实战Google深度学习框架-C3-TensorFlow入门
第三章:TensorFlow入门
TensorFlow存在计算模型,数据模型和运算模型(本文用TF代表TensorFlow)
3.1 计算模型-计算图
3.1.1 计算图的概念
TensorFlow这个词Tensor表示张量,可以简单的理解为多维数组,Flow直观的表达了张量之间通过计算相互转化的过程。
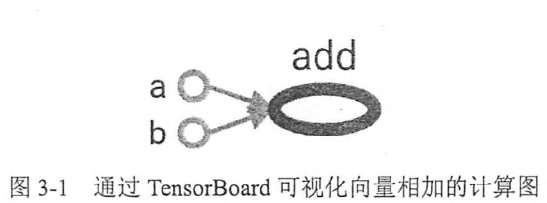
如上图,TensorFlow中每个节点都是一个计算,而边代表了计算之间的依赖关系。a,b这两个常量不依赖任何其他计算,而add则依赖于两个常量的取值。所有TensorFlow的程序都可以用类似的计算图的形式来表示。
3.1.2计算图的使用
TF使用默认的计算图,也可通过tf.Graph函数生成新的计算图,不同计算图上的张量和运算都不会共享。
'''
产生两个计算图,每个图都定义了一个名字为'v'的变量,分别初始化为0和1
可见计算图可以用来隔离张量和计算,使用tf.Graph.device可以指定运行计算的设备
g = tf.Graph()
with g.device('/gpu:0'):
result = a + b
将加法计算跑在GPU上
'''
import tensorflow as tf g1 = tf.Graph()#生成新的计算图
#如果需要定义多个Graph,则需要在with语句中调用as_default()方法将某个graph设置成默认Graph #tf.zeros_initializer:全部是0
#tf.ones_initializer:全是1 with g1.as_default():#设g1为默认图
#在计算图g1中定义变量"v",并设置初始值为0,shape指定变量维度
v = tf.get_variable('v', initializer=tf.zeros_initializer(shape=[1])) '''
tf.Variable()与tf.get_variable()区别
使用tf.Variable时,如果检测到命名冲突,系统会自己处理。使用tf.get_variable()时,系统不会处理冲突,而会报错
w_1 = tf.Variable(3, name="w_1")
w_2 = tf.Variable(1, name="w_1")
print(w_1.name)
print(w_2.name)
#输出
#w_1:0
#w_1_1:0 w_1 = tf.get_variable(name="w_1",initializer=1)
w_2 = tf.get_variable(name="w_1",initializer=2)
#错误信息
#ValueError: Variable w_1 already exists, disallowed. Did
#you mean to set reuse=True in VarScope?
''' g2 = tf.Graph()#生成新的计算图
with g2.as_default():#设g2为默认图
#在计算图g2中定义变量"v",并设置初始值为1
v = tf.get_variable('v',shape=[1], initializer=tf.ones_initializer()) #tf.variable_scope可以让不同命名空间中的变量取相同的名字,无论tf.get_variable或者tf.Variable生成的变量 #在计算图g1中读取变量'v'的取值
with tf.Session(graph=g1) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope('', reuse=True):
#在计算图g1中,变量'v'的取值应该为0,所以下面这行会输出[0.]
print(sess.run(tf.get_variable('v'))) #在计算图g2中读取变量'v'的取值
with tf.Session(graph=g2) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope('', reuse=True):
#在计算图g2中,变量'v'的取值应该为1,所以下面这行会输出[1.]
