Guava 源码分析(Cache 原理)

前言
Google 出的 Guava 是 Java 核心增强的库,应用非常广泛。
我平时用的也挺频繁,这次就借助日常使用的 Cache 组件来看看 Google 大牛们是如何设计的。
缓存
本次主要讨论缓存。
缓存在日常开发中举足轻重,如果你的应用对某类数据有着较高的读取频次,并且改动较小时那就非常适合利用缓存来提高性能。
缓存之所以可以提高性能是因为它的读取效率很高,就像是 CPU 的 L1、L2、L3 缓存一样,级别越高相应的读取速度也会越快。
但也不是什么好处都占,读取速度快了但是它的内存更小资源更宝贵,所以我们应当缓存真正需要的数据。
其实也就是典型的空间换时间。
下面谈谈 Java 中所用到的缓存。
JVM 缓存
首先是 JVM 缓存,也可以认为是堆缓存。
其实就是创建一些全局变量,如 Map、List 之类的容器用于存放数据。
这样的优势是使用简单但是也有以下问题:
- 只能显式的写入,清除数据。
- 不能按照一定的规则淘汰数据,如
LRU,LFU,FIFO等。 - 清除数据时的回调通知。
- 其他一些定制功能等。
Ehcache、Guava Cache
所以出现了一些专门用作 JVM 缓存的开源工具出现了,如本文提到的 Guava Cache。
它具有上文 JVM 缓存不具有的功能,如自动清除数据、多种清除算法、清除回调等。
但也正因为有了这些功能,这样的缓存必然会多出许多东西需要额外维护,自然也就增加了系统的消耗。
