通过Flink实现个推海量消息数据的实时统计
背景
消息报表主要用于统计消息任务的下发情况。比如,单条推送消息下发APP用户总量有多少,成功推送到手机的数量有多少,又有多少APP用户点击了弹窗通知并打开APP等。通过消息报表,我们可以很直观地看到消息推送的流转情况、消息下发到达成功率、用户对消息的点击情况等。
个推在提供消息推送服务时,为了更好地了解每天的推送情况,会从不同的维度进行数据统计,生成消息报表。个推每天下发的消息推送数巨大,可以达到数百亿级别,原本我们采用的离线统计系统已不能满足业务需求。随着业务能力的不断提升,我们选择了Flink作为数据处理引擎,以满足对海量消息推送数据的实时统计。
本文将主要阐述选择Flink的原因、Flink的重要特性以及优化后的实时计算方法。
离线计算平台架构
在消息报表系统的初期,我们采用的是离线计算的方式,主要采用spark作为计算引擎,原始数据存放在HDFS中,聚合数据存放在Solr、Hbase和Mysql中:
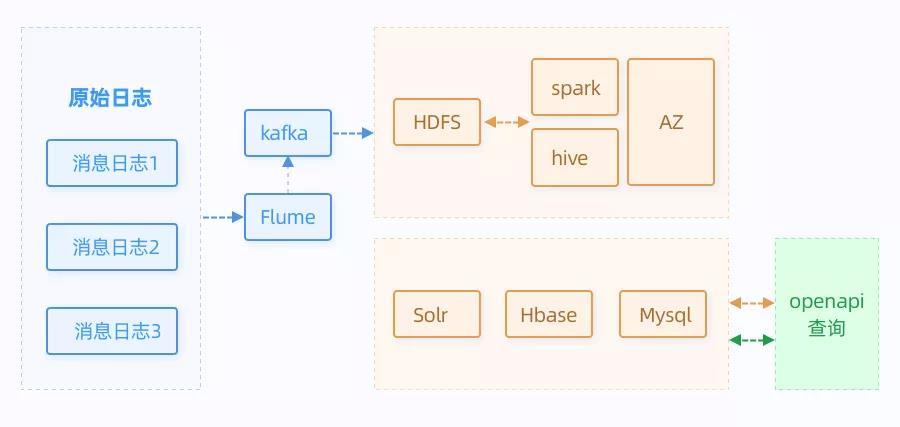
查询的时候,先根据筛选条件,查询的维度主要有三个:
- appId
- 下发时间
- taskGroupName
根据不同维度可以查询到taskId的列表,然后根据task查询hbase获取相应的结果,获取下发、展示和点击相应的指标数据。在我们考虑将其改造为实时统计时,会存在着一系列的难点:
- 原始数据体量巨大,每天数据量达到几百亿规模,需要支持高吞吐量;
- 需要支持实时的查询;
- 需要对多份数据进行关联;
- 需要保证数据的完整性和数据的准确性。
Why Flink
Flink是什么
Flink 是一个针对流数据和批数据的分布式处理引擎。它主要是由 Java 代码实现。目前主要还是依靠开源社区的贡献而发展。
对 Flink 而言,其所要处理的主要场景就是流数据。Flink 的前身是柏林理工大学一个研究性项目, 在 2014 被 Apache 孵化器所接受,然后迅速地成为了 ASF(Apache Software Foundation)的顶级项目之一。
方案对比
为了实现个推消息报表的实时统计,我们之前考虑使用spark streaming作为我们的实时计算引擎,但是我们在考虑了spark streaming、storm和flink的一些差异点后,还是决定使用Flink作为计算引擎:
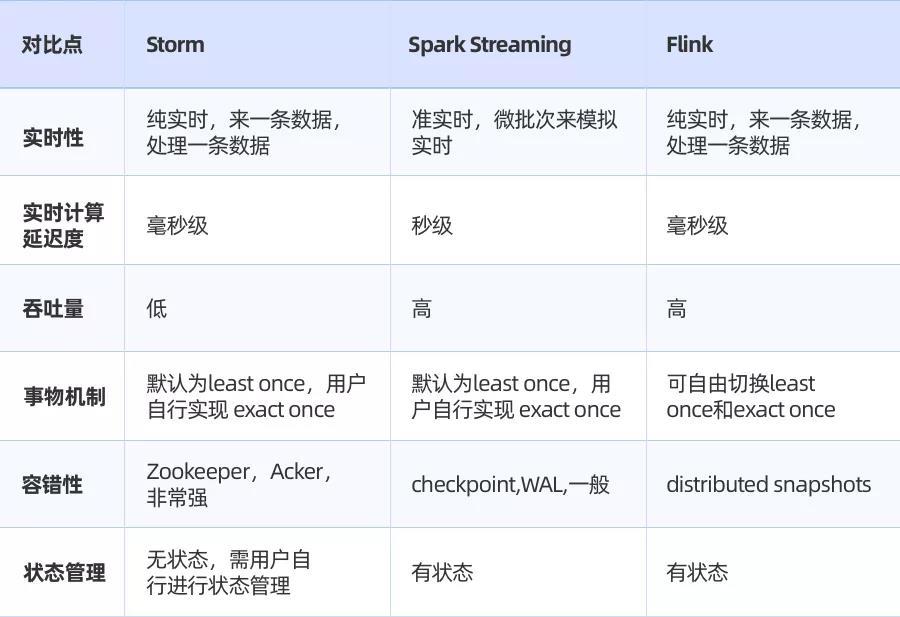
针对上面的业务痛点,Flink能够满足以下需要:
Flink以管道推送数据的方式,可以让Flink实现高吞吐量。