print(sess.run(tf.get_variable('v')))
3.2 数据模型-张量
3.2.1 张量的概念
在TF中,所有的数据都通过张量的形式表示。但张量并没有真正保存数字,它保存的是如何得到这些数字的计算过程(保存的是计算过程)
import tensorflow as tf
a = tf.constant([1], name='a')
b = tf.constant([2], name='b')
result = tf.add(a, b, name = 'add')
print(result)
#Tensor("add:0", shape=(1,), dtype=int32)
从上面可以看出并没有得到加法的结果,而得到一个张量的结构,包含三个属性:名字(name),维度(shape),类型(type),其中shape=(1,)表示了张量result是一个一维数组,数组长度为1,不同类型的张量想加会出错
3.2.2 张量的使用
主要有两大好处:一是对中间计算结果的引用,可以提高代码的可读性;二是当计算图构造完成后,张量可以用来获取计算结果
import tensorflow as tf #使用张量记录中间结果
a = tf.constant([1.0, 2.0], name='a')
b = tf.constant([2.0, 3.0], name='b')
result = a + b
print(result)
#Tensor("add_1:0", shape=(2,), dtype=float32) #直接计算向量的和,可读性差
result2 = tf.constant([1.0, 2.0], name='a') + tf.constant([2.0, 3.0], name='b')
print(result2)
#Tensor("add_2:0", shape=(2,), dtype=float32) #其实a和b是对常量生成这个运算结果的引用
3.3 TF 运行模型-会话
会话-拥有并管理TF程序运行时的所有资源,运行完毕后需要关闭会话来帮助系统回收资源,否则会资源泄露。会话模式如下两种:
###方法一###
#创建会话
import tensorflow as tf
sess = tf.Session() #获取关心的结果
sess.run(...) #关闭会话,释放资源
sess.close() ###方法二###
with tf.Session() as sess:
sess.run(...) #不需要调用sess.close()来关闭会话,自动关闭 a = tf.constant(8)
b = tf.constant(9)
c = a * b
#方法一
sess = tf.Session()
sess.run(c)#72
sess.close() #方法二
with tf.Session() as sess:
sess.run(c)
#72
不像tf.Graph(),TF不会自动生成默认的会话,而需要手动指定。指定后就可以使用Tensor.eval()【张量调用eval()方法来获取张量的值】
import tensorflow as tf
a = tf.constant(7)
b = tf.constant(9)
c = a * b sess = tf.Session()
with sess.as_default():
print(c.eval())#张量调用eval()方法获取张量c的值
#63
3.4 TF实现神经网络
3.4.1TF游乐场及神经网络简介:http://playground.tensorflow.org
从网页可以看出,TF游乐场左侧提供了4个不同的数据集来测试神经网络,不同颜色的点代表不同的标签,可以看出是二分类问题。如判断某工厂生产的零件是否合格,输入是x1表示零件长度,x2表示零件的质量。
输入层表示特征的输入,输出层表示输出的结果值,然后设置个阈值来判断零件是否合格。输入层和输出层之间的神经网络叫做隐藏层。一般隐藏层越多,这个神经网络就越“深”
隐藏层的节点表示一个神经元,边表示权重。颜色表示绝对值大小。颜色越浅,表示绝对值越小。