分布式缓存
刚才提到的两种缓存其实都是堆内缓存,只能在单个节点中使用,这样在分布式场景下就招架不住了。
于是也有了一些缓存中间件,如 Redis、Memcached,在分布式环境下可以共享内存。
具体不在本次的讨论范围。
Guava Cache 示例
之所以想到 Guava 的 Cache,也是最近在做一个需求,大体如下:
从 Kafka 实时读取出应用系统的日志信息,该日志信息包含了应用的健康状况。
如果在时间窗口 N 内发生了 X 次异常信息,相应的我就需要作出反馈(报警、记录日志等)。
对此 Guava 的 Cache 就非常适合,我利用了它的 N 个时间内不写入数据时缓存就清空的特点,在每次读取数据时判断异常信息是否大于 X 即可。
伪代码如下:
@Value("${alert.in.time:2}")
private int time ;
@Bean
public LoadingCache buildCache(){
return CacheBuilder.newBuilder()
.expireAfterWrite(time, TimeUnit.MINUTES)
.build(new CacheLoader<Long, AtomicLong>() {
@Override
public AtomicLong load(Long key) throws Exception {
return new AtomicLong(0);
}
});
}
/**
* 判断是否需要报警
*/
public void checkAlert() {
try {
if (counter.get(KEY).incrementAndGet() >= limit) {
LOGGER.info("***********报警***********");
//将缓存清空
counter.get(KEY).getAndSet(0L);
}
} catch (ExecutionException e) {
LOGGER.error("Exception", e);
}
}
首先是构建了 LoadingCache 对象,在 N 分钟内不写入数据时就回收缓存(当通过 Key 获取不到缓存时,默认返回 0)。
然后在每次消费时候调用 checkAlert() 方法进行校验,这样就可以达到上文的需求。
我们来设想下 Guava 它是如何实现过期自动清除数据,并且是可以按照 LRU 这样的方式清除的。
大胆假设下:
内部通过一个队列来维护缓存的顺序,每次访问过的数据移动到队列头部,并且额外开启一个线程来判断数据是否过期,过期就删掉。有点类似于我之前写过的 动手实现一个 LRU cache
胡适说过:大胆假设小心论证
下面来看看 Guava 到底是怎么实现。
原理分析
看原理最好不过是跟代码一步步走了:
示例代码在这里:
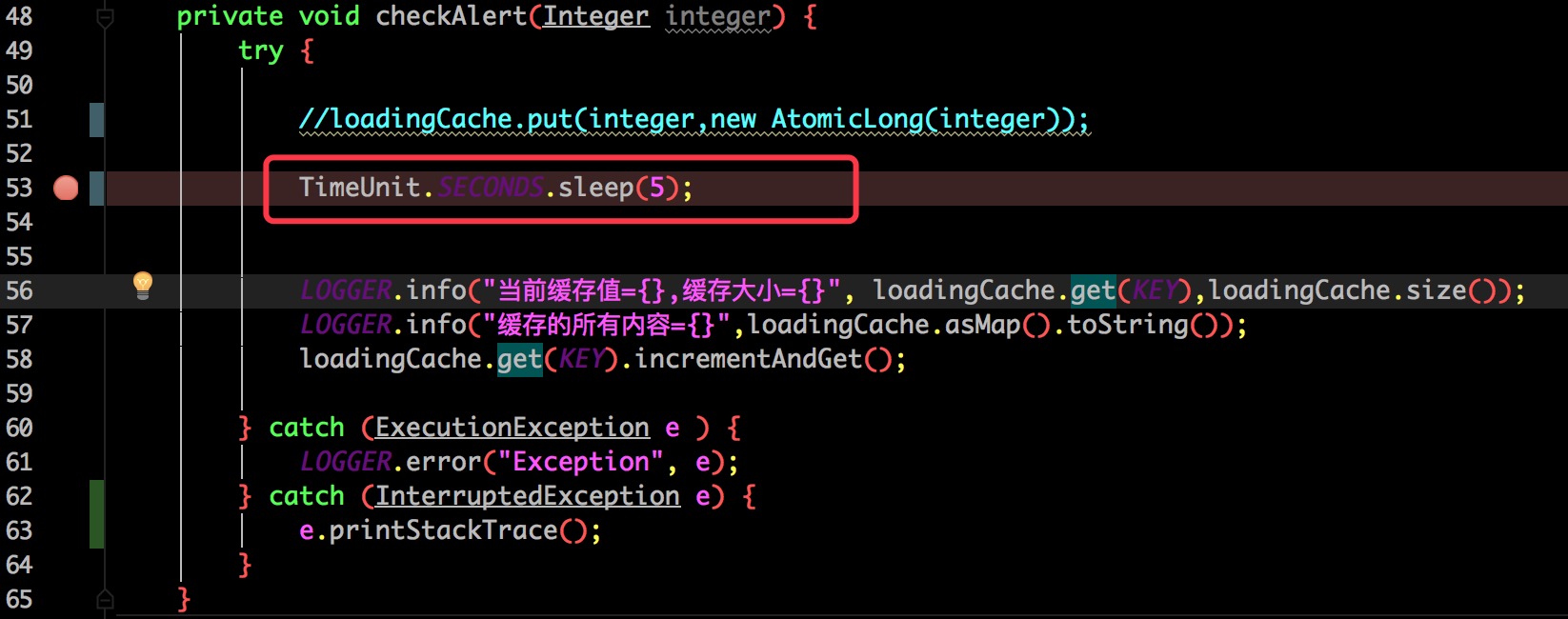
为了能看出 Guava 是怎么删除过期数据的在获取缓存之前休眠了 5 秒钟,达到了超时条件。
