【Storm篇】--Storm中的同步服务DRPC
一、前述
Drpc(分布式远程过程调用)是一种同步服务实现的机制,在Storm中客户端提交数据请求之后,立刻取得计算结果并返回给客户端。同时充分利用Storm的计算能力实现高密度的并行实时计算。
二、具体原理
DRPC 是通过一个 DRPC 服务端(DRPC server)来实现分布式 RPC 功能的。
DRPC Server 负责接收 RPC 请求,并将该请求发送到 Storm中运行的 Topology,等待接收 Topology 发送的处理结果,并将该结果返回给发送请求的客户端。
(其实,从客户端的角度来说,DPRC 与普通的 RPC 调用并没有什么区别。)
DRPC设计目的是为了充分利用Storm的计算能力实现高密度的并行实时计算。
(Storm接收若干个数据流输入,数据在Topology当中运行完成,然后通过DRPC将结果进行输出。)
流程图如下: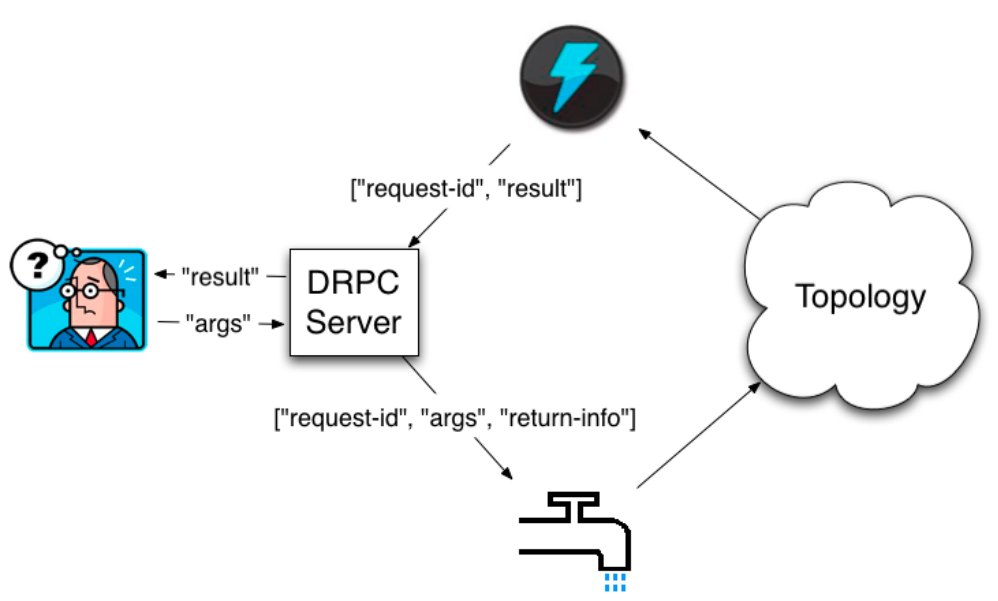
解释:
客户端通过向 DRPC 服务器发送待执行函数的名称以及该函数的参数来获取处理结果。实现该函数的拓扑使用一个DRPCSpout 从 DRPC 服务器中接收一个函数调用流。DRPC 服务器会为每个函数调用都标记了一个唯一的 id。随后拓扑会执行函数来计算结果,并在拓扑的最后使JoinResult的Bolt实现数据的聚合, ReturnResults 的 bolt 连接到 DRPC 服务器,根据函数调用的 id 来将函数调用的结果返回。
三、实现方式
方法1.