使用神经网络解决分类问题主要分为以下4个步骤:
1.准备神经系统输入
2.定义神经系统的结构,即如何从输入得到输出,这就是神经网络的前向传播算法。
3.通过train调整神经网络中参数的取值
4.使用训练好的神经网络来预测未知数据
3.4.2前向传播算法
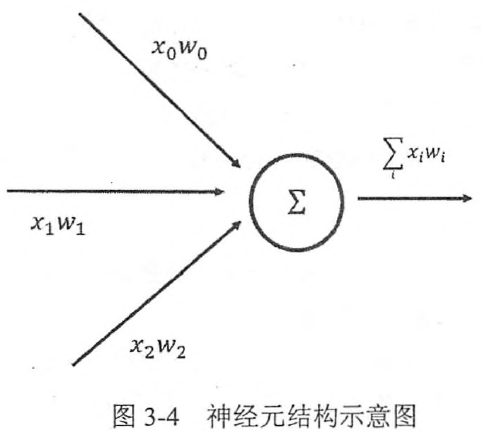
神经网络是如何做到将输入的特征经过层层节点得到最后的输出,并通过这些输出来解决分类或者回归问题的呢?这就是需要前向传播算法。其中单个神经元结构如下图:
下图给出一个简单的判断零件是否合格的三层全连接神经网络(之所以称为全连接神经网络是因为相邻两层之间任意两个节点之间都有连接)
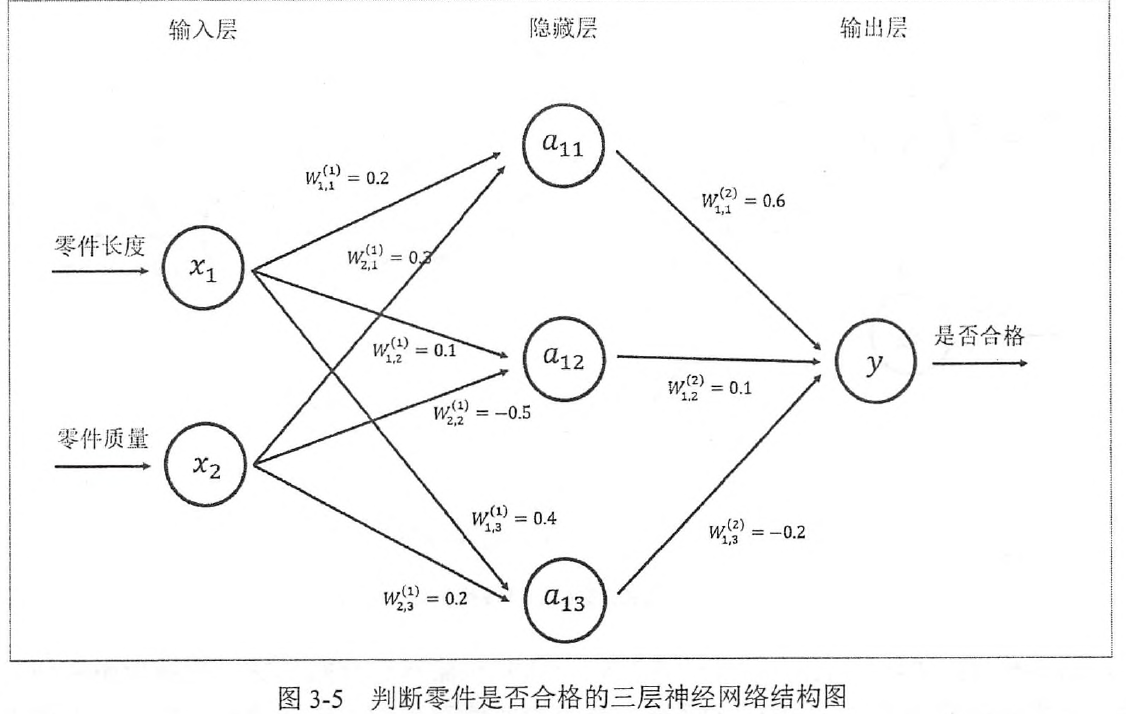
W上标表示神经系统隐藏层层数,\(W^{(1)}\)表示第一层节点参数,\(W^{(2)}\)表示第二层节点参数,W下标表明了连接节点编号,比如\(W^{(1)}_{1,2}\)表示连接x1和\(a_{12}\)节点的边上的权重。
上图的计算过程就是前向传播算法。前向传播算法可以表示为矩阵相乘。其中输入\(x = [x_1,x_2]\),而\(W^{1}\)表示一个2*3的矩阵:
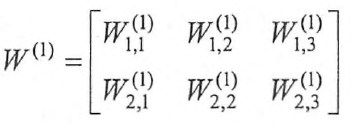
通过矩阵相乘,可以得到隐藏层三个节点组成的向量取值:

而输出层可以表示为:
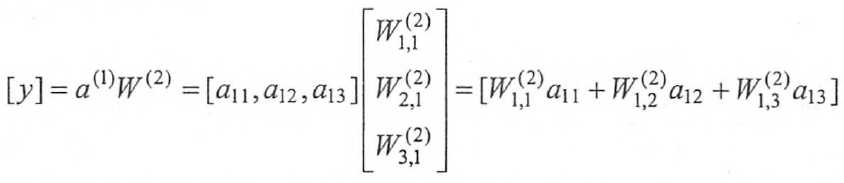
这样向前传播算法就可以通过矩阵相乘的方式表达出来了。在TF中矩阵相乘很容易实现:
import tensorflow as tf a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
3.4.3 神经网络参数与TF变量
TF中变量(tf.Variable)的作用就是保存和更新神经网络中的参数,并且变量需要指定初始值。如声明一个2*3矩阵变量的方法:
import tensorflow as tf weights = tf.Variable(tf.random_normal( [2,3], stddev=2) )
#矩阵中的元素是均值为0,标准差为2随机数

TF也支持通过常数来初始化一个变量
神经网络中,偏置项(bias)通常会使用常数来设置初始化值。
import tensorflow as tf
biases = tf.Variable(tf.zeros([3]))#初始化为9且长度为3的变量 #除了使用随机数或者常数,TF也支持通过其他变量的初始值来初始化新的变量
w2 = tf.Variable(weights.initialized_value())
w3 = tf.Variable(weights.initialized_value * 2.0)
下面简单实现一下神经网络的前向传播过程:
import tensorflow as tf w1 = tf.Variable(tf.random_normal([2,3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3,1], stddev=1, seed=1)) x = tf.constant([[0.7, 0.9]]) a = tf.matmul(x, w1)
y = tf.matmul(a, w2) sess = tf.Session()
#因为w1, w2都没有运行初始化过程,下面运行初始化
sess.run(w1.initializer)
sess.run(w2.initializer) print(sess.run(y))
sess.close()
如果变量很多的话,上面的sess.run(w1.initializer)方法就显得很麻烦了,因此 tf.global_variables_initializer()就显得很重要了。
3.4.4 通过TF训练神经网络
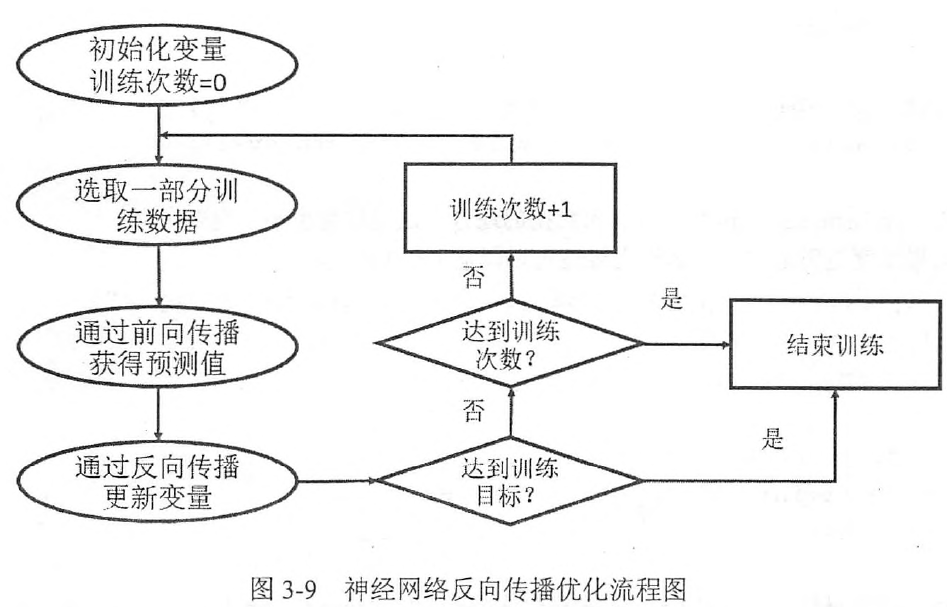