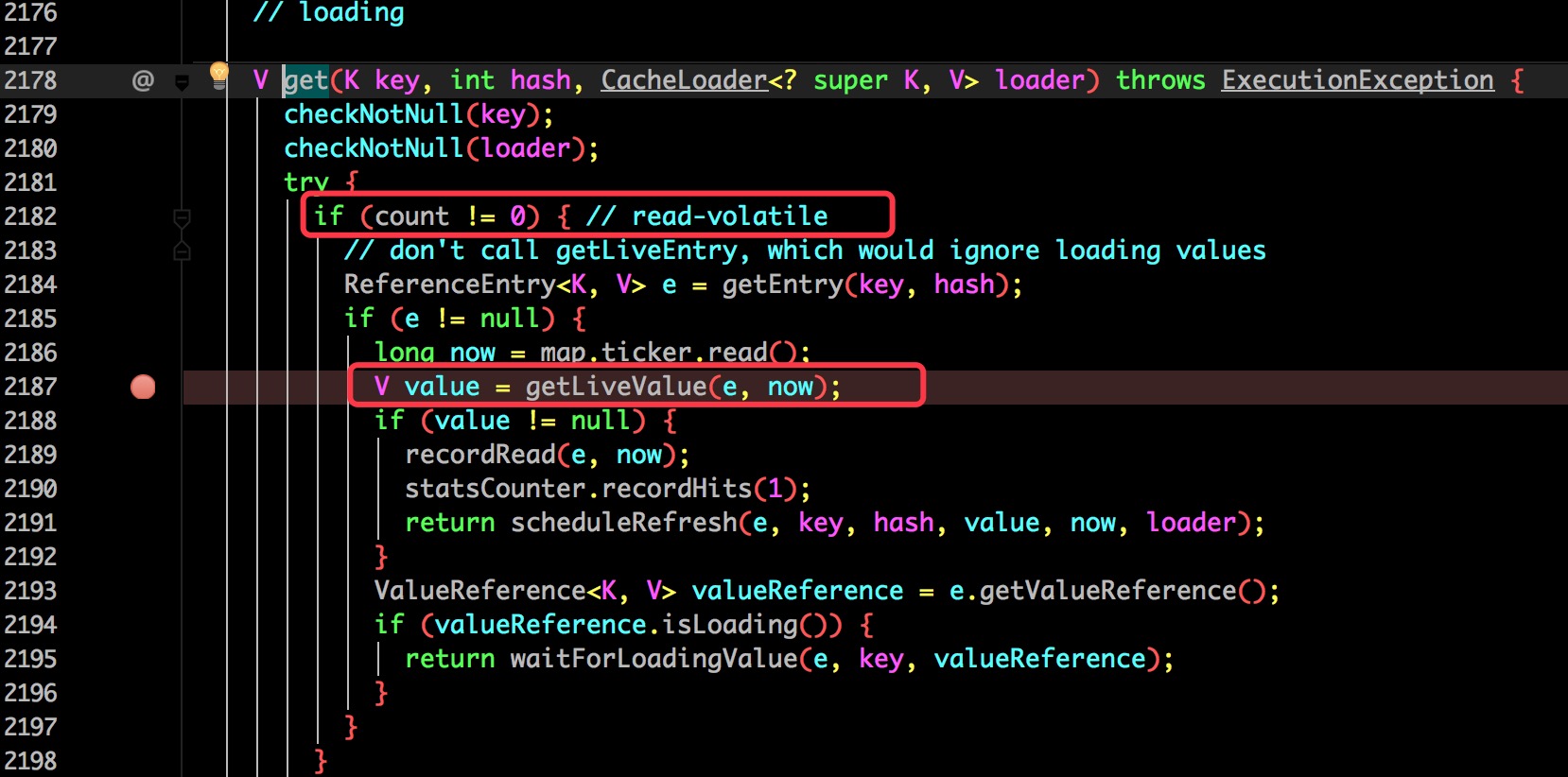
最终会发现在 com.google.common.cache.LocalCache 类的 2187 行比较关键。
再跟进去之前第 2182 行会发现先要判断 count 是否大于 0,这个 count 保存的是当前缓存的数量,并用 volatile 修饰保证了可见性。
更多关于 volatile 的相关信息可以查看 你应该知道的 volatile 关键字
接着往下跟到:
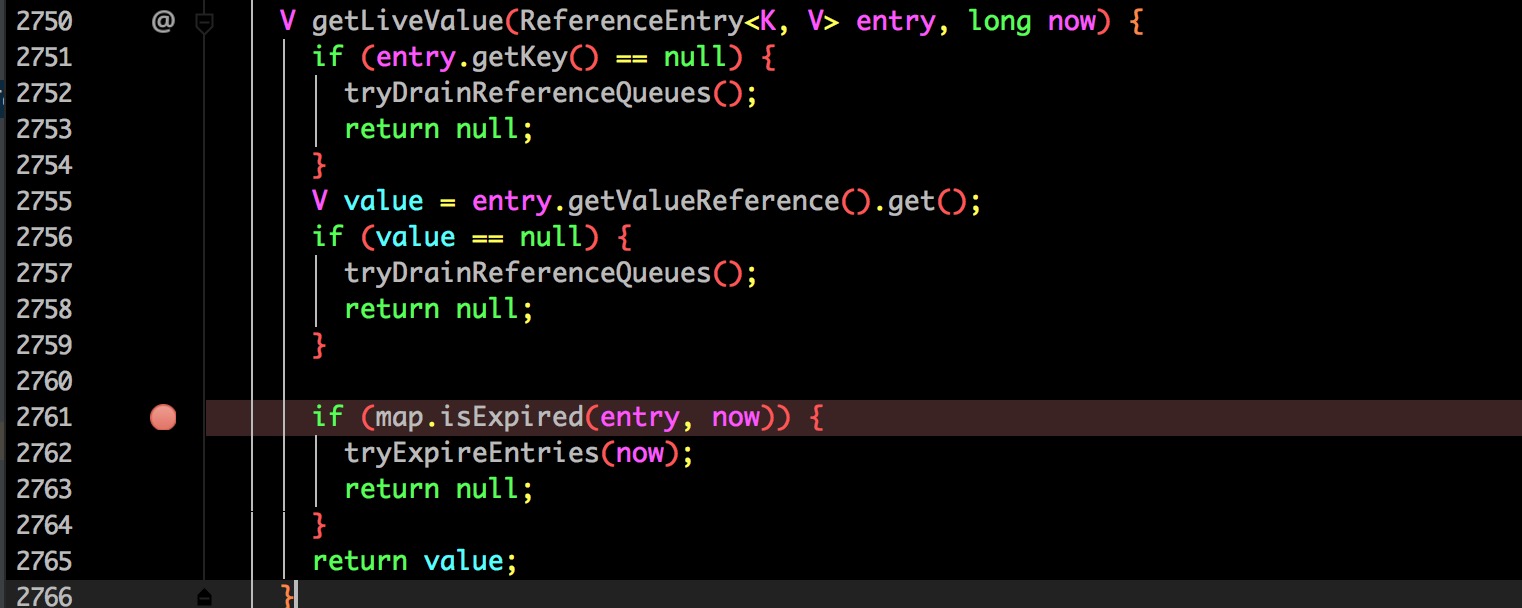
2761 行,根据方法名称可以看出是判断当前的 Entry 是否过期,该 entry 就是通过 key 查询到的。

这里就很明显的看出是根据根据构建时指定的过期方式来判断当前 key 是否过期了。
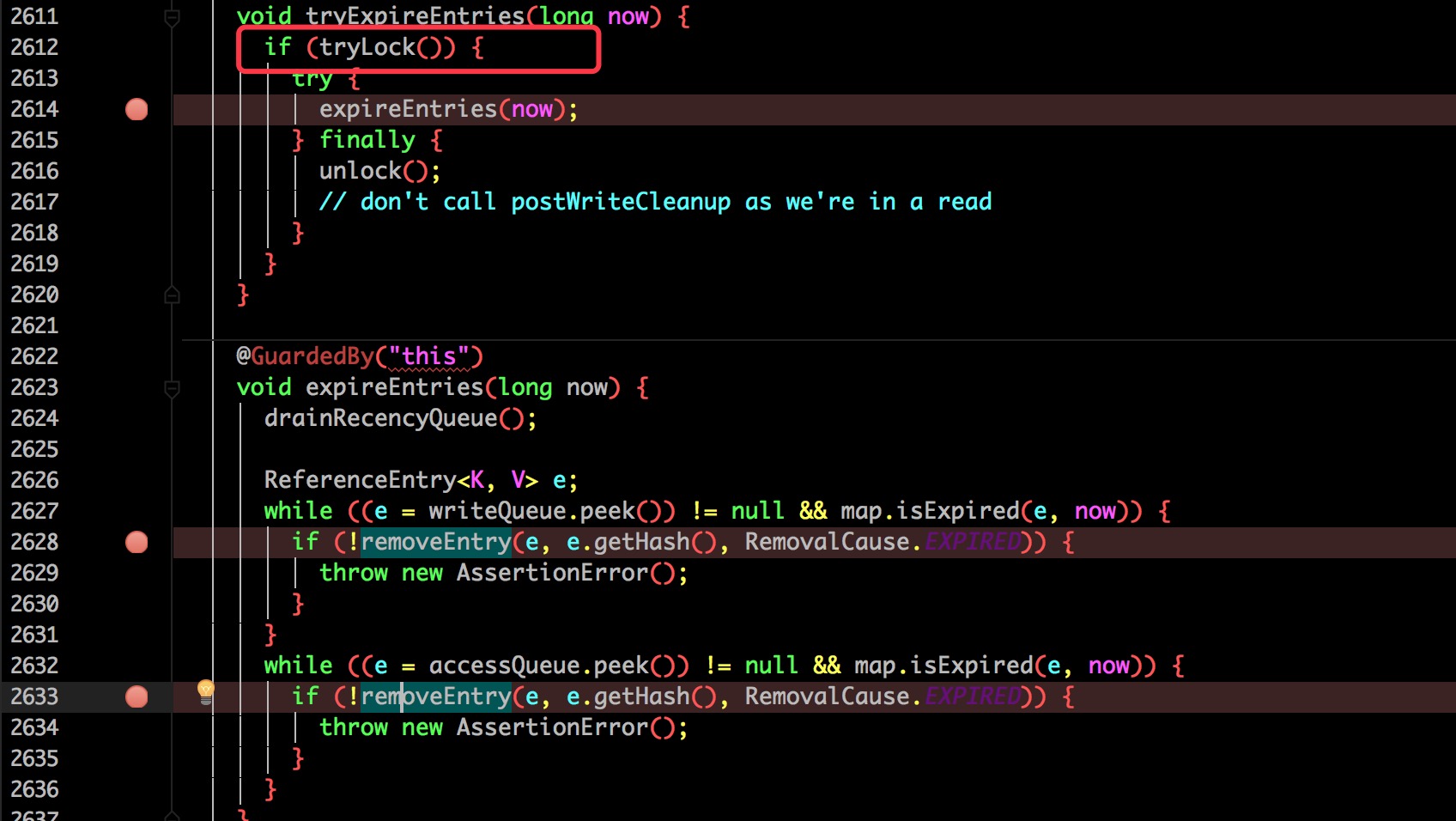
如果过期就往下走,尝试进行过期删除(需要加锁,后面会具体讨论)。
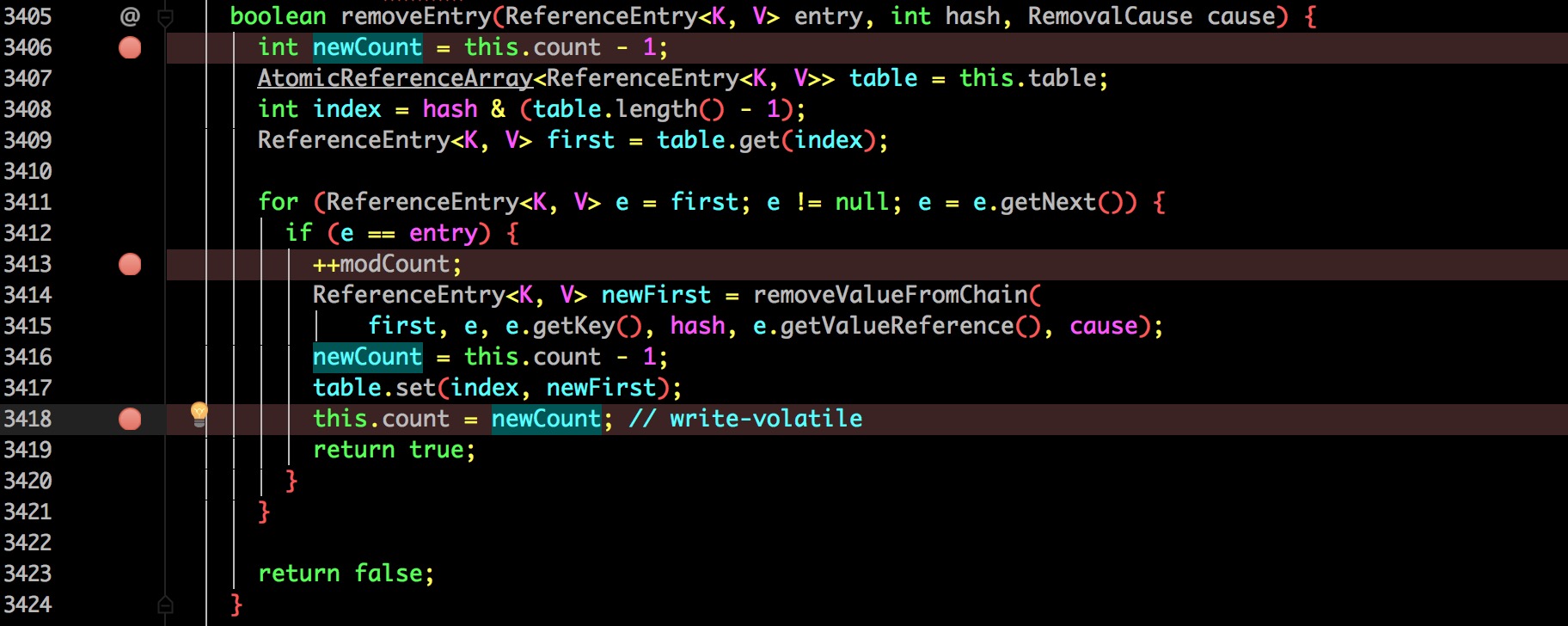
到了这里也很清晰了:
- 获取当前缓存的总数量
- 自减一(前面获取了锁,所以线程安全)
- 删除并将更新的总数赋值到 count。
其实大体上就是这个流程,Guava 并没有按照之前猜想的另起一个线程来维护过期数据。
应该是以下原因:
- 新起线程需要资源消耗。
- 维护过期数据还要获取额外的锁,增加了消耗。