Flink是真正意义上的流式处理,延时更低,能够满足我们消息报表统计的实时性要求。
Flink可以依靠强大的窗口功能,实现数据的增量聚合;同时,可以在窗口内进行数据的join操作。
我们的消息报表涉及到金额结算,因此对于不允许存在误差,Flink依赖自身的exact once机制,保证了我们数据不会重复消费和漏消费。
Flink的重要特性
下面我们来具体说说Flink中一些重要的特性,以及实现它的原理:
1)低延时、高吞吐
Flink速度之所以这么快,主要是在于它的流处理模型。
Flink 采用 Dataflow 模型,和 Lambda 模式不同。Dataflow 是纯粹的节点组成的一个图,图中的节点可以执行批计算,也可以是流计算,也可以是机器学习算法。流数据在节点之间流动,被节点上的处理函数实时 apply 处理,节点之间是用 netty 连接起来,两个 netty 之间 keepalive,网络 buffer 是自然反压的关键。
经过逻辑优化和物理优化,Dataflow 的逻辑关系和运行时的物理拓扑相差不大。这是纯粹的流式设计,时延和吞吐理论上是最优的。
简单来说,当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理。
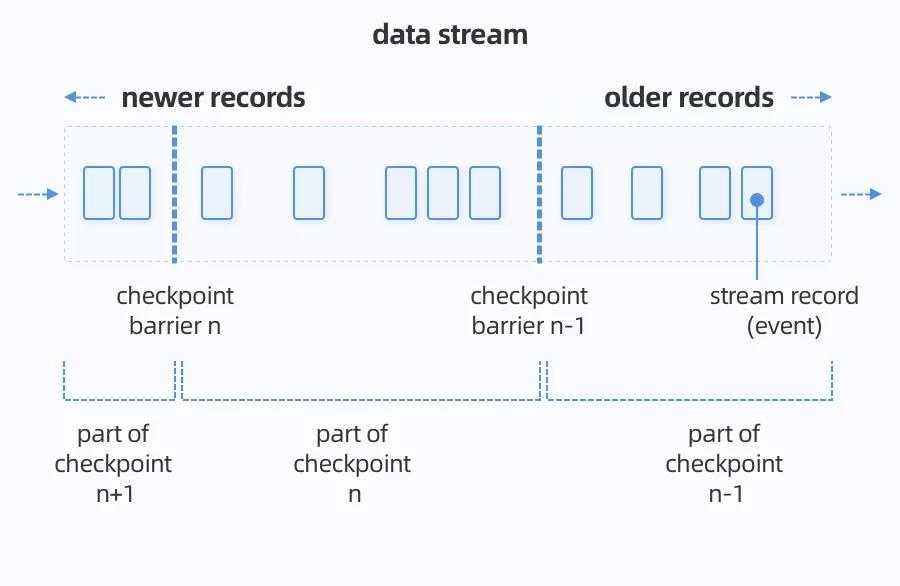
2)Checkpoint
Flink是通过分布式快照来实现checkpoint,能够支持Exactly-Once语义。
分布式快照是基于Chandy和Lamport在1985年设计的一种算法,用于生成分布式系统当前状态的一致性快照,不会丢失信息且不会记录重复项。
Flink使用的是Chandy Lamport算法的一个变种,定期生成正在运行的流拓扑的状态快照,并将这些快照存储到持久存储中(例如:存储到HDFS或内存中文件系统)。检查点的存储频率是可配置的。
3)backpressure
back pressure出现的原因是为了应对短期数据尖峰。
旧版本Spark Streaming的back pressure通过限制最大消费速度实现,对于基于Receiver 形式,我们可以通过配置spark.streaming. receiver.maxRate参数来限制每个 receiver 每秒最大可以接收的记录的数据。
对于 Direct Approach 的数据接收,我们可以通过配置spark.streaming. kafka.maxRatePerPartition 参数来限制每次作业中每个 Kafka 分区最多读取的记录条数。
