HanLP vs LTP 分词功能测试
文章摘自github,本次测试选用 HanLP 1.6.0 , LTP 3.4.0
测试思路
使用同一份语料训练两个分词库,同一份测试数据测试两个分词库的性能。
语料库选取1998年01月的人民日报语料库。199801人民日报语料
该词库带有词性标注,为了遵循LTP的训练数据集格式,需要处理掉词性标注。
测试数据选择SIGHan2005提供的开放测试集。
SIGHan2005的使用可以参见其附带的readme。
HanLP
java -cp libs/hanlp-1.6.0.jar com.hankcs.hanlp.model.perceptron.Main -task CWS -train -reference ../OpenCorpus/pku98/199801.txt -model cws.bin
mkdir -p data/model/perceptron/pku199801
mv -f cws.bin data/model/perceptron/pku199801/cws.bin
默认情况下,训练的迭代次数为5。
修改 src/main/resouces 文件:
root=../test-hanlp-ltp
打包命令:
gradle clean build
SIGHan2005的MSR测试集
执行命令:
java -cp build/libs/test-hanlp-ltp-1.0-SNAPSHOT.jar com.zongwu33.test.TestForSIGHan2005 ../NLP/icwb2-data/testing/msr_test.utf8 segment-msr-result.txt
将分词的结果生成到segment-msr-result.txt文件里。 利用SIGHan2005的脚本生成分数:
perl ../NLP/icwb2-data/scripts/score ../NLP/icwb2-data/gold/msr_training_words.utf8 \
../NLP/icwb2-data/gold/msr_test_gold.utf8 segment-msr-result.txt > score-msr.ut8
可以得到 HanLP在MSR数据集上的测试结果:
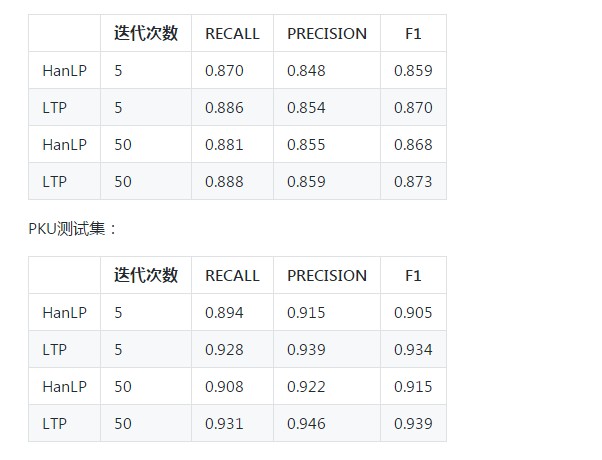
=== TOTAL TRUE WORDS RECALL: 0.870
=== TOTAL TEST WORDS PRECISION: 0.848
=== F MEASURE: 0.859
SIGHan2005的PKU测试集
java -cp build/libs/test-hanlp-ltp-1.0-SNAPSHOT.jar com.zongwu33.test.TestForSIGHan2005 ../NLP/icwb2-data/testing/pku_test.utf8 segment-pku-result.txt
perl ../NLP/icwb2-data/scripts/score ../NLP/icwb2-data/gold/pku_training_words.utf8 ../NLP/icwb2-data/gold/pku_test_gold.utf8 segment-pku-result.txt > score-pku.utf8
结果:
=== TOTAL TRUE WORDS RECALL: 0.894
=== TOTAL TEST WORDS PRECISION: 0.915
=== F MEASURE: 0.905
Docker安装 LTP
LTP
生成符合LTP训练格式的训练集文件:
java -cp build/libs/test-hanlp-ltp-1.0-SNAPSHOT.jar com.zongwu33.test.CreateSimpleCorpus ../OpenCorpus/pku98/199801.txt simple-199801.txt
simple-199801.txt 即为结果。 训练集 和开发集都指定为这个文件:
../LTP/ltp-3.4.0/tools/train/otcws learn --model model-test --reference simple-199801.txt --development simple-199801.txt --max-iter 5
SIGHan2005的MSR测试集
测试:
../LTP/ltp-3.4.0/tools/train/otcws test --model model-test --input /data/testLTP/icwb2-data/testing/msr_test.utf8 > msr_result.txt
利用SIGHan2005的脚本生成分数:
perl icwb2-data/scripts/score icwb2-data/gold/msr_training_words.utf8 \