而在查询时候顺带做了这些事情,但是如果该缓存迟迟没有访问也会存在数据不能被回收的情况,不过这对于一个高吞吐的应用来说也不是问题。
总结
最后再来总结下 Guava 的 Cache。
其实在上文跟代码时会发现通过一个 key 定位数据时有以下代码:

如果有看过 ConcurrentHashMap 的原理 应该会想到这其实非常类似。
其实 Guava Cache 为了满足并发场景的使用,核心的数据结构就是按照 ConcurrentHashMap 来的,这里也是一个 key 定位到一个具体位置的过程。
先找到 Segment,再找具体的位置,等于是做了两次 Hash 定位。
上文有一个假设是对的,它内部会维护两个队列 accessQueue,writeQueue 用于记录缓存顺序,这样才可以按照顺序淘汰数据(类似于利用 LinkedHashMap 来做 LRU 缓存)。
同时从上文的构建方式来看,它也是构建者模式来创建对象的。
因为作为一个给开发者使用的工具,需要有很多的自定义属性,利用构建则模式再合适不过了。
Guava 其实还有很多东西没谈到,比如它利用 GC 来回收内存,移除数据时的回调通知等。之后再接着讨论。
最后插播个小广告:
Java-Interview 截止目前将近 8K star。

这次定个小目标:争取冲击 1W star。
感谢各位老铁的支持与点赞。
欢迎关注公众号一起交流:
Guava 源码分析(Cache 原理)的更多相关文章
