A Neural Probabilistic Language Model (2003)论文要点
论文链接:http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
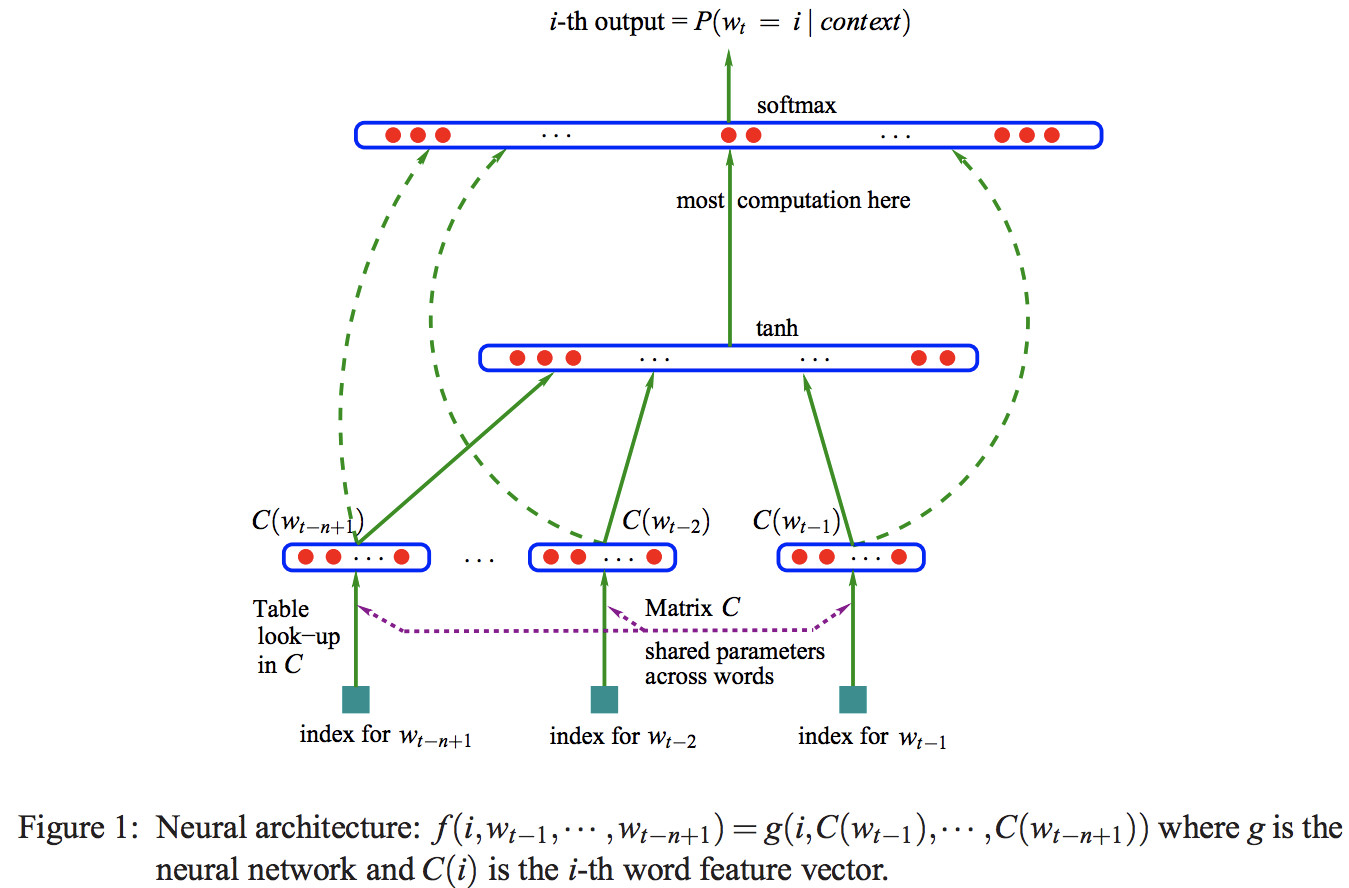
解决n-gram语言模型(比如tri-gram以上)的组合爆炸问题,引入词的分布式表示。
通过使得相似上下文和相似句子中词的向量彼此接近,因此得到泛化性。
相对而言考虑了n-gram没有的更多的上下文和词之间的相似度。
使用浅层网络(比如1层隐层)训练大语料。

feature vector维度通常在100以内,对比词典大小通常在17000以上。

C是全局共享的向量数组。
最大化正则log似然函数:
非归一化的log似然:

hidden units num = h
word feature vector dimension = m
context window width = n
output biases b: |V|
hidden layer biases d: h
hidden to output weights U: |V|*h
word feature vector to output weights W: |V|*(n-1)*m
hidden layer weights H: h*(n-1)*m
word reature vector group C: |V|*m
Note that in theory, if there is a weight decay on the weights W and H but not on C, then W and H could converge towards zero while C would blow up. In practice we did not observe such behavior when training with stochastic gradient ascent.
每次训练大部分参数不需要更新。
训练算法:



可改进点:
1. 分成子网络并行训练
2. 输出词典|V|改成树结构,预测每层的条件概率:计算量|V| -> log|V|
3. 梯度重视特别的样本,比如含有歧义词的样本
4. 引入先验知识(词性等)
5. 可解释性
6. 一词多义(一个词有多个词向量)
A Neural Probabilistic Language Model (2003)论文要点的更多相关文章
- A Neural Probabilistic Language Model
A Neural Probabilistic Language Model,这篇论文是Begio等人在2003年发表的,可以说是词表示的鼻祖.在这里给出简要的译文 A Neural Probabili ...
- pytorch ---神经网络语言模型 NNLM 《A Neural Probabilistic Language Model》
论文地址:http://www.iro.umontreal.ca/~vincentp/Publications/lm_jmlr.pdf 论文给出了NNLM的框架图: 针对论文,实现代码如下: # -* ...
- 从代码角度理解NNLM(A Neural Probabilistic Language Model)
其框架结构如下所示: 可分为四 个部分: 词嵌入部分 输入 隐含层 输出层 我们要明确任务是通过一个文本序列(分词后的序列)去预测下一个字出现的概率,tensorflow代码如下: 参考:https: ...
- Efficient Estimation of Word Representations in Vector Space (2013)论文要点
论文链接:https://arxiv.org/pdf/1301.3781.pdf 参考: A Neural Probabilistic Language Model (2003)论文要点 https ...
- NLP问题特征表达基础 - 语言模型(Language Model)发展演化历程讨论
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- 论文分享|《Universal Language Model Fine-tuning for Text Classificatio》
https://www.sohu.com/a/233269391_395209 本周我们要分享的论文是<Universal Language Model Fine-tuning for Text ...
- #论文阅读# Universial language model fine-tuing for text classification
论文链接:https://aclweb.org/anthology/P18-1031 对文章内容的总结 文章研究了一些在general corous上pretrain LM,然后把得到的model t ...
- 【论文翻译】KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships
KLMo:建模细粒度关系的知识图增强预训练语言模型 (KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Graine ...
- Recurrent Neural Network Language Modeling Toolkit代码学习
Recurrent Neural Network Language Modeling Toolkit 工具使用点击打开链接 本博客地址:http://blog.csdn.net/wangxingin ...
随机推荐
- 例子 使用sqlite3 数据库建立数据方式
#!/usr/bin/env python#coding:utf-8import sqlite3#建立一个数据库cx = sqlite3.connect("E:/test.db") ...
- Xshell 6 安装注册说明
1.下载 官方下载到的版本在进行安装的时候,是有序列号输入框的如下图,但是好像我们从那个所谓的官网上下载的却没有,只能下载到一点击注册就跳转到一个网站的那种版本. 像上面这种版本如何下载呢? 我们去官 ...
- Ubuntu下借助URLOS实现快速安装DzzOffice企业办公套件
如今,越来越多的个人.团队甚至企业都在使用GSuite或者Office365等网络办公套件,为什么人们越来越喜爱使用网络办公套件?一方面是考虑数字资产的安全性以及管理效率,另一方面则是日益增大的协同办 ...
- 快速排序基本思想,递归写法,python和java编写快速排序
1.基本思想 快速排序有很多种编写方法,递归和分递归,分而治之法属于非递归,比递归简单多了.在这不使用代码演示.下面我们来探讨一下快速排序的递归写法思想吧. 设要排序的数组是A[0]……A[N-1], ...
- SqlService 数据操作
存储过程: if exists(select * from sysobjects where name='proce_name') drop procedure proce_name go creat ...
- mysql——插入、更新、删除数据(概念)
一.插入数据 1.为表的所有字段插入数据 -------------------------------------------------------------------------- (1)i ...
- 1.docker 慕课入门
本文是学习慕课网的实战https://www.imooc.com/learn/824 同时结合菜鸟教程的思想https://www.runoob.com/docker/docker-architec ...
- Linux基础命令---间歇执行命令---watch
[watch] watch指令可以间歇性的执行程序,将输出结果以全屏的方式显示,默认是2s执行一次. watch指令下发后,将会一直被执行,直到被中断. [语法] watch \ [-d h v t] ...
- python装饰器的原理
装饰器的原理就是利用<闭包函数>来实现,闭包函数的原理就是包含内层函数的return和外层环境变量:
- Luogu P4902 乘积
题目 我们要求的是 \[ \prod\limits_{i=a}^b\prod\limits_{j=1}^i(\frac ij)^{\lfloor\frac ij\rfloor} \] 先把它拆开 \[ ...