icwb2-data/gold/msr_test_gold.utf8 msr_result.txt > ltp-msr-score.utf8
查看ltp-msr-score.utf8 :
=== TOTAL TRUE WORDS RECALL: 0.886
=== TOTAL TEST WORDS PRECISION: 0.854
=== F MEASURE: 0.870
SIGHan2005的PKU测试集
../LTP/ltp-3.4.0/tools/train/otcws test --model model-test --input /data/testLTP/icwb2-data/testing/pku_test.utf8 > pku_result.txt
perl icwb2-data/scripts/score icwb2-data/gold/pku_training_words.utf8 \
icwb2-data/gold/pku_test_gold.utf8 pku_result.txt > ltp-pku-score.ut8
=== TOTAL TRUE WORDS RECALL: 0.928
=== TOTAL TEST WORDS PRECISION: 0.939
=== F MEASURE: 0.934
对比
MSR测试集:
性能测试
阿里云ECS机器配置:
机器配置:Intel Xeon CPU *4 2.50GHz,内存16G
测试数据集 20M的网络小说,约140315句(不含空行)。
HanLP
java -cp test-hanlp-ltp-1.0-SNAPSHOT.jar com.zongwu33.test.PerformanceTest ../NLP/strict-utf8-booken.txt
init model: 313 ms
total time:15677 ms
total num:140315
需要15.677 s,可以计算得到处理速度 1375k/s 。
LTP
../LTP/ltp-3.4.0/tools/train/otcws test --model model-test --input strict-utf8-booken.txt > /dev/null
[INFO] 2018-03-26 17:04:19 ||| ltp segmentor, testing ...
[INFO] 2018-03-26 17:04:19 report: input file = strict-utf8-booken.txt
[INFO] 2018-03-26 17:04:19 report: model file = model-test
[INFO] 2018-03-26 17:04:19 report: evaluate = false
[INFO] 2018-03-26 17:04:19 report: sequence probability = false
[INFO] 2018-03-26 17:04:19 report: marginal probability = false
[INFO] 2018-03-26 17:04:19 report: number of labels = 4
[INFO] 2018-03-26 17:04:19 report: number of features = 491820
[INFO] 2018-03-26 17:04:19 report: number of dimension = 1967296
[INFO] 2018-03-26 17:05:13 Elapsed time 53.680000
需要53s。处理速度389k/s。
对比

开源协议
Apache License Version 2.0
HanLP vs LTP 分词功能测试的更多相关文章
- LTP 分词算法实践
参考链接: https://github.com/HIT-SCIR/ltp/blob/master/doc/install.rst http://www.xfyun.cn/index.php/serv ...
- 开源自然语言处理工具包hanlp中CRF分词实现详解
CRF简介 CRF是序列标注场景中常用的模型,比HMM能利用更多的特征,比MEMM更能抵抗标记偏置的问题. [gerative-discriminative.png] CRF训练 这类耗时的任务,还 ...
- spark集群使用hanlp进行分布式分词操作说明
本篇分享一个使用hanlp分词的操作小案例,即在spark集群中使用hanlp完成分布式分词的操作,文章整理自[qq_33872191]的博客,感谢分享!以下为全文: 分两步: 第一步:实现han ...
- 44、NLP的其他分词功能测试
1. 命名实体识别功能测试 @Test public void testNer(){ if (NER.create("ltp_data/ner.model")<0) { Sy ...