通过LinearDRPCTopologyBuilder (该方法也过期,不建议使用)
该方法会自动为我们设定Spout、将结果返回给DRPC Server等,我们只需要将Topology实现
package com.sxt.storm.drpc; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.StormSubmitter;
import backtype.storm.drpc.LinearDRPCTopologyBuilder;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; public class BasicDRPCTopology {
public static class ExclaimBolt extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String input = tuple.getString(1);
collector.emit(new Values(tuple.getValue(0), input + "!"));
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "result"));
} } public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("exclamation");//通过LinearDRPCTopologyBuilder 定义拓扑 //exclamation是函数名称
builder.addBolt(new ExclaimBolt(), 3); Config conf = new Config(); if (args == null || args.length == 0) {
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster(); cluster.submitTopology("drpc-demo", conf, builder.createLocalTopology(drpc));//这是拓扑名称 for (String word : new String[] { "hello", "goodbye" }) {
System.err.println("Result for \"" + word + "\": " + drpc.execute("exclamation", word));
} cluster.shutdown();
drpc.shutdown();
} else {
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createRemoteTopology());
}
}
}
方法2:
直接通过普通的拓扑构造方法TopologyBuilder来创建DRPC拓扑
需要手动设定好开始的DRPCSpout以及结束的ReturnResults
package com.sxt.storm.drpc; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.drpc.DRPCSpout;
import backtype.storm.drpc.ReturnResults;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; public class ManualDRPC {
public static class ExclamationBolt extends BaseBasicBolt { @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("result", "return-info"));
} @Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String arg = tuple.getString(0);
Object retInfo = tuple.getValue(1);
collector.emit(new Values(arg + "!!!", retInfo));
} } public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
LocalDRPC drpc = new LocalDRPC(); DRPCSpout spout = new DRPCSpout("exclamation", drpc);//自定义drpc spout
builder.setSpout("drpc", spout);
builder.setBolt("exclaim", new ExclamationBolt(), 3).shuffleGrouping("drpc");
builder.setBolt("return", new ReturnResults(), 3).shuffleGrouping("exclaim");//自定义结束的ReturnResults
LocalCluster cluster = new LocalCluster();
Config conf = new Config();
cluster.submitTopology("exclaim", conf, builder.createTopology()); System.err.println(drpc.execute("exclamation", "aaa"));
System.err.println(drpc.execute("exclamation", "bbb")); }
}
四、Storm运行模式
1、本地模式
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
LocalDRPC drpc = new LocalDRPC();
DRPCSpout spout = new DRPCSpout("exclamation", drpc);
builder.setSpout("drpc", spout);
builder.setBolt("exclaim", new ExclamationBolt(), 3).shuffleGrouping("drpc");
builder.setBolt("return", new ReturnResults(), 3).shuffleGrouping("exclaim");
LocalCluster cluster = new LocalCluster();
Config conf = new Config();
cluster.submitTopology("exclaim", conf, builder.createTopology());
System.err.println(drpc.execute("exclamation", "aaa"));
System.err.println(drpc.execute("exclamation", "bbb"));
}
2.远程模式(集群模式)
修改配置文件conf/storm.yaml
drpc.servers:
- "node1“
启动DRPC Server
bin/storm drpc &
通过StormSubmitter.submitTopology提交拓扑
public static void main(String[] args) {
DRPCClient client = new DRPCClient("node1", 3772);//通信端口
try {
String result = client.execute("exclamation", "11,22");
System.out.println(result);
} catch (TException e) {
e.printStackTrace();
} catch (DRPCExecutionException e) {
e.printStackTrace();
}
总结:Drpc分布式远程调用帮我们
1、 实现了drpcSpout用来向后发送数据,我们只需要传参即可。
2、 实现了最后的JoinResult用来汇合结果,ReturnResult用来将结果返回客户端。从而达到实时的目的。
3.、我们可以修改并行度,使集群的并行计算能力达到最优,主要实现并行计算。
【Storm篇】--Storm中的同步服务DRPC的更多相关文章
- Storm流计算之项目篇(Storm+Kafka+HBase+Highcharts+JQuery,含3个完整实际项目)
1.1.课程的背景 Storm是什么? 为什么学习Storm? Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop. 随着越来越多的场景对Hadoop的MapRed ...
- 亿级流量场景下,大型架构设计实现【2】---storm篇
承接之前的博:亿级流量场景下,大型缓存架构设计实现 续写本博客: ****************** start: 接下来,我们是要讲解商品详情页缓存架构,缓存预热和解决方案,缓存预热可能导致整个系 ...
- 【Storm篇】--Storm从初始到分布式搭建
一.前述 Storm是一个流式处理框架,相比较于SparkStreaming是一个微批处理框架,hadoop是一个批处理框架. 二 .搭建流程 1.集群规划 Nimbus Supervisor ...