从上可以看出需要通过反向传播更新变量,每次的变量不同,计算图都会增加一个节点,导致计算图太大,因此TF提供了placeholder,先定义一个位置,后将更新的数据通过placeholder传入计算图,而不需要额外增加节点,完美。
import tensorflow as tf w1 = tf.Variable(tf.random_normal([2, 3], stddev=1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev=1)) #定义placeholder作为存放输入数据的地方,这里维度也不一定要定义
#但维度如果确定,那么给出维度可以降低出错的概率
x = tf.placeholder(tf.float32, shape=(1, 2), name='input')
a = tf.matmul(x, w1)
y = tf.matmul(a, w2) sess = tf.Session()
init_op = tf.global_variables_initializer()
sess.run(init_op) #下面一行会报错:InvalidArgumentError : You must feed a value for placeholder
#tensor 'input' with dtype float and shape [1,2]
#print(sess.run(y))会出错 #下面一行将会得到正确结果
print(sess.run(y, feed_dict = {x: [[0.7, 0.9]]}))
上述例子中x = [[0.7, 0.9]],但是训练神经网络时,每次提供的是一个batch的训练实例,也就是有n个1*2样本,如果将输入的1*2矩阵变成n*2矩阵,那么就会得到n个样本的前向传播结果了。其中n*2矩阵的每一行为一个样本,前向传播的结果为n*1的矩阵,矩阵的每一行就代表了一个样本的前向传播结果。
import tensorflow as tf w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1)) #定义placeholder作为存放输入数据的地方,这里维度也不一定要定义
#但维度如果确定,那么给出维度可以降低出错的概率
x = tf.placeholder(tf.float32, shape=(3, 2), name='input')
a = tf.matmul(x, w1)
y = tf.matmul(a, w2) sess = tf.Session()
init_op = tf.global_variables_initializer()
sess.run(init_op) #下面一行会报错:InvalidArgumentError : You must feed a value for placeholder
#tensor 'input' with dtype float and shape [1,2]
#print(sess.run(y))会出错 #下面一行将会得到正确结果
print(sess.run(y, feed_dict = {x: [[0.7, 0.9], [0.1, 0.4], [0.5, 0.8]]}))
得到一个batch的前向传播结果后,还需要定义一个损失函数来刻画当前预测值与真实值之间的差距,然后通过反向传播算法来调整神经网络参数的取值使得差距可以被缩小。
3.4.5 完整的神经网络样例程序
import tensorflow as tf
from numpy.random import RandomState #定义训练数据batch的大小
batch_size = 8 #定义神经网络的参数
w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1)) #在shape的一个维度上使用None,可以方便使用不大的batch大。
#在训练时需要把数据分成比较小的batch,但在测试时,可以一次性使用全部的数据。
#当数据集比较小时这样比较方便测试,但数据集比较大时,将大量数据放入一个batch可能会导致内存溢出。