但这样是非常不方便的,在实际上线前,还需要对集群进行压测,来决定参数的大小。
Flink运行时的构造部件是operators以及streams。每一个operator消费一个中间/过渡状态的流,对它们进行转换,然后生产一个新的流。
描述这种机制最好的类比是:Flink使用有效的分布式阻塞队列来作为有界的缓冲区。如同Java里通用的阻塞队列跟处理线程进行连接一样,一旦队列达到容量上限,一个相对较慢的接受者将拖慢发送者。
消息报表的实时计算
优化之后,架构升级成如下:
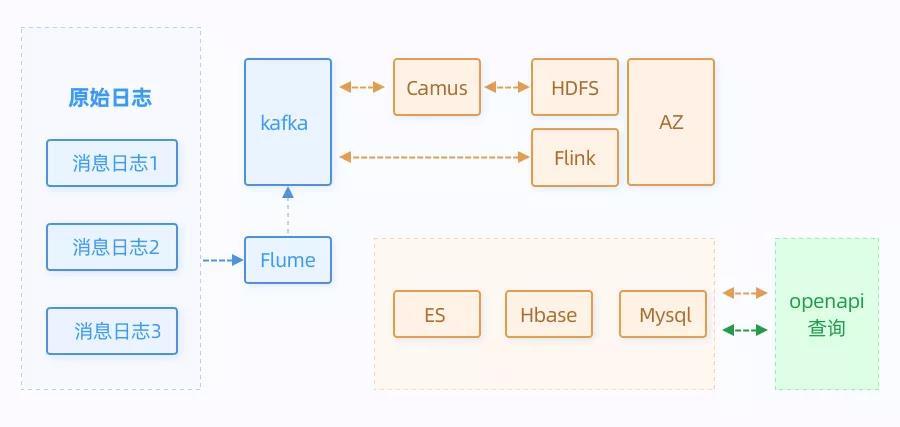
可以看出,我们做了以下几点优化:
- Flink替换了之前的spark,进行消息报表的实时计算;
- ES替换了之前的Solr。
对于Flink进行实时计算,我们的关注点主要有以下4个方面:
- ExactlyOnce保证了数据只会被消费一次
- 状态管理的能力
- 强大的时间窗口
- 流批一体
为了实现我们实时统计报表的需求,主要依靠Flink的增量聚合功能。
首先,我们设置了Event Time作为时间窗口的类型,保证了只会计算当天的数据;同时,我们每隔一分钟增量统计当日的消息报表,因此分配1分钟的时间窗口。
然后我们使用.aggregate (AggregateFunction af, WindowFunction wf) 做增量的聚合操作,它能使用AggregateFunction提前聚合掉数据,减少 state 的存储压力。之后,我们将增量聚合后的数据写入到ES和Hbase中。
流程如下所示:
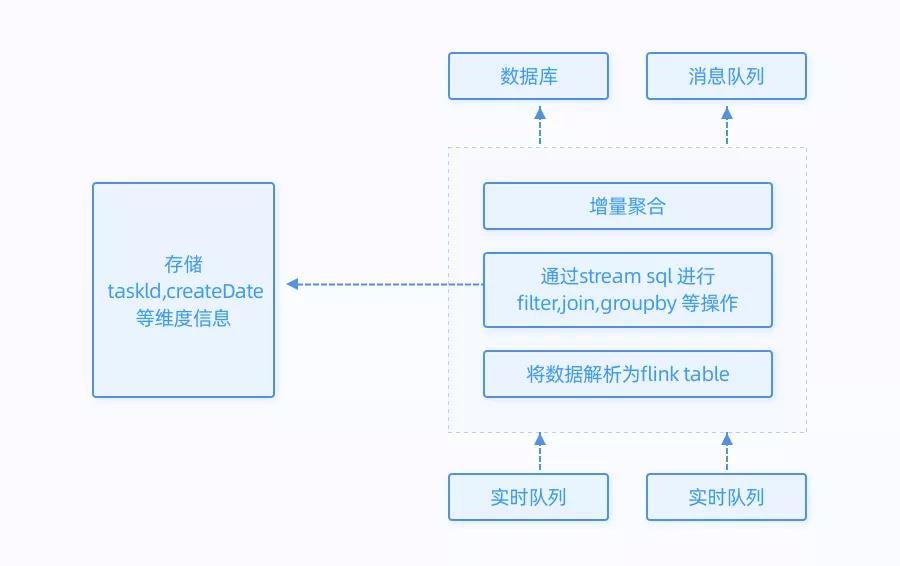
同时,在查询的时候,我们通过taskID、日期等维度进行查询,先从ES中获取taskID的集合,之后通过taskID查询hbase,得出统计结果。
总结
通过使用Flink,我们实现了对消息推送数据的实时统计,能够实时查看消息下发、展示、点击等数据指标,同时,借助FLink强大的状态管理功能,服务的稳定性也得到了一定的保障。未来,个推也将持续优化消息推送服务,并将Flink引入到其他的业务线中,以满足一些实时性要求高的业务场景需求。
通过Flink实现个推海量消息数据的实时统计的更多相关文章
- 利用大数据技术处理海量GPS数据
我秀中国物联网地图服务平台目前接入的监控车辆近百万辆,每天采集GPS数据7亿多条,产生日志文件70GB,使用传统的数据处理方式非常耗时. 比如,仅仅对GPS做一些简单的统计分析,程序就需要几个小时才能 ...