- hanlp中文智能分词自动识别文字提取实例
需求:客户给销售员自己的个人信息,销售帮助客户下单,此过程需要销售人员手动复制粘贴收获地址,电话,姓名等等,一个智能的分词系统可以让销售人员一键识别以上各种信息 经过调研,找到了一下开源项目 1.wo ...
- MapReduce实现与自定义词典文件基于hanLP的中文分词详解
前言: 文本分类任务的第1步,就是对语料进行分词.在单机模式下,可以选择python jieba分词,使用起来较方便.但是如果希望在Hadoop集群上通过mapreduce程序来进行分词,则hanLP ...
- 基于hanlp的es分词插件
摘要:elasticsearch是使用比较广泛的分布式搜索引擎,es提供了一个的单字分词工具,还有一个分词插件ik使用比较广泛,hanlp是一个自然语言处理包,能更好的根据上下文的语义,人名,地名,组 ...
- windows下使用LTP分词,安装pyltp
1.LTP介绍 ltp是哈工大出品的自然语言处理工具箱, 提供包括中文分词.词性标注.命名实体识别.依存句法分析.语义角色标注等丰富. 高效.精准的自然语言处理技术.pyltp是python下对ltp ...
- 开源中文分词工具探析(七):LTP
LTP是哈工大开源的一套中文语言处理系统,涵盖了基本功能:分词.词性标注.命名实体识别.依存句法分析.语义角色标注.语义依存分析等. [开源中文分词工具探析]系列: 开源中文分词工具探析(一):ICT ...
随机推荐
- 运行Office 2007安装程序提示:"找不到Office.zh-cn\OfficeMUI.xml"(转载)亲测
去网上查结果原来是Office 2007和Visual Studio 2008 Authoring Component组件相冲突,网上说用VS.Net 2008光盘WCU\WebDesignerCor ...
- ubuntu16.04运行ros的时候编译工作空间catkin_make出现的一个问题Could not find a package configuration file provided by
最近在进行ros里面的gazebo仿真之前需要对自己创建的工作空间进行编译,但是进行编译的时候输入catkin_make出现如下错误提示 查阅ROS问答社区之后发现两个比较有用的链接,如下 https ...
- Windows Server 2012系统上安装.net framework3.5教程
1.先下载WIN2012R2安装NET3.5的专用数据源 https://pan.baidu.com/s/1bqiUTyR 提取码h09k 并解压,比如解压到桌面,解压后的路径为C:\Users\Ad ...
- CSS效果:不怎么样的登录表单
HTML: <html lang="en"> <head> <meta charset="UTF-8"> <meta ...
- npm ERR! Unexpected end of JSON input while parsing near...错误
问题解决方案在GitHub中: https://github.com/vuejs-templates/webpack/issues/990 总结一下:1.删除package-lock.json 2.进 ...
- 201771010141 周强 面向对象程序设计(Java)第12周作业
实验十二 图形程序设计 实验时间 2018-11-14 1.实验目的与要求 (1) 掌握Java GUI中框架创建及属性设置中常用类的API: (2) 掌握Java GUI中2D图形绘制常用类的AP ...
- Axure10种非交互功能简介(引自人人都是产品经理)
一.notes:控件和页面注释 越来越多的PM开始用Axure来写PRD,但行内并不存在约定成俗的文档规范.作者目前为止见过的Axure版PRD中,大部分采用原型+旁边文字标注的方法来表达产品逻辑.其 ...
- npm 镜像源替换为淘宝镜像
1.查询配置的镜像源地址: npm get registry 2.配置为淘宝镜像源 npm config set registry http://registry.npm.taobao.org/ 3. ...
- 连续多次调用inet_ntoa()结果重复
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <pcap.h> ...
- iOS Property 关键字的使用
atomic和nonatomic用来决定编译器生成的getter和setter是否为原子操作. atomic 设置成员变量的@property属性时,默认为atomic,提供多线程安全 ...