- 《ArcGIS Runtime SDK for Android开发笔记》——数据制作篇:发布具有同步能力的FeatureService服务
1.前言 从ArcGIS 10.2.1开始推出离在线一体化技术之后,数据的离在线一体化编辑一直是大家所关注的一个热点.数据存储在企业级地理数据库中,通过ArcGIS桌面软件加载后配图处理,并发布到Ar ...
- 基于Storm的工程中使用log4j
最近使用Storm开发,发现log4j死活打不出debug级别的日志,网上搜到的关于log4j配置的方法都试过了,均无效. 最终发现问题是这样的:最新的storm使用的日志系统已经从log4j切换到了 ...
- storm - 使用过程中的一点思考
引子 这几天为了优化原有的数据处理框架,比较系统的学习了storm的一些内容,整理一下心得 1. storm提供的是一种数据处理思想,它不提供具体的解决方案 storm的核心是topo的定义,而top ...
- 【Storm篇】--Storm并发机制
一.前述 为了提高Storm的并行能力,通常需要设置并行. 二.具体原理 1. Storm并行分为几个方面: Worker – 进程一个Topology拓扑会包含一个或多个Worker(每个Worke ...
- 第五篇:CUDA 并行程序中的同步
前言 在并发,多线程环境下,同步是一个很重要的环节.同步即是指进程/线程之间的执行顺序约定. 本文将介绍如何通过共享内存机制实现块内多线程之间的同步. 至于块之间的同步,需要使用到 global me ...
- 分布式流式处理框架:storm简介 + Storm术语解释
简介: Storm是一个免费开源.分布式.高容错的实时计算系统.它与其他大数据解决方案的不同之处在于它的处理方式.Hadoop 在本质上是一个批处理系统,数据被引入 Hadoop 文件系统 (HDFS ...
随机推荐
- IE8 disable 兼容行问题
在chrome 下 如果样式设置为disabled 则不能点击, 但是在IE9 或者IE8 则还是可以点击
- kafka写入hdfs
碰到的问题 (1)线程操作问题,因为单机节点,代码加锁就好了,后续再写 (2) 消费者写hdfs的时候以流的形式写入,但是什么时候关闭流就是一个大问题了,这里引入了 fsDataOutputStr ...
- Gradle 下载的依赖包在什么位置?
Mac系统默认下载到:/Users/(用户名)/.gradle/caches/modules-2/files-2.1Windows系统默认下载到:C:\Users\(用户名)\.gradle\cach ...
- BFS —— 信息学一本通(1451:棋盘游戏)
题目描述 在一个4*4的棋盘上有8个黑棋和8个白棋,当且仅当两个格子有公共边,这两个格子上的棋是相邻的.移动棋子的规则是交换相邻两个棋子.现在给出一个初始棋盘和一个最终棋盘,要求你找出一个最短的移动序 ...
- 数据分析——pandas
简介 import pandas as pd # 在数据挖掘前一个数据分析.筛选.清理的多功能工具 ''' pandas 可以读入excel.csv等文件:可以创建Series序列,DataFrame ...
- VS2017下使用Git遇到的问题
我在使用最新版的VS2017时,想获取服务器上最新代码,Fetch到了最新修改,但是在拉取代码的时候出现了问题 user@user-PC MINGW64 /d/demo/myrepos (dev-cs ...
- 关于Python2 与 Python3 的区别
Python是一门动态解释性的强类型定义语言. 1.Python2 : ①.臃肿,源代码的重复量很多. ②.语法不清晰,掺杂着C,php,Java的一些陋习. Python3 : 几乎是重构后的源 ...
- Android四大组件的简介
Android开发四大组件分别是: 一.活动(Activity): 用于表现功能.二.服务(Service): 后台运行服务,不提供界面呈现. 三.广播接收器(BroadcastReceiver):用 ...
- IOS开发中关于runtime的认识
首先要知道我们写的代码在程序运行过程中都会被转化成runtime的C代码执行. runtime突出的一点就是OC中消息传递机制的应用.objc_msgsend(target,SEL); 首先我们先看一 ...
- mysql import error
mysql导入文件一直出错,显示ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option s ...