python +requests 爬虫-爬取图片并进行下载到本地
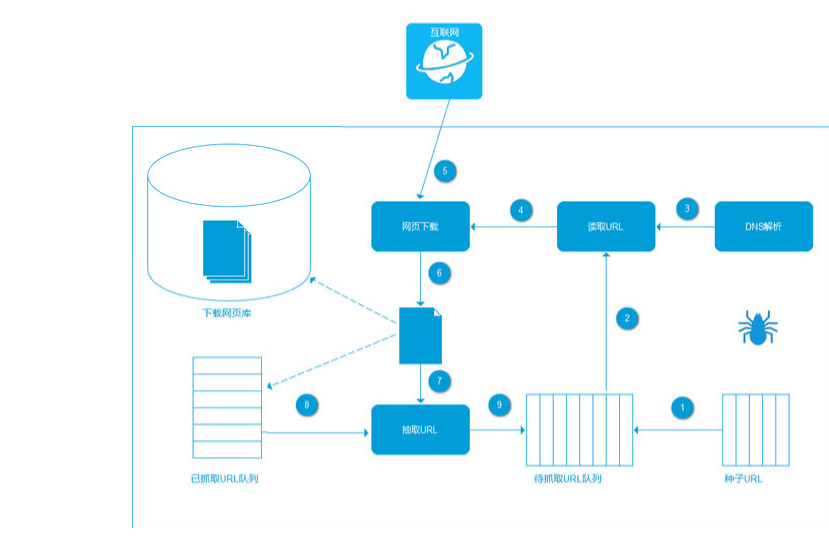
- 爬虫实现方式:
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。

- 环境 :
- python
- re
- requests
- 正则:
pic_url = re.findall('"objURL":"(.*?)",',html, re.S)
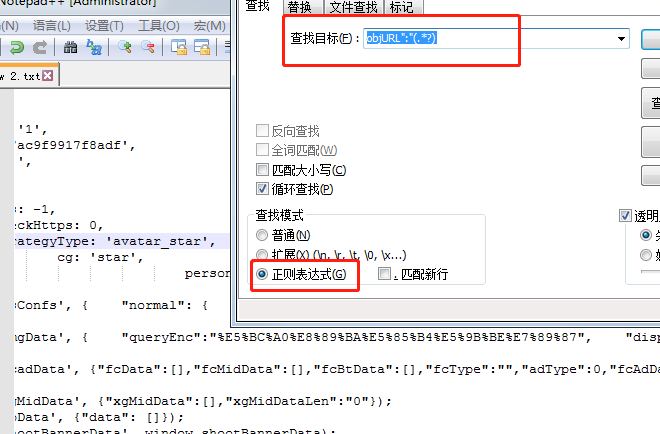
- 小技巧:这边的正则如果你不太确定有没有匹配到的话可以使用notepad++来匹配下
- 第一步查看你需要抓取网页右击查看源代码
- 第二步把代码贴入notepad++中
- 第三步f12查询选择正则进行匹配
- 也可用这个网址:http://tool.oschina.net/regex/#
- 废话不多说直接上代码
import re
import requests def download(html):
#通过正则匹配
pic_url = re.findall('"objURL":"(.*?)",',html, re.S)
i = 1
for key in pic_url:
print("开始下载图片:"+key +"\r\n")
try:
pic = requests.get(key, timeout=10)
except requests.exceptions.ConnectionError:
print('图片无法下载')
continue
#保存图片路径
dir = '保存路径' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
def main():
url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&fm=index&pos=history&word=lay'
result = requests.get(url)
download(result.text) if __name__ == '__main__':
main()
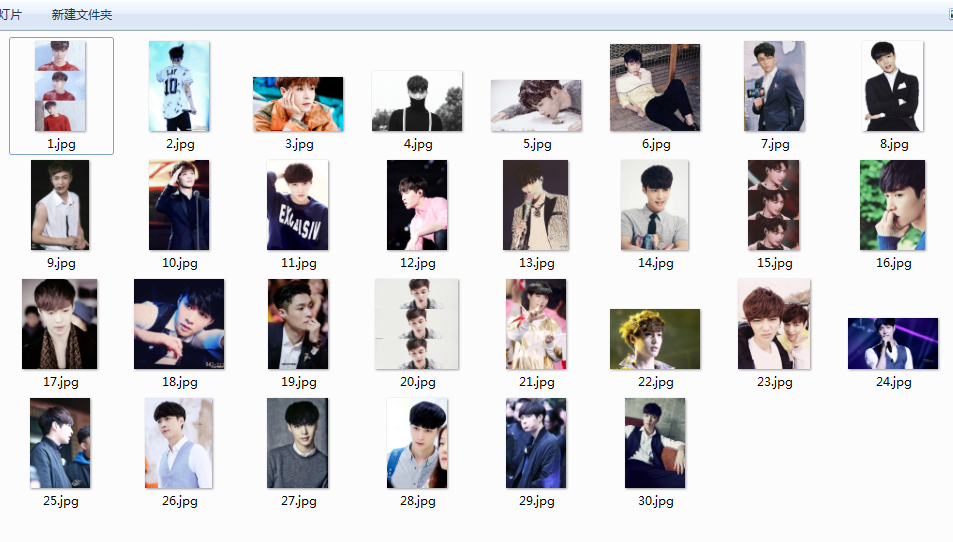
- 最后找到你下载图片的文件,然后看下小绵羊的盛世美颜
python +requests 爬虫-爬取图片并进行下载到本地的更多相关文章
- python网络爬虫&&爬取图片
爬取学院官网数据from urllib.request import * #导入所有request urllib文件夹,request只是里面的一个模块from lxml import etree # ...
- Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片
Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片 其实没太大用,就是方便一些,因为现在各个平台之间的图片都不能共享,比如说在 CSDN 不能用简书的图片, ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 使用Scrapy爬取图片入库,并保存在本地
使用Scrapy爬取图片入库,并保存在本地 上 篇博客已经简单的介绍了爬取数据流程,现在让我们继续学习scrapy 目标: 爬取爱卡汽车标题,价格以及图片存入数据库,并存图到本地 好了不多说,让我们实 ...
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度.搜狗.googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨.同时 ...
- Python 爬虫 爬取图片入门
爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 用户看到的网页实质是由 HTML 代码构成的,爬 ...
- 一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
[一.项目背景] 相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态. 今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来 ...
- Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
随机推荐
- 【CF321E】+【bzoj5311】
决策单调性 + WQS二分 贴个代码先... //by Judge #pragma GCC optimize("Ofast") #include<bits/stdc++.h& ...
- HDU 6468 /// DFS
题目大意: 把 1~15 的数字典序排序后为 1, 10, 11, 12, 13, 14, 15, 2, 3, 4, 5, 6, 7, 8, 9 此时给定 n k, 求1~n的数组字典序排序后 第k个 ...
- eclipse 使用技巧、经验 (编码、格式化模板、字体)
版权声明:本文为博主原创文章,未经博主同意不得转载.安金龙 的博客. https://blog.csdn.net/smile0198/article/details/28697515 1.设置编码为U ...
- Nodejs中request出现ESOCKETTIMEDOUT解决方案
做需求的时候,使用Nodejs的request批量请求某一个接口,由于接口超时,出现 ESOCKETTIMEDOUT,程序中断 为了让程序遇到 ESOCKETTIMEDOUT 之后能够继续执行下去,需 ...
- Windows10测试低版本IE方法
前端开发工程师可能了解IETester是一款IE多版本兼容性测试软件,但是只支持Windows Xp,Vista,7,8系统,Windows10是不支持的,网上所说的开启.net framework ...
- mysql 导出表中数据为excel的xls格式文件
需求: 利用mysql客户端导出数据库中数据,以便进行分析,统计. 解决命令: 在windos命令行(linux同理)下,用如下命令即可: mysql -hlocalhost -uroot -ppas ...
- APKMirror - 直接下载google play里的应用
APKMirror - Free APK Downloads - Download Free Android APKs #APKPLZ https://www.apkmirror.com/
- java 关键字volatile
一.Java内存模型 想要理解volatile为什么能确保可见性,就要先理解Java中的内存模型是什么样的. Java内存模型规定了所有的变量都存储在主内存中.每条线程中还有自己的工作内存,线程的工作 ...
- django之项目部署知识点
一:项目部署的框架 nginx和uWSGI在生产服务器上进行的部署 二:什么是nginx? nginx是一个web服务器. 什么是web服务器? web服务器则主要是让客户可以通过浏览器进行访问,处理 ...
- 前端之form表单与css(1)
目录 一.form表单 1.1表单的属性 1.2input 1.2.1form表单提交数据的两种方式 1.3select标签 1.4label标签 1.5textarea多行文本标签 二.CSS 2. ...