- Guava 源码分析(Cache 原理 对象引用、事件回调)
前言 在上文「Guava 源码分析(Cache 原理)」中分析了 Guava Cache 的相关原理. 文末提到了回收机制.移除时间通知等内容,许多朋友也挺感兴趣,这次就这两个内容再来分析分析. 在开 ...
- Guava 源码分析之Cache的实现原理
Guava 源码分析之Cache的实现原理 前言 Google 出的 Guava 是 Java 核心增强的库,应用非常广泛. 我平时用的也挺频繁,这次就借助日常使用的 Cache 组件来看看 Goog ...
- MyBatis 源码分析 - 缓存原理
1.简介 在 Web 应用中,缓存是必不可少的组件.通常我们都会用 Redis 或 memcached 等缓存中间件,拦截大量奔向数据库的请求,减轻数据库压力.作为一个重要的组件,MyBatis 自然 ...
- Spring Boot 揭秘与实战 源码分析 - 工作原理剖析
文章目录 1. EnableAutoConfiguration 帮助我们做了什么 2. 配置参数类 – FreeMarkerProperties 3. 自动配置类 – FreeMarkerAutoCo ...
- Tomcat源码分析——请求原理分析(下)
前言 本文继续讲解TOMCAT的请求原理分析,建议朋友们阅读本文时首先阅读过<TOMCAT源码分析——请求原理分析(上)>和<TOMCAT源码分析——请求原理分析(中)>.在& ...