x = tf.placeholder(tf.float32, shape=(None, 2), name='x_input')
y_ = tf.placeholder(tf.float32, shape=(None, 1), name='y-input') #定义神经网络前向传播过程
a = tf.matmul(x, w1)
y = tf.matmul(a, w2) #定义损失函数和反向传播算法
#tf.log计算TensorFlow的自然对数
#tf.reduce_mean计算张量的各个维度上的元素的平均值。
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy) #通过随机数生成一个模拟数据集
rdm = RandomState(1)#对于某一个伪随机数发生器,只要该种子(seed)相同,产生的随机数序列就是相同的,此处种子为1
dataset_size = 128
X = rdm.rand(dataset_size, 2)#rand()产生[0, 1)均匀分布 #定义样本集的标签:在这里所有x1 + x2 < 1的样本都被认为是正样本(如零件合格)
#其他为负样本(比如零件不合格),这里使用0表示负样本,1表示正样本
Y = [ [int(x1+x2 < 1)]for (x1, x2) in X ] #创建一个会话来运行TF程序
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
#初始化所有变量
sess.run(init_op)
#训练之前的神经网络参数值
print(sess.run(w1))
print(sess.run(w2)) #定义训练的轮数
STEPS = 5000
for i in range(STEPS):
#每次选取batch_size个样本进行训练
start = (i * batch_size) % dataset_size
end = min(start + batch_size, dataset_size) #通过选取的样本训练神经网络并更新参数
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]}) if i% 1000 == 0:
#每隔一段时间计算在所有数据上的交叉熵并输出
total_cross_entropy = sess.run(cross_entropy, feed_dict={x: X, y_: Y})
#随着训练的进行,交叉熵越小说明预测的结果与真实的结果差距越小
print("After %d training step(s), cross entropy on all data is %g" % (i, total_cross_entropy)) #训练后的神经网络的参数的值
print(sess.run(w1))
print(sess.run(w2))
#它使得这个神经网络能更好的拟合提供的训练数据
实战Google深度学习框架-C3-TensorFlow入门的更多相关文章
- Reading | 《TensorFlow:实战Google深度学习框架》
目录 三.TensorFlow入门 1. TensorFlow计算模型--计算图 I. 计算图的概念 II. 计算图的使用 2.TensorFlow数据类型--张量 I. 张量的概念 II. 张量的使 ...
- 【书评】【不推荐】《TensorFlow:实战Google深度学习框架》(第2版)
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 这本书我老老实实从头到尾看了一遍(实际上是看到第9章,刚看完,后面的实在看不下去了,但还是会坚持看的),所有的代码 ...
- 学习《TensorFlow实战Google深度学习框架 (第2版) 》中文PDF和代码
TensorFlow是谷歌2015年开源的主流深度学习框架,目前已得到广泛应用.<TensorFlow:实战Google深度学习框架(第2版)>为TensorFlow入门参考书,帮助快速. ...
