始终为所有的对象维护一个被称为运行时地类型标识.这个信息跟踪着每个对象所属地类.虚拟机 利用运行时类型信息选择相应地方法执行. 然而,可以通过专门地Java类访问这 ...
- 空list赋值
list=[] i =0 list[i] =1 Traceback (most recent call last): File "D:\ProgramData\Anaconda3\lib\s ...
- WDA基础十五:POPUP WINDOW
1.组件控制器定义属性: 2.实现popup方法: METHOD stock_popup . DATA: l_cmp_api TYPE REF TO if_wd_component, l_window ...
- 【PAT】反转链表
PAT 乙级 1025 给定一个常数 K 以及一个单链表 L,请编写程序将 L 中每 K 个结点反转.例如:给定 L 为 1 → 2 → 3 → 4 → 5 → 6,K 为 3,则输出应该为 3 → ...
- 【OS】Process & Thread
Process Thread 定义 资源(CPU.内存等)分配的最小单元,是程序执行时的一个实例.程序运行时系统就会创建一个进程,并为它分配资源,然后把该进程放入进程就绪队列,进程调度器选中它的时 ...