- android不需要Socket的跨进程推送消息AIDL!
上篇介绍了跨进程实时通讯http://www.cnblogs.com/xiaoxiaing/p/5818161.html 但是他有个缺点就是服务端无法推送消息给客户端,今天这篇文章主要说的就是服务器推 ...
- signalr推送消息
参考:Tutorial: Getting Started with SignalR 2 and MVC 5 环境:vs2013,webapi2,entity framework6.0 实现效果:当用户 ...
- HTML5服务器推送消息的各种解决办法
摘要 在各种BS架构的应用程序中,往往都希望服务端能够主动地向客户端推送各种消息,以达到类似于邮件.消息.待办事项等通知. 往BS架构本身存在的问题就是,服务器一直采用的是一问一答的机制.这就意味着如 ...
- IOS 本地通知推送消息
在现在的移动设备中,好多应用性的APP都用到了推送服务,但是有好多推送的内容,比如有的只是单纯的进行推送一个闹钟类型的,起了提醒作 用,有的则是推送的实质性的内容,这就分为推送的内容来区别用什么推送, ...
- iOS极光推送 点击推送消息跳转页面
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launc ...
- JAVA调用易信接口向指定好友推送消息(二)POST测试
易信的API接口做的还算简单 http://open.yixin.im/document/oauth/api 根据指南上的步骤,利用易信提供的测试ID AppID(client_id): yxbbd0 ...
- iOS 推送,当接到推送消息时如何处理?
接收到通知时有两种进入的方式:1.当app未运行时(BOOL)application:(UIApplication *)application didFinishLaunchingWithOption ...
- iOS8推送消息的回复处理速度
iOS8我们有一个新的通知中心,我们有一个新的通报机制.当在屏幕的顶部仅需要接收一个推拉向下,你可以看到高速接口,天赋并不需要输入应用程序的操作.锁定屏幕,用于高速处理可以推动项目. 推送信息,再次提 ...
随机推荐
- vue运行碰到的问题
Expected indentation of 0 spaces but found 2 解决方案: 文件中加入"indent": ["off", 2]就可以了 ...
- 对xxl-job进行simpleTrigger并动态创建任务扩展
业务场景 需求上要求能实现quartz的simpleTrigger任务,同时还需要动态的创建任务而非在控制面板上创建,查阅xxl-job官方文档发现simpelTrigger其暂时还躺在to do l ...
- cookie和session的详解和区别
会话(Session)跟踪是Web程序中常用的技术,用来跟踪用户的整个会话.常用的会话跟踪技术是Cookie与Session.Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端 ...
- Django框架——基础之模型系统(ORM的介绍和字段及字段参数)
1.ORM简介 1.1 ORM的概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说,ORM ...
- java的移位和异或运算
Java移位运算种类 基础:我们知道在Java中int类型占32位,可以表示一个正数,也可以表示一个负数.正数换算成二进制后的最高位为0,负数的二进制最高为为1 例子: -5换算成二进制后为:1111 ...
- (转)Java8内存模型-永久代(PermGen)和元空间(Metaspace)
原文链接:https://www.cnblogs.com/paddix/p/5309550.html 一.JVM内存模型 根据jvm规范,jvm内存共分为虚拟机栈.堆.方法区.程序计算器.本地方法栈五 ...
- 利用shell脚本做一个用户登录系统
效果图如下: #!/bin/bash# while truedocat << EOF//======================\\\\| 用户登录系统 |-------------- ...
- 基于linux与busybox的reboot命令流程分析
http://www.xuebuyuan.com/736763.html 基于Linux与Busybox的Reboot命令流程分析 ********************************** ...
- pickle和JSON的序列化
Pickle和JSON的序列化 Python的pickle模块允许我们把对象只节存储成一个特殊的存储格式,它本质上是把一个对象转换成一种可以存储到文件或者类文件对象或者一个字节字符串的格式: > ...
- 多线程与UI操作(一)
C#中禁止跨线程直接访问控件,InvokeRequired是为了解决这个问题而产生的,当一个控件的InvokeRequired属性值为真时,说明有一个创建它以外的线程想访问它. 此时它将会在内部调用n ...