- [Tensorflow实战Google深度学习框架]笔记4
本系列为Tensorflow实战Google深度学习框架知识笔记,仅为博主看书过程中觉得较为重要的知识点,简单摘要下来,内容较为零散,请见谅. 2017-11-06 [第五章] MNIST数字识别问题 ...
- 1 如何使用pb文件保存和恢复模型进行迁移学习(学习Tensorflow 实战google深度学习框架)
学习过程是Tensorflow 实战google深度学习框架一书的第六章的迁移学习环节. 具体见我提出的问题:https://www.tensorflowers.cn/t/5314 参考https:/ ...
- TensorFlow+实战Google深度学习框架学习笔记(5)----神经网络训练步骤
一.TensorFlow实战Google深度学习框架学习 1.步骤: 1.定义神经网络的结构和前向传播的输出结果. 2.定义损失函数以及选择反向传播优化的算法. 3.生成会话(session)并且在训 ...
- TensorFlow实战Google深度学习框架-人工智能教程-自学人工智能的第二天-深度学习
自学人工智能的第一天 "TensorFlow 是谷歌 2015 年开源的主流深度学习框架,目前已得到广泛应用.本书为 TensorFlow 入门参考书,旨在帮助读者以快速.有效的方式上手 T ...
- TensorFlow实战Google深度学习框架10-12章学习笔记
目录 第10章 TensorFlow高层封装 第11章 TensorBoard可视化 第12章 TensorFlow计算加速 第10章 TensorFlow高层封装 目前比较流行的TensorFlow ...
- TensorFlow实战Google深度学习框架5-7章学习笔记
目录 第5章 MNIST数字识别问题 第6章 图像识别与卷积神经网络 第7章 图像数据处理 第5章 MNIST数字识别问题 MNIST是一个非常有名的手写体数字识别数据集,在很多资料中,这个数据集都会 ...
- TensorFlow实战Google深度学习框架1-4章学习笔记
目录 第1章 深度学习简介 第2章 TensorFlow环境搭建 第3章 TensorFlow入门 第4章 深层神经网络 第1章 深度学习简介 对于许多机器学习问题来说,特征提取不是一件简单的事情 ...
随机推荐
- LeetCode算法题-Find Mode in Binary Search Tree(Java实现)
这是悦乐书的第246次更新,第259篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第113题(顺位题号是501).给定具有重复项的二叉搜索树(BST),找到给定BST中的 ...
- 前端面试回顾---javascript的面向对象
转:https://segmentfault.com/a/1190000011061136 前言 前一阵面试,过程中发现问到一些很基础的问题时候,自己并不能很流畅的回答出来.或者遇到一些基础知识的应用 ...
- typescript 学习笔记
错的写法 枚举 错误写法 方法可选参 类 子类没有找父类
- Vue 自定义一个插件的用法、小案例及在项目中的应用
1.开发插件 install有两个参数,第一个是Vue构造器,第二个参数是一个可选的选项对象 MyPlugin.install = function (Vue, options) { // 1 ...
- UVA - 11478 - Halum(二分+差分约束系统)
Problem UVA - 11478 - Halum Time Limit: 3000 mSec Problem Description You are given a directed grap ...
- (一) Getting Started
Elasticsearch is a highly scalable open-source full-text search and analytics engine. It allows you ...
- 在物理内存中观察CLR托管内存及GC行为
虽然看了一些书,还网络上的一些博文,不过对CLR托管内存细节依然比较模糊.而且因为工作原因总会有很多质疑,想要亲眼看到内存里二进制数据的变化. 所以借助winhex直接查看内存以证实书上的描述或更进一 ...
- .Net Core应用框架Util介绍(二)
Util的开源地址 https://github.com/dotnetcore/util Util的开源协议 Util以MIT协议开源,这是目前最宽松的开源协议,你不仅可以用于商业项目,还能把Util ...
- Oracle的表被锁后的恢复
运行下列SQL,找出数据库的serial#,执行结果如下图所示 SELECT T2.USERNAME, T2.SID, T2.SERIAL#, T2.LOGON_TIME FROM V$LOCKE ...
- 安装Java和Tomcat
安装Java 下载java源码包 安装的是JDK8,下载地址如下:下载链接 注意,不要在服务器中使用wget来下载jdk,因为oracle会认为你是爬虫,下载的文件不是jdk,而是一个html文件. ...