- Tomcat源码分析——请求原理分析(中)
前言 在<TOMCAT源码分析——请求原理分析(上)>一文中已经介绍了关于Tomcat7.0处理请求前作的初始化和准备工作,请读者在阅读本文前确保掌握<TOMCAT源码分析——请求原 ...
- Tomcat源码分析——请求原理分析(上)
前言 谈起Tomcat的诞生,最早可以追溯到1995年.近20年来,Tomcat始终是使用最广泛的Web服务器,由于其使用Java语言开发,所以广为Java程序员所熟悉.很多人早期的J2EE项目,由程 ...
- wifidog源码分析 - wifidog原理 tiger
转:http://www.cnblogs.com/tolimit/p/4223644.html wifidog源码分析 - wifidog原理 wifidog是一个用于配合认证服务器实现无线网页认证功 ...
- [Guava源码分析]ImmutableCollection:不可变集合
摘要: 我的技术博客经常被流氓网站恶意爬取转载.请移步原文:http://www.cnblogs.com/hamhog/p/3888557.html,享受整齐的排版.有效的链接.正确的代码缩进.更好的 ...
- [Guava源码分析]Ordering:排序
我的技术博客经常被流氓网站恶意爬取转载.请移步原文:http://www.cnblogs.com/hamhog/p/3876466.html,享受整齐的排版.有效的链接.正确的代码缩进.更好的阅读体验 ...
随机推荐
- Mysql和mongo安装配置
mysql配置 1.下载镜像 docker pull mysql/mysql-server 2.运行容器 docker run -d -p 3306:3306 --name [Name] [Image ...
- 部署Mvc Core SSL网站到Centos并用Nginx作为反向代理
1. 先在本地比如~/Downloads下建立MVC项目 2. 生成mvc使用的ssl证书 2.1. 生成.key文件 openssl genrsa -des3 -out server.key 2 ...
- String.length()和String.getBytes().length
1.字符与字节 抛出如下代码: public static void main(String[] args) { String str = "活出自己范儿"; System.out ...
- 【C语言编程练习】5.7填数字游戏求解
之前的东西就不上传了,大致就跟现在的一样 1. 题目要求 计算 ABCD * E DCBA 这个算式中每个字母代表什么数字? 2. 题目分析 如果是我们人去做这道题会怎么办,一定是这样想把,一个四位 ...
- BZOJ.2054.疯狂的馒头(并查集)
BZOJ 倒序处理,就是并查集傻题了.. 并查集就是确定下一个未染色位置的,直接跳到那个位置染.然而我越想越麻烦=-= 以为有线性的做法,发现还是要并查集.. 数据随机线段树也能过去. //18400 ...
- mysql数据库 ,java 代码巧妙结合提升系统性能。
查询频繁的表t_yh_transport_task 保证数据量最少,增加查询效率, 常用于查询的字段增加索引, 每日定时移动数据 <!-- 医院系统预约任务历史删除定时器 --> & ...
- C++ 三大特性:封装、继承、多态性
要讲 封装.继承.多态就必须从面向对象说起 开发一个软件是为了解决某些问题,这些问题所涉及的业务范围称为该软件的问题域.面向对象的编程语言将客观事物看作具有属性和行为(或服务)的对象,通过抽象找出同 ...
- [POJ2823]Sliding Window 滑动窗口(单调队列)
题意 刚学单调队列的时候做过 现在重新做一次 一个很经典的题目 现在有一堆数字共N个数字(N<=10^6),以及一个大小为k的窗口.现在这个从左边开始向右滑动,每次滑动一个单位,求出每次滑动后窗 ...
- Tensor类型
Tensor类型 1.Tensor有不同的数据类型,每种类型又有CPU和GPU两种版本: 2.默认的tensor类型是FloatTensor,t.set_default_tensor_type可以修改 ...
- CSS-单位em 和 rem
1,em单位(css3新增单位) em:就是一种长度单位,它是参照当前元素的字号,如果没有设置,就参照父容器,一直到浏览器的默认字号大小 em 是相对长度单位(参照父元素),其参照当前元素字号大小,如 ...