机器学习实战(笔记)------------KNN算法
1.KNN算法
KNN算法即K-临近算法,采用测量不同特征值之间的距离的方法进行分类。
以二维情况举例:
假设一条样本含有两个特征。将这两种特征进行数值化,我们就可以假设这两种特种分别为二维坐标系中的横轴和纵轴,将一个样本以点的形式表示在坐标系中。这样,两个样本直接变产生了空间距离,假设两点之间越接近越可能属于同一类的样本。如果我们有一个待分类数据,我们计算该点与样本库中的所有点的距离,取前K个距离最近的点,以这K个中出现次数最多的分类作为待分类样本的分类。这样就是KNN算法。
优点:精度高,对异常值不敏感,无数据输入假定
缺点:时间、空间复杂度太大(比如每一次分类都需要计算所有样本点与测试点的距离)
2.KNN算法的Python实现
import operator
from os import listdir
import matplotlib
import matplotlib.pyplot as plt
from numpy import array, shape, tile, zeros
#分类方法
#inx 待分类向量
#dataSet 测试数据
#labels 测试数据标签
#k 取前k个作为样本
def classify(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
diffMat=tile(inX,(dataSetSize,1))-dataSet #tile方法利用输入数组进行扩充
sqDiffMat=diffMat**2
sqDistance=sqDiffMat.sum(axis=1)
distance=sqDistance**0.5
index=distance.argsort() #返回按从小到大的顺序排序后的元素下标
classCount={}
for i in range(k):
lable=labels[index[i]]
classCount[lable]=classCount.get(lable,0)+1
#在python3中dict.iteritems()被废弃
sortedClasssCount=sorted(classCount.items(),
key=operator.itemgetter(1),reverse=True)
return sortedClasssCount[0][0]
代码传入的三个参数分别为待分类向量,测试数据,测试数据标签。代码使用欧式距离公式计算向量点之间的距离。
\]
numpy.tile(A,reps)A指待输入数组,reps则决定A的重复次数
sorted(iterable,cmp,key,reverse)这里利用了key参数使得使用字典中的value值进行排序
实例1:KNN算法改进约会网站配对效果
背景
假设A在利用约会网站进行约会,她将自己交往过的人分为三类:
- 不喜欢的人
- 魅力一般的人
- 极具魅力的人
A收集这些人的生活记录,从中提取中三类特征,存储在文本datingTestSet2中:
- 每年获得的飞行常客里程数
- 玩游戏视频所耗时间百分比
- 每周消耗的冰淇淋公升数
利用这三类特征和标签组成的样本库,我们可以在获得一个人的这三种特征的特征值的情况下,利用KNN算法判断该人是否会是A喜欢人
读取数据
我们将数据从文本中读出,并且以矩阵的形式进行存储
def file2matrix(filename):
fr=open(filename)
datalines=fr.readlines()
numberoflines=len(datalines)
returnMat=zeros((numberoflines,3))
classlabelVector=[]
index=0
for line in datalines:
line=line.strip()
listfromline=line.split('\t')
returnMat[index,:]=listfromline[0:3]
classlabelVector.append(int(listfromline[-1]))
index=index+1
return returnMat,classlabelVector
分析数据
我们可以利用Matplotlib制作原始数据的散点图,观察特征
def analydata():
a,b=file2matrix('datingTestSet2.txt')
#创建一个图形实例
fig=plt.figure()
ax=fig.add_subplot(111)
#scatter方法创建散点图
#分析图像可以发现使用第一列和第二列数据特征更加明显
ax.scatter(a[:,0],a[:,1],15.0*array(b),15.0*array(b))
plt.show()
画图结果:
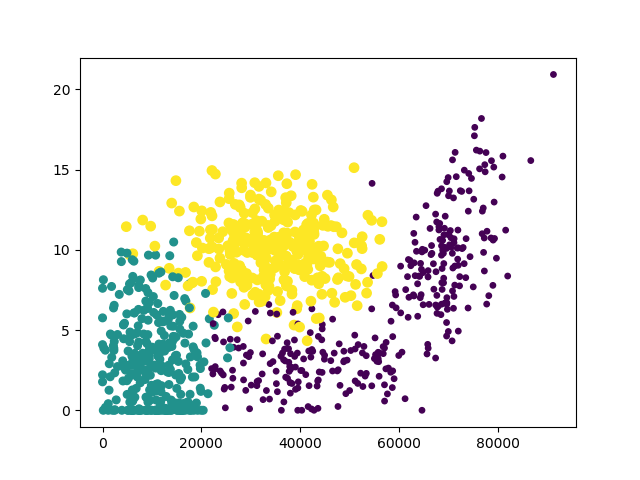
这里以“冰淇淋公斤数”和“玩视频游戏所耗时间百分比”作为横纵坐标特征最为明显
归一化数据
在数据分析和机器学习中,经常要进行数据归一化。因为不同的特征值使用不同的量度,上下限不同,使得有的特征产生的差值很大,而有的很小,会影响算法准确性。所以要先对数据预处理,进行数据归一化处理。
\]
分类器与测试
我们利用KNN算法,以前10%的数据作为待分类数据,后90%的数据作为样本库测试数据,进行分类与测试
def datingClassTest():
hoRatio=0.10
datingDataMat,datingLables=file2matrix('datingTestSet2.txt')
normMat=data2normal(datingDataMat)
m=normMat.shape[0]
numTestVecs=int(hoRatio*m)
errorCount=0
for i in range(numTestVecs):
result=classify(normMat[i,:],normMat[numTestVecs:m,:],
datingLables[numTestVecs:m],3)
print("the classify come back with: %d,the real answer is: %d"
%(result,datingLables[i]))
if(result!=datingLables[i]):
errorCount+=1.0
print("error rate is:%f"%(errorCount/float(numTestVecs)))
测试结果,错误率大概在5%左右。
我们可以改变hoRatio和k的值,检查错误率是否发生变化
实例2:手写识别系统
背景
假设我们有一些手写数字,以如下形式保存:
00000000000001100000000000000000
00000000000011111100000000000000
00000000000111111111000000000000
00000000011111111111000000000000
00000001111111111111100000000000
00000000111111100011110000000000
00000001111110000001110000000000
00000001111110000001110000000000
00000011111100000001110000000000
00000011111100000001111000000000
00000011111100000000011100000000
00000011111100000000011100000000
00000011111000000000001110000000
00000011111000000000001110000000
00000001111100000000000111000000
00000001111100000000000111000000
00000001111100000000000111000000
00000011111000000000000111000000
00000011111000000000000111000000
00000000111100000000000011100000
00000000111100000000000111100000
00000000111100000000000111100000
00000000111100000000001111100000
00000000011110000000000111110000
00000000011111000000001111100000
00000000011111000000011111100000
00000000011111000000111111000000
00000000011111100011111111000000
00000000000111111111111110000000
00000000000111111111111100000000
00000000000011111111110000000000
00000000000000111110000000000000
这是一个32*32的矩阵,利用0代表背景,1来代表手写数字
对于这些数据,我们也可以利用KNN算法来识别写的是0~9中的哪里数字
注:存储数据的文件,例如:0_0.txt代码数字0的第一个手写样本数据
数据预处理:转换成测试向量
数据使用32X32的矩阵形式存储,为了能够使用我们实现的KNN分类器,我们必须将其转化成1X1024的向量形式进行表示,也可以叫做降维,将二维数据转换成了一维数据
def img2vector(filename):
fr=open(filename)
returnVect=zeros((1,1024))
for i in range(32):
linestr=fr.readline()
for j in range(32):
returnVect[0,i*32+j]=int(linestr[j])
return returnVect
使用KNN算法进行分类
转换成向量以后,我们就可以使用我们实现的KNN分类器进行分类了
import operator
from os import listdir
import matplotlib
import matplotlib.pyplot as plt
from numpy import array, shape, tile, zeros
def handwritingClassTest():
hwlabels=[]
traingfilelist=listdir('digits/trainingDigits')
m=len(traingfilelist)
trainingDataMat=zeros((m,1024))
for i in range(m):
filenameStr=traingfilelist[i]
fileStr=filenameStr.split('.')[0]
label=int(fileStr.split('_')[0])
hwlabels.append(label)
trainingDataMat[i,:]=img2vector
('digits/trainingDigits/%s' % filenameStr)
errorCount=0.0
testfilelist=listdir('digits/testDigits')
mTest=len(testfilelist)
for i in range(mTest):
filenameStr=testfilelist[i]
fileStr=filenameStr.split('.')[0]
label=int(fileStr.split('_')[0])
testVector=img2vector('digits/testDigits/%s' %filenameStr)
result=classify(testVector,trainingDataMat,hwlabels,3)
print('come back with: %d,the real answer is: %d' % (int(result),label))
if(int(result)!=label):
errorCount=errorCount+1.0
print('total number errors is :%f' % errorCount)
print('error rate is :%f'% (errorCount/float(mTest)))
os.listdir()利用该方法,可以得到指定目录里面的所有文件名
机器学习实战(笔记)------------KNN算法的更多相关文章
- 算法代码[置顶] 机器学习实战之KNN算法详解
改章节笔者在深圳喝咖啡的时候突然想到的...之前就有想写几篇关于算法代码的文章,所以回家到以后就奋笔疾书的写出来发表了 前一段时间介绍了Kmeans聚类,而KNN这个算法刚好是聚类以后经常使用的匹配技 ...
- 机器学习实战 之 KNN算法
现在 机器学习 这么火,小编也忍不住想学习一把.注意,小编是零基础哦. 所以,第一步,推荐买一本机器学习的书,我选的是Peter harrigton 的<机器学习实战>.这本书是基于pyt ...
- 机器学习实战之kNN算法
机器学习实战这本书是基于python的,如果我们想要完成python开发,那么python的开发环境必不可少: (1)python3.52,64位,这是我用的python版本 (2)numpy 1.1 ...
- 《机器学习实战》KNN算法实现
本系列都是参考<机器学习实战>这本书,只对学习过程一个记录,不做详细的描述! 注释:看了一段时间Ng的机器学习视频,感觉不能光看不练,现在一边练习再一边去学习理论! KNN很早就之前就看过 ...
- 机器学习实战笔记——KNN
机器学习实战——读书笔记 书籍奉上
- 机器学习实战笔记——KNN约会网站
''' 机器学习实战——KNN约会网站优化 ''' import operator import numpy as np from numpy import * from matplotlib.fon ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 《机器学习实战》kNN算法及约会网站代码详解
使用kNN算法进行分类的原理是:从训练集中选出离待分类点最近的kkk个点,在这kkk个点中所占比重最大的分类即为该点所在的分类.通常kkk不超过202020 kNN算法步骤: 计算数据集中的点与待分类 ...
- 机器学习之路--KNN算法
机器学习实战之kNN算法 机器学习实战这本书是基于python的,如果我们想要完成python开发,那么python的开发环境必不可少: (1)python3.52,64位,这是我用的python ...
- 机器学习实战笔记-k-近邻算法
机器学习实战笔记-k-近邻算法 目录 1. k-近邻算法概述 2. 示例:使用k-近邻算法改进约会网站的配对效果 3. 示例:手写识别系统 4. 小结 本章介绍了<机器学习实战>这本书中的 ...
随机推荐
- ROS串口通信
身处机器人行业,不想一直只做低端的单片机控制,老是待在舒适区,所以一直都想学一下ROS系统,但看了几个月资料后,感觉还是云里雾里,似懂非懂,感念似乎都很清楚,但要实际去做,却又感觉无从下手. 于是想先 ...
- vue常考面试题
组件中 data 什么时候可以使用对象? 这道题其实更多考的是 JS 功底: 组件复用时所有组件实例都会共享 data,如果 data 是对象的话,就会造成一个组件修改 data 以后会影响到其他所有 ...
- com.alibaba.druid.pool.DruidDataSource : {dataSource-2} init error
这几天准备写一个项目,其中的整合druid的时候,发现出现了下面这个错误.找了好久都没有找到.网上的各种解决方法都不对. 2018-11-07 16:26:28.940 INFO 19684 --- ...
- XLSReadWriteII5导入excel数据
procedure TForm1.Button1Click(Sender: TObject); var xls: TXLSReadWriteII5; openFile: TOpenDialog; Ro ...
- 2018DDCTF misc1
一.题目: (╯°□°)╯︵ ┻━┻ d4e8e1f4a0f7e1f3a0e6e1f3f4a1a0d4e8e5a0e6ece1e7a0e9f3baa0c4c4c3d4c6fbb9e1e6b3e3b9e ...
- MongoDB系列----uupdate和数组
db.collection.update( criteria, objNew, upsert, multi ) criteria : update的查询条件,类似sql update查询内where后 ...
- Python基础之数组和向量化计算总结
一.多维数组 1.生成ndarray (array函数) .np.array()生成多维数组 例如:import numpy as npdata1=[6,7.5,8,0,1] #创建简 ...
- U面经Prepare: Print Binary Tree With No Two Nodes Share The Same Column
Give a binary tree, elegantly print it so that no two tree nodes share the same column. Requirement: ...
- 《linux就该这么学》第十三节课:第11章和第12章,vsftpd服务与samba和nfs服务
第十一章 (借鉴请改动) 11.1.文件传输协议 FTP文件穿数协议,端口20用于数据传输,21端口用于传输相关FTP命令 ftp协议的两种工作模式: 主动模式:ftp向客户端发起 被动模式(默认): ...
- linux 邮件服务器—Extmail
环境: Centos 6.5 :172.16.9.13 (DNS 服务器) Centos 6.5: 172.16.9.11 (postfix 邮件服务器) 安装软件: yum